As a solution to improve resource utilization and reduce costs, co-location is generally recognized by the industry. In the process of cloud-nativeization and cost reduction and efficiency improvement, iQiyi has successfully mixed big data offline computing, audio and video content processing and other workloads with online business, and has achieved phased gains. This article focuses on big data as an example to introduce the practical process of implementing a mixed-deployment system from 0 to 1.
background
iQIYI big data supports important scenarios such as operational decision-making, user growth, advertising distribution, video recommendations, search, and membership within the company, providing a data-driven engine for the business. As business demands grow, the amount of computing resources required is increasing day by day, and cost control and resource supply are facing greater pressure.
iQIYI's big data computing is divided into two data processing links: offline computing and real-time computing, among which:
-
Offline computing includes Spark-based data processing, Hive-based hourly or even day-level data warehouse construction and corresponding report query and analysis. This type of calculation usually starts in the early morning of every day to calculate the previous day's data and ends in the morning. . 0 - 8 o'clock every day is the peak period of computing resource demand. The total resources of the cluster are often insufficient, and tasks are often queued and backlogged. During the day, there is a large amount of idle time, resulting in a waste of resources.
-
Real-time computing includes real-time data stream processing represented by Kafka + Flink, which has relatively stable resource requirements.
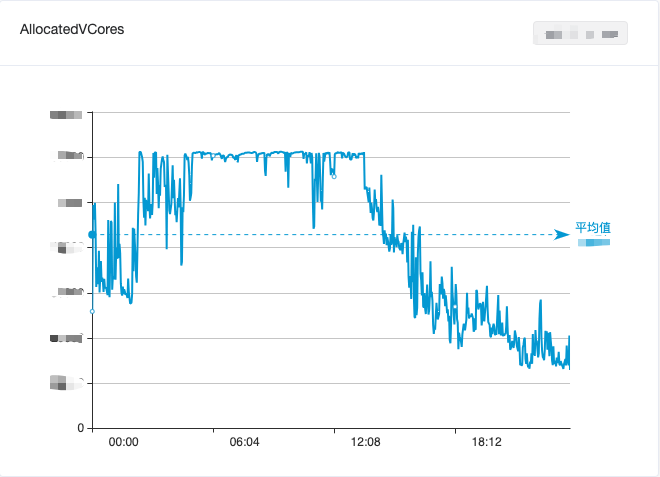
In order to balance the utilization of big data resources, we mixed offline computing and real-time computing, which alleviated the idle waste of resources during the day to a certain extent. However, it was still unable to effectively cut peaks and fill valleys, and the overall utilization of big data computing resources still showed " The tidal phenomenon of “daytime trough and early morning peak” is shown in Figure 1.
Figure 1. Changes in CPU usage of the big data computing cluster within one day
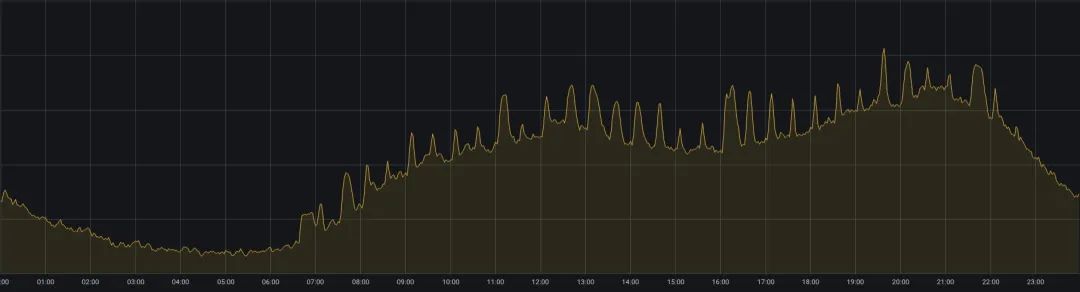
iQiyi’s online business faces another problem: the balance between service quality and resource utilization. The online business mainly serves scenarios such as iQiyi video playback. There are more users watching videos at noon and evening, and resource usage has a tidal phenomenon of "peaks during the day and troughs in the early morning" (as shown in Figure 2). In order to ensure service quality during peak periods, online businesses usually reserve more resources, making resource utilization very unsatisfactory.
Figure 2. Changes in CPU usage of the online business cluster within one day
In order to improve utilization, the previous generation container platform developed by iQiyi adopted a CPU static overbooking strategy. Although this method has a significant effect on improving utilization, it is limited by factors such as core capabilities and cannot avoid interruptions between services on a single machine. Occasional resource competition issues have also led to unstable online business service quality, and this problem has never been properly resolved.
With the advancement of cloud nativeization, the iQiyi container platform has gradually transformed into the Kubernetes (hereinafter referred to as "K8s") technology stack. In recent years, many open source projects related to co-deployment have appeared in the K8s community, and there are also some co-deployment practices in the industry [1] . Against this background, the computing platform team adjusted its work direction from "static overbooking" to "dynamic overbooking + mixed deployment".
As the most typical offline business, big data is a pioneer in trying to implement co-location. On the one hand, big data has a large volume and relatively stable computing resource requirements; on the other hand, big data business and online business can achieve complementary effects in many dimensions, and resource utilization can be fully improved through co-location.
Based on the above analysis, the iQiyi computing platform team and the big data team began to explore co-location.
Mixed location plan design
The iQiyi big data system is built on the open source Apache Hadoop ecosystem and uses YARN as the computing resource scheduling system. The online business is built on K8s. How to connect two different resource scheduling systems is the first thing that needs to be solved in the co-location solution.
There are usually two co-located solutions in the industry:
-
Option 1: Directly run big data jobs (Spark, Flink, etc., MapReduce is not supported) on K8s and use its native scheduler
-
Option 2: Run YARN’s NodeManager (hereinafter referred to as “NM”) on K8s, and big data jobs are still scheduled through YARN
After careful consideration, we chose option two for the following two main reasons:
-
At present, the vast majority of big data computing jobs in the company are scheduled based on YARN. YARN has powerful scheduling functions (multi-tenant multi-queue, rack awareness), excellent scheduling performance (5k+ containers/s) and complete security mechanisms ( Kerberos, Delegation Tokens) and supports almost all big data computing frameworks such as MapReduce, Spark, and Flink. Since the introduction of YARN in 2014, the iQiyi big data team has built a series of platforms around it for development, operation and maintenance, computing governance, etc., providing internal users with a convenient big data development process. Therefore, compatibility with YARN API is one of the important considerations when selecting a hybrid solution.
-
Although K8s has a batch scheduler, it is not mature enough, and there is a bottleneck in scheduling performance (<1k containers/s), which is not enough to support the needs of big data scenarios.
At the K8s level, both parties need a set of standard interfaces to manage and use co-location resources. There are many excellent projects in the community, such as Alibaba's open source Koordinator [2], Tencent's open source FinOps project Crane [3], ByteDance's open source project Katalyst [4], etc. Among them, Koordinator has "natural" adaptability with the Dragon Lizard Operating System (one of the CentOS alternatives that iQiyi is trying), and can collaborate to achieve online business load monitoring, idle resource overcommitment, task hierarchical scheduling, and offline Workload QoS guarantee, etc., meet iQiyi’s needs.
Based on the above technology selection, through in-depth transformation, we containerized YARN NM and ran it in K8s Pod, and can sense Koordinator's dynamically changing hyper-resolution computing resources in real time, thereby achieving automatic horizontal and vertical expansion and contraction, and maximizing utilization. Mixed resources.
Evolution of co-located scheduling strategy
The co-location of big data and online business has gone through multiple stages of technological evolution, which we will introduce in detail below.
Stage 1: Time-sharing multiplexing at night
In order to quickly verify the solution, we first completed the containerization transformation of NM on K8s Pod (Koordinator was not used at this stage) and expanded it to the existing Hadoop cluster as an elastic node. At the big data level, these K8s NMs are uniformly scheduled by YARN together with NMs on other physical machines. These elastic nodes start and stop regularly every day and only run between 0 - 9 o'clock.
At this stage, we have completed more than 20 renovations. Here are the 5 main renovation points:
Improvement point 1: Fixed IP pool
Traditional NM is deployed on a physical machine, and the IP and domain name of the machine are fixed. The node whitelist (slaves file) is configured on the YARN ResourceManager (hereinafter referred to as "RM") to allow the node to join the cluster. At the same time, the YARN cluster uses Kerberos to implement security authentication. Before deployment, the keytab file needs to be generated in the Kerberos KDC and distributed to the NM node.
In order to adapt to YARN's whitelist and security authentication mechanism, we use the self-developed static IP function for self-built clusters. Each static IP will have a corresponding K8s StaticIP resource to record the corresponding relationship between Pod and IP. At the same time, it is based on the public cloud We will also deploy the self-developed StaticIP CRD in the cluster and create StaticIP resources for each static IP, thereby providing YARN with a fixed IP pool that has the same usage as the self-built cluster. Create DNS records and keytab files in advance based on the IP in the fixed IP pool, so that the required configuration can be quickly obtained when NM starts.
Transformation point 2: Elastic YARN Operator
In order to make users unaware of the introduction of elastic nodes, we added elastic NM to the existing Hadoop YARN cluster. Taking into account the complexity of dynamically aware resources in later mixed deployments, we chose the self-developed Elastic YARN Operator to better manage the life cycle of elastic NM.
At this stage, the strategies supported by the Elastic YARN Operator are:
-
按需启动:应对离线任务的突发流量,包括寒暑假、节假日、重要活动等场景
-
周期性上下线:利用在线服务每天凌晨的资源利用率低谷期,运行大数据任务
改造点 3:Node Label - 弹性与固定资源隔离
由于 Flink 等大数据实时流计算任务是 7x24 小时不间断常驻运行的,对 NM 的稳定性的要求比批处理更高,弹性 NM 节点的缩容或资源量调整会使得流计算任务重启,导致实时数据波动。为此,我们引入了 YARN Node Label 特性 [5],将集群分为固定节点(物理机 NM)和弹性节点(K8s NM)。批处理任务可以使用任意节点,流任务则只能使用固定节点运行。
此外,批处理任务容错的基础在于 YARN Application Master 的稳定性。我们的解决方案是,给 YARN 新增了一个配置,用于设置 Application Master 默认使用的 label,确保 Application Master 不被分配到弹性 NM 节点上。这一功能已经合并到社区:
YARN-11084
、
YARN-11088
。
改造点 4:NM Graceful Decommission
我们采用了弹性节点固定时间上下线,来对在离线资源进行削峰填谷。弹性 NM 的上线由 YARN Operator 来启动,一旦启动完成,任务就可被调度上。弹性 NM 的下线则略微复杂些,因为任务仍然运行在上面,我们需要尽可能保证任务在下线的时间区间内已经结束。
例如我们周期性部署策略为:0 - 8 点弹性 NM 上线,8 - 9 点为下线时间区间,9 - 24 点为节点离线状态。通过使用 YARN graceful decommission [6] 的机制,将增量 container 请求避免分配到 decommissioning 的节点上,在下线时间区间内等待任务缓慢结束即可。
但是在我们集群中,批处理任务大部分是 Spark 3.1.1 版本,因为 Spark 申请的 YARN container 是作为 task 的 executor 来使用,在大部分情况下,1 个小时的下线区间往往是不够的。因此我们引入了 SPARK-20624 的一系列优化 [7],通过 executor 响应 YARN decommission 事件来将 executor 尽可能快速退出。
改造点 5:引入 Remote Shuffle Service - Uniffle
Shuffle 作为离线任务中的重要一环,我们采用 Spark ESS on NodeManager 的部署模式。但在引入弹性节点后,因为弹性 NM 生命周期短,无法保证在 YARN graceful decommmission 的时间区间内,任务所在节点的 shuffle 数据被消费完,导致作业整体失败。
基于这一点,我们引入了 Apache Uniffle (incubating) [8] 实现 remote shuffle service 来解耦 Spark shuffle 数据与 NM 的生命周期,NM 被转变为单纯的计算,不存储中间 shuffle 数据,从而实现 NM 快速平滑下线。
另外一方面,弹性 NM 挂载的云盘性能一般,无法承载高 IO 和高并发的随机读写,同时也会对在线服务产生影响。通过独立构建高性能 IO 的 Uniffle 集群,提供更快速的 shuffle 服务。
爱奇艺作为 Uniffle 的深度参与者,贡献了 100+ 改进和 30+ 特性,包括 Spark AQE 优化 [9] 、Kerberos 的支持 [10] 和超大分区优化 [11] 等。
阶段二:资源超分
在阶段一,我们仅使用 K8s 资源池剩余未分配资源实现了初步的混部。为了最大限度地利用空闲资源,我们引入 Koordinator 进行资源的超分配。
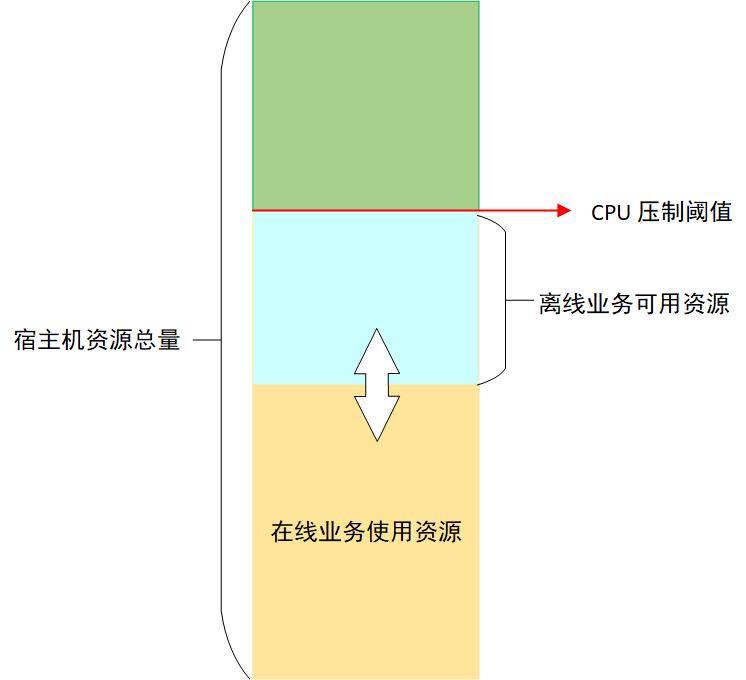
我们对弹性 NM 的资源容量采用了固定规格限制:10 核 batch-cpu、30 GB batch-memory(batch-cpu 和 batch-memory 是 Koordinator 超分出来的扩展资源),NM 保证离线任务使用的资源总量不会超过这些限制。
为了保证在线业务的稳定性,Koordinator 会对节点上离线任务能够使用的 CPU 进行压制 [12],压制结果由压制阈值和在线业务 CPU 实际用量(不是 request 请求)的差值决定,这个差值就是离线业务能够使用的最大 CPU 资源,由于在线业务 CPU 实际使用量不断变化,所以离线业务能够使用的 CPU 也在不断变化,如图 3 所示:
对离线任务的 CPU 压制保证了在线业务的稳定性,但是离线任务执行时间就会被拉长。如果某个节点上离线任务被压制程度比较严重,就可能会导致等待的发生,从而拖慢整体任务的运行速度。为了避免这种情况,Koordinator 提供了基于 CPU 满足度的驱逐功能 [13],当离线任务使用的 CPU 被压制到用户指定的满足度以下时,就会触发离线任务的驱逐。离线任务被驱逐后,可以调度到其他资源充足的机器上运行,避免等待。
在经过一段时间的测试验证后,我们发现在线业务运行稳定,集群 CPU 7 天平均利用率提升了 5%。但是节点上的 NM Pod 被驱逐的情况时有发生。NM 被驱逐之后,RM 不能及时感知到驱逐情况的发生,会导致失败的任务延迟重新调度。为了解决这个问题,我们开发了 NM 动态感知节点离线 CPU 资源的功能。
阶段三:从夜间分时复用到全天候实时弹性
与其触发 Koordinator 的驱逐操作,不如让 NM 主动感知节点上离线资源的变化,在离线资源充足时,调度较多任务,离线资源不足时,停止调度任务,甚至主动杀死一些离线 container 任务,避免 NM 被 Koordinator 驱逐。
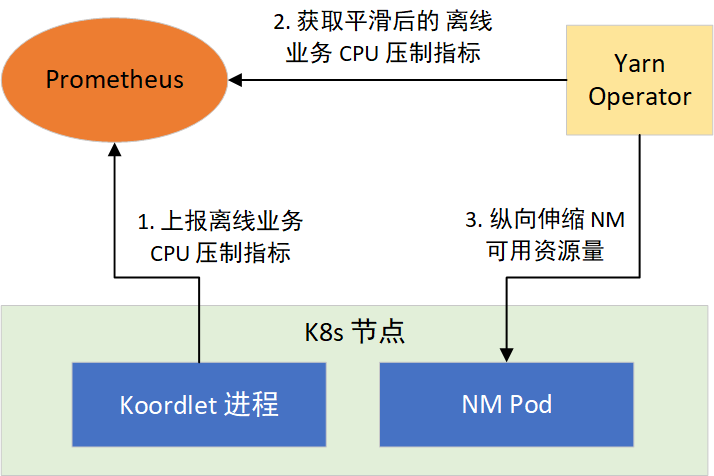
根据这个思路,我们通过 YARN Operator 动态感知节点所能利用的资源,来纵向伸缩 NM 可用资源量。分两步实现:1)提供离线任务 CPU 压制指标;2)让 NM 感知 CPU 压制指标,采取措施。如图 4 所示:
CPU 压制指标
Koordinator 的 Koordlet 组件,运行于 K8s 的节点上,负责执行离线任务 CPU 压制、Pod 驱逐等操作,它以 Prometheus 格式提供了 CPU 压制指标,经过采集后就可以通过 Prometheus 对外提供。CPU 压制指标默认每隔 1 秒更新 1 次,会随着在线业务负载的变化而变化,波动较大。而 Prometheus 的指标抓取周期一般都大于 1 秒,这会造成部分数据的丢失,为了平滑波动,我们对 Koordlet 进行了修改,提供了 1 min、5 min、10 min CPU 压制指标的均值、方差、最大值和最小值等指标供 NM 选择使用。
YARN Operator 动态感知和纵向伸缩
在 NM 常驻的部署模式下,YARN Operator 提供了新的策略。通过在 YARN Operator 接收到当前部署的节点 10 min 内可利用的资源指标,用来决策是否对所在宿主机上的 NM 进行纵向伸缩。
对于扩容,一旦超过 3 核,则向 RM 进行节点的资源更新。扩容过程如图 5 所示:
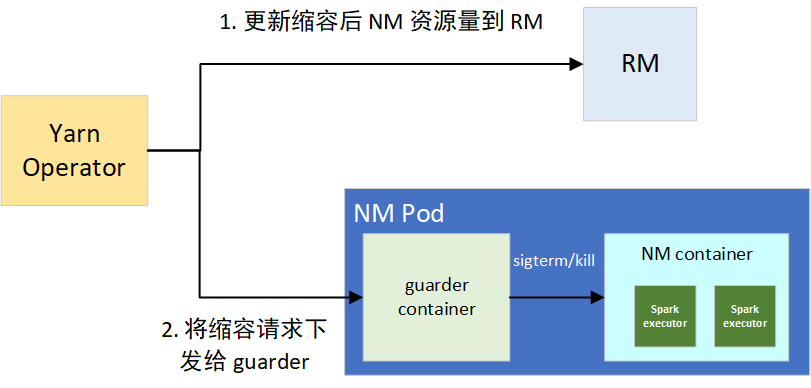
缩容的话,如果抑制率控制在 10% 以内的波动,我们默认忽略。一旦超过阈值,则会触发缩容操作,分为两个步骤:1)更新节点在 RM 上的可用资源,用来堵住增量的 container 分配需求;2)将缩容请求下发给 NM 的 guarder sidecar 容器,来对部分资源超用的 container 的平滑和强制下线,避免因占用过多 CPU 资源导致整个 NM 被驱逐。
guarder 在拿到目标可用资源后,会对当前所有的 YARN container 进程进行排序,包括框架类型、运行时长、资源使用量三者,决策拿到要 kill 的进程。在 kill 前,会进行 SIGPWR 信号的发送,用来平滑下线任务,Spark Executor 接收到此信号,会尽可能平滑退出。缩容过程如图 6 所示:
通常节点的资源量变动幅度不是很大,且 NM 可使用的资源量维持在较高的水平(平均有 20 core),部分 container 的存活周期为 10 秒级,因此很快就能降至目标可用资源量值。涉及到变动幅度频繁的节点,通过 guarder 的平滑下线和 kill 决策,container 失败数非常低,从线上来看,按天统计平均 force kill container 数目为 5 左右,guarder 发送的平滑下线信号有 500+,可以看到效果比较好。
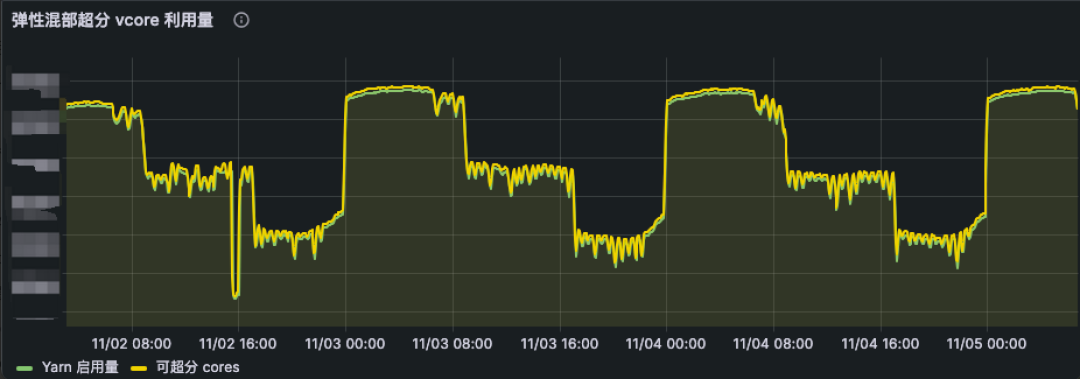
在离线 CPU 资源感知功能全面上线后,NM Pod 被驱逐的情况基本消失。因此,我们逐步将混部时间由凌晨的 0 点至 8 点,扩展到全天 24h 运行,并根据在线业务负载分布情况,在一天的不同时段采用不同的 CPU 资源超分比,从而实现全天候实时弹性调度策略。伴随着全天 24h 的稳定运行,集群 CPU 利用率再度提升了 10%。从线上混部 K8s 集群来看(如图 7 所示),弹性 NM 的 vcore 使用资源量(绿线)也是动态贴合可超分的资源(黄线)。
阶段四:提升资源超分率
为了提供更多的离线资源,我们开始逐步调高 CPU 资源的超分比,而 NM Pod 被驱逐的情况再次发生了,这一次的原因是内存驱逐。我们将物理机器的内存超分比设置为 90%,从集群总体情况看,物理机器上的内存资源比较充足,刚开始我们只关注了 CPU 资源,没有关注内存资源。而 NM 的 CPU 和内存按照 1:4 的比例来使用,随着 CPU 超分比的提高,YARN 任务需要的内存也在提升,最终当 K8s 节点内存使用量超过设定的阈值时,就会触发 Koordinator 的驱逐操作。
经过观察,我们发现内存驱逐在某些节点上发生的概率特别高,这些节点的内存比其他节点内存小,而 CPU 数量是相同的,因此这些节点在 CPU 超分比相同的情况下,更容易因为内存原因被驱逐,它们能提供的离线内存更少。因此,guarder 容器也需要感知节点的离线内存资源用量,并根据资源用量采取相应的措施,这个过程与 CPU 离线资源的感知一样的,不再赘述。
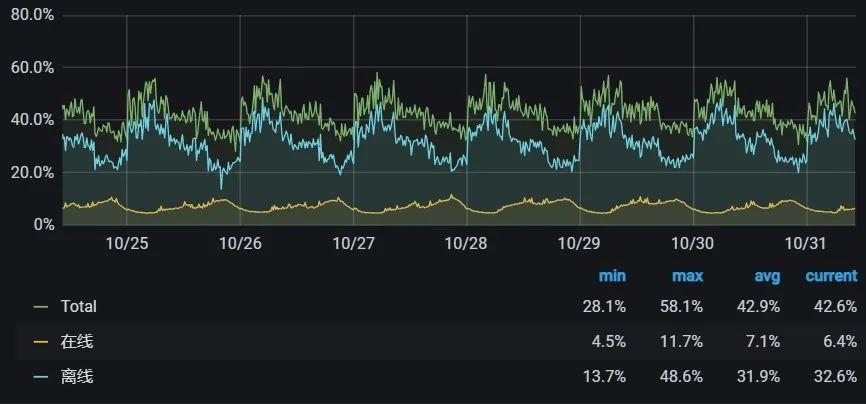
内存感知功能上线后,我们又逐步提升了 CPU 的超分比,当前在线业务集群的 CPU 利用率已经提升到全天平均 40%+、夜间 58% 左右。
效果
通过大数据离线计算与在线业务的混部,我们将在线业务集群 CPU 平均利用率从 9% 提升到 40%+,在不增加机器采购的同时满足了部分大数据弹性计算的资源需求,每年节省数千万元成本。
同时,我们也将这套框架应用到大数据 OLAP 分析场景,实现了 Impala/Trino on K8s 弹性架构,满足数据分析师日常动态查询需求,支持了寒暑假、春晚直播、广告 618 与双 11 等重要活动期间临时大批量资源扩容需求,保障了广告、BI、会员等数据分析场景的稳定、高效。
未来计划
当前,大数据离在线混部已稳定运行一年多,并取得阶段性成果,未来我们将基于这套框架进一步推进大数据云原生化:
-
完善离在线混部可观测性:建立精细化的 QoS 监控,保障在线服务、大数据弹性计算任务的稳定性。
-
加大离在线混部力度:K8s 层面,继续提高宿主机资源利用率,提供更多的弹性计算资源供大数据使用。大数据层面,进一步提升通过离在线混部框架调度的弹性计算资源占比,节省更多成本。
-
大数据混合云计算:目前我们主要使用爱奇艺内部的 K8s 进行混部,随着公司混合云战略的推进,我们计划将混部推广到公有云 K8s 集群中,实现大数据计算的多云调度。
-
探索云原生的混部模式:尽管复用 YARN 的调度器能让我们快速利用混部资源,但它也带来了额外的资源管理和调度开销。后续我们也将探索云原生的混部模式,尝试将大数据的计算任务直接使用 K8s 的离线调度器进行调度,进一步优化调度速度和资源利用率。
参考资料
[1] 一文看懂业界在离线混部技术. https://www.infoq.cn/article/knqswz6qrggwmv6axwqu
[2] Koordinator: QoS-based Scheduling for Colocating on Kubernetes. https://koordinator.sh/
[3] Crane: Cloud Resource Analytics and Economics in Kubernetes clusters. https://gocrane.io/
[4] Katalyst: a universal solution to help improve resource utilization and optimize the overall costs in the cloud. https://github.com/kubewharf/katalyst-core
[5] Apache Hadoop YARN - Node Labels. https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/NodeLabel.html
[6] Apache Hadoop YARN - Graceful Decommission of YARN Nodes. https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/GracefulDecommission.html
[7] Apache Spark - Add better handling for node shutdown. https://issues.apache.org/jira/browse/SPARK-20624
[8] Apache Uniffle: Remote Shuffle Service. https://uniffle.apache.org/
[9] Apache Uniffle - Support getting memory data skip by upstream task ids. https://github.com/apache/incubator-uniffle/pull/358
[10] Apache Uniffle - Support storing shuffle data to secured dfs cluster. https://github.com/apache/incubator-uniffle/pull/53
[11] Apache Uniffle - Huge partition optimization. https://github.com/apache/incubator-uniffle/issues/378
[12] Koordinator - CPU Suppress. https://koordinator.sh/docs/user-manuals/cpu-suppress/
[13] Koordinator - Eviction Strategy based on CPU Satisfaction. https://koordinator.sh/docs/user-manuals/cpu-evict/

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。