Article Directory
- Question1: Briefly introduce Hadoop?
- Answer1:
- Question2: A brief introduction to HDFS?
- Answer2:
- Question3: Briefly introduce MapReduce?
- Answer3:
- Question4: Talk about the life cycle of Hadoop MapReduce jobs?
- Answer4:
- Question5: A brief introduction to Yarn?
- Answer5:
- Question6: What is the operation process of YARN?
- Answer6:
- Question7: Briefly explain the difference between Hadoop2 and Hadoop3?
- Answer7:
Interview-oriented blogs are presented in Q / A style.
Question1: Briefly introduce Hadoop?
Answer1:
Hadoop is a big data solution, which provides a set of distributed system infrastructure. Its core content includes hdfs and mapreduce (Attachment: hadoop2.0 is introduced to yarn, and the stable and available version is now Hadoop3.0).
hdfs is used to provide data storage, and mapreduce is used to facilitate data calculation.
- hdfs also corresponds to namenode and datanode, where namenode is responsible for saving the basic information of metadata, and datanode directly stores the data itself;
- mapreduce corresponds to jobtracker and tasktracker, where jobtracker is responsible for distributing tasks and tasktracker is responsible for performing specific tasks;
- Corresponding to the master / slave architecture, namenode and jobtracker should correspond to master, datanode and tasktracker should correspond to slave. Whether it is hdfs or mapreduce, between the master and slave nodes are confirmed to survive by heartbeat.
Question2: A brief introduction to HDFS?
Answer2:
HDFS architecture diagram, as shown below:
In HDFS, NameNode and Secondary NameNode are Masters, and all Datanodes are Slaves.
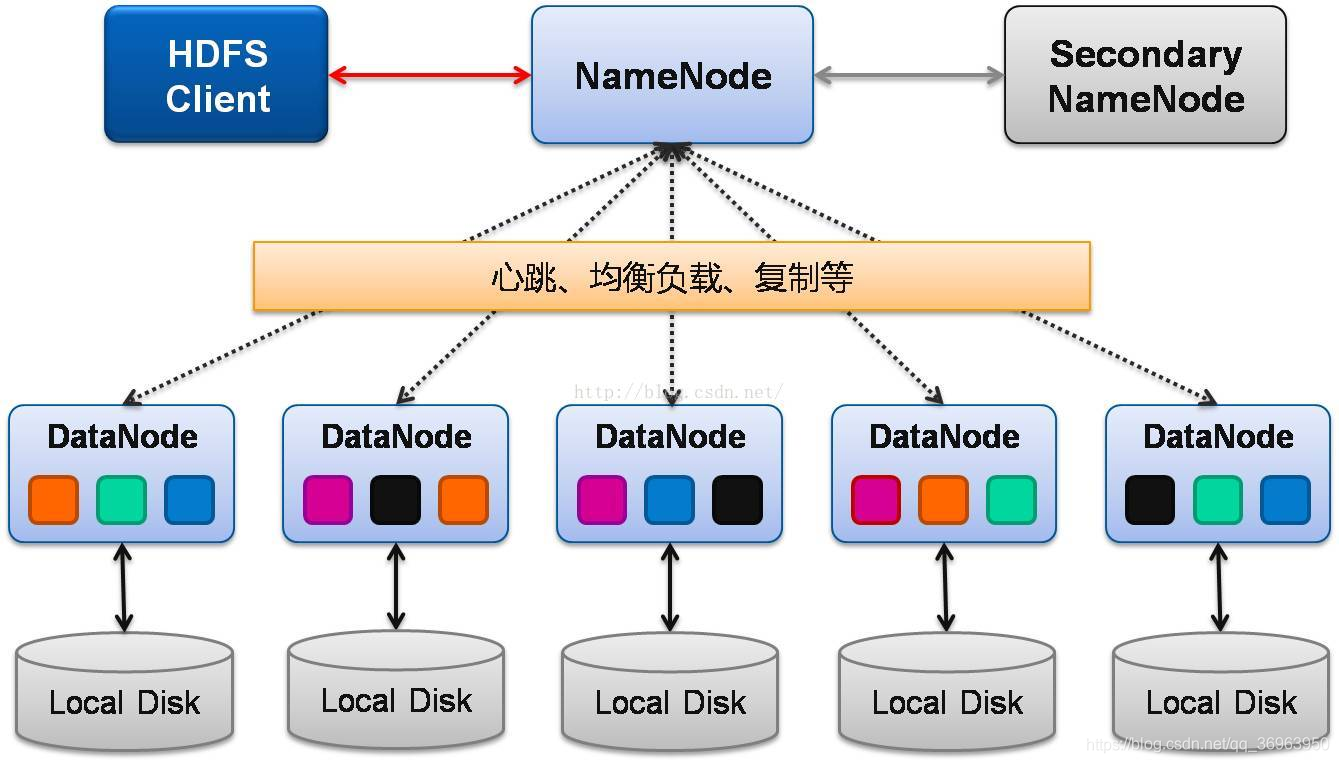
1、Client
Client (representing user) accesses files in HDFS by interacting with NameNode and DataNode. Client provides a POSIX-like file system interface for users to call.
2 、 NameNode
Function: Responsible for managing the HDFS directory tree and related file metadata information.
There is only one NameNode in the entire Hadoop cluster. It is the "master" of the entire system and is responsible for managing the HDFS directory tree and related file metadata information. This information is stored on the local disk in the form of "fsimage" (HDFS metadata image file) and "editlog" (HDFS file change log), and is reconstructed when HDFS restarts. In addition, the NameNode is also responsible for monitoring the health status of each DataNode. Once a DataNode is found to be down, the DataNode is moved out of HDFS and the data on it is backed up again.
3 、 Secondary NameNode
Function: Regularly merge fsimage and edits logs and transfer them to NameNode.
The most important task of Secondary NameNode is not to perform hot backup for NameNode metadata, but to periodically merge fsimage and edits logs and transfer them to NameNode. It should be noted here that in order to reduce the pressure on the NameNode, the NameNode will not merge fsimage and edits and store the files on the disk, but it will be done by the Secondary NameNode.
4, DataNode
Function: Responsible for actual data storage, and regularly report data information to NameNode.
Generally speaking, each Slave node is installed with a DataNode, which is responsible for the actual data storage and regularly reports the data information to the NameNode. DataNode organizes file content with a fixed-size block as the basic unit. By default, the block size is 64MB. When a user uploads a large file to HDFS, the file will be divided into several blocks and stored in different DataNodes. At the same time, in order to ensure reliable data, the same block will be written to several blocks in a pipelined manner (default Yes 3, this parameter can be configured) on different DataNodes. This process of storing files after cutting is transparent to users.
Question3: Briefly introduce MapReduce?
Answer3:
Hadoop MapReduce uses the Master / Slave (M / S) architecture, as shown in the figure.
In Map Reduce, JobTracker is Master, and all TaskTrackers are Slave.
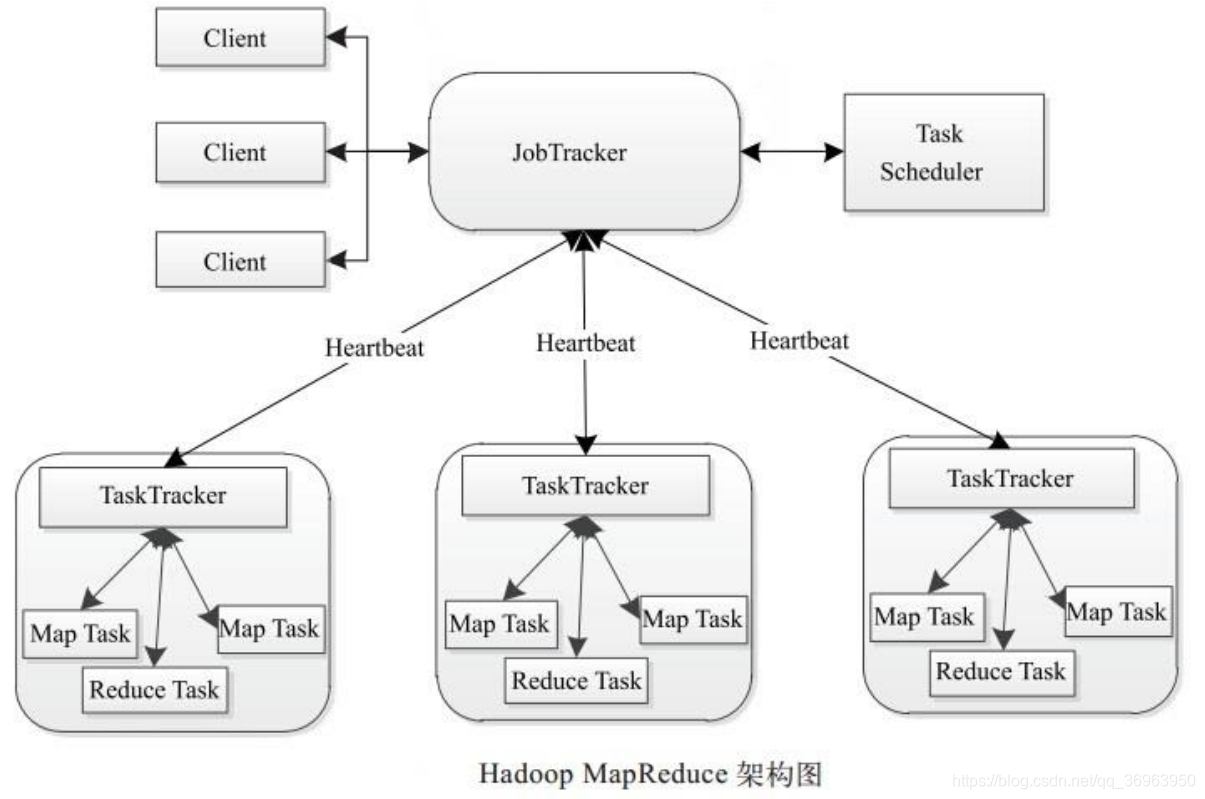
MapReduce is mainly composed of the following components: Client, JobTracker, TaskTracker and Task. The following describes these components separately.
1、Client
The MapReduce program written by the user is submitted to the JobTracker through the Client; at the same time, the user can view the running status of the job through some interfaces provided by the Client.
Within Hadoop, a "job" (Job) is used to represent a MapReduce program. A MapReduce program can correspond to several jobs (Job), and each job (Job) will be decomposed into several Map / Reduce tasks (Task).
2 、 JobTracker
JobTracker is mainly responsible for resource monitoring and job scheduling. JobTracker monitors the health status of all TaskTrackers and jobs. Once a failure is found, it will transfer the corresponding task to other nodes; at the same time, JobTracker will track the progress of the task execution, resource usage and other information, and inform the task scheduler , And the scheduler will select the appropriate task to use these resources when the resources become idle.
In Hadoop, the task scheduler is a pluggable module, and users can design the corresponding scheduler according to their needs.
3、TaskTracker
TaskTracker will periodically report the usage of resources on the node and the progress of the task to JobTracker through Heartbeat, and at the same time receive the commands sent by JobTracker and perform corresponding operations (such as starting a new task, killing the task, etc.)
TaskTracker uses "slot" to divide the amount of resources on this node. "Slot" stands for computing resources (CPU, memory, etc.). A task has a chance to run after it gets a slot, and the role of the Hadoop scheduler is to allocate idle slots on each TaskTracker to the Task. Slots are divided into two types: Map slot and Reduce slot, which are used by MapTask and Reduce Task respectively.
In this way, TaskTracker limits the concurrency of Task by the number of slots (configurable parameters).
4、Task
Task is divided into two types: Map Task and Reduce Task, both started by TaskTracker.
Compared with HDFS, which stores data in blocks of fixed size, MapReduce's processing unit is split. Split is a logical concept. It only contains some metadata information, such as the starting position of the data, the length of the data, and the node where the data is located. Its division method is completely decided by the user.
But it should be noted that the number of splits determines the number of Map Tasks, because each split will be handled by a Map Task.
5. Map Task execution process
The Map Task execution process is shown in the figure:
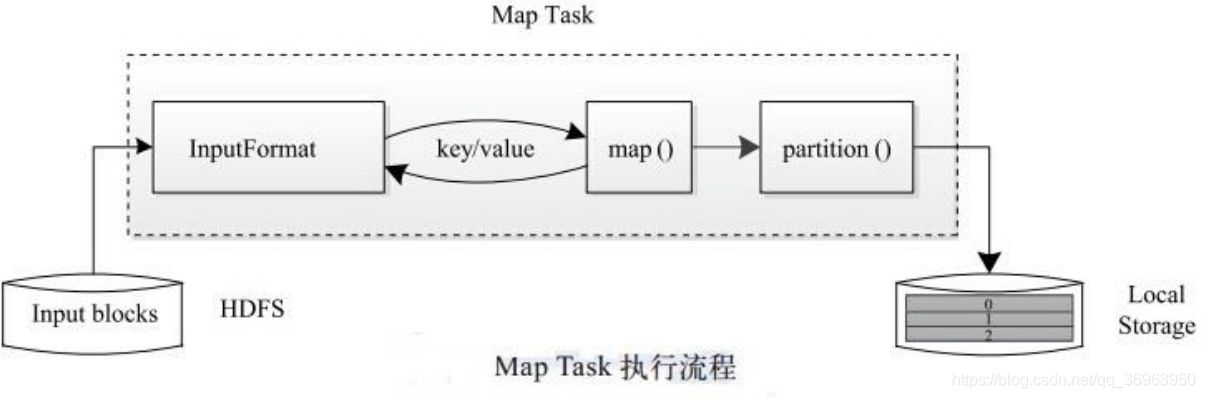
As can be seen from the figure, the Map Task first parses the corresponding split iteration into key / value pairs, and then calls the user-defined map () function for processing, and then the temporary data is divided into several partitions (each partition will be a Reduce Task processing), and finally store the temporary results on the local disk.
6. Reduce Task execution process
In the above Map Task execution flowchart, the middle step is that the temporary data is divided into several partitions. In fact, each partition will be processed by a Reduce Task, so how does the Reduce Task handle it?
The implementation process of Reduce Task is divided into three stages:
- Read the intermediate results of MapTask from a remote node (called "Shuffle stage");
- Sort key / value pairs by key (called "Sort stage");
- Read <key, value list> in turn, call the user-defined reduce () function to process, and store the final result on HDFS (called the "Reduce stage").
Question4: Talk about the life cycle of Hadoop MapReduce jobs?
Answer4:
Step 1: Job submission and initialization
Job submission: After the user submits the job (ie, Job), the JobClient instance first uploads the job-related information, such as the program jar package, job configuration file, and sharding meta-information file, to the distributed file system (usually HDFS). Among them, the fragment meta information file records the logical location information of each input fragment. Then JobClient notifies JobTracker through RPC (ie Romote Procedure Call, remote procedure call).
Job initialization: After JobTracker receives a new job submission request, the job scheduling module initializes the job: creates a JobInProgress object for the job to track the job status, and JobInProgress creates a TaskInProgress object for each Task to track each task TaskInProgress may need to manage multiple "Task Run Attempts" (called "Task Attempt").
Step 2: Task scheduling and monitoring
Since the task scheduling and monitoring functions are completed by JobTracker, TaskTracker periodically reports the resource usage of this node to JobTracker through Heartbeat. Once idle resources appear, JobTracker will select a suitable task to use the idle resources according to a certain strategy. Completed by the task scheduler. The task scheduler is a pluggable independent module and has a two-layer architecture, that is, the job (ie Job) is selected first, and then the task (ie Task) is selected from the job (Job). Among them, the task selection needs to be considered Data locality.
In addition, JobTracker tracks the entire running process of the job and provides a comprehensive guarantee for the successful operation of the job. First, when the TaskTracker or Task fails, the calculation task is transferred. Second, when the execution progress of a Task lags far behind other Tasks of the same job, the same Task is started for it, and the Task result with fast calculation is selected as the final result.
Step 3: Prepare the task running environment
The preparation of the operating environment includes JVM startup and resource isolation, all implemented by TaskTracker.
JVM startup: TaskTracker starts an independent JVM for each Task to avoid different Tasks affecting each other during operation;
resource isolation: TaskTracker uses operating system processes to achieve resource isolation to prevent Task from abusing resources.
Step 4: Task execution
After TaskTracker prepares the running environment for Task, it will start Task. During operation, the latest progress of each Task is first reported by the Task to the TaskTracker via RPC, and then reported by the TaskTracker to the JobTracker.
Step 5: Homework completed
After all tasks are executed, the entire job (ie, Job) is successfully executed.
Question5: A brief introduction to Yarn?
Answer5:
YARN is a framework for resource management and task scheduling. It mainly includes three modules: ResourceManager (RM), NodeManager (NM), and ApplicationMaster (AM). Among them, ResourceManager is responsible for the monitoring, allocation and management of all resources; NodeManager is responsible for the maintenance of each node; ApplicationMaster is responsible for the scheduling and coordination of each specific application.
For all applications, RM has absolute control and allocation of resources. Each AM will negotiate resources with RM, and communicate with NodeManager to execute and monitor tasks.
The relationship between several modules is shown in the figure.

For the explanation of the above figure: the
two Client client instance requests on the left, one red and one blue.
The first line, MapReduce Status, indicates the status of the current MapReduce. Each application contains a master node AM. Since the figure shows that two applications are being processed, the three red Container containers will all be processing MapReduce The state is passed to the red AM application master node, and the blue Container container also passes the current MapReduce state to the blue AM application master node.
The second line Job Submission indicates job submission, which means that the two clients on the left submit the job to RM.
The third line Node Status represents the node status. The NodeManager is responsible for the maintenance of each node. The three NodeManagers submit the node status information to the RM Global Resource Manager.
The fourth line, Resource Request, means to make resource request actions. In the figure, two AMs make resource requests to RM for their own applications.
Question 1: Is there any inclusion, juxtaposition or other relationship between AM and NM?
Answer 1: There is no relationship between AM and NM. AM corresponds to an application. An application contains an AM. NM corresponds to an internal node of Yarn. An internal node needs an NM to maintain it.
Question 2: What is the relationship between AM and RM? What is the relationship between NM and RM?
Answer 2: Because AM corresponds to an application, it will naturally send a Resource Request resource request to RM to request resources for the application; because NM corresponds to an internal node, it will naturally report Node Status node status information to RM.
ResourceManager module
- RM meaning: ResourceManager is responsible for the resource management and allocation of the entire cluster and is a global resource management system.
- RM and NM: NodeManager reports resource usage to ResourceManager in the form of heartbeat (currently mainly CPU and memory usage). RM only accepts NM's resource return information, and the specific resource processing is left to NM to handle.
- RM and AM: YARN Scheduler allocates resources according to application requests, and is not responsible for application job monitoring, tracking, running status feedback, startup, etc.
NodeManager module
- NM meaning: NodeManager is the resource and task manager on each node, it is the agent that manages this machine, is responsible for the operation of the node program, and the management and monitoring of the node resources. Each node in the YARN cluster runs a NodeManager.
- NM and RM: The NodeManager regularly reports to the ResourceManager the usage of the node's resources (CPU, memory) and the running status of the Container. When ResourceManager goes down, NodeManager automatically connects to the RM standby node.
- NM and AM: NodeManager receives and processes various requests such as Container start and stop from ApplicationMaster.
ApplicationMaster module
- AM meaning: Each application submitted by the user contains an ApplicationMaster, which can run on a machine other than ResourceManager.
- AM and RM: responsible for negotiating with the RM scheduler to obtain resources (denoted by Container).
- AM and NM: Communicate with NM to start / stop tasks.
- AM and Task Task: The task will be further allocated to internal tasks (secondary resource allocation).
- AM and Task Task: Monitor the running status of all tasks, and re-apply resources for the task to restart the task when the task fails.
Note: RM is only responsible for monitoring AM and starting it when AM fails. RM is not responsible for the fault tolerance of AM internal tasks. The fault tolerance of tasks is completed by AM.
Question6: What is the operation process of YARN?
Answer6:
- The client submits the application program to the RM, including the necessary information of the ApplicationMaster that starts the application, such as the ApplicationMaster program, the command to start the ApplicationMaster, and the user program.
- ResourceManager starts a container for running ApplicationMaster.
- The starting ApplicationMaster registers itself with the ResourceManager, and keeps a heartbeat with the RM after the startup is successful.
- ApplicationMaster sends a request to ResourceManager to apply for the corresponding number of containers.
- ResourceManager returns the container information of ApplicationMaster application. Successfully applied
containers are initialized by ApplicationMaster. After the startup information of the container is initialized, the AM communicates with the corresponding NodeManager and requests the NM to start the container. AM and NM maintain heartbeats to monitor and manage tasks running on NM. - While the container is running, ApplicationMaster monitors the container. The container reports its progress and status to the corresponding AM through the RPC protocol.
- While the application is running, the client directly communicates with AM to obtain information such as the application's status and progress updates.
- After the application runs, ApplicationMaster logs off itself to the ResourceManager and allows the container belonging to it to be taken back.
Question7: Briefly explain the difference between Hadoop2 and Hadoop3?

Answer7:
The 22 differences between hadoop2.X and hadoop3.X are as follows:
1.License
adoop 2.x-Apache 2.0, open source
Hadoop 3.x-Apache 2.0, open source
2. The minimum supported Java version
Hadoop 2.x-The minimum supported version of java is java 7
Hadoop 3.x-The minimum supported version of java is java 8
3. Fault tolerance
Hadoop 2.x-You can handle fault tolerance by copying (wasting space).
Hadoop 3.x-Erasure coding can handle fault tolerance.
4. Data balance
Hadoop 2.x-For data, balance using HDFS balancer.
Hadoop 3.x-For data, balancing uses the Intra-data node balancer, which is called through the HDFS disk balancer CLI.
5. Store Scheme
Hadoop 2.x-Use 3X copy Scheme
Hadoop 3.x-Support erasure coding in HDFS.
6. Storage overhead
Hadoop 2.x-HDFS has 200% overhead in storage space.
Hadoop 3.x-Storage overhead is only 50%.
7. Storage overhead example
Hadoop 2.x-If there are 6 blocks, then 18 blocks will take up space due to the copy scheme (Scheme).
Hadoop 3.x-If there are 6 blocks, then there will be 9 block spaces, 6 blocks, and 3 blocks for parity.
8. YARN timeline service
Hadoop 2.x-Use old timeline services with scalability issues.
Hadoop 3.x-Improve timeline service v2 and increase the scalability and reliability of the timeline service.
9. Default port range
Hadoop 2.x-In Hadoop 2.0, some default ports are Linux temporary port ranges. So at startup, they will not be able to bind.
Hadoop 3.x-But in Hadoop 3.0, these ports have moved out of the short-term range.
10. Tools
Hadoop 2.x-Use Hive, pig, Tez, Hama, Giraph and other Hadoop tools.
Hadoop 3.x-Hive, pig, Tez, Hama, Giraph and other Hadoop tools can be used.
11. Compatible file system
Hadoop 2.x-HDFS (default FS), FTP file system: It stores all data on a remotely accessible FTP server. Amazon S3 (Simple Storage Service) file system Windows Azure Storage Blob (WASB) file system.
Hadoop 3.x-It supports all front and Microsoft Azure Data Lake file systems.
12. Datanode resources
Hadoop 2.x-Datanode resources are not dedicated to MapReduce, we can use it for other applications.
Hadoop 3.x-The data node resources here can also be used for other applications.
13.MR API compatibility
Hadoop 2.x-MR API compatible with Hadoop 1.x programs, can execute
Hadoop 3.x on Hadoop 2.X -Here, MR API is compatible with running Hadoop 1.x programs for Hadoop 3.X carried out
14. Supports Microsoft Windows
Hadoop 2.x-It can be deployed on Windows.
Hadoop 3.x-It also supports Microsoft Windows.
15. Slot / Container
Hadoop 2.x-Hadoop 1 applies to the concept of slots, but Hadoop 2.X applies to the concept of containers. Through the container, we can run common tasks.
Hadoop 3.x-It also applies to the concept of containers.
16. Single point of failure
Hadoop 2.x-has SPOF function, so as long as Namenode fails, it will automatically recover.
Hadoop 3.x-has SPOF function, so as long as Namenode fails, it will automatically recover, and it can be overcome without human intervention.
17. HDFS Alliance
Hadoop 2.x-In Hadoop 1.0, there is only one NameNode to manage all Namespaces, but in Hadoop 2.0, multiple NameNodes are used for multiple Namespaces.
Hadoop 3.x-Hadoop 3.x also has multiple namespaces for multiple namespaces.
18. Scalability
Hadoop 2.x-We can scale to 10,000 nodes per cluster.
Hadoop 3.x-Better scalability. We can scale more than 10,000 nodes for each cluster.
19. Access data faster
Hadoop 2.x-Due to the data node cache, we can quickly access the data.
Hadoop 3.x-Here we can also quickly access the data through the Datanode cache.
20. HDFS snapshot
Hadoop 2.x-Hadoop 2 adds support for snapshots. It provides disaster recovery and protection for user errors.
Hadoop 3.x-Hadoop 2 also supports snapshot function.
21. Platform
Hadoop 2.x-Can be used as a platform for various data analysis, can run event processing, streaming media and real-time operations.
Hadoop 3.x-Here you can also run event processing, streaming media and real-time operations on top of YARN.
22. Cluster resource management
Hadoop 2.x-For cluster resource management, it uses YARN. It improves scalability, high availability, and multi-tenancy.
Hadoop 3.x-For clusters, resource management uses YARN with all functions.
