Endereço de vídeo: Shang Silicon Valley Big Data Project "Offline Data Warehouse for Online Education"_bilibili_bilibili
Índice
Capítulo 8 Camada DIM de desenvolvimento de data warehouse
Capítulo 8 Camada DIM de desenvolvimento de data warehouse
P039
Capítulo 8 Camada DIM de desenvolvimento de data warehouse
Pontos de design da camada DIM:
(1) O design da camada DIM é baseado na teoria da modelagem dimensional, esta camada armazena a tabela de dimensões do modelo dimensional.
(2) O formato de armazenamento de dados da camada DIM é armazenamento de coluna orc + compactação rápida.
(3) A especificação de nomenclatura do nome da tabela da camada DIM é dim_table name_full table ou identificador de tabela zip (completo/zip).
[2023-08-21 10:21:33] org.apache.hadoop.hive.ql.parse.SemanticException:Falha ao obter uma sessão spark: org.apache.hadoop.hive.ql.metadata.HiveException: Falha ao criar Cliente Spark para sessão Spark 2ed82e1b-8afb-4ad0-9ed2-0f84191a4343
P040


show databases;
use edu2077;
show tables;
--8.1 章节维度表(全量)
DROP TABLE IF EXISTS dim_chapter_full;
CREATE EXTERNAL TABLE dim_chapter_full
(
`id` STRING COMMENT '章节ID',
`chapter_name` STRING COMMENT '章节名称',
`course_id` STRING COMMENT '课程ID',
`video_id` STRING COMMENT '视频ID',
`publisher_id` STRING COMMENT '发布者ID',
`is_free` STRING COMMENT '是否免费',
`create_time` STRING COMMENT '创建时间',
`update_time` STRING COMMENT '更新时间'
) COMMENT '章节维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/edu/dim/dim_chapter_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');
--数据装载
--insert overwrite覆盖写,insert into会造成数据重复。
insert overwrite table dim_chapter_full partition (dt = '2022-02-21')
select id,
chapter_name,
course_id,
video_id,
publisher_id,
is_free,
create_time,
update_time
from ods_chapter_info_full
where dt = '2022-02-21';
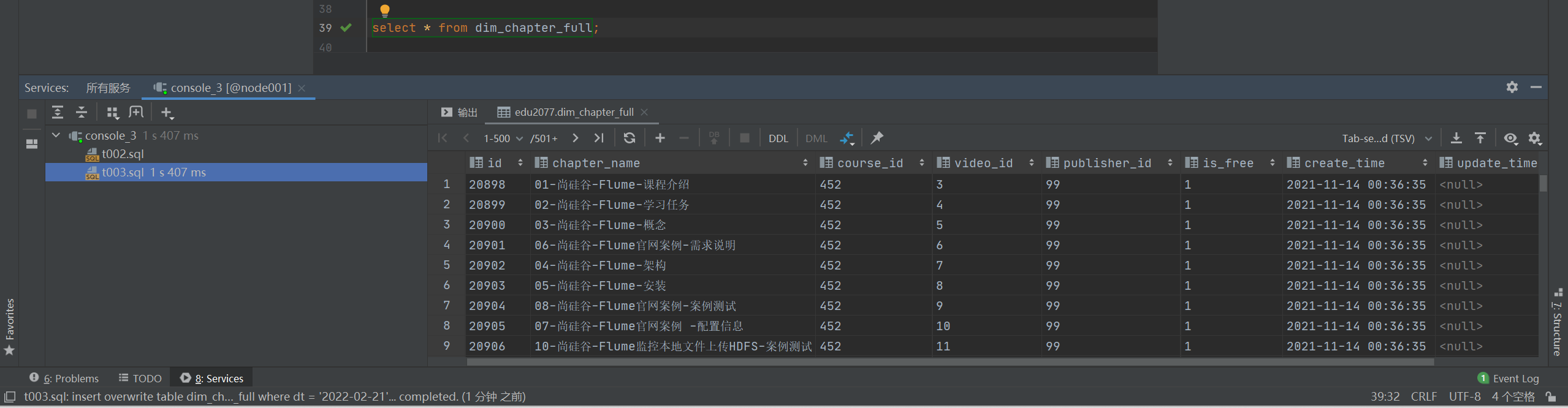
select *
from dim_chapter_full;
--8.2 课程维度表(全量)
DROP TABLE IF EXISTS dim_course_full;
CREATE EXTERNAL TABLE dim_course_full
(
`id` STRING COMMENT '编号',
`course_name` STRING COMMENT '课程名称',
`subject_id` STRING COMMENT '学科id',
`subject_name` STRING COMMENT '学科名称',
`category_id` STRING COMMENT '分类id',
`category_name` STRING COMMENT '分类名称',
`teacher` STRING COMMENT '讲师名称',
`publisher_id` STRING COMMENT '发布者id',
`chapter_num` BIGINT COMMENT '章节数',
`origin_price` decimal(16, 2) COMMENT '价格',
`reduce_amount` decimal(16, 2) COMMENT '优惠金额',
`actual_price` decimal(16, 2) COMMENT '实际价格',
`create_time` STRING COMMENT '创建时间',
`update_time` STRING COMMENT '更新时间',
`chapters` ARRAY<STRUCT<chapter_id : STRING,chapter_name : STRING, video_id : STRING,is_free
: STRING>> COMMENT '章节'
) COMMENT '课程维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/edu/dim/dim_course_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');
select *
from ods_base_source_full
where dt = '2022-02-21';
select *
from ods_course_info_full
where dt = '2022-02-21';
select *
from (
select id,
course_name,
course_slogan,
subject_id,
teacher,
publisher_id,
chapter_num,
origin_price,
reduce_amount,
actual_price,
course_introduce,
create_time,
update_time
from ods_course_info_full
where dt = '2022-02-21'
) ci;--ci是别名
with ci as (
select id,
course_name,
course_slogan,
subject_id,
teacher,
publisher_id,
chapter_num,
origin_price,
reduce_amount,
actual_price,
course_introduce,
create_time,
update_time
from ods_course_info_full
where dt = '2022-02-21'
),
bci as (
select id, category_name
from ods_base_category_info_full
where dt = '2022-02-21'
),
bs as (
select id, subject_name, category_id
from ods_base_subject_info_full
where dt = '2022-02-21'
),
chapter as (
select course_id,
--chapter_id : STRING,chapter_name : STRING, video_id : STRING,is_free : STRING
collect_set(
named_struct('chapter_id', id, 'chapter_name', chapter_name,
'video_id', video_id, 'is_free', is_free)) cs
from ods_chapter_info_full
where dt = '2022-02-21'
group by course_id
)
insert overwrite table dim_course_full partition (dt = '2022-02-21')
select ci.id,
course_name,
subject_id,
subject_name,
category_id,
category_name,
teacher,
publisher_id,
chapter_num,
origin_price,
reduce_amount,
actual_price,
create_time,
update_time,
cs chapters
from ci
left join bs
on ci.subject_id = bs.id
left join bci
on bs.category_id = bci.id
left join chapter
on ci.id = chapter.course_id;
--desc function extended named_struct;
select * from dim_course_full;P041
--8.3 Tabela de dimensões de vídeo (valor total)
show databases;
--8.3 视频维度表(全量)
DROP TABLE IF EXISTS dim_video_full;
CREATE EXTERNAL TABLE dim_video_full
(
`id` STRING COMMENT '编号',
`video_name` STRING COMMENT '视频名称',
`during_sec` BIGINT COMMENT '时长',
`video_status` STRING COMMENT '状态 未上传,上传中,上传完',
`video_size` BIGINT COMMENT '大小',
`version_id` STRING COMMENT '版本号',
`chapter_id` STRING COMMENT '章节id',
`chapter_name` STRING COMMENT '章节名称',
`is_free` STRING COMMENT '是否免费',
`course_id` STRING COMMENT '课程id',
`publisher_id` STRING COMMENT '发布者id',
`create_time` STRING COMMENT '创建时间',
`update_time` STRING COMMENT '更新时间'
) COMMENT '视频维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/edu/dim/dim_video_zip/'
TBLPROPERTIES ('orc.compress' = 'snappy');
select *
from ods_video_info_full
where dt = '2022-02-21';
insert overwrite table dim_video_full partition (dt = '2022-02-21')
select id,
video_name,
during_sec,
video_status,
video_size,
version_id,
chapter_id,
chapter_name,
is_free,
course_id,
publisher_id,
create_time,
update_time
from (
select id,
video_name,
during_sec,
video_status,
video_size,
video_url,
video_source_id,
version_id,
chapter_id,
course_id,
publisher_id,
create_time,
update_time,
deleted
from ods_video_info_full
where dt = '2022-02-21'
and deleted = '0'
) vi
left join(
select chapter_name,
video_id,
is_free
from ods_chapter_info_full
where dt = '2022-02-21'
) ci
on vi.id = ci.video_id;
select *
from dim_video_full;
insert overwrite table dim_video_full partition (dt = '2022-02-21')
select vt.id,
video_name,
during_sec,
video_status,
video_size,
version_id,
chapter_id,
chapter_name,
is_free,
course_id,
publisher_id,
create_time,
update_time
from (
select id,
video_name,
during_sec,
video_status,
video_size,
version_id,
chapter_id,
course_id,
publisher_id,
create_time,
update_time
from ods_video_info_full
where dt = '2022-02-21'
and deleted = '0'
) vt
join
(
select id,
chapter_name,
is_free
from ods_chapter_info_full
where dt = '2022-02-21'
) cht
on vt.chapter_id = cht.id;
org.apache.hadoop.hive.ql.parse.SemanticException:Falha ao obter uma sessão Spark: org.apache.hadoop.hive.ql.metadata.HiveException: Falha ao criar cliente Spark para sessão Spark 2519dff0-c795-4852-a1b4 -f40ad1750136
23/08/2023
14:50 t004.sql: inserir tabela de substituição dim_vi… em vt.chapter_id = cht.id… falhou.15:00 t004.sql: inserção da tabela de substituição dim_vi… em vt.chapter_id = cht.id… falhou.

org.apache.hadoop.hive.ql.parse.SemanticException:Falha ao obter uma sessão spark: org.apache.hadoop.hive.ql.metadata.HiveException: Falha ao criar o cliente Spark devido a solicitação de recurso inválida: Memória do executor necessária ( 2.048 MB), memória offHeap (0) MB, sobrecarga (384 MB) e memória PySpark (0 MB) está acima do limite máximo (2.048 MB)


[atguigu@node001 hadoop]$ myhadoop.sh start
================ 启动 hadoop集群 ================
---------------- 启动 hdfs ----------------
Starting namenodes on [node001]
Starting datanodes
Starting secondary namenodes [node003]
--------------- 启动 yarn ---------------
Starting resourcemanager
Starting nodemanagers
--------------- 启动 historyserver ---------------
[atguigu@node001 hadoop]$ cd /opt/module/hive/hive-3.1.2/
[atguigu@node001 hive-3.1.2]$ nohup bin/hive &
[1] 11485
[atguigu@node001 hive-3.1.2]$ nohup: 忽略输入并把输出追加到"nohup.out"
[atguigu@node001 hive-3.1.2]$ nohup bin/hive --service hiveserver2 &
[2] 11626
[atguigu@node001 hive-3.1.2]$ nohup: 忽略输入并把输出追加到"nohup.out"
[atguigu@node001 hive-3.1.2]$ jpsall
================ node001 ================
3872 QuorumPeerMain
4291 Kafka
11381 JobHistoryServer
10583 NameNode
11626 RunJar
10747 DataNode
13660 Jps
13533 YarnCoarseGrainedExecutorBackend
11485 RunJar
11167 NodeManager
================ node002 ================
7841 Jps
5586 ResourceManager
2946 Kafka
7683 ApplicationMaster
2552 QuorumPeerMain
5384 DataNode
5711 NodeManager
================ node003 ================
6944 YarnCoarseGrainedExecutorBackend
2256 QuorumPeerMain
5040 SecondaryNameNode
4929 DataNode
2643 Kafka
5158 NodeManager
7047 Jps
[atguigu@node001 hive-3.1.2]$ P042
8.4 Tabela de dimensões do papel do exame (volume completo)
--8.4 试卷维度表(全量)
DROP TABLE IF EXISTS dim_paper_full;
CREATE EXTERNAL TABLE dim_paper_full
(
`id` STRING COMMENT '编号',
`paper_title` STRING COMMENT '试卷名称',
`course_id` STRING COMMENT '课程id',
`create_time` STRING COMMENT '创建时间',
`update_time` STRING COMMENT '更新时间',
`publisher_id` STRING COMMENT '发布者id',
`questions` ARRAY<STRUCT<question_id: STRING, score: DECIMAL(16, 2)>> COMMENT '题目'
) COMMENT '试卷维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/edu/dim/dim_paper_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');
select *
from ods_test_paper_full;
insert overwrite table dim_paper_full partition (dt = '2022-02-21')
select id,
paper_title,
course_id,
create_time,
update_time,
publisher_id,
qs
from (
select id,
paper_title,
course_id,
create_time,
update_time,
publisher_id,
deleted
from ods_test_paper_full
where dt = '2022-02-21'
--and deleted = '0'
) tp
left join (
select paper_id,
--question_id: STRING, score: DECIMAL(16, 2)
collect_set(named_struct('question_id', id, 'score', score)) qs
from ods_test_paper_question_full
where dt = '2022-02-21'
and deleted = '0'
group by paper_id
) pq
on tp.id = pq.paper_id;
select * from dim_paper_full;P043
8.5 Tabela de dimensão de origem (valor total)
8.6 Tabela de dimensões da pergunta (quantidade total)
8.7 Tabela de dimensão regional (valor integral)
--8.5 来源维度表(全量)
DROP TABLE IF EXISTS dim_source_full;
CREATE EXTERNAL TABLE dim_source_full
(
`id` STRING COMMENT '编号',
`source_site` STRING COMMENT '来源'
) COMMENT '来源维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/edu/dim/dim_source_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');
insert overwrite table edu2077.dim_source_full partition (dt = '2022-02-21')
select id,
source_site
from edu2077.ods_base_source_full obsf
where dt = '2022-02-21';
select * from dim_source_full;
--8.6 题目维度表(全量)
DROP TABLE IF EXISTS dim_question_full;
CREATE EXTERNAL TABLE dim_question_full
(
`id` STRING COMMENT '编号',
`chapter_id` STRING COMMENT '章节id',
`course_id` STRING COMMENT '课程id',
`question_type` BIGINT COMMENT '题目类型',
`create_time` STRING COMMENT '创建时间',
`update_time` STRING COMMENT '更新时间',
`publisher_id` STRING COMMENT '发布者id'
) COMMENT '题目维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/edu/dim/dim_question_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');
insert overwrite table edu2077.dim_question_full
partition (dt = '2022-02-21')
select id,
chapter_id,
course_id,
question_type,
create_time,
update_time,
publisher_id
from edu2077.ods_test_question_info_full
where deleted = '0'
and dt = '2022-02-21';
select * from dim_question_full;
--8.7 地区维度表(全量)
DROP TABLE IF EXISTS dim_province_full;
CREATE EXTERNAL TABLE dim_province_full
(
`id` STRING COMMENT '编号',
`name` STRING COMMENT '省名称',
`region_id` STRING COMMENT '地区id',
`area_code` STRING COMMENT '行政区位码',
`iso_code` STRING COMMENT '国际编码',
`iso_3166_2` STRING COMMENT 'ISO3166编码'
) COMMENT '地区维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/edu/dim/dim_province_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');
insert overwrite table edu2077.dim_province_full partition (dt = '2022-02-21')
select id,
name,
region_id,
area_code,
iso_code,
iso_3166_2
from edu2077.ods_base_province_full
where dt = '2022-02-21';
select * from dim_province_full;P044
8.8 Tabela de dimensão de tempo (especial)
--8.8 时间维度表(特殊)
DROP TABLE IF EXISTS dim_date;
CREATE EXTERNAL TABLE dim_date
(
`date_id` STRING COMMENT '日期id',
`week_id` STRING COMMENT '周id,一年中的第几周',
`week_day` STRING COMMENT '周几',
`day` STRING COMMENT '每月的第几天',
`month` STRING COMMENT '一年中的第几月',
`quarter` STRING COMMENT '一年中的第几季度',
`year` STRING COMMENT '年份',
`is_workday` STRING COMMENT '是否是工作日',
`holiday_id` STRING COMMENT '节假日'
) COMMENT '时间维度表'
STORED AS ORC
LOCATION '/warehouse/edu/dim/dim_date/'
TBLPROPERTIES ('orc.compress' = 'snappy');
DROP TABLE IF EXISTS tmp_dim_date_info;
CREATE EXTERNAL TABLE tmp_dim_date_info
(
`date_id` STRING COMMENT '日',
`week_id` STRING COMMENT '周id',
`week_day` STRING COMMENT '周几',
`day` STRING COMMENT '每月的第几天',
`month` STRING COMMENT '第几月',
`quarter` STRING COMMENT '第几季度',
`year` STRING COMMENT '年',
`is_workday` STRING COMMENT '是否是工作日',
`holiday_id` STRING COMMENT '节假日'
) COMMENT '时间维度表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/warehouse/edu/tmp/tmp_dim_date_info/';
insert overwrite table dim_date
select *
from tmp_dim_date_info;
insert overwrite table dim_date
select date_id,
week_id,
week_day,
day,
month,
quarter,
year,
is_workday,
holiday_id
from tmp_dim_date_info;
select * from dim_date;P045
8.9 Tabela de dimensões do usuário (tabela de zíper)


--8.9 用户维度表(拉链表)
DROP TABLE IF EXISTS dim_user_zip;
CREATE EXTERNAL TABLE dim_user_zip
(
`id` STRING COMMENT '编号',
`login_name` STRING COMMENT '用户名称',
`nick_name` STRING COMMENT '用户昵称',
`real_name` STRING COMMENT '用户姓名',
`phone_num` STRING COMMENT '手机号',
`email` STRING COMMENT '邮箱',
`user_level` STRING COMMENT '用户级别',
`birthday` STRING COMMENT '用户生日',
`gender` STRING COMMENT '性别 M男,F女',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间',
`status` STRING COMMENT '状态',
`start_date` STRING COMMENT '开始日期',
`end_date` STRING COMMENT '结束日期'
) COMMENT '用户表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/edu/dim/dim_user_zip/'
TBLPROPERTIES ('orc.compress' = 'snappy');P046
8.9 Tabela de dimensões do usuário (tabela de zíper)
(3) Carregamento do primeiro dia
Não há dados nas tabelas incrementais, como inc: No Projeto do Sistema de Educação Online do Vale do Silício, a tabela incremental ods_user_info_inc não possui dados e não há operações relacionadas no material didático. Você pode me ajudar a dar uma olhada quando tiver tempo ? Deveria ser que ao executar o script de carregamento de dados hdfs_to_ods_db.sh, os dados da tabela incremental não fossem adicionados ao hdfs.
Após iniciar o Maxwell , basta executar o script hdfs_to_ods_db.sh.
{"id":"3","login_name":"tws1uxb5r","nick_name":"进林","passwd":null,"real_name":"贺进林","phone_num":"13443888468","email":"[email protected]","head_img":null,"user_level":"1","birthday":"1987-06-16","gender":null,"create_time":"2022-02-16 00:00:00","operate_time":null,"status":null}
{
"id":"3",
"login_name":"tws1uxb5r",
"nick_name":"进林",
"passwd":null,
"real_name":"贺进林",
"phone_num":"13443888468",
"email":"[email protected]",
"head_img":null,
"user_level":"1",
"birthday":"1987-06-16",
"gender":null,
"create_time":"2022-02-16 00:00:00",
"operate_time":null,
"status":null
}--8.9 用户维度表(拉链表)
DROP TABLE IF EXISTS dim_user_zip;
CREATE EXTERNAL TABLE dim_user_zip
(
`id` STRING COMMENT '编号',
`login_name` STRING COMMENT '用户名称',
`nick_name` STRING COMMENT '用户昵称',
`real_name` STRING COMMENT '用户姓名',
`phone_num` STRING COMMENT '手机号',
`email` STRING COMMENT '邮箱',
`user_level` STRING COMMENT '用户级别',
`birthday` STRING COMMENT '用户生日',
`gender` STRING COMMENT '性别 M男,F女',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间',
`status` STRING COMMENT '状态',
`start_date` STRING COMMENT '开始日期',
`end_date` STRING COMMENT '结束日期'
) COMMENT '用户表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/edu/dim/dim_user_zip/'
TBLPROPERTIES ('orc.compress' = 'snappy');
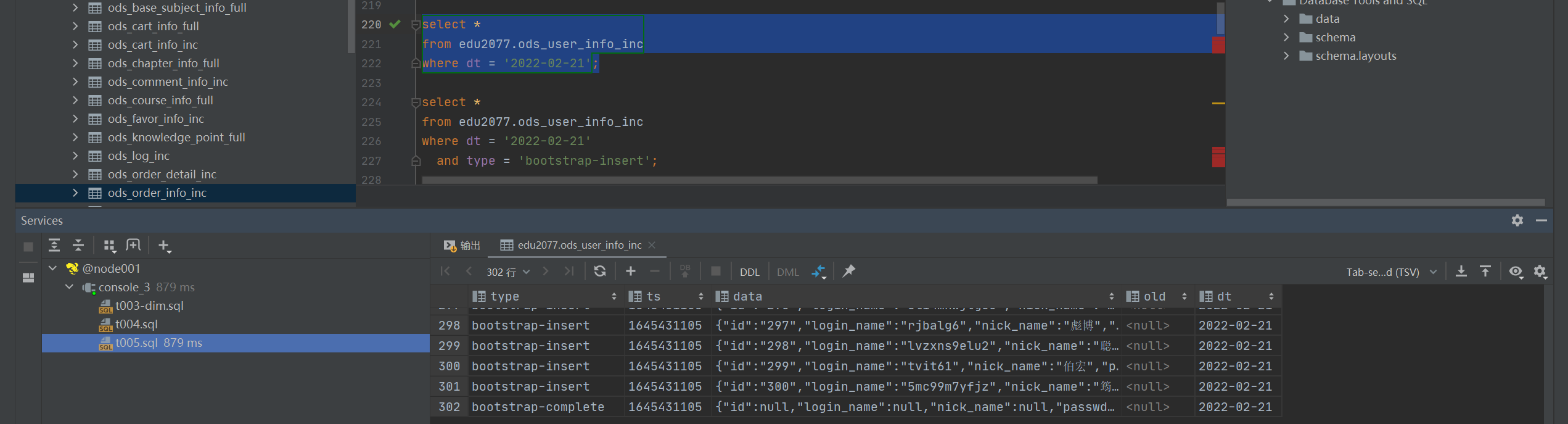
select * from edu2077.ods_user_info_inc
where dt = '2022-02-21';
select * from edu2077.ods_user_info_inc
where dt = '2022-02-21'
and type = 'bootstrap-insert';
select data.id,
data.login_name,
data.nick_name,
data.passwd,
data.real_name,
data.phone_num,
data.email,
data.head_img,
data.user_level,
data.birthday,
data.gender,
data.create_time,
data.operate_time,
data.status
from edu2077.ods_user_info_inc
where dt = '2022-02-21'
and type = 'bootstrap-insert';
insert overwrite table edu2077.dim_user_zip partition (dt = '9999-12-31')
select data.id,
data.login_name,
data.nick_name,
md5(data.real_name),
md5(if(data.phone_num regexp '^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\\d{8}$',
data.phone_num, null)),
md5(if(data.email regexp '^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\\.[a-zA-Z0-9_-]+)+$', data.email, null)),
data.user_level,
data.birthday,
data.gender,
data.create_time,
data.operate_time,
data.status,
'2022-02-21' start_date,
'9999-12-31' end_date
from edu2077.ods_user_info_inc
where dt = '2022-02-21'
and type = 'bootstrap-insert';
select * from dim_user_zip;P047
8.9 Tabela de dimensões do usuário (tabela de zíper)
(4) Carregamento diário
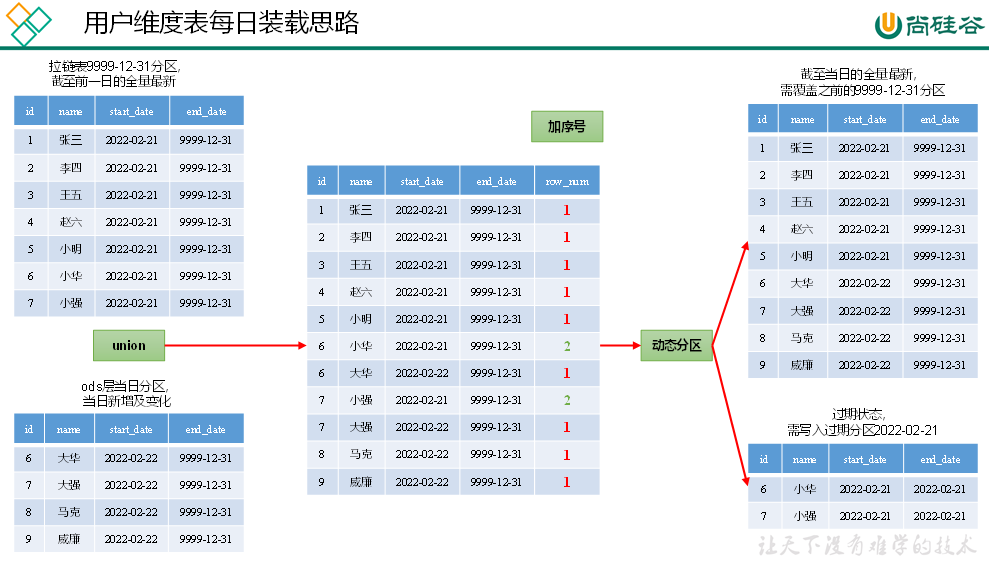
--8.9 用户维度表(拉链表)
--(4)每日装载
select *
from edu2077.ods_user_info_inc
where dt = '2022-02-21';
select *
from edu2077.ods_user_info_inc
where dt = '2022-02-22';
select *
from dim_user_zip
where dt = '9999-12-31';
select data.id,
data.login_name,
data.nick_name,
md5(data.real_name),
md5(if(data.phone_num regexp '^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\\d{8}$',
data.phone_num, null)),
md5(if(data.email regexp '^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\\.[a-zA-Z0-9_-]+)+$', data.email, null)),
data.user_level,
data.birthday,
data.gender,
data.create_time,
data.operate_time,
data.status,
'2022-02-21' start_date,
'9999-12-31' end_date
from edu2077.ods_user_info_inc
where dt = '2022-02-22';
select id,
login_name,
nick_name,
real_name,
phone_num,
email,
user_level,
birthday,
gender,
create_time,
operate_time,
status,
start_date
from dim_user_zip
where dt = '9999-12-31'
union
select data.id,
data.login_name,
data.nick_name,
md5(data.real_name),
md5(if(data.phone_num regexp '^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\\d{8}$',
data.phone_num, null)),
md5(if(data.email regexp '^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\\.[a-zA-Z0-9_-]+)+$', data.email, null)),
data.user_level,
data.birthday,
data.gender,
data.create_time,
data.operate_time,
data.status,
'2022-02-21' start_date,
'9999-12-31' end_date
from edu2077.ods_user_info_inc
where dt = '2022-02-22';
set hive.exec.dynamic.partition.mode=nonstrict;--关闭严格模式
insert overwrite table edu2077.dim_user_zip partition (dt)
select id,
login_name,
nick_name,
real_name,
phone_num,
email,
user_level,
birthday,
gender,
create_time,
operate_time,
status,
start_date,
if(rn = 1, '9999-12-31', date_sub('2022-02-22', 1)) end_date,
if(rn = 1, '9999-12-31', date_sub('2022-02-22', 1)) dt
from (
select id,
login_name,
nick_name,
real_name,
phone_num,
email,
user_level,
birthday,
gender,
create_time,
operate_time,
status,
start_date,
end_date,
row_number() over (partition by id order by start_date desc) rn
from (
select id,
login_name,
nick_name,
real_name,
phone_num,
email,
user_level,
birthday,
gender,
create_time,
operate_time,
status,
start_date,
end_date
from edu2077.dim_user_zip
where dt = '9999-12-31'
union
select id,
login_name,
nick_name,
real_name,
phone_num,
email,
user_level,
birthday,
gender,
create_time,
operate_time,
status,
'2020-02-22' start_date,
'9999-12-31' end_date
from (
select data.id,
data.login_name,
data.nick_name,
md5(data.real_name) real_name,
md5(if(data.phone_num regexp
'^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\\d{8}$',
data.phone_num, null)) phone_num,
md5(if(data.email regexp '^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\\.[a-zA-Z0-9_-]+)+$',
data.email, null)) email,
data.user_level,
data.birthday,
data.gender,
data.create_time,
data.operate_time,
data.status,
row_number() over (partition by data.id order by ts desc) rn
from edu2077.ods_user_info_inc
where dt = '2022-02-22'
) t1
where rn = 1
) t2
) t3;P048
8.10 Script de carregamento de dados
8.10.1 Script de carregamento do primeiro dia
8.10.2 Script de carregamento diário
#vim ods_to_dim_init.sh
#!/bin/bash
if [ -n "$2" ] ;then
do_date=$2
else
echo "请传入日期参数"
exit
fi
APP=edu
dim_chapter_full="
insert overwrite table ${APP}.dim_chapter_full
partition (dt = '$do_date')
select id,
chapter_name,
course_id,
video_id,
publisher_id,
is_free,
create_time,
update_time
from ${APP}.ods_chapter_info_full
where deleted = '0'
and dt = '$do_date';"
dim_course_full="
with a as
(
select id, category_name
from ${APP}.ods_base_category_info_full
where deleted = '0'
and dt = '$do_date'
),
b as
(
select id, subject_name, category_id
from ${APP}.ods_base_subject_info_full
where deleted = '0'
and dt = '$do_date'
),
c as
(
select id,
course_name,
subject_id,
teacher,
publisher_id,
chapter_num,
origin_price,
reduce_amount,
actual_price,
create_time,
update_time
from ${APP}.ods_course_info_full
where deleted = '0'
and dt = '$do_date'
),
d as
(
select course_id,
collect_set(named_struct('chapter_id', id, 'chapter_name', chapter_name, 'video_id', video_id, 'is_free', is_free)) chapters
from ${APP}.ods_chapter_info_full
where deleted = '0'
and dt = '$do_date'
group by course_id
)
insert overwrite table ${APP}.dim_course_full
partition(dt = '$do_date')
select c.id,
course_name,
subject_id,
subject_name,
category_id,
category_name,
teacher,
publisher_id,
chapter_num,
origin_price,
reduce_amount,
actual_price,
create_time,
update_time,
chapters
from c
left join b
on c.subject_id = b.id
left join a
on b.category_id = a.id
left join d
on c.id = d.course_id;"
dim_video_full="
insert overwrite table ${APP}.dim_video_full partition (dt = '$do_date')
select vt.id,
video_name,
during_sec,
video_status,
video_size,
version_id,
chapter_id,
chapter_name,
is_free,
course_id,
publisher_id,
create_time,
update_time
from (
select id,
video_name,
during_sec,
video_status,
video_size,
version_id,
chapter_id,
course_id,
publisher_id,
create_time,
update_time
from ${APP}.ods_video_info_full
where dt = '$do_date' and deleted = '0'
) vt
join
(
select id,
chapter_name,
is_free
from ${APP}.ods_chapter_info_full
where dt = '$do_date'
) cht
on vt.chapter_id = cht.id;"
dim_paper_full="
insert overwrite table ${APP}.dim_paper_full partition (dt = '$do_date')
select t1.id,
paper_title,
course_id,
create_time,
update_time,
publisher_id,
questions
from ${APP}.ods_test_paper_full t1
left join
(
select paper_id,
collect_set(named_struct('question_id', question_id, 'score', score)) questions
from ${APP}.ods_test_paper_question_full
where deleted = '0' and dt = '$do_date'
group by paper_id
) t2
on t1.id = t2.paper_id
where t1.deleted = '0' and t1.dt = '$do_date';"
dim_source_full="
insert overwrite table ${APP}.dim_source_full partition (dt = '$do_date')
select id,
source_site
from ${APP}.ods_base_source_full obsf
where dt = '$do_date';"
dim_question_full="
insert overwrite table ${APP}.dim_question_full
partition (dt = '$do_date')
select id,
chapter_id,
course_id,
question_type,
create_time,
update_time,
publisher_id
from ${APP}.ods_test_question_info_full
where deleted = '0'
and dt = '$do_date';"
dim_province_full="
insert overwrite table ${APP}.dim_province_full partition (dt = '$do_date')
select id,
name,
region_id,
area_code,
iso_code,
iso_3166_2
from ${APP}.ods_base_province_full
where dt = '$do_date';"
dim_user_zip="
insert overwrite table ${APP}.dim_user_zip
partition (dt = '9999-12-31')
select data.id,
data.login_name,
data.nick_name,
md5(data.real_name),
md5(if(data.phone_num regexp '^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\\d{8}$',data.phone_num,null)),
md5(if(data.email regexp '^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\\.[a-zA-Z0-9_-]+)+$',data.email,null)),
data.user_level,
data.birthday,
data.gender,
data.create_time,
data.operate_time,
data.status,
'$do_date' start_date,
'9999-12-31' end_date
from ${APP}.ods_user_info_inc
where dt = '$do_date'
and type = 'bootstrap-insert';"
case $1 in
dim_chapter_full|dim_course_full|dim_video_full|dim_paper_full|dim_source_full|dim_question_full|dim_province_full|dim_user_zip)
eval "hive -e \"\$$1\""
;;
"all" )
hive -e "${dim_chapter_full}${dim_course_full}${dim_video_full}${dim_paper_full}${dim_source_full}${dim_question_full}${dim_province_full}${dim_user_zip}"
;;
esac#vim ods_to_dim.sh
#!/bin/bash
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d "-1 day" +%F`
fi
APP=edu
dim_chapter_full="
insert overwrite table ${APP}.dim_chapter_full
partition (dt = '$do_date')
select id,
chapter_name,
course_id,
video_id,
publisher_id,
is_free,
create_time,
update_time
from ${APP}.ods_chapter_info_full
where deleted = '0'
and dt = '$do_date';"
dim_course_full="
with a as
(
select id, category_name
from ${APP}.ods_base_category_info_full
where deleted = '0'
and dt = '$do_date'
),
b as
(
select id, subject_name, category_id
from ${APP}.ods_base_subject_info_full
where deleted = '0'
and dt = '$do_date'
),
c as
(
select id,
course_name,
subject_id,
teacher,
publisher_id,
chapter_num,
origin_price,
reduce_amount,
actual_price,
create_time,
update_time
from ${APP}.ods_course_info_full
where deleted = '0'
and dt = '$do_date'
),
d as
(
select course_id,
collect_set(named_struct('chapter_id', id, 'chapter_name', chapter_name, 'video_id', video_id, 'is_free', is_free)) chapters
from ${APP}.ods_chapter_info_full
where deleted = '0'
and dt = '$do_date'
group by course_id
)
insert overwrite table ${APP}.dim_course_full
partition(dt = '$do_date')
select c.id,
course_name,
subject_id,
subject_name,
category_id,
category_name,
teacher,
publisher_id,
chapter_num,
origin_price,
reduce_amount,
actual_price,
create_time,
update_time,
chapters
from c
left join b
on c.subject_id = b.id
left join a
on b.category_id = a.id
left join d
on c.id = d.course_id;"
dim_video_full="
insert overwrite table ${APP}.dim_video_full partition (dt = '$do_date')
select vt.id,
video_name,
during_sec,
video_status,
video_size,
version_id,
chapter_id,
chapter_name,
is_free,
course_id,
publisher_id,
create_time,
update_time
from (
select id,
video_name,
during_sec,
video_status,
video_size,
version_id,
chapter_id,
course_id,
publisher_id,
create_time,
update_time
from ${APP}.ods_video_info_full
where dt = '$do_date' and deleted = '0'
) vt
join
(
select id,
chapter_name,
is_free
from ${APP}.ods_chapter_info_full
where dt = '$do_date'
) cht
on vt.chapter_id = cht.id;"
dim_paper_full="
insert overwrite table ${APP}.dim_paper_full partition (dt = '$do_date')
select t1.id,
paper_title,
course_id,
create_time,
update_time,
publisher_id,
questions
from ${APP}.ods_test_paper_full t1
left join
(
select paper_id,
collect_set(named_struct('question_id', question_id, 'score', score)) questions
from ${APP}.ods_test_paper_question_full
where deleted = '0' and dt = '$do_date'
group by paper_id
) t2
on t1.id = t2.paper_id
where t1.deleted = '0' and t1.dt = '$do_date';"
dim_source_full="
insert overwrite table ${APP}.dim_source_full partition (dt = '$do_date')
select id,
source_site
from ${APP}.ods_base_source_full obsf
where dt = '$do_date';"
dim_question_full="
insert overwrite table ${APP}.dim_question_full
partition (dt = '$do_date')
select id,
chapter_id,
course_id,
question_type,
create_time,
update_time,
publisher_id
from ${APP}.ods_test_question_info_full
where deleted = '0'
and dt = '$do_date';"
dim_province_full="
insert overwrite table ${APP}.dim_province_full partition (dt = '$do_date')
select id,
name,
region_id,
area_code,
iso_code,
iso_3166_2
from ${APP}.ods_base_province_full
where dt = '$do_date';"
dim_user_zip="
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table ${APP}.dim_user_zip
partition(dt)
select
id,
login_name,
nick_name,
real_name,
phone_num,
email,
user_level,
birthday,
gender,
create_time,
operate_time,
status,
start_date,
if(rn=1,'9999-12-31',date_sub('$do_date',1)) end_date,
if(rn=1,'9999-12-31',date_sub('$do_date',1)) dt
from
(
select
id,
login_name,
nick_name,
real_name,
phone_num,
email,
user_level,
birthday,
gender,
create_time,
operate_time,
status,
start_date,
end_date,
row_number() over (partition by id order by start_date desc) rn
from
(
select
id,
login_name,
nick_name,
real_name,
phone_num,
email,
user_level,
birthday,
gender,
create_time,
operate_time,
status,
start_date,
end_date
from ${APP}.dim_user_zip
where dt='9999-12-31'
union
select
id,
login_name,
nick_name,
real_name,
phone_num,
email,
user_level,
birthday,
gender,
create_time,
operate_time,
status,
'2020-02-22' start_date,
'9999-12-31' end_date
from
(
select
data.id,
data.login_name,
data.nick_name,
md5(data.real_name) real_name,
md5(if(data.phone_num regexp '^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\\d{8}$',data.phone_num,null)) phone_num,
md5(if(data.email regexp '^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\\.[a-zA-Z0-9_-]+)+$',data.email,null)) email,
data.user_level,
data.birthday,
data.gender,
data.create_time,
data.operate_time,
data.status,
row_number() over (partition by data.id order by ts desc) rn
from ${APP}.ods_user_info_inc
where dt='$do_date'
)t1
where rn=1
)t2
)t3;"
case $1 in
dim_chapter_full|dim_course_full|dim_video_full|dim_paper_full|dim_source_full|dim_question_full|dim_province_full|dim_user_zip)
eval "hive -e \"\$$1\""
;;
"all" )
hive -e "${dim_chapter_full}${dim_course_full}${dim_video_full}${dim_paper_full}${dim_source_full}${dim_question_full}${dim_province_full}${dim_user_zip}"
;;
esac