Article Directory
- Question1: Briefly introduce Hbase?
- Answer1:
- Hbase is a distributed database solution that solves the high-speed storage and reading of massive data through a large number of cheap machines
- HBase column storage
- The core concept of Hbase
- Question2: Talk about the core architecture of Hbase?
- Answer2:
- Question3: What is the writing process of Hbase?
- Answer3:
- Question4: Introduce the scene that triggers MemStore flashing when writing in Hbase?
- Answer4:
- Question5: Talk about the difference between Hbase and Cassandra?
- Answer5:
Interview-oriented blogs are presented in Q / A style.
Question1: Briefly introduce Hbase?
Answer1:
Hbase is a distributed database solution that solves the high-speed storage and reading of massive data through a large number of cheap machines
base is a distributed, column-oriented open source database (in fact, it is precisely for column families). HDFS provides reliable low-level data storage services for Hbase, MapReduce provides high-performance computing capabilities for Hbase, and Zookeeper provides stable services and failover mechanisms for Hbase. Therefore, we say that Hbase is a high-speed storage and reading of massive data through a large number of cheap machines Distributed database solution.
HBase column storage
Hbase uses columnar storage. One of the important benefits of the columnar approach is that, because the selection rules in queries are defined by columns, the entire database is automatically indexed.
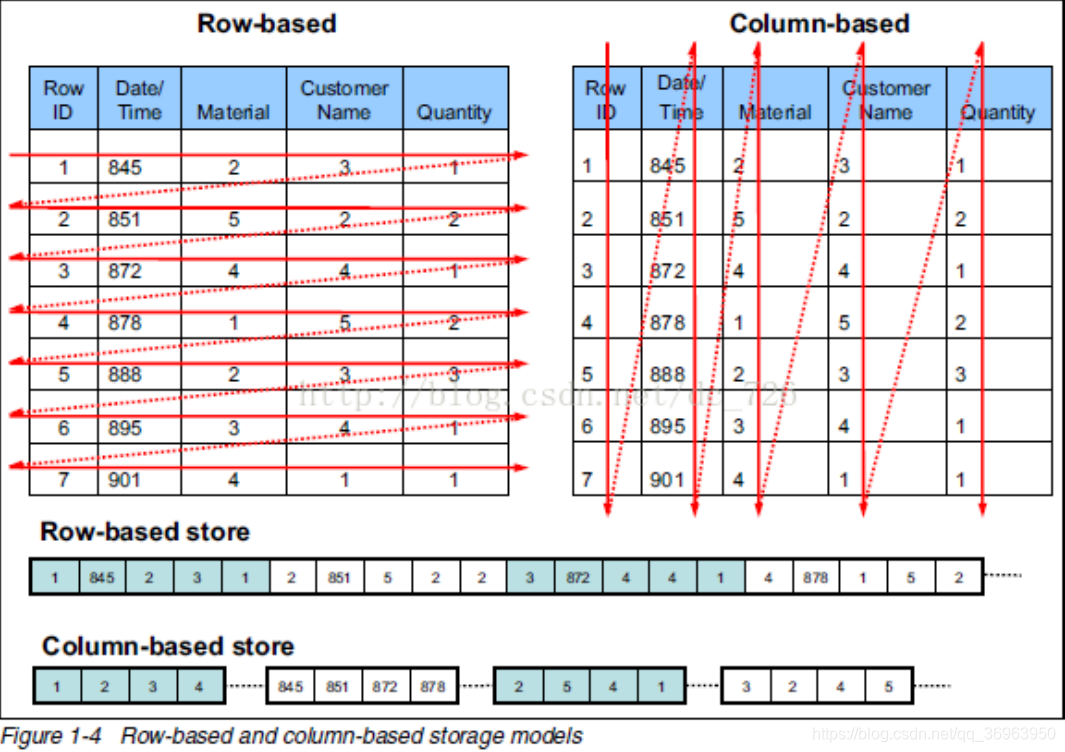
The column storage here actually refers to column family storage, and Hbase stores data according to column families. There can be a lot of columns under the column family, and the column family must be specified when creating the table. In order to deepen the understanding of the Hbase column family, the following is a simple relational database table and Hbase database table:
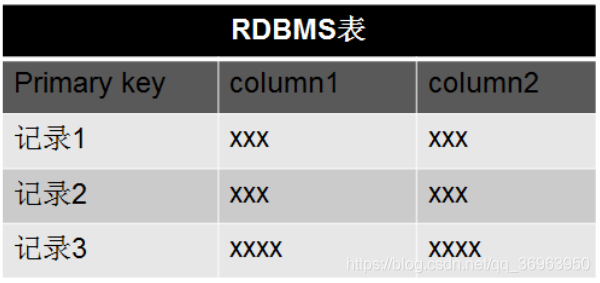
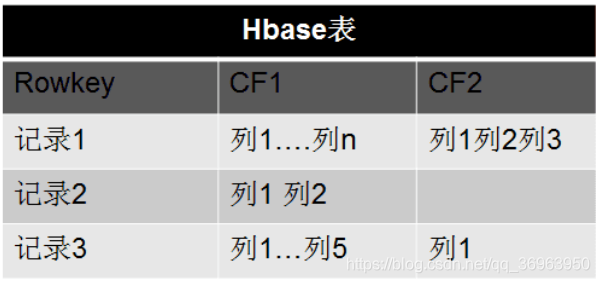
The core concept of Hbase
1、Column Family 列族
Column Family is also called column family. Hbase divides data storage by column family. Column family can contain any number of columns below to achieve flexible data access. When creating a Hbase table, you must specify the column family. Just like the specific columns must be specified when the relational database is created. The more column families in Hbase, the better. The official recommendation is that column families should be less than or equal to 3. The scenario we use is generally 1 column family.
2. Rowkey (Rowkey query, Rowkey range scan, full table scan)
The concept of Rowkey is exactly the same as the primary key in mysql. Hbase uses Rowkey to uniquely distinguish a row of data. Hbase only supports 3 query methods: single row query based on Rowkey, range scan based on Rowkey, and full table scan.
3. Region partition
Region: The concept of Region is similar to the partitioning or sharding of relational databases. Hbase will allocate the data of a large table to different regions based on the different ranges of Rowkey. Each region is responsible for a certain range of data access and storage. In this way, even if it is a huge table, because it is cut to a different region, the access delay is very low.
4. Multiple versions of TimeStamp
TimeStamp is the key to achieving multiple versions of Hbase. Use different timestame in Hbase to identify different versions of data corresponding to the same rowkey row. When writing data, if the user does not specify the corresponding timestamp, Hbase will automatically add a timestamp, the timestamp and the server time remain the same. In
Hbase, the data of the same rowkey is arranged in reverse order of timestamp. By default, the latest version is queried, and the user can read the data of the old version with the value of the specified timestamp.
Question2: Talk about the core architecture of Hbase?
Answer2:
Hbase is composed of several components such as Client, Zookeeper, Master, HRegionServer, and HDFS.
The Hbase architecture is shown below:
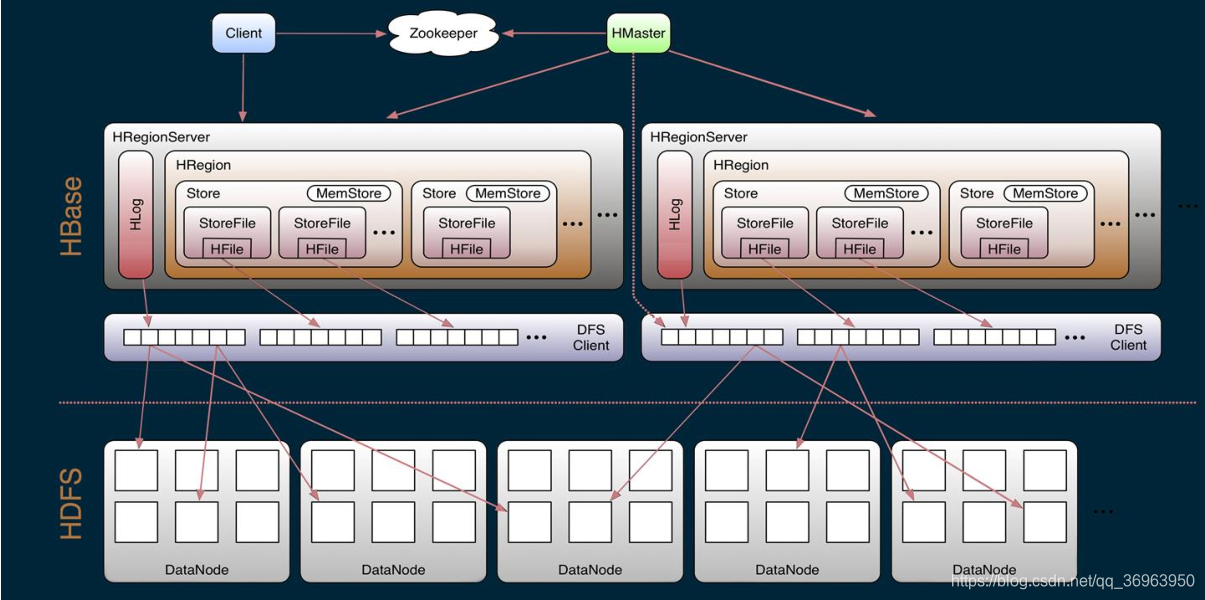
1. Hbase component: Client
Client includes an interface to
access Hbase. In addition, Client also maintains a corresponding cache to speed up Hbase access, such as cache.META. Metadata information.
2. Hbase component: Zookeeper
Hbase uses Zookeeper to do master high availability, RegionServer monitoring, metadata entry,
and cluster configuration maintenance. The specific work is as follows:
- Use Zookeeper to ensure that only one master is running in the cluster. If the master is abnormal
, a new master will be generated through the competition mechanism to provide services - Use Zookeeper to monitor the status of RegionServer. When RegionSevrer is abnormal
, notify Master RegionServer about the upper and lower limits through callback - A unified entry address for storing metadata through Zookeeper.
3. Hbase component: Hmaster
The main responsibilities of the master node are as follows:
- Assign Region to RegionServer
- Maintain load balancing of the entire cluster
- Maintain the metadata information of the cluster to discover the failed region, and allocate the failed region to the normal RegionServer. When the RegionSever fails, coordinate the corresponding Hlog split.
4. Hbase component: HregionServer
HregionServer is directly connected to the user's read and write requests, and is a real "work" node. Its functions are summarized as follows:
- Manage the region assigned by the master
- Handle read and write requests from the client
- Responsible for interacting with the underlying HDFS, storing data to HDFS
- Responsible for the split after the Region becomes larger
- Responsible for the merge of Storefile
5. Hbase component: HDFS
HDFS provides Hbase with the ultimate low-level data storage service, and provides Hbase with high availability (Hlog is stored in
HDFS).
6. Region addressing mode (via zookeeper .META)
Region addressing mode, as shown below:
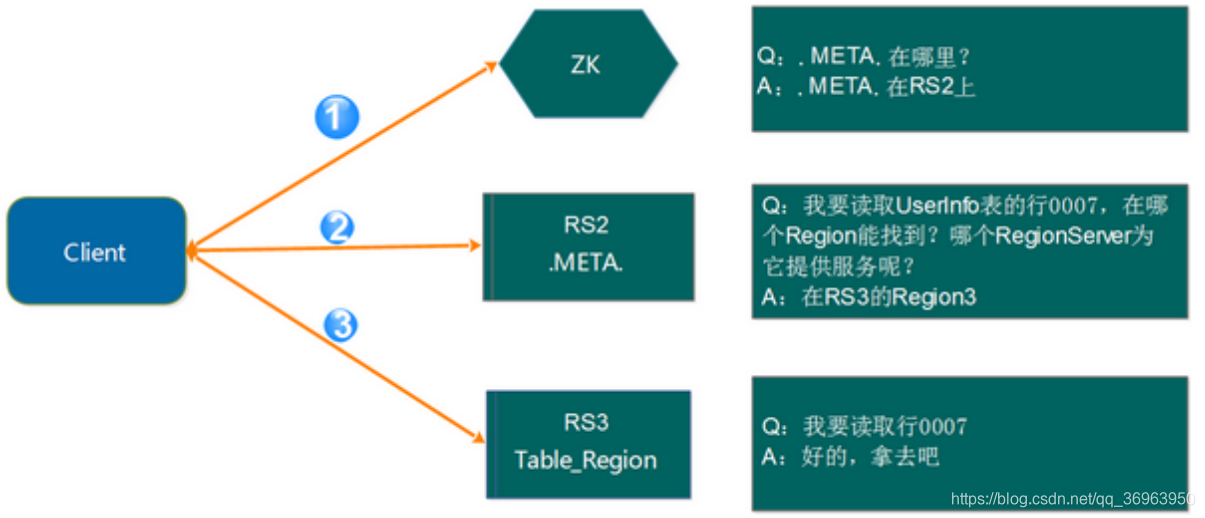
Step 1: Client requests ZK to obtain the address of the RegionServer where .META. Is located.
Step 2: The client requests the RegionServer where .META. Is located to obtain the
address of the RegionServer where the access data is located. The client caches the relevant information of .META. For the next quick access.
Step 3: The Client requests the RegionServer where the data is located to obtain the required data.
Question3: What is the writing process of Hbase?
Answer3:
Hbase write process, as shown below:
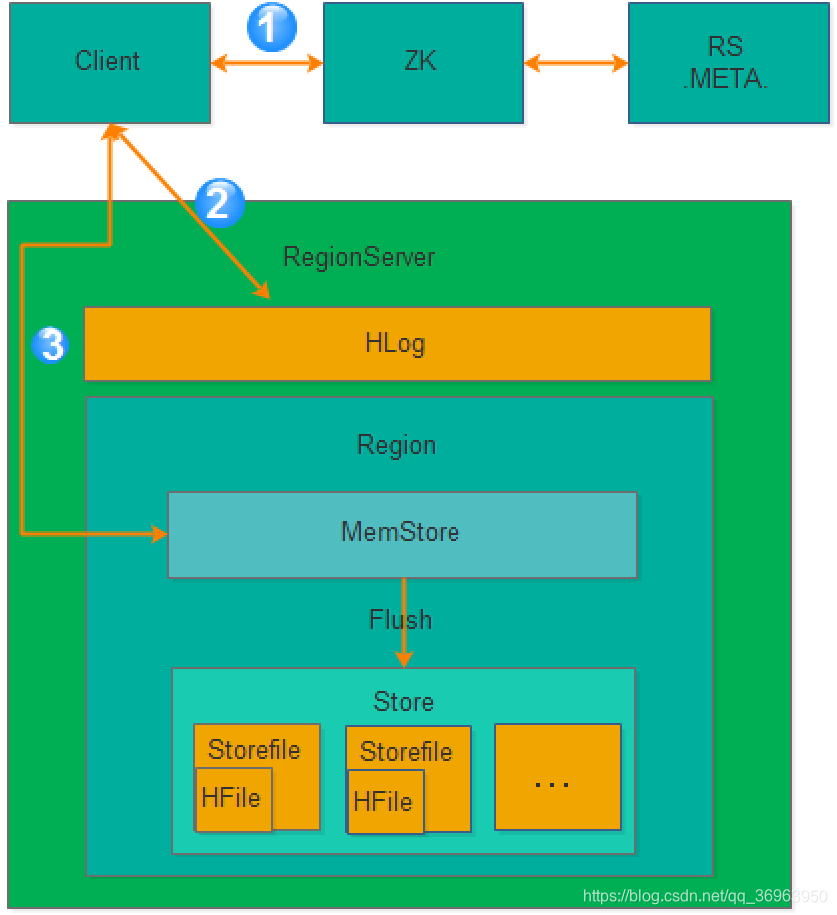
As you can see from the picture above, there are three steps to the atmosphere:
Step 1: Obtain the RegionServer
Client to obtain the RegionServer where the region where data is written is located.
Step 2: Request to write Hlog.
Request to write Hlog. Hlog is stored in HDFS. When the RegionServer is abnormal, you need to use Hlog to recover data.
Step 3: Request to write MemStore
Request to write MemStore, only when writing Hlog and writing MemStore are successful, the request writing is completed. MemStore will gradually flash to HDFS later.
Question4: Introduce the scene that triggers MemStore flashing when writing in Hbase?
Answer4:
In order to improve the write performance of Hbase, when a write request is written to MemStore, it will not be flashed immediately. Instead, it will wait for a certain time to perform the brush operation, which is summarized in the following scenarios:
1. Global memory control
This global parameter is used to control the overall memory usage. When all memstores account for the largest proportion
of the entire heap , it will trigger the flashing operation. This parameter is hbase.regionserver.global.memstore.upperLimit, which defaults to 40% of the entire heap memory. But this does not mean that the flashing operation triggered by global memory will lose all MemStores, but is controlled by another parameter hbase.regionserver.global.memstore.lowerLimit, which defaults to 35% of the entire heap memory. When flushing to all memstore accounts for 35% of the entire heap memory, stop flashing. This is mainly to reduce the impact of flash disk on the business and achieve the purpose of smoothing the system load.
2. MemStore reaches the upper limit.
When the size of MemStore reaches the size of hbase.hregion.memstore.flush.size, it will trigger the
flash disk. The default size is 128M.
3. The number of RegionServer's Hlog reaches the upper limit.
As mentioned earlier, in order to ensure the consistency of Hbase data, if there are too many Hlogs, it will cause the failure recovery time to be too long, so Hbase will limit the maximum number of Hlogs. When the maximum number of Hlogs is reached, the disk will be forcibly swiped. This parameter is hase.regionserver.max.logs, the default is 32.
4. Manual trigger
You can manually trigger the flush operation through the hbase shell or java api.
5. Triggering off the RegionServer Triggering the RegionServer
normally will trigger the flashing operation. After all the data is flushed, there is no need to use Hlog to
recover the data.
6. The Region triggers after using HLOG to restore the data.
When the RegionServer fails, the Region above it will be migrated to other normal RegionServer. After the data of the Region is restored, the brush will be triggered. Provide business access.
Question5: Talk about the difference between Hbase and Cassandra?
Answer5:
A summary of the table (HBase vs Cassandra):
| HBase | Cassandra | |
|---|---|---|
| Language | Java | Java |
| Point of departure | BigTable | BigTable and Dynamo |
| License | Apache | Apache |
| Protocol | HTTP/REST (also Thrift) | Custom, binary (Thrift) |
| Data distribution | The table is divided into multiple regions and exists on different region servers | Improved consistent hashing (virtual node) |
| Storage target | Large file | Small file |
| consistency | Strong consistency | Final consistency, Quorum NRW strategy |
| Architecture | master/slave | p2p |
| High availability | NameNode is a single point of failure for HDFS | P2P and decentralized design, no single point of failure |
| Scalability | Region Server expansion, by publishing itself to the Master, the Master evenly distributes the Region | Capacity expansion requires adjusting data distribution among multiple nodes on the Hash Ring |
| Read and write performance | Data read and write positioning may have to go through network RPCs up to 6 times, with low performance. | Data read and write positioning is very fast |
| Data conflict handling | Optimistic concurrency control | Vector clock |
| Temporary fault handling | Region Server goes down, redo HLog | Data return mechanism: When a node is down, the new data hashed to the node is automatically routed to the next node for hinted handoff. After the source node is restored, it is pushed back to the source node. |
| Permanent fault recovery | The Region Server is restored, and the master reallocates regions to it | Merkle hash tree, which synchronizes Merkle Tree through Gossip protocol to maintain data consistency between cluster nodes |
| Member communication and error detection | Zookeeper | Based on Gossip |
| CAP | 1. Strong consistency, 0 data loss. 2. Low availability. 3. Convenient expansion. | 1. Weak consistency, data may be lost. 2. High availability. 3. Convenient expansion. |
