In solving the problem of classification, evaluation can simply choose not too much. But the basic 2 can be divided into two categories, we are speaking channel said today
- Based on a probability threshold in the threshold determination accuracy of prediction
- Model to measure the overall performance evaluation (at various thresholds) of
Before said indicators, in all cases first encountered classification problems will simply go over. 36 degrees Beijing Let's take an example of a cool thing - we predict it will rain! The horizontal axis is the predicted probability from 0-1, the red part is no rainy days (negative sample), the blue part of rainy days (positive samples). In a real situation it is difficult to find a perfect division classifier positive and negative samples, so we can see by the middle part, the presence of positive and negative samples in predicting the probability of coincidence, that is, where there will be mistakes, whether we thresholds card sample prediction.
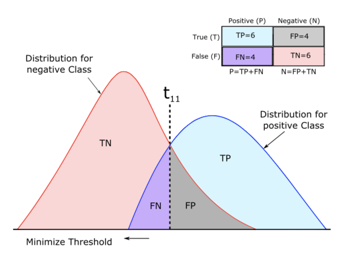
Distribution of the above four cases, a confusion matrix can simply be summarized

TP: positive forecast & real positive
FP: predictive real positive & negative
TN: & forecast negative real negative
FN: to predict the true positive & negative
Based on the index threshold
Classification model output is the probability that each sample is positive, we must first convert into a 0/1 probability forecast. Given a threshold value, we predict a probability greater than a threshold sample prediction is positive, smaller than negative. Then four cases above confustion matrix inside will appear. How do we model to evaluate performance?
Novice perspective - Accuracy!
This should be the first to know that most people of evaluation, it is the mix of positive and negative samples to evaluate the overall classification accuracy.
\[Accuracy = \frac{TP + TN}{TP + TN + FN + FP}\]
With a veteran will be able to see all the tutorial inside Imbalance Sample example to tell you, if you are only 1% of the positive samples, that all your prediction accuracy rate is negative is the 99% it - so simple and naive ~. ~
Accuracy is not of course can not be used, and the proportion of positive samples together can compare also seen some of the information. But Accuracy is indeed more suitable for positive and negative samples 55 to open, and forecast the situation for more than a positive sample.
Accuracy know ye considered to be all right, in solving practical problems, they tend to use more directional indicators, but usually also selected more than two indicators because there are often trade-off between different indicators
When the goal is to accurately predict the positive samples - precision, recall, F1
From the perspective of precision forecast predicted a positive measure of accuracy, recall from the perspective of the true distribution measure is positive predictive accuracy. there is precision and recall trade-off, you want to pick out the more positive samples, must bear the risk of a positive forecast for the accuracy of decline. For example when the plane through security, you want to ensure that dangerous goods are basically identified, it will certainly have to bear a certain rate of false positives. However, in this context apparently found no dangerous items miscarriage of justice than let passengers check again to open the package to be more important.
\[ \begin{align} precision &= \frac{TP}{TP+FP} \\ recall &= \frac{TP}{TP+FN} \end{align} \]
Since there are trade-off, it will generally be integrated with the composite index of two indicators - Fl Score
\ [= Fl \ FRAC. 1} {{\ FRAC. 1 {{}} + Precision \ FRAC. 1 {{}}} = Recall \ frac {precision * recall} { precision + recall} \]
In fact, simple point directly to the precision, recall averaging can be used as a composite index, but F1 by taking the inverse of the way first and then averaged to avoid precision equal to 0 or recall occurs such extreme circumstances
When the goal is to accurately predict the true distribution - sensitivity (recall), specifity, fpr
sensitivity, sepcifity both from the perspective of the real distribution, respectively, to measure the positive / negative sample prediction accuracy. The pair with the most common medical tests, a measure of the probability of actual ill / sick people were not properly tested. Properly test a sick person is very important, but not the right to exclude a person sick is also very important.
\[ \begin{align} sensitivity &= recall \\ specifity & =\frac{TN}{TN + FP} \\ \end{align} \]
If specifity very strange to many people, then it must know a lot of people brothers fpr. fpr and recall (tpr) together form a ROC curve. The tradeoff for this same logic to explain that medical tests, doctors want to miss neither the patient's condition (recall), or else itself did not want to scare people sick sick (fpr).
\ [Fpr = \ frac {FP } {TN + FP} = 1- specifity \]
And threshold associated frequently used indicators is almost these. Calculating these indicators is dependent on the determination threshold value, it is often used in the application validation set come ambassador F1 / accuracy of the maximum threshold value, and then applied to the test set, then the test set F1 / accuracy to evaluate the performance of the model. Here are a few applications of the index kaggle game
- F1 score
https://www.kaggle.com/c/quora-insincere-questions-classification/overview/evaluation - accuracy
https://www.kaggle.com/c/titanic/overview/evaluation
But beginning used thresholds and associated evaluation sometimes after the model has been determined. The first step in determining the model, often still need some indicators can be integrated to measure the overall performance of the model. simple! rough! What do the whole curve threshold, you give me the number would be finished!
Comprehensive Evaluation Index
Comprehensive evaluation of these indicators are basically re-processing of the product. Corresponding kaggle game will be continuously updated.
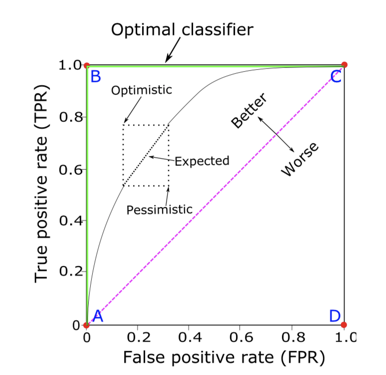
tpr(recall) + fpr = ROC-> AUC
With the threshold drops from 1-0, we expect a positive sample will gradually become more correctly screened positive samples will be gradually increased, but the negative samples are false positive probability will gradually rise.
Traversing the entire process threshold may be represented by ROC curve, the horizontal axis is the false positive rate (FPR), and the vertical axis is the accuracy (tpr / recall / sensitivity). But you want to directly compare the two classifiers who ROC curve will be a bit difficult, so we use a scaler to describe the ROC curve is AUC - Area under curve. The larger the area under the ROC curve closer to perfect classifier, and a diagonal of 50% plus or minus a random guess AUC can be obtained.
Kaggle link https://www.kaggle.com/c/santander-customer-transaction-prediction/overview/evaluation
AUC applies to positive and negative samples relative balance of the situation, and the accuracy of the prediction probability model does not require classification of the case. See articles [combat]
precision + recall = AUCPR(AP)
ROC-AUC and ideas above. As the threshold value decreases from 1 to 0, the prediction is positive samples increases, correctly screened positive samples increase, but positive predictive accuracy decreases.
In this way we get PR curve, and the area under the curve AUCPR. AUCPR sometimes also referred to as AP, recall that averaged values of all corresponding precision. At first glance I was fooled, this has been treated as two concepts in mind. But a written formula, the mother maybe it is not a thing.
\ [AUCPR = \ sum_1 ^ K \ Delta {r (k)} * p (k) = \ int_o ^ 1 {p (r) dr} = AP \]
AP 刚好弥补AUC曲线的不足,适用于正负样本imbalance的情况,或者我们更关心模型在正样本上表现的情况。但AP同样不能保证模型预测概率的准确率。详见【实战篇】
cross-entropy loss
cross-entropy放在这里会有点奇怪,因为本质上它是和这里其他所有指标都不同的存在。其他的评价指标评价的是0/1的分类效果,或者更准确说是对排序效果(根据阈值把预测值从大到小分成0/1两半)进行评价。但是cross-entropy是直接对预测概率是否拟合真实概率进行评价。
\[ L = -\sum_{i=1}^N y_i * log p_i + (1-y_i) * log(1-p_i) \]
kaggle链接 https://www.kaggle.com/c/statoil-iceberg-classifier-challenge/overview/evaluation
cross-entropy弥补了AP和AUC的不足。如果分类目标其实是获得对真实概率的估计的话,使用cross-entropy应该是你的选择。详见【实战篇】
*Mean F1 Score
kaggle链接 https://www.kaggle.com/c/instacart-market-basket-analysis/overview/evaluation
第一次见到这个指标是在Instacart的kaggle比赛里面。这里的mean不是指的对所有阈值下的F1求平均值而是对每个order_id的多个product_id求F1,再对所有order_id的F1求平均,有点绕...
之所以把这个评价指标也放在这里是因为这个特殊的评价方法会对你如何split训练集/测试集,以及如何选定最优的阈值产生影响。有兴趣的可以来试一试,反正我觉得自己是把能踩的坑都踩了一个遍,欢迎大家一起来踩坑 >_<
Reference
- Alaa Tharwat,Classification assessment methods,Applied Computing and Informatics
- Nan Ye,Kian Ming A. Chai,Wee Sun Lee,Hai Leong Chieu,Optimizing F-Measures: A Tale of Two Approaches,
- https://en.wikipedia.org/wiki/Confusion_matrix