
iQiyi built a traditional offline data warehouse based on Hive to support the company's operational decisions, user growth, video recommendations, membership, advertising and other business needs. In recent years, as businesses have higher requirements for real-time data. We introduced data lake technology based on Iceberg to significantly improve data query performance and overall circulation efficiency. From a performance and cost perspective, migrating existing Hive tables to the data lake is necessary. However, over the years, hundreds of petabytes of Hive data have been accumulated on the big data platform. How to migrate Hive to the data lake has become a major challenge we face. This article introduces iQiyi's technical solution for smooth migration from Hive to Iceberg data lake, helping businesses accelerate data processes and improve efficiency and revenue.
01
Hive VS Iceberg
Hive is a Hadoop-based data warehouse and analysis platform that provides a SQL-like language to support complex data processing and analysis.
Iceberg is an open source data table format designed to provide scalable, stable and efficient table storage to support analytical workloads. Iceberg provides transactional guarantees and data consistency similar to traditional databases, and supports complex data operations such as updates, deletes, etc.
Table 1-1 lists the comparison between Hive and Iceberg in terms of timeliness, query performance, etc.:
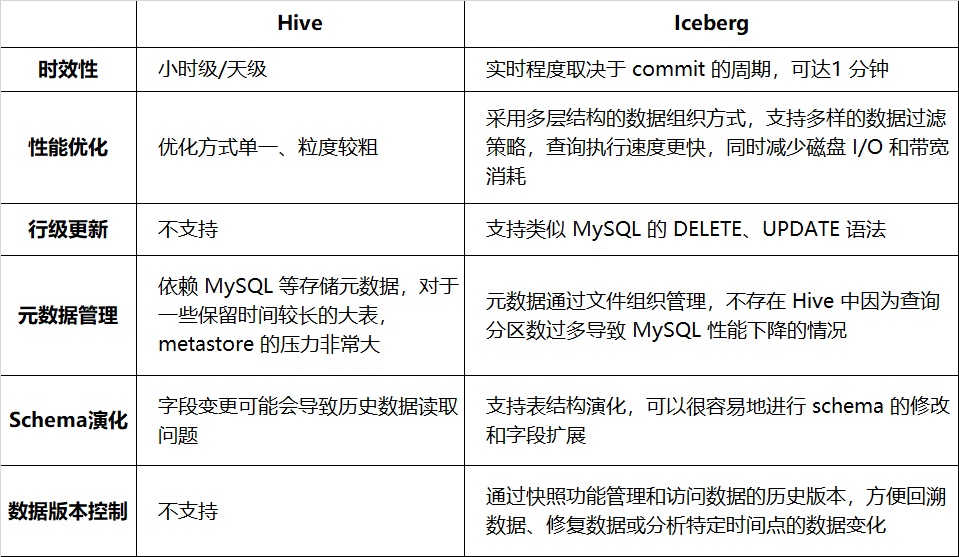
Table 1-1 Comparison between Hive and Iceberg
Switching to Iceberg can improve the efficiency and reliability of data processing and provide better support for complex data operations. Currently, it has been connected to more than a dozen businesses such as advertising, membership, Venus logs, and auditing. For more details about iQiyi’s Iceberg practice, you can read the previous series of articles (see citation at the end of the article).
02
Hive stock data smooth switching Iceberg
Iceberg has many advantages over Hive, but the business data is already running in the Hive environment, and the business does not want to invest a lot of manpower in modifying the inventory tasks. We have investigated common switching methods in the industry [1] and provided the ability to smoothly switch between self-service Hive and Iceberg on the data lake platform. This section will describe the specific implementation plan.
1. Check compatibility
Before the actual switch, we verified Spark's compatibility with Hive and Iceberg.
Spark's query and write syntax for Hive and Iceberg tables are basically the same. The SQL statements for querying Hive tables can query Iceberg tables without modification.
However, there are big differences between Iceberg and Hive in terms of DDL, mainly in the way of modifying the table structure. The details are as described in Table 2-1. There needs to be a one-to-one correspondence between the actual schema and the schema of the data file, otherwise it will affect the query of data. Therefore, you should be more cautious when processing DDL statements. It is not recommended to bind such DDL statements with tasks.
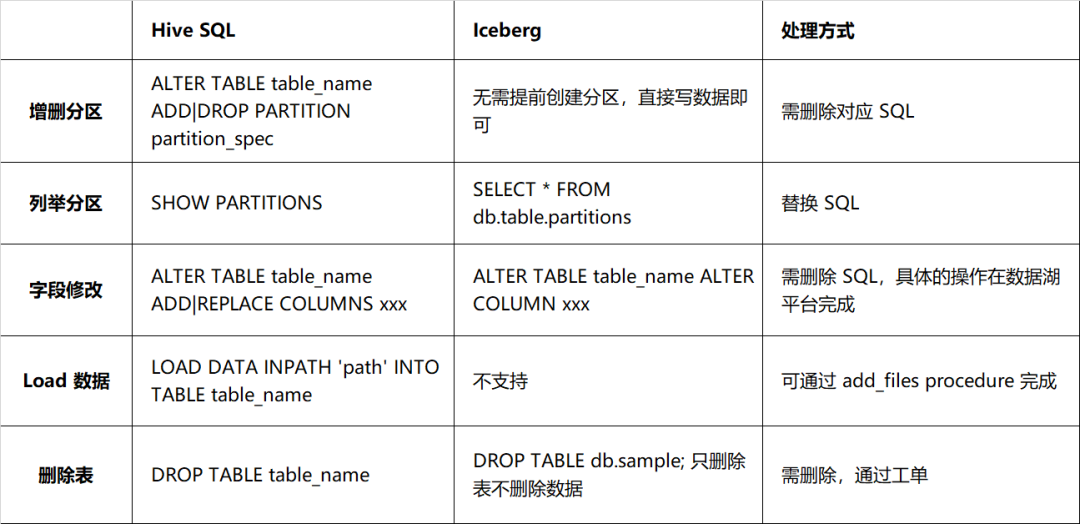
Table 2-1 Syntax compatibility comparison between Hive and Iceberg
2. Industry switching solution
2.1 Business double-write switching
The business replicates the existing pipeline to implement dual writing of Hive and Iceberg. After the old and new channel pairs are consistent, switch to the Iceberg channel and log off the original channel. This solution requires the business to invest manpower in development and calculation, which is time-consuming and labor-intensive.
2.2 Switch in place, client stops writing
If the business is allowed to stop writing for a period of time and switch, the following methods can be used:
-
Spark migrate procedure is a function officially provided by Iceberg, which can switch a Hive table to Iceberg in place. The example is as follows:
CALL catalog_name.system.migrate('db.sample'); |
This program does not modify the original data, it only scans the data of the original table and then constructs Iceberg metainformation, referencing the original file. Therefore, the migrate program executes very quickly, but the existing data cannot use features such as file indexes to speed up queries. If you want existing data to be accelerated as well, you can use Spark's rewrite_data_files method to rewrite historical data.
The migrate program does not delete the Hive table, but renames it to sample__BACKUP__. The __BACKUP__ suffix here is hard-coded. If you need to roll back, you can drop the newly created Iceberg table and rename the Hive table back.
-
Using the CTAS statement , the Spark example is as follows:
CREATE TABLE db.sample_iceberg USING Iceberg PARTITIONED BY dt LOCATION 'qbfs://....' TBLPROPERTIES('write.target-file-size-bytes' = '512m', ...) AS SELECT * FROM db.sample; |
After the writing is completed, the logarithm is performed. After the requirements are met, the switch is completed by renaming.
ALTER TABLE db.sample RENAME TO db.sample_backup; ALTER TABLE db.sample_iceberg RENAME TO db.sample; |
The advantage of CTAS compared to migrate is that the existing data is rewritten, so it can optimize partitioning, column sorting, file formats, small files, etc. The disadvantage is that if there is a lot of existing data, rewriting is time-consuming and resource-intensive.
The above two solutions have the following characteristics:
advantage:
The solution is simple, just execute existing SQL
Can be rolled back, the original Hive table is still there
shortcoming:
Write/Reader Not Validated: Write or query exceptions may occur after switching to Iceberg table
Requiring the switching process to stop writing is unacceptable for some businesses
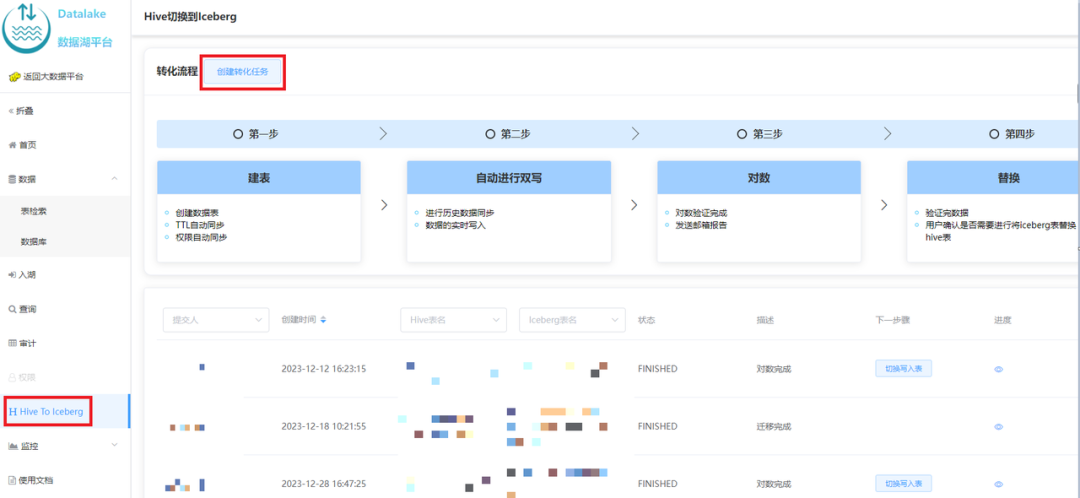
3. iQiyi smooth migration plan
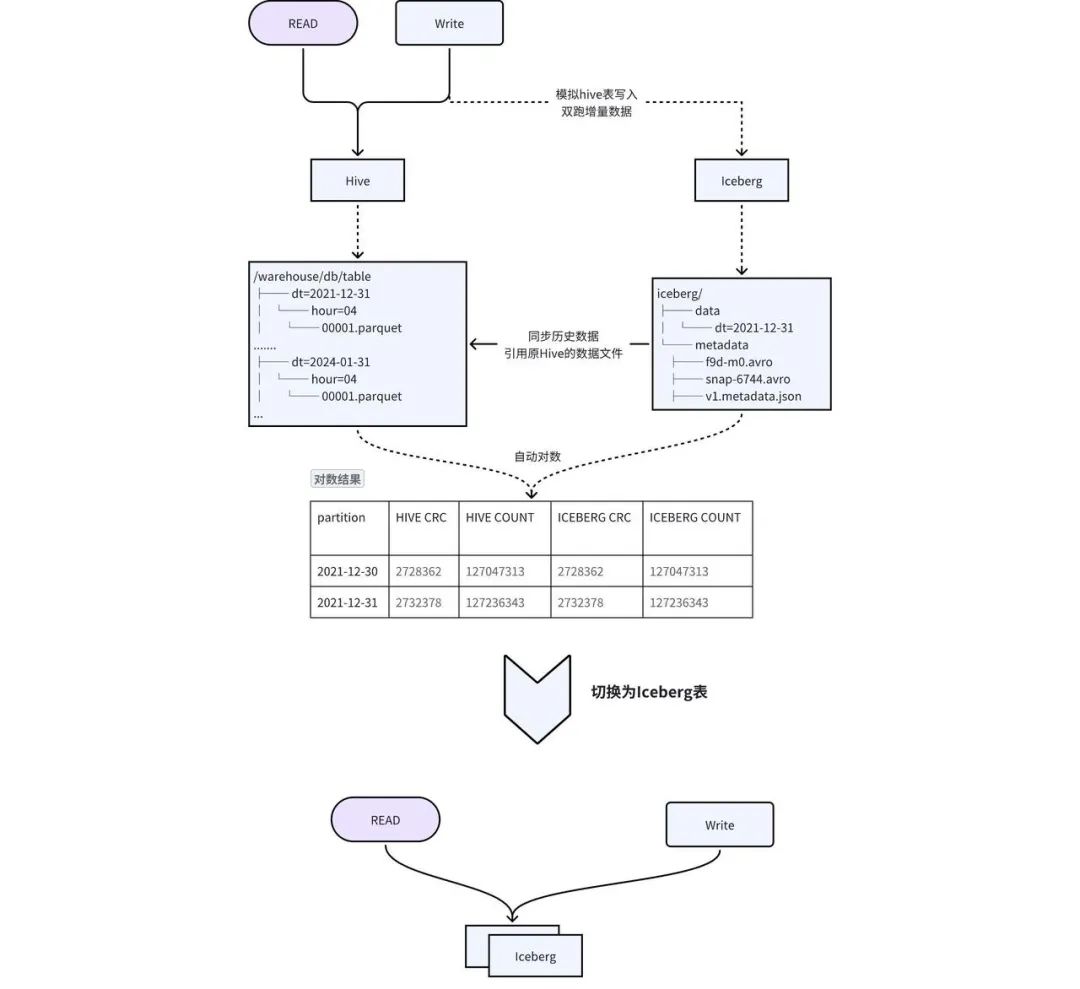
Considering the shortcomings of the above solution, we designed a solution of dual-write in place + transparent switching to achieve smooth migration, as shown in Figure 2-1:
-
Table creation : Create an Iceberg table with the same schema as Hive, and synchronize meta-information such as TTL and permissions of the Hive table to the Iceberg table. -
Migrating historical data to Iceberg : Hive historical data is added to Iceberg through the add_file procedure. This operation will construct Iceberg's metadata based on Hive data. In fact, Iceberg's metadata points to Hive's data files, reducing data redundancy. and historical data synchronization time. -
Incremental data double writing : iQIYI's self-developed Pilot SQL gateway detects writing tasks in the Hive table, automatically copies and writes SQL, and replaces the output with the Iceberg table to achieve double writing. -
数据一致性 校验: 当历史数据同步完成且增量双写到一定次数之后,后台会自动发起对数,校验 Hive 和 Iceberg 中的数据是否一致。对于历史数据与增量数据会选取一部分数据进行 count 以及字段 CRC 数值校验。 -
切换 : 数据一致性校验完成后,进行 Hive 和 Iceberg 的切换,用户不需要修改任务,直接使用原来的表名进行访问即可。正常切换过程耗时在几分钟之内。
03
核心收益 - 加速查询
1. Iceberg 查询加速技术
2. Iceberg 加速技巧
-
配置分区:使用分区剪裁的方式使查询只针对特定分区的数据执行,而不需要扫描整个数据集。 -
指定排序列:通过对数据分布进行合理的组织,最大限度的发挥文件级别的过滤效果,使得查询只集中在特定的文件。例如通过下面的方式使得写入 sample 表的数据按照 category, id 降序写入,注意由于多了一个排序的环节,这种方式会比非排序的写入耗时长。
|
|
-
高基数列应用布隆过滤器:在查询数据时,会自动应用布隆过滤器来快速验证查询数据是否存在于某个数据块,避免不必要的磁盘访问。
|
|
-
使用 Trino 代替 Spark:由于 Trino 自身 MPP 的架构,在查询上相较于 Spark 更有优势,并且 Trino 自身对 Iceberg 也有相应的优化,因此如果有秒级查询的需求,可将引擎由 Spark 切换到 Trino。 -
Alluxio 缓存:使用 Alluxio 作为数据缓存层,将数据缓存在内存中。在查询时可以直接从内存中获取数据,避免从磁盘读取数据的开销,可大大提高查询速度,也可防止 HDFS 抖动对任务的影响。 -
ORC 代替 Parquet:由于 Trino 对 ORC 格式有特定的优化,使得 ORC 的读取性能要优于 Parquet,可以将文件格式设置为 ORC 加速查询。 -
配置合并:写 Iceberg 的任务往往会出现写入文件较小但数量较多的情况,通过将小文件合并成一个或少量更大的文件,有利于减少读取的文件数,降低磁盘 I/O。
3. 性能评测
3.1 文件内过滤性能提升
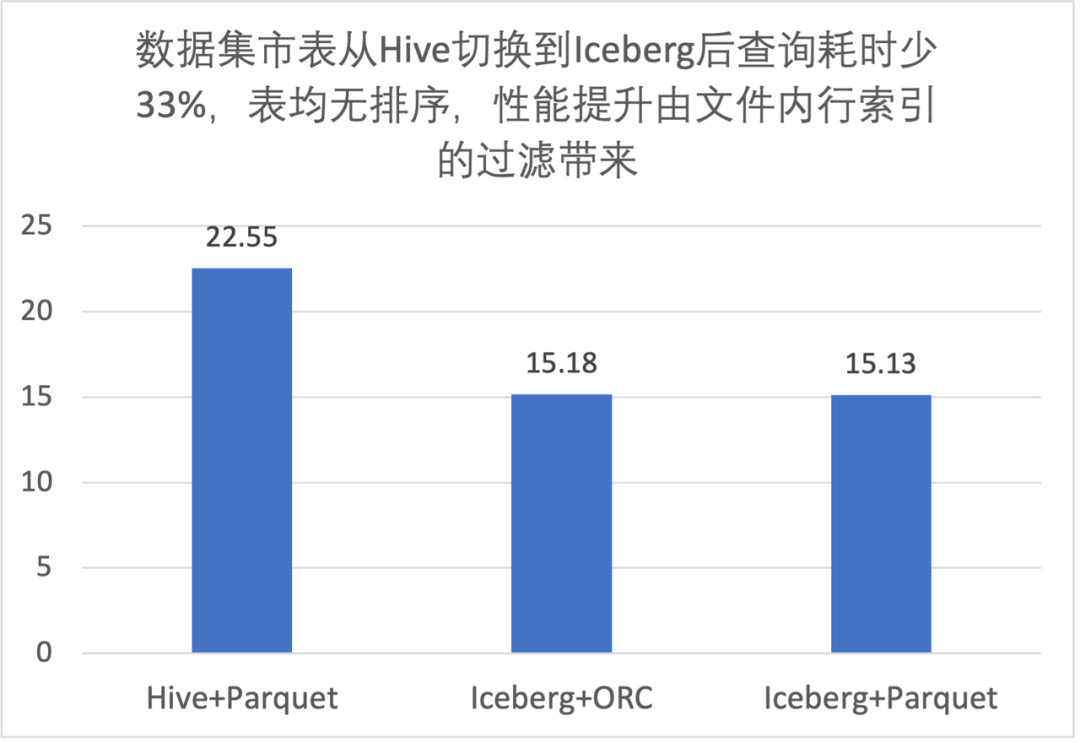
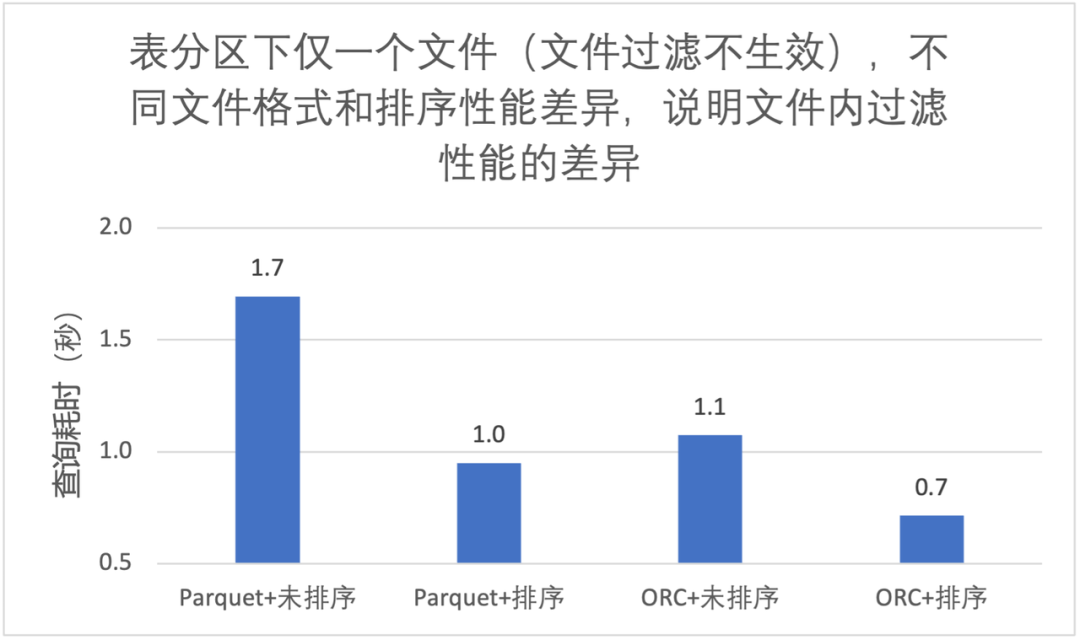
3.2 列排序对文件内过滤性能提升
-
同样的文件格式,排序后文件内过滤效果更好,大致能快 40%; -
ORC 查询性能优于 Parquet; -
使用 Trino 查询,我们推荐 Iceberg 表 + ORC 文件格式 + 列排序;
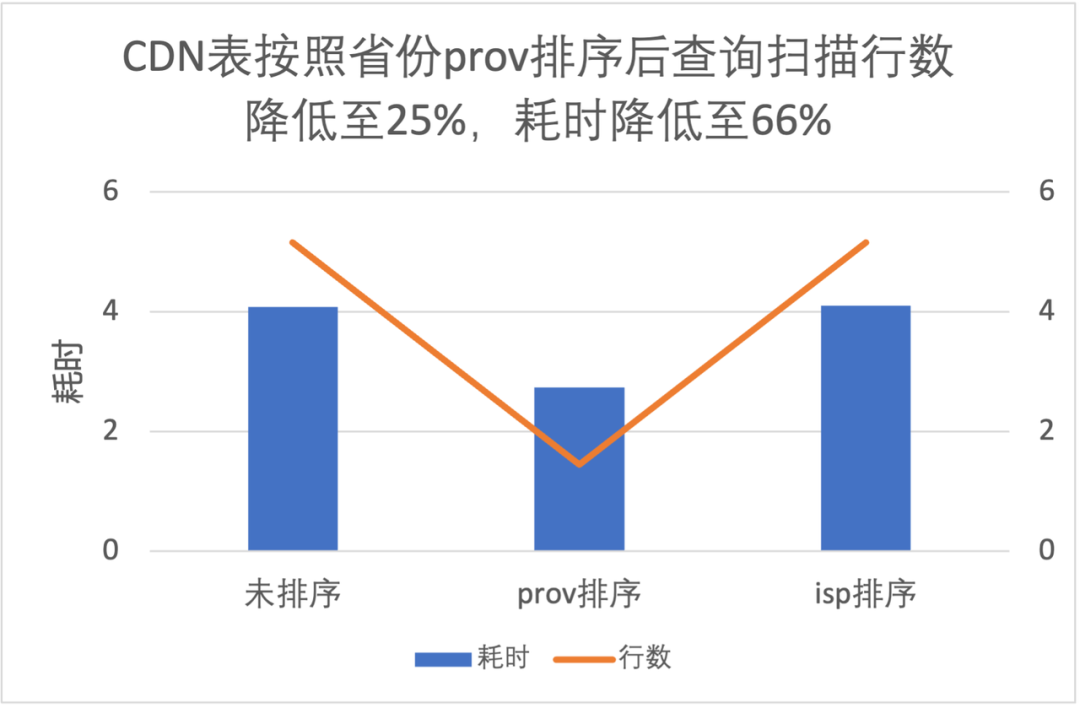
3.3 列排序对文件级过滤性能提升
|
|
-
按照 prov 排序查询读取数据量是不排序的 25%,耗时是 66%; -
按照 isp 排序提升不明显,这是因为 isp 数据量有明显的倾斜,条件中 isp 值占比高达 90%;
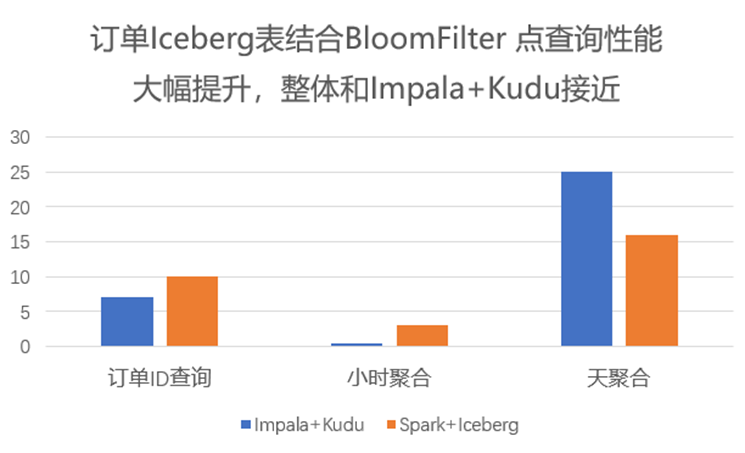
3.4 布隆过滤器的性能提升
3.5 Spark 和 Trino 性能比较
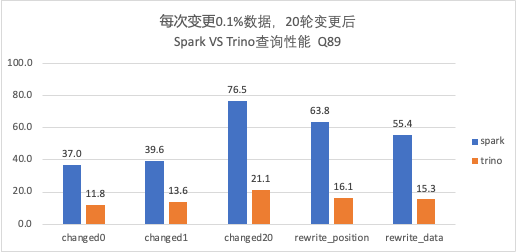
-
Trino 对于 V2 表查询结果与 Spark 一致,且在相同核数性能优于 Spark,耗时是 Spark 的 1/3 左右; -
随着变更轮次的增加(Data File 和 Postition Delete File 数量增加),Trino 查询性能也会逐渐变慢,需要定期进行合并。
04
核心收益 - 支持变更
1. 变更在业务使用场景
-
ETL 计算:如广告计费,通过接入 Iceberg 实现变更,简化业务逻辑,实现了更长时间范围的转化回收; -
数据修正:批量修正,如对某个数据的状态进行修改、批量删除等; -
隐私相关:如播放记录、搜索记录,用户需要删除历史条目等; -
CDC 同步:如订单业务,需要将 MySQL 中的数据进行大数据分析,通过 Flink CDC 技术很方便地将 MySQL 数据入湖,实时性可达到分钟级。
2. Hive 如何实现变更
-
分区覆写 例如修改某个 id 的相关内容,先筛选出要修改的目标行,更新后与历史数据进行合并,最后覆盖原表。这种方式对不需要修改的数据进行了重写,浪费计算资源;且覆写的粒度最小是分区级别,数据无法进一步细分,任务耗时相对较长。 -
标记删除 通常的做法是添加标志位,数据初始写入时标志位置 0,需要删除时,插入相同的数据,且标志位置 1,查询时过滤掉标志位为 1 的数据即可。这种方式在语义上未实现真正的删除,历史数据仍然保存在 Hive 中,浪费空间,而且查询语句较为复杂。
3. Iceberg 支持的变更类型
-
Delete:删除符合指定条件的数据,例如
|
|
-
Update:更新指定范围的数据,例如
|
|
-
MERGE:若数据已存在 UPDATE,不存在执行 INSERT,例如
|
|
4. Iceberg 变更策略
-
Copy on Write(写时合并):当进行删除或更新特定行时,包含这些行的数据文件将被重写。写入耗时取决于重写的数据文件数量,频繁变更会面临写放大问题。如果更新数据分布在大量不同的文件,那么更新的执行速度比较慢。这种方式由于结果文件数较少,读取的速度会比较快,适合频繁读取、低频批次更新的场景。 -
Merge on Read(读时合并):文件不会被重写,而是将更改写入新文件,当读取数据时,将新文件合并到原始数据文件得到最终结果。这使得写入速度更快,但读取数据时必须完成更多工作。写入新文件有两种方式,分别是记录删除某个文件对应的行(position delete)、记录删除的数据(equality detete)。 -
Position Delete:当前 Spark 的实现方式,记录变更对应的文件及行位置。这种方式不需要重写整个数据文件,只需找到对应数据的文件位置并记录,减少了写入的延迟,读取时合并的代价较小。 -
Equality Delete:当前 Flink 的实现方式,记录了删除数据行的主键。这种方式要求表必须有唯一的主键,写入过程无需查询数据文件,延迟最低;然而它的读取代价最大,这是由于读取时需要将 equality delete 记录和所有的原始文件进行 JOIN。
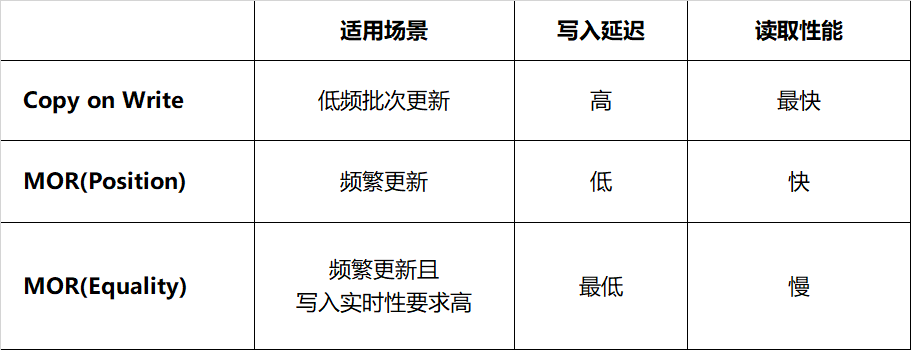 表 4-1 Iceberg 不同变更策略对比
表 4-1 Iceberg 不同变更策略对比
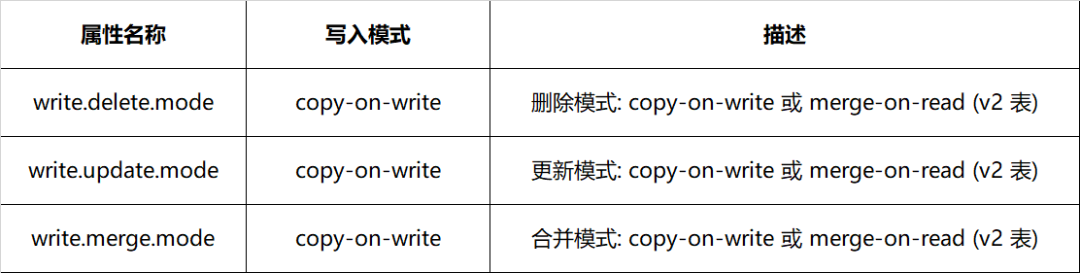 表 4-2 Iceberg 变更属性配置方式
表 4-2 Iceberg 变更属性配置方式
5. 业务接入
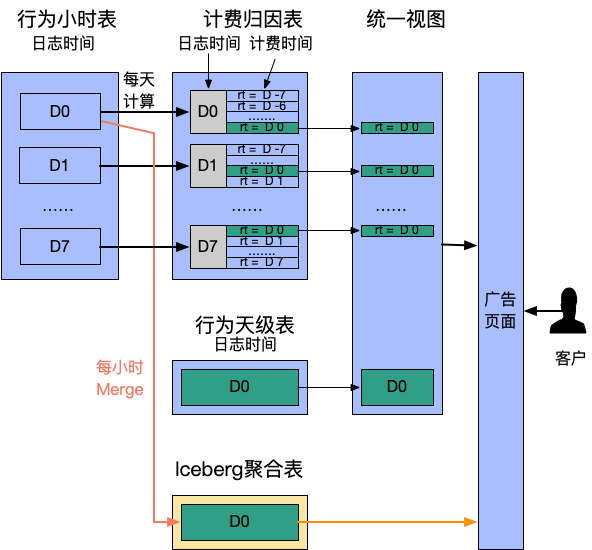
5.1 广告计费转换
-
每天触发一次计算,从行为表聚合出过去 7 天的“计费时间”数据。此处用 rt 字段代表计费时间 -
提供统一视图合并行为数据和计费时间数据,计费归因表 rt as dt 作为分区过滤查询条件,满足同时检索曝光和计费转化的需求
|
|
-
时效性提升:从天级缩短到小时级,客户更实时观察成本,有利于预算引入; -
计算更长周期数据:原先为计算效率仅提供 7 日内转换,而真实场景转换周期可能超过 1 个月; -
表语义清晰:多表联合变为单表查询。
5.2 数据修正
|
|
05
总结
06
引用
-
From Hive Tables to Iceberg Tables: Hassle-Free -
通过数据组织优化加速基于Apache Iceberg的大规模数据分析 -
Row-Level Changes on the Lakehouse: Copy-On-Write vs. Merge-On-Read in Apache Iceberg -
《爱奇艺数据湖实战 - 综述》 -
《爱奇艺数据湖实战 - 广告》 -
《爱奇艺数据湖实战 - 基于数据湖的日志平台架构演进》 -
《爱奇艺数据湖实战 - 数据湖技术在爱奇艺BI场景的应用》 -
《爱奇艺在Iceberg落地相关性能优化与实践》

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。