⭐️halo, hello everyone, first time meeting ~ I am Sister Nan ~
⭐️Inspired by some excellent public accounts recently, I hope to try to use some new methods to write a new technology sharing. In a relaxed and humorous tone, I will carry out some technical science popularization and sharing on my official account~
⭐️Originally, the article was posted on the internal technical forum of the factory, but after being encouraged by many colleagues, I tried to post it in my circle of friends, and explored some things that I had never done before~
⭐️This article can be regarded as the beginning and test the water. If the effect is good, Sister Nan will work hard to continue the series of technical science articles, and if it is a public account, you can also explore some new topics besides technology, and strive to make a A series of articles with personal characteristics and original IP~ I hope everyone will join us~

--- ---
I don't know if everyone is in the usual brick-moving career
Have you ever heard of the term " graph computing "?
But everyone must have heard of it in work reports and technical science popularization
Words like "intelligence", "artificial intelligence"

And the graph calculation we are going to talk about today
It is the hot frontier darling in the field of artificial intelligence in recent years
It is also a commonly used "big killer" in the field of risk control and anti-fraud

Before understanding graph computing
First of all, we must understand what is a " graph "

what we say today
In fact, it is a data structure used to represent the relationship between objects
Has strong abstraction and flexibility
It has strong expressive ability in terms of structure and semantics
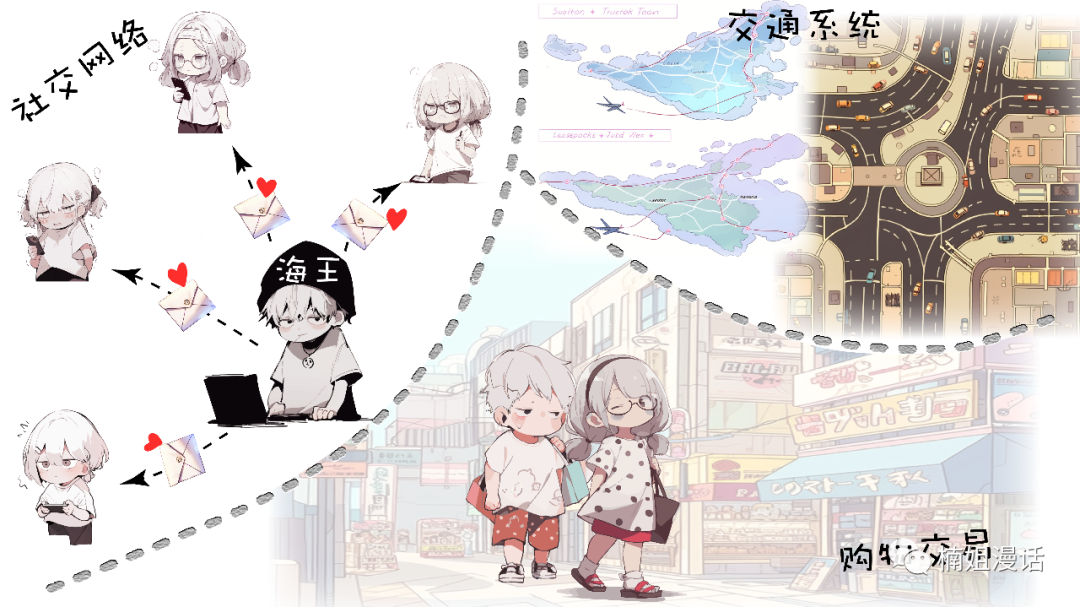
It is precisely because of the rich expressiveness of the graph structure
There are many examples in real life that can be represented as "graphs"
Such as social networks , road networks , financial transactions , etc.

Friends who are engaged in research and development or algorithm related know that
Our commonly used machine learning and deep learning algorithms
Most of them are used to process some regular, orderly, or structured data
Such as matrix, picture, text, sequence, etc.
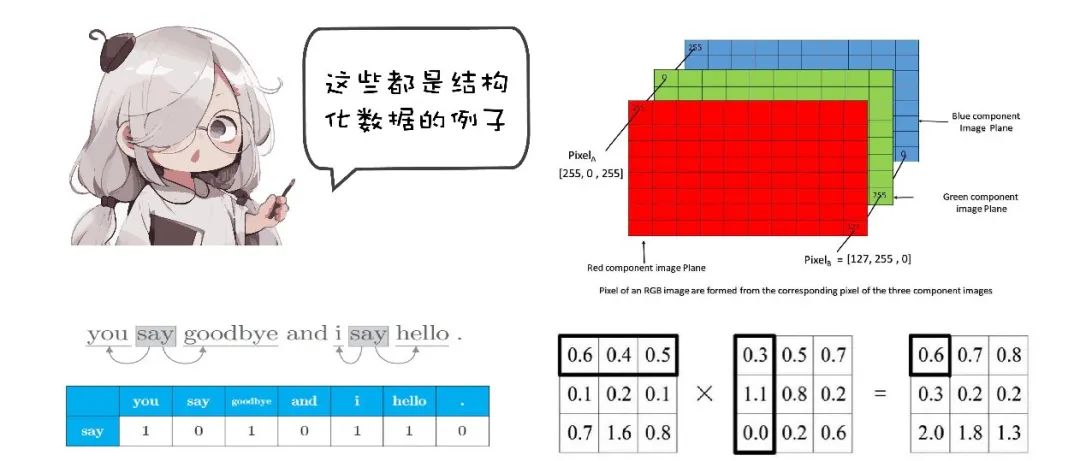
And the processed data are assumed to be independent and identically distributed
However, the nodes on the graph are naturally connected
This means that the nodes are not independent

At this point, the graph computing we are going to mention today comes
Its core is precisely to model data as a graph structure
And solve how to convert the problem solution into a computational problem on the graph structure
When the algorithm task involves association analysis between multiple individuals
Graph computing often enables problems to be solved naturally
Expressed as a series of operations and calculations on the graph structure

However, graph computing needs to solve various problems
It is difficult to solve all problems with one set of computing models
Next, we will come to the system site
Those things about graph computing
--- ★ ---

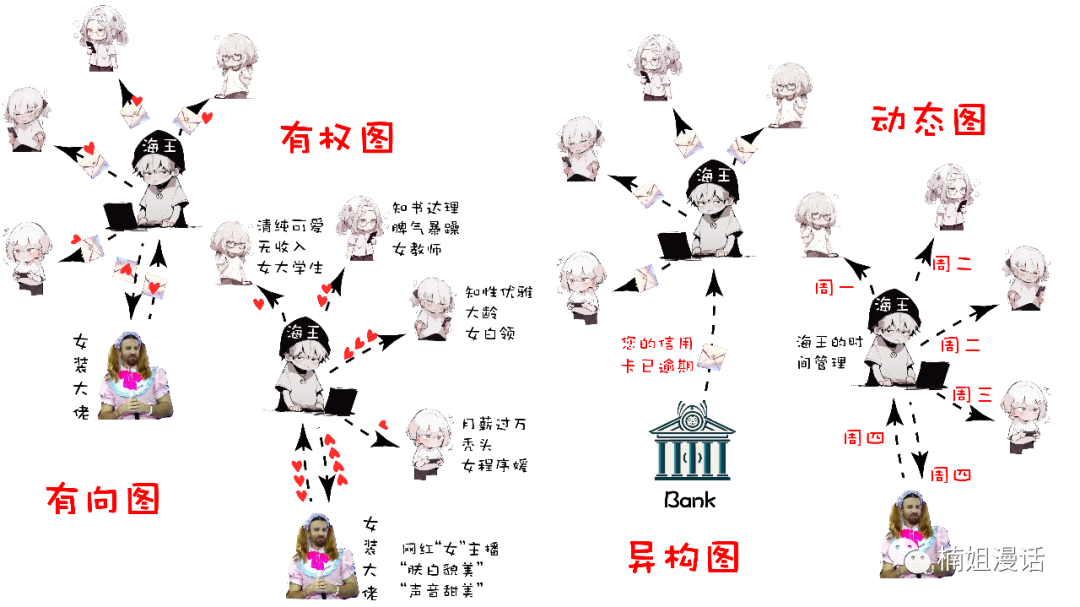
For example, by virtue of whether the edge has direction
Graphs can be divided into directed graphs and undirected graphs
Whether the edge has weight
Graphs can also be divided into weighted graphs and unweighted graphs.
Whether the vertices and edges in the graph have multiple types
Graphs can be divided into isomorphic graphs and heterogeneous graphs
Also, whether the graph structure and graph information change over time
Graphs can be divided into static graphs and dynamic graphs
" Degree " and " Neighborhood "
are two important concepts involving graph nodes
The "degree" of a node refers to the number of nodes connected to it
If it is a directed graph, it will also distinguish between "in-degree" and "out-degree"
A node's "neighbors" are other nodes connected to it

About the representation of graphs
There are still a few basic concepts that have to be mentioned
One is the " adjacency matrix "
Used to quantitatively represent the edge relationship between nodes
There are also " node features " and " edge features "
Unique numerical properties used to characterize nodes and edges

No matter how complex the graph algorithm model
are based on these basic concepts
Ask one of the most basic questions about graphs - the problem of node representation
It is how to base on the information and attributes of the above graph
Quantified representation of nodes or edges in a graph
In CV and NLP tasks
We will design CNN and RNN modules
To model the information represented by image pixels and text characters
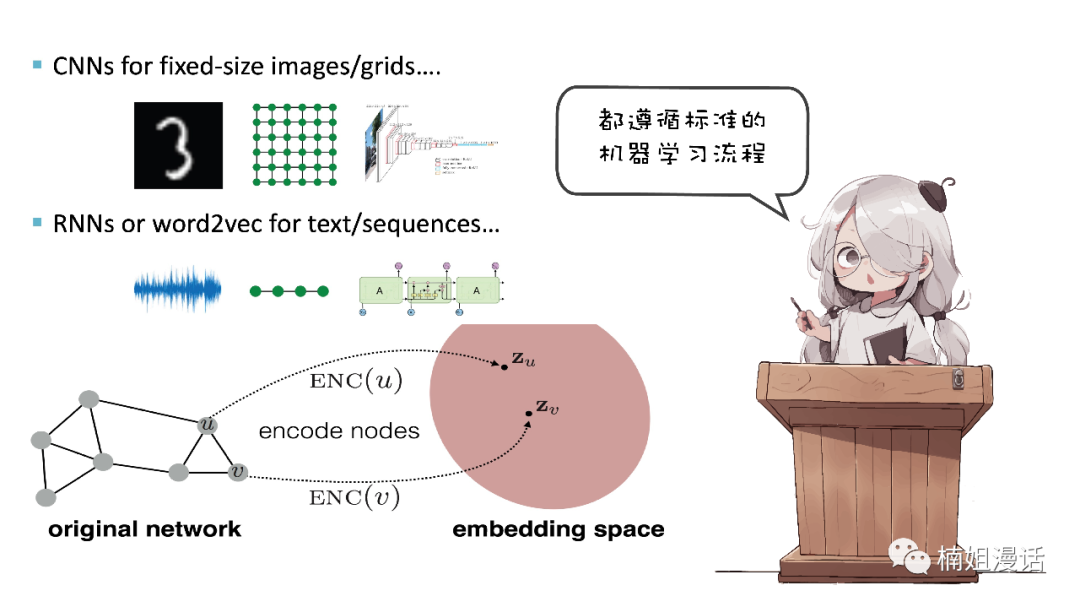
The same idea is also used in graph representation learning
With a reasonable node vector representation
We can then explore various downstream tasks
For example, to classify nodes
Find those nodes that have special behavior or properties
or community division
Find out the set of nodes with the strongest aggregation and the highest similarity
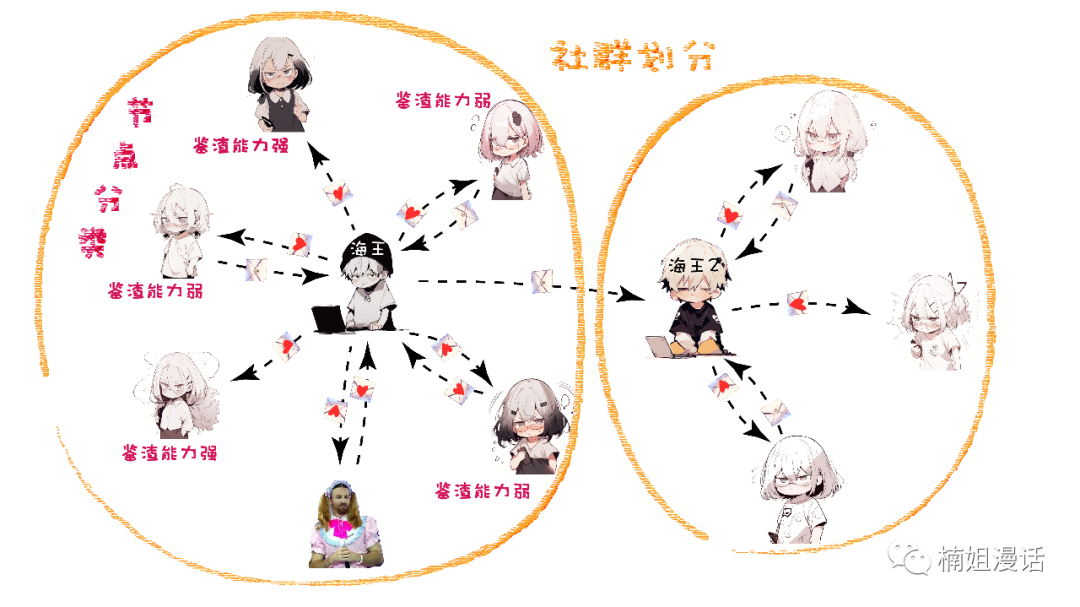
In addition, various downstream tasks such as link prediction and subgraph partitioning can also be performed.
What do you want to do with graph computing
totally depends on your actual needs

see here
congratulations
You have already started graph calculation

--- ★ ★ ---
Graph computing is not a new algorithm
If we trace its history

Euler is considered one of the greatest mathematicians in human history
For his description of the problem with the Seven Arch Bridge in Königsberg
The discipline of graph theory then emerged
In a park in Königsberg
There are seven bridges connecting the two islands in the Pregel River to the banks of the river
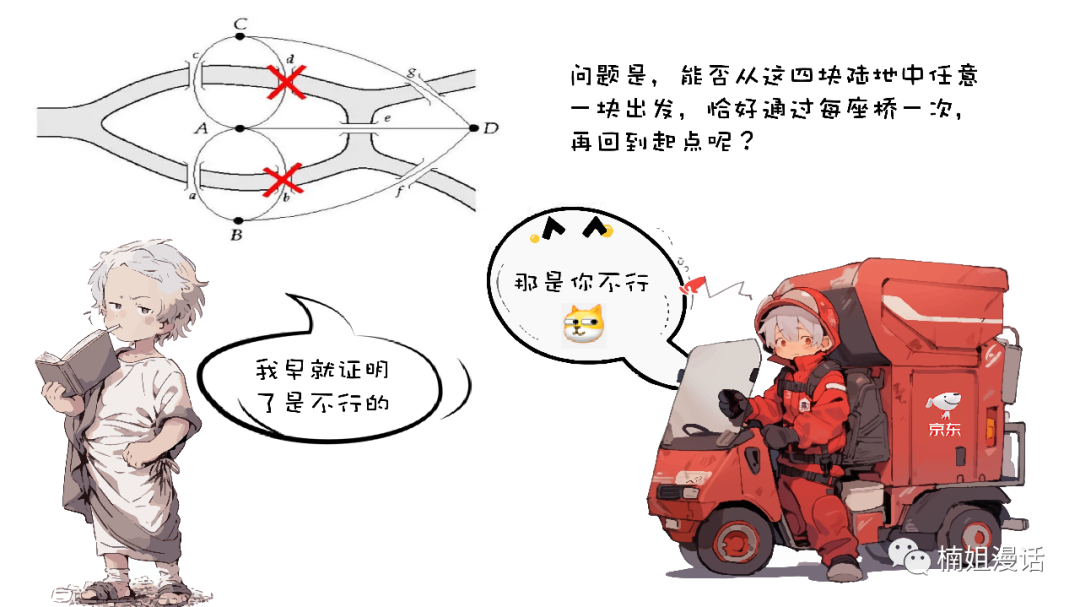
Euler studied and proved this problem in 1736
He attributed the problem to the "one stroke" problem
And prove that the one-stroke move is impossible
during his research
Abstract the land and bridge in the problem into points and edges respectively
and form a simple topological graph
introduces basic concepts about graphs

After that, an early application of graph theory appeared
- area rendering ( coloring )
With the advent of the age of great navigation from the 15th to the 17th centuries
and the rise of the nation-state concept after the French Revolution
Countries around the world are starting to create higher-resolution maps
And how to use the fewest colors in the drawing
To ensure that two adjacent areas (country, state, province)
distinguish with different colors
This problem is a classic graph theory problem

mid 19th century
Mathematicians prove 'five-color map' problem by calculating by hand
And until a full century later, in 1976,
It was only with the help of computer computing power that the feasibility of the "four-color map" was initially proved.
And after optimizing through graph calculation
Replaced the five-color map with a four-color map
The above map coloring problem is a typical NP-complete problem in mathematics

such as navigation, resource scheduling, search and recommendation engines
However, the big data framework and solutions corresponding to these scenarios
In the beginning
There is no real use of native graph storage and computing modes
In other words, people are still using columnar databases
or even document databases to solve graph theory problems
Inefficient and low-dimensional tools are used to forcefully solve complex and high-dimensional problems
Then its user experience may be poor or the input-output ratio is extremely bad

In recent years, with the development of the Internet
Knowledge graph gradually penetrates into the hearts of the people
The development of graph computing and graph databases has only begun to receive renewed attention
In the past half a century, many graph computing algorithms have come out
Including the well-known Dijkstra algorithm that appeared in 1956
Research solves the shortest path problem for graphs
Various more complex community discovery algorithms have emerged as the times require
Used to detect associations between communities, customer groups, and suspects

It is to represent each vertex in the graph as a low-dimensional vector
And make the vector able to save as much structure and content information of the graph as possible
and can be used as features for subsequent learning tasks
Such as node classification, link prediction, etc.

These works are aimed at different types of data such as isomorphic graphs, heterogeneous graphs, attribute graphs, and dynamic graphs.
Various proposals have been proposed
Including classic algorithms DeepWalk , LINE , Node2Vec
The basic idea of these algorithms is to generate data based on random walks
Then optimize the parameters by training
generate probabilistic models

Extend classic neural network models such as RNN, CNN, etc. to graph data
Unlike graph representation learning, which tries to learn the vector of each point
The purpose of the graph neural network is actually to learn the aggregation function
All points can use local information to calculate their own representation through the same function
Even if the graph structure changes, or even a completely new graph
can also use the original function to calculate meaningful results
Regarding the graph neural network, a series of classic algorithms have also been born

--- ★★★ ---
Finally, let’s talk about the practical application of graph computing
At present, many large Internet companies and financial technology companies
In fact, it is inseparable from graph computing technology

PageRank invented by Google founder Larry Page at the end of the 20th century
This is a large-scale page, link ranking algorithm
It can be said that the core technology of early Google is a shallow concurrent graph computing technology
There is also Facebook, the core of its technical framework is its Social Graph
That is, friends associate friends and associate friends
As a result, Facebook has established a strong social network
Facebook open source a lot of things
But this core graph computing engine and architecture has never been open source
If you can recall the world financial crisis that broke out in 2007-2008
Lehman Brothers goes bankrupt
Goldman Sachs was able to get out
The real reason behind it is the application of a powerful graph database system - SecDB

And for all the technology-driven new Internet companies
Such as Paypal, eBay and many of our domestic financial and e-commerce companies
Graph computing is not uncommon
Graph's core competencies can help them reveal the interrelationships of data
the last ten years
With the widespread application of artificial intelligence technology represented by deep learning
Graph learning has gradually become a hot topic

Breakthroughs have also been made in causality, explainability
Now, graph learning has also been extended further
Such as advertising , financial risk control , intelligent transportation , medical care , smart city and other fields

Finally, let’s talk about some examples of graph computing applications in financial anti-fraud
In fields involving money transactions such as finance and e-commerce
There is always no shortage of black products active in it for illegal profit
Such as plucking wool , swiping orders , cashing out , false transactions , etc.
Compared with the occasional arbitrage behavior of individual users themselves
Those black production gangs that gather and operate crimes in various business scenarios with gangs as units
Their actions will cause greater and more serious economic losses to the platform

And graph computing is a good recipe for identifying gang cases
By using thousands of accounts, merchants, equipment, network environment, etc. as nodes
Link registration, transaction and other key information as related information
A heterogeneous map with a very wide coverage can be formed
Combined with different application backgrounds to determine the recognition target
And select graph computing models, samples, labels, etc.
One graph training with supervised learning
Finally, in the inference stage, the probability output of the risk level of the nodes or edges in the graph is output

Then some friends will say
There are too few high-quality sample labels for risk control scenarios
Not a big problem, there are also many graphical models that can be used for unsupervised learning
For example , community discovery does not require any tag information
The most closely related node set can be clustered
in our experience
It is one of the best graph algorithms to identify gangsters

Another example is the popular self-supervised learning and comparative learning in recent years.
Applied to the field of graph computing, unsupervised pre-training can be performed on the graph
Starting from the nature of graph structure and graph attributes
Learn vectors with good representational power for graph nodes
Can be used in various downstream risk control intelligent models
--- ★★★★ ---
With the recent explosion of AIGC large models out of the circle
Artificial intelligence has ushered in a new wave

Compared to generative language and vision models
Graph computing is indeed a bit colder
But Sister Nan believes that a good meal is not afraid of being late
The days without radiance are all preparations for radiance
Maybe one day, graph computing will also usher in its own hot search

---- Written at the end ----
★ It took more than 40 days before and after this article, and it was finally completed, which can be regarded as the realization of Sister Nan's idea a few months ago. Due to the huge amount of the project, I thought about it many times during the process, but fortunately, with the support of Xiao Jiang, I persisted and completed the first chapter, which was not perfect. If there is time later, Sister Nan will continue to write, and strive to make a series of articles with a very personal style. Sister Nan has been engaged in risk control work for three years and two months. This article is also intended to pay tribute to her three years of algorithmic time, pay tribute to the thigh mentor Chen who brought her into the industry, and pay tribute to the lovely risk control colleagues who have been working together~
★ This article is just the first article to test the waters, and there may be imperfections or impreciseness, please understand, and thank you very much for your patience to see the end~
★ The pictures in this article are only for illustration and illustration, and contain some exaggerated and humorous elements, please do not take the same place~ Any similarity is purely coincidental~ No offense is intended~
★ It is not easy for Sister Nan to produce pictures, and they are not perfect. Please do not use the original pictures in this article for other occasions and purposes without permission.
This article is shared from the WeChat public account - JD Cloud Developers (JDT_Developers).
If there is any infringement, please contact [email protected] to delete it.
This article participates in the " OSC Source Creation Program ". You are welcome to join in and share it.