First, the primer
Last lecture, I take you saw the three-dimensional graphics rendering process in the computer's. This rendering process, into the process vertex, primitive processing, rasterization, fragment processing, and finally the operation of the pixel. This series of process,
Also known as the graphics rendering pipeline or pipeline.
In particular due to the real-time calculation of multi-pixel rendering, graphics accelerator card boarded the stage of history. Voodoo or by the TNT 3dFx NVidia such graphics accelerator,
the CPU does not need to go to a processing pixel points primitive processing, rasterizing processing, and fragments of these operations. The 3D games are also developed from this era.
You can see this picture, this is the change polygon modeling "Tomb Raider" game. This change, it is from 1996 to 2016, 20 years to the graphics card brings progress.
Two, Shader birth and programmable graphics processor
1, no matter how fast your graphics card, if the CPU does not work, 3D screen is the same as or not
I do not know if you have found TNT and Voodoo graphics rendering pipeline, there's no "vertex processing" this step. At the time, the vertices of the polygon linear change, transformation to coordinate the work of our screen is still done by the CPU.
Therefore, the better the performance of the CPU, it is possible to support the more polygons, polygonal modeling the effect corresponding to the more natural like a real person. The polygon 3D game performance is also limited
In the performance of our CPU. No matter how fast your graphics card, if the CPU does not work, 3D screen, like or not.
2, launched in 1999 NVidia GeForce 256 graphics card
So, we launched in 1999 NVidia GeForce 256 graphics card, put the vertex processing computing power, but also moved to the graphics card in the CPU inside. However, this is for programmers who want to do 3D gaming is not enough,
even to the GeForce 256. The whole process is in graphics rendering hardware inside a fixed line to complete. Programmers on the accelerator card can do it, just change the configuration to achieve different graphics rendering. If you pass
through can not change the configuration, we have no other way.
3, programmers hope we can have some GPU programmability
This time, programmers hope we can have some GPU programmability. This programming ability is not like the CPU, as there are very general instructions, can be anything you want action,
but in the entire rendering pipeline some special steps (Graphics Pipeline), it is possible to define their own algorithms to process data or operations. So, from the beginning of 2001, Direct3D 8.0,
Microsoft introduced the first programmable pipeline concept (Programable Function Pipeline) is.
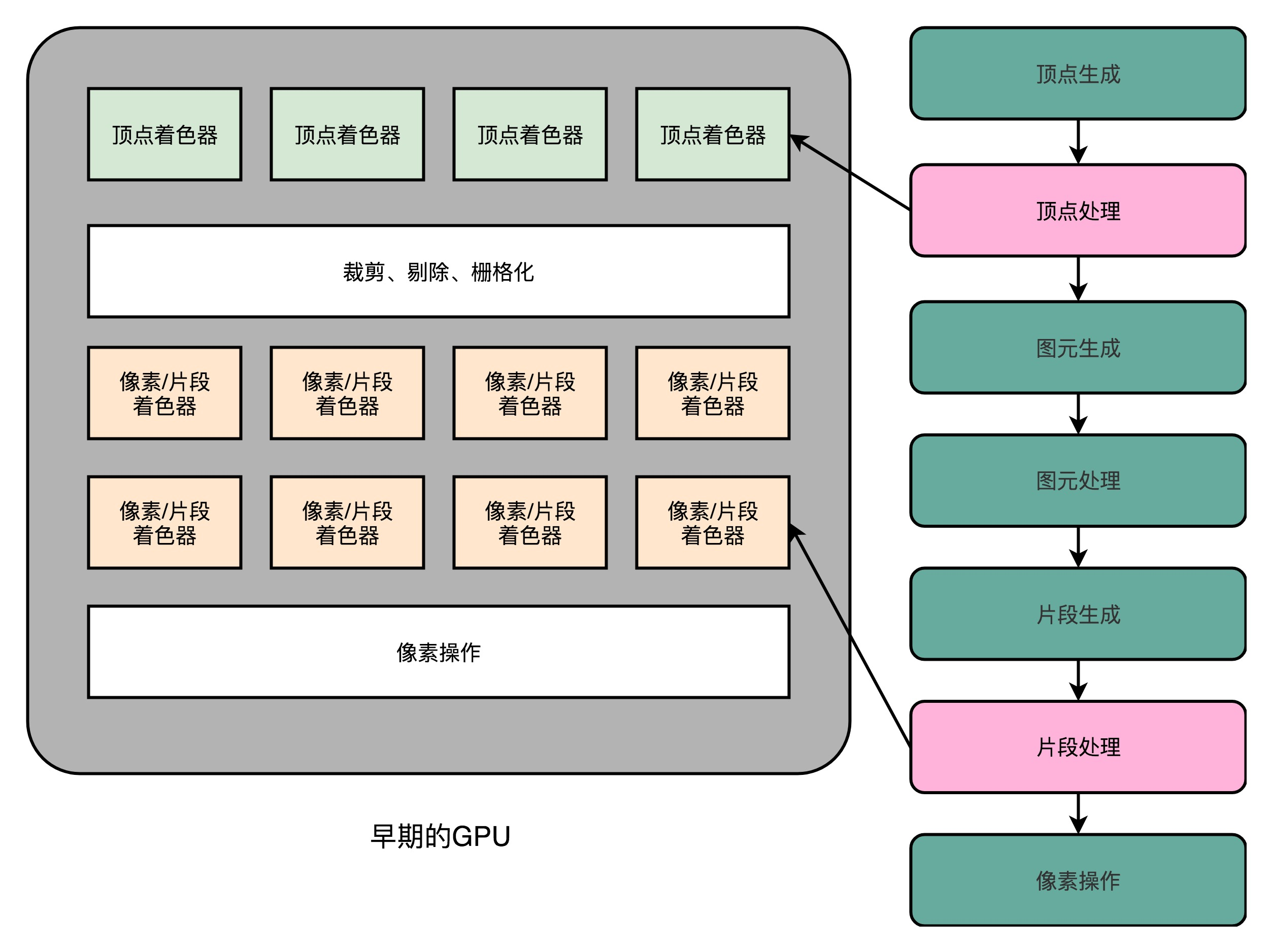
A programmable start line it is limited to vertex processing (Vertex Processing) Processing and fragments (Fragment Processing) section. Compared to the original can only be provided by Direct3D graphics and graphical interfaces such as fixed configuration,
Programmers can finally begin on the graphic effects begin to show their talents.
These can be programming interfaces, which we call Shader, Chinese name is the shader. It is called "shader", because these start "programmable" interface, only the modified vertex and fragment processing program logic processing section.
We use these interfaces to do, is mainly light, brightness, color, etc. is performed, so that the color cried.
4, Shader birth
These can be programming interfaces, which we call Shader , Chinese name is the shader. It is called "shader", because these start "programmable" interface, only the modified vertex and fragment processing program logic processing section.
We use these interfaces to do, is mainly light, brightness, color, etc. is performed, so called shaders
Vertex Shader and Shader Fragment Shader these two types are independent of the hardware circuit
This time the GPU, there are two types Shader, that is, Vertex Shader and Fragment Shader. We see a talk, the vertex processing performed when we operate the vertices of a polygon; fragment in operation, when
we operate the pixel on the screen. For a vertex usually more complicated than fragments. So first, these two are independent Shader hardware circuit, also have separate programming interface. Because doing so,
the hardware design is much simpler, can accommodate more Shader on a GPU.
5, there is a problem independent of hardware circuit
But then, we soon found that, although our specific logic on the vertex processing and fragment processing is not the same, but the instruction set which can be used in the same set. Moreover, although the separate and Vertex Shader Fragment Shader,
you can reduce the complexity of the hardware design, but also brought a waste, half Shader has not been used. In the entire rendering pipeline, the time Vertext Shader run, Fragment Shader stop there doing nothing.
Fragment Shader at run time, Vertext Shader also stop there in a daze.
6, unified shader architecture
Originally GPU is not cheap, the result of circuit design is idle half the time. Hardware engineers like to plan carefully plucked out of every minute, of course, can not stand the performance. Thus, the unified shader architecture (Unified Shader Architecture) came into being.
Since we use the instruction set is the same, it is better to put a number on the GPU inside the same Shader hardware circuit, and then through a unified scheduling, the vertex processing, processing primitives, fragments of these tasks are handed over to deal with these Shader ,
The whole GPU busy as possible. This design is our modern GPU design is unified shader architecture.
7, a universal graphics processor
Interestingly, this is not the first appearance of the GPU in the PC inside, but from a game console is Microsoft's XBox 360. Later, this architecture was only used ATI and NVidia graphics card inside. This time the role of "shader", and
in fact has little to do with its name, but to name became a generic abstract calculation module.
It is precisely because Shader become a "universal" module, only the use of the GPU used to do a variety of general-purpose computing, that is, GPGPU (General-Purpose Graphics Processing Units Computing ON, GPGPU).
It is precisely because the GPU can be used to make a variety of general-purpose computing, only the fiery depth study of the past 10 years.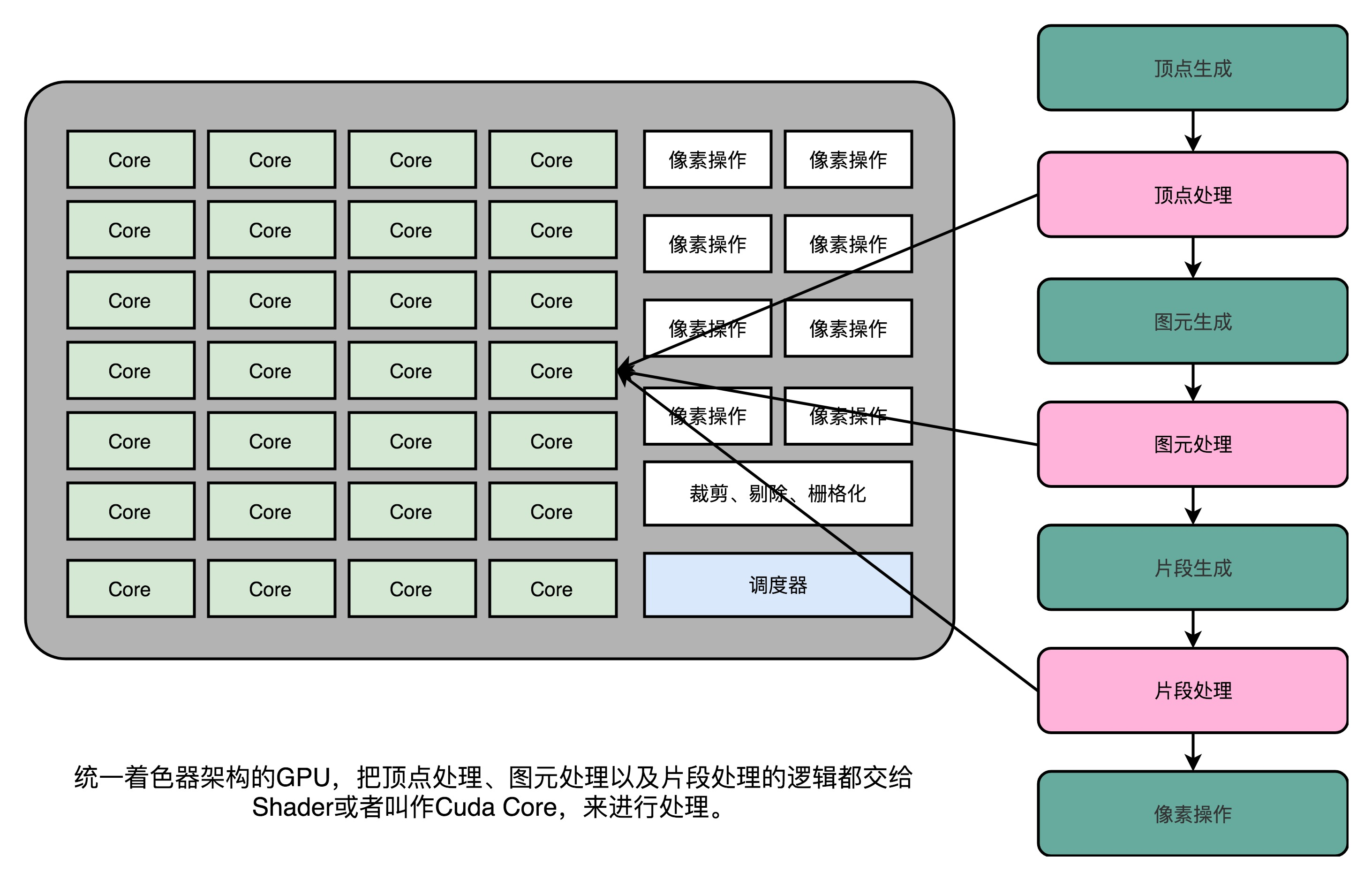
Third, the three core ideas of modern GPU
Finished the evolutionary history of modern GPU, then the next, we take a look at why modern GPU on the graphics rendering, depth can learn so fast
1, thin chip
Let's take a look back, before spending a lot of talk carefully explain modern CPU. Modern CPU in the transistor becomes more and more and more complex, in fact, is not used to achieve the "calculate" the core functionality, but the process used to achieve order execution,
branch prediction, and then we want to memory speak cache sections.
In the GPU, the redundant circuit is a little, the whole process of the GPU is a streaming process (Stream Processing) a. Since the branch condition is not so much, or complex dependencies,
we can put the GPU circuits corresponding to these can be removed, do a little thin, leaving only instruction fetch, instruction decode, and the ALU to perform these calculations require registers and caches just fine. Generally, these circuits we will abstracted into three parts, that is, in the following FIG fetch and decode instructions, and the ALU execution context.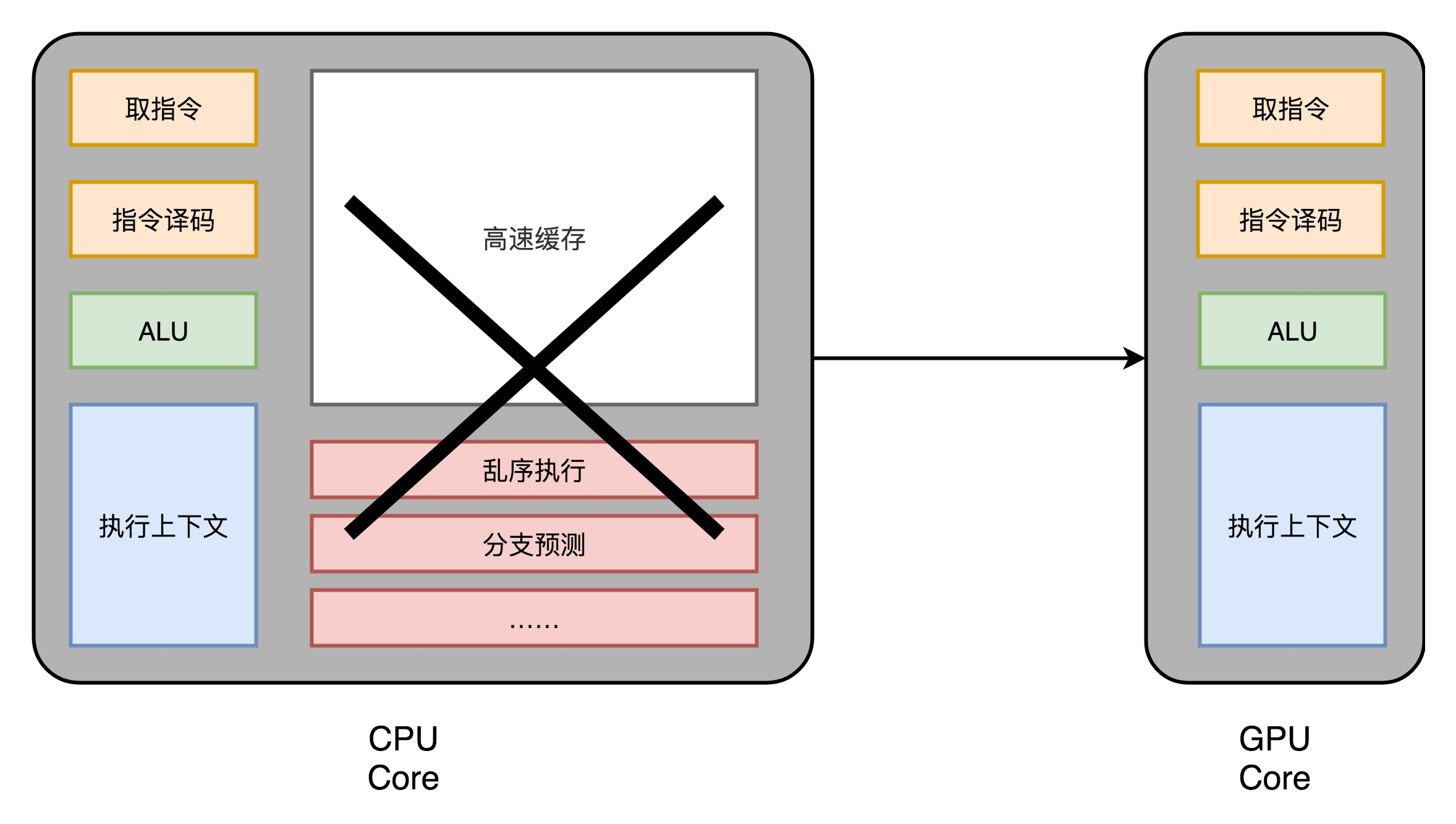
2, multicore parallel and SIMT
1, multicore parallel
As a result, our GPU circuitry is much simpler than the CPU. Thus, we can in which a GPU, such a number of parallel plug GPU computing circuit to achieve, if the CPU inside the same multi-core CPU.
CPU and different is what we do not need a separate multi-threaded computing to achieve. The operation is natural because the GPU parallel.

In the last lecture we have seen but in fact, both for the polygon vertices in the process, or a screen in which each pixel is processed to calculate each point is independent. Therefore, simply adding the GPU polynuclear,
can do accelerated parallel. However, this acceleration is not enough light, the engineers felt performance as well as further squeezing of space.
2, SIMT Technology
We talked about the stresses inside the first 27, CPU processing technology, there's something called SIMD. This technique is said that in doing vector calculation when we instruction to be executed is the same, except that the data of the same instruction was different.
In GPU rendering pipeline where this technology may make great use of.
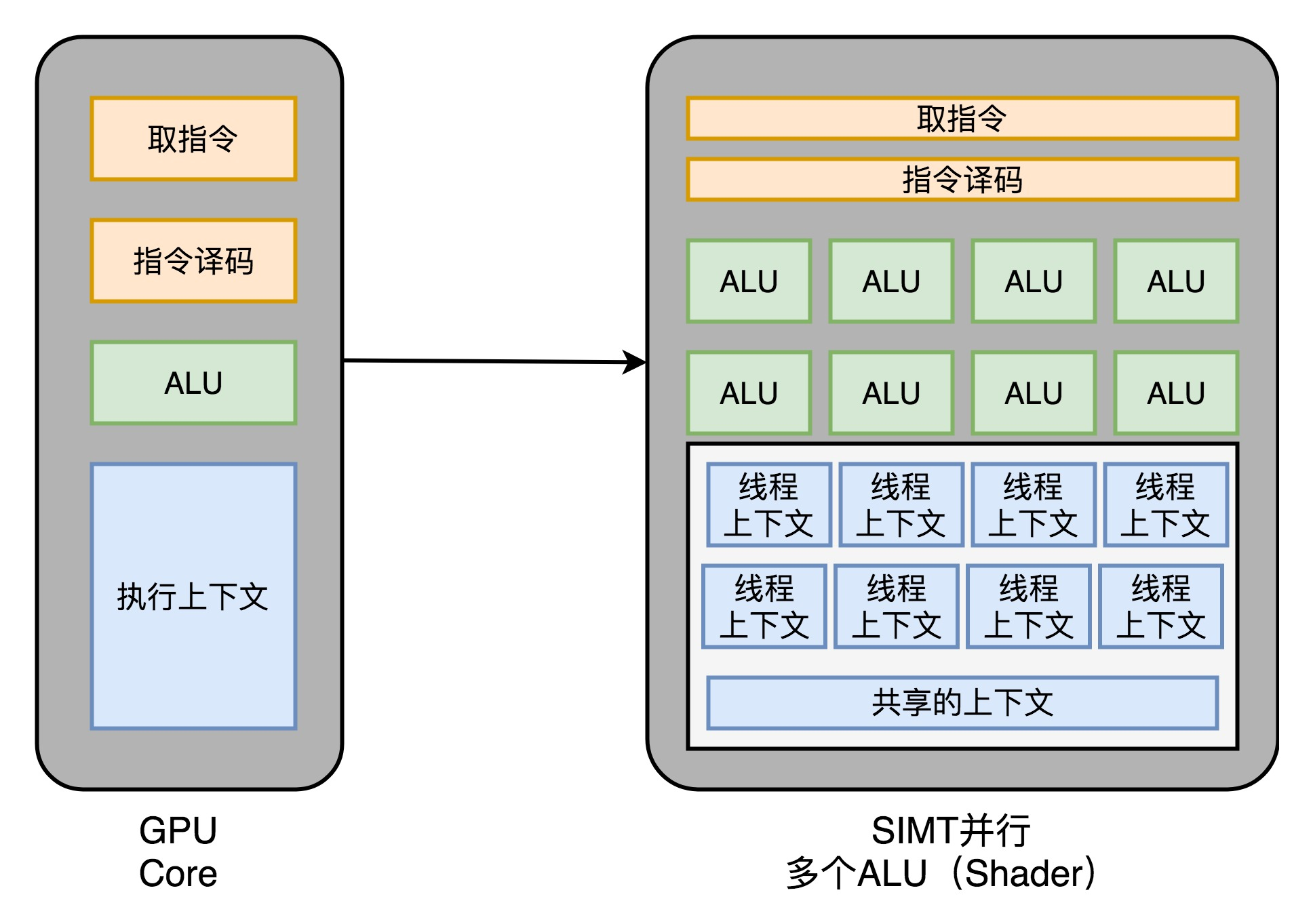
Whether it is linear transformation to the vertices, or points adjacent pixels on the screen light and color, are calculated using the same flow of instructions. So, GPU draws on the CPU inside the SIMD, with a called SIMT (Single Instruction, Multiple Threads) technology. SIMT it is more flexible than SIMD. In SIMD inside, the CPU-time extraction of a plurality of fixed-length data, into which registers with one instruction to execute. The SIMT, you can put multiple data to different threads to deal with.
Instruction execution processes of the thread which is the same, but may vary depending on different data, different conditional branches come. Thus, the same code and the same process may perform different specific instructions. This is a condition if the thread went branch,
another thread walked else is a conditional branch.
Thus, we can design the GPU further evolution, that is, the instruction fetch and instruction decode stage, the instruction fetch can give back to a plurality of different parallel ALU operations. In this way, one of our core GPU's,
you can put down more ALU, at the same time a more parallel computing.
3, GPU in the "hyper-threading"
Although mainly inside the GPU numerical calculation based. But since it is already a "universal computing" architecture of, GPU which can not avoid this condition will be if ... else branch. However, the GPU we can not branch prediction circuit of this CPU.
These circuits above "chip downsizing" when we had been cut off.
So, GPU in the instructions, and CPU may experience a similar "pipeline stall" problem. Think of pipeline stalls, you should be able to remember, we talked about before the Hyper-Threading technology CPU inside. On the GPU, we can still do something similar,
that is, when it came to a standstill, the scheduling of some other computing tasks to the current ALU.
And Hyper-Threading, as if it wants to schedule a different task over, we need to address this task, providing more execution context. So a number of Core inside the execution context, we need more than the ALU.
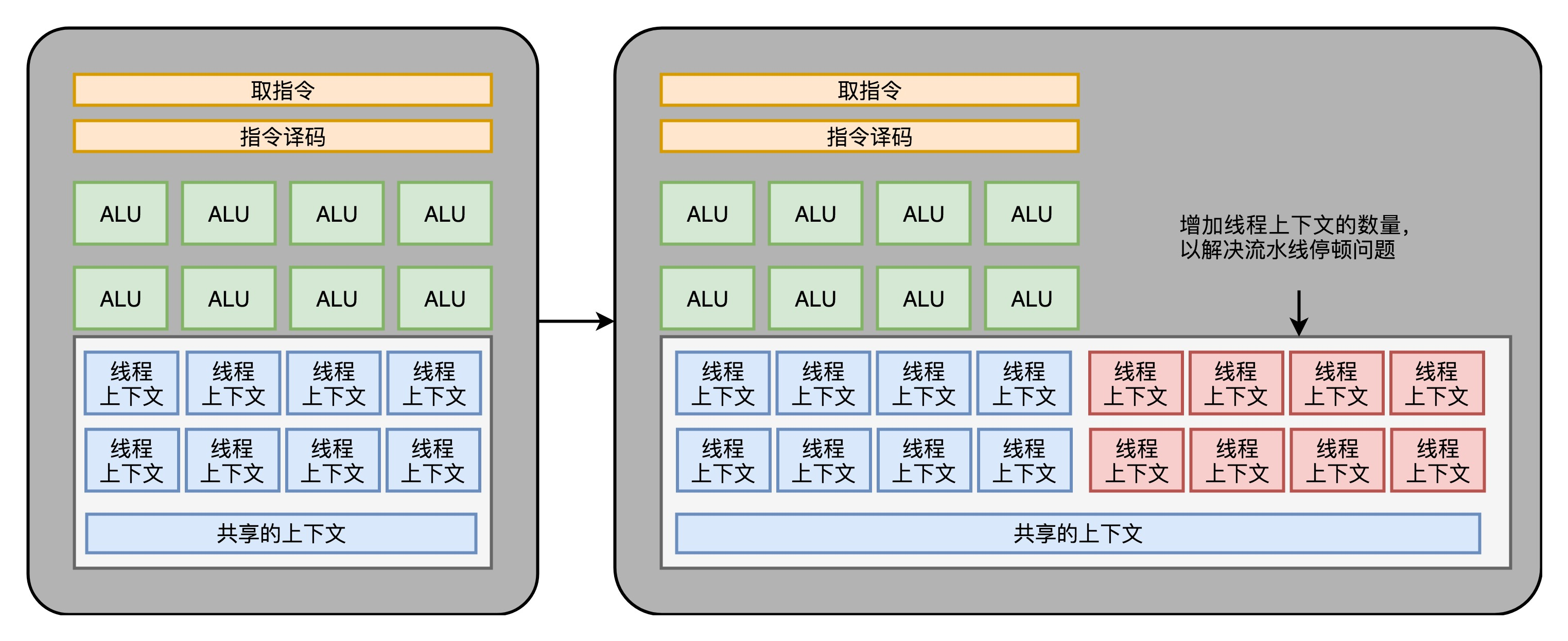
Four, GPU performance difference in the depth of learning
In the chip by thin, SIMT execution context and more, we have a better at parallel GPU computing violence. This chip is also suitable for today's depth study of usage scenarios.
On the one hand, GPU is a possible framework for "general-purpose computing," we can be programmed to implement different algorithms on the GPU. On the other hand, now calculate the depth of learning, they are large vectors and matrices, calculate the mass of training samples.
Entire calculation process, there is no complex logic and branches, very suitable for this GPU parallel computing architecture strong ability.
We see a NVidia 2080 graphics card specifications, can be calculated, which in the end how much computing power.
2080 a total of 46 SM (Streaming Multiprocessor, streaming processor), this is equivalent to SM GPU Core GPU inside, the inside of each SM 64 Cuda Core.
You can think of, here's Cuda Core is to say above us ALU number or the number of Pixel Shader, 46x64 it will have a total of 2944 Shader. Then, there are 184 TMU, TMU is Texture Mapping Unit,
which is used for computing texture mapping unit, it can also be considered another type of Shader.

2080 is clocked at 1515MHz, if the automatic overclocking (Boost), you can to 1700MHz. NVidia and graphics, according to the design of the hardware architecture, each clock cycle can execute two instructions. Therefore, the ability to do floating-point operations, is this:
(2944 + 184)× 1700 MHz × 2 = 10.06 TFLOPS
Control what the official technical specifications, is precisely what 10.07TFLOPS.
So, the performance of the latest Intel i9 9900K is how much? Less than 1TFLOPS. The 2080 video card and 9900K price is about the same. Therefore, in the actual depth of learning, by the time it takes to GPU,
often one or two orders of magnitude reduction. The large deep learning model calculations, often is a multi-card parallel, take days or months. This time, with the CPU is clearly inappropriate.
Today, with the launch of GPGPU, GPU computing is not just a graphics device, it is a good tool used to make the numerical calculation. Likewise, but also because of the rapid development of the GPU, has brought prosperity over the past 10 years, the depth of learning
V. Summary extension
This lesson there, we are talking about, GPU is not the beginning of a "programmable" capability, programmers can only be designed graphics rendering need to use to configure. With the advent of "programmable pipeline", the
programmer can handle to realize their algorithms vertex processing and fragment. In order to further improve the utilization of GPU hardware inside the chip, Microsoft XBox 360 which, for the first time introduced a "unified shader architecture" so
get GPU has become a "universal computing" capability architecture.
Then, we proceed from the hardware of a CPU, GPU removed for nothing out of order execution and branch prediction circuit used to be thin. Then, based on the vertex processing and rendering pipeline fragment processing which is parallel to the natural.
We can add a lot of cores in the GPU inside.
And because our pipelines inside, the entire instruction process is the same, we have introduced in the SIMD CPU and similar SIMT architecture. This change, further increasing the number of GPU ALU inside.
Finally, do not suffer in order to enable GPU pipeline stalls, we are in the same GPU computing core inside, plus more execution context, the GPU always busy.
GPU inside multicore, the ALU, combined with multi-Context, it makes a strong parallelism. The same architecture GPU, if just to make numerical calculation, count ten times the CPU power of the same price or more.
And this powerful computing capabilities, as well as "unified shader architecture", making GPU computing model is very suitable for deep learning, which is the massive computing, parallel easy, and there is not much logic control branch.
Use GPU-depth learning, training time is often able to deep learning algorithms, shortened by one, or even two orders of magnitude. The GPU is now also increasingly used in a variety of scientific computing and machine learning, not just used on a graphics rendering.