Data lake as we see it
As the data center team of iQiyi, our core task is to manage and service the large number of data assets within the company. In the process of implementing data governance, we continue to absorb new concepts and introduce cutting-edge tools to refine our data system management.
"Data lake" is a concept that has been widely discussed in the data field in recent years, and its technical aspects have also received widespread attention from the industry. Our team has conducted in-depth research on the theory and practice of data lakes. We believe that data lakes are not only a new perspective on data management, but also a promising technology for integrating and processing data.
Data lake is an idea of data governance
The purpose of implementing a data lake is to provide an efficient storage and management solution to bring the ease of use and availability of data to a new level.
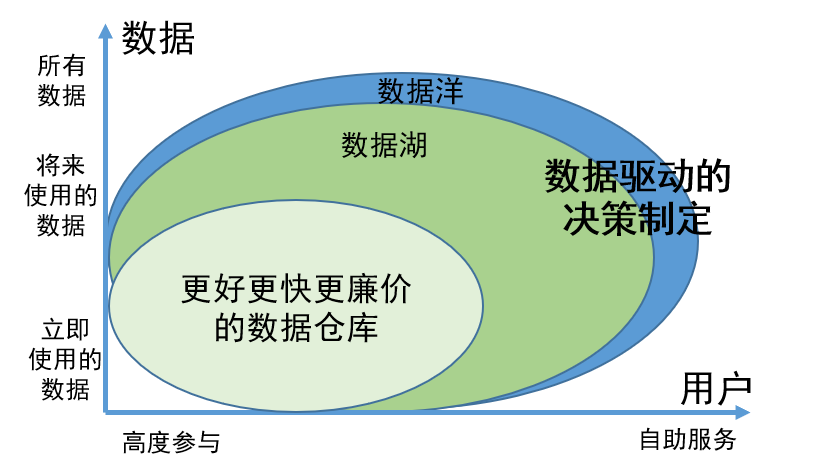
As an innovative data governance concept, the value of data lake is mainly reflected in the following two aspects:
1. The ability to comprehensively store all data, regardless of whether the data is being used or is temporarily unavailable, ensures that the required information can be easily found when needed and improves work efficiency;
2. The data in the data lake has been scientifically managed and organized, making it easier for users to find and use data on their own. This management model greatly reduces the involvement of data engineers. Users can complete the tasks of data search and use by themselves, thus saving a lot of human resources.
In order to manage all types of data more effectively, the data lake divides data into four core areas based on different characteristics and needs, namely original area, product area, work area and sensitive area:
Raw area
: This area is focused on meeting the needs of data engineers and professional data scientists, and its main purpose is to store raw, unprocessed data. When necessary, it can also be partially opened to support specific access requirements.
Product area
: Most of the data in the product area is processed and processed by data engineers, data scientists and business analysts to ensure the standardization and high degree of data management. This type of data is usually widely used in business reporting, data analysis, machine learning and other fields.
Work area
: The work area is mainly used to store intermediate data generated by various data workers. Here, users are responsible for managing their data to support flexible data exploration and experimentation to meet the needs of different user groups.
Sensitive area
: The sensitive area focuses on security and is mainly used to store sensitive data, such as personally identifiable information, financial data, and legal compliance data. This area is protected by the highest level of access control and security.
Through this division, the data lake can better manage different types of data while providing convenient data access and utilization to meet various needs.
Application of Data Lake Data Governance Ideas in Data Center
The goal of the data center is to solve problems such as inconsistent statistical calibers, repeated development, slow response to indicator development needs, low data quality, and high data costs caused by data surge and business expansion.
The goals of the data center and data lake are consistent. By combining the concept of data lake, the data system and overall architecture of the data center have been optimized and upgraded.
In the initial stage of data center construction, we integrated the company's data warehouse system, conducted in-depth research on the business, sorted out the existing field and dimension information, summarized the consistency dimensions, and established unified indicators system and formulated data warehouse construction specifications. According to this specification, we built the original data layer (ODS), detailed data layer (DWD), and aggregated data layer (MID) of the unified data warehouse, and established a device library, including an accumulated device library and a new device library. On the basis of the unified data warehouse, the data team built a theme data warehouse and business market based on different analysis and statistical directions and business needs. The subject data warehouse and business market include further processed detailed data, aggregated data, and application layer data tables. The data application layer uses these data to provide different services to users.
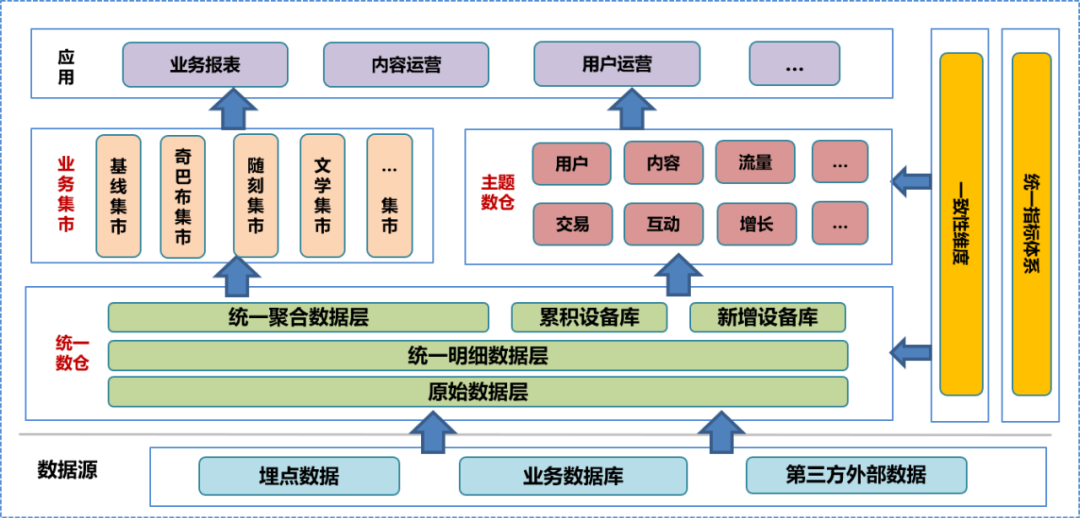
In a unified data warehouse system, the original data layer and
below
are not open to the public. Users can only use data engineers to process processed data, so it is inevitable that some data details will be lost.
In daily work, users with data analysis capabilities often want to access the underlying raw data to conduct personalized analysis or troubleshooting.
The data management concept of data lake can effectively solve this problem. After introducing the data governance idea of the data lake, we sorted out and integrated the existing data resources, enriched and expanded the data metadata, and built a data metadata center specifically for managing metadata. center.
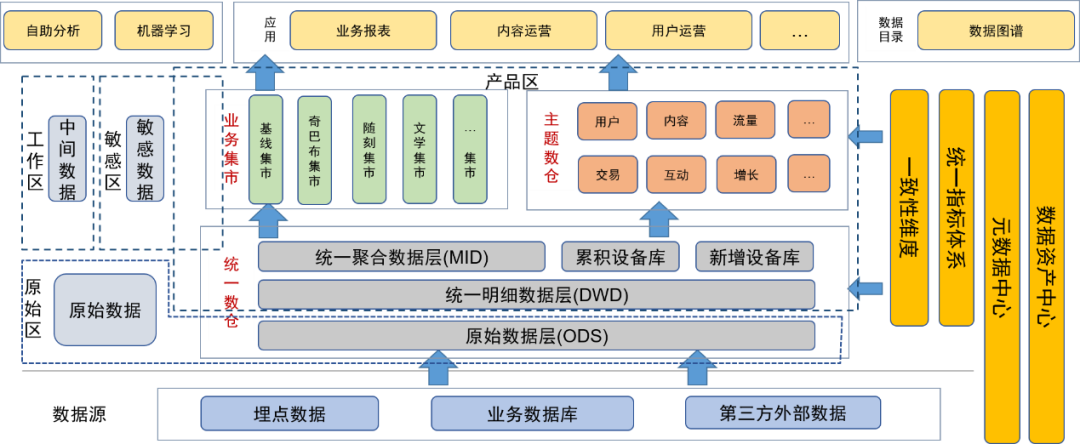
After introducing the data lake concept for data governance, we placed the original data layer and other original data (such as original log files) in the original data area. Users with data processing capabilities can apply for permission to use the data in this area.
The detailed layer, aggregation layer, theme data warehouse, and business mart of the unified data warehouse are placed in the product area. These data have been processed by the data engineers of the data team and provided to users as final data products. The data in this area has been processed by data management. , so the data quality is guaranteed.
We have also defined sensitive areas for sensitive data and focused on controlling access rights.
Temporary tables or personal tables generated daily by users and data developers are placed in the temporary area. These data tables are the responsibility of the users themselves and can be opened to other users conditionally.
The metadata of each data is maintained through the metadata center, including table information, field information, and the dimensions and indicators corresponding to the fields. At the same time, we also maintain data lineage, including table-level and field-level lineage relationships.
Maintain the asset characteristics of data through the data asset center, including management of data level, sensitivity, and permissions.
In order to facilitate users to better use data on their own, we provide a data map as a data directory at the application layer for users to query data, including metadata such as data usage, dimensions, indicators, and lineage. At the same time, the platform can also be used as a portal for permission application.
In addition, we also provide a self-service analysis platform to provide data users with self-service analysis capabilities.
While optimizing the data system, we also upgraded the data middle platform architecture based on the data lake concept.
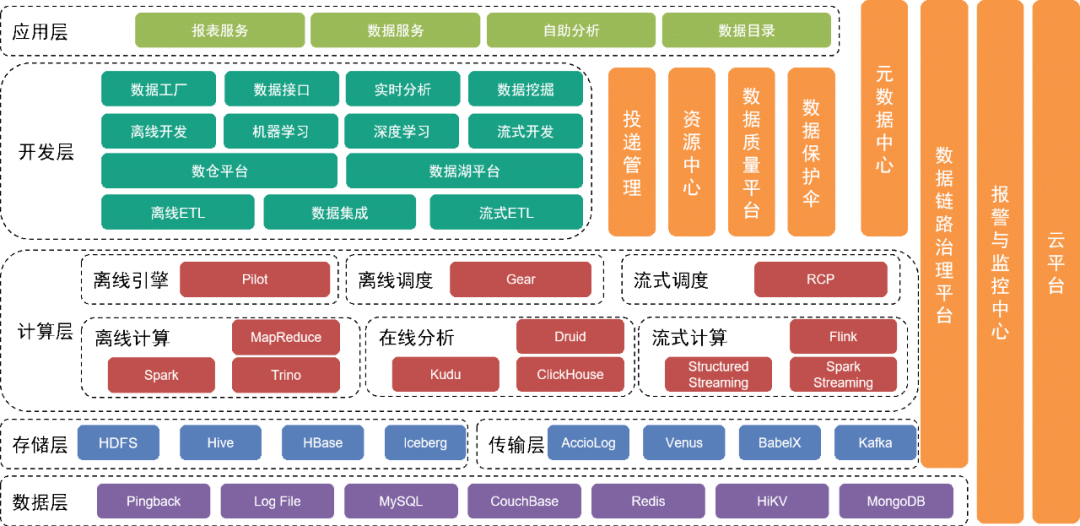
The bottom layer is the data layer , which includes various data sources, such as Pingback data, which is mainly used to collect user behavior. Business data is stored in various relational databases and NoSQL databases.
These data are stored in the storage layer through different collection tools in the transport layer.
Above the data layer is the storage layer
, which is mainly based on HDFS, a distributed file system, to store original files. Other structured or unstructured data is stored in Hive, Iceberg or HBase.
Further up is the computing layer
, which mainly uses the offline engine Pilot to drive Spark or Trino for offline calculations, and uses the scheduling engine Gear offline workflow engine for scheduled workflow scheduling. The RCP real-time computing platform is responsible for scheduling stream computing. After several rounds of iterations, flow computing currently mainly uses Flink as the computing engine.
The development layer above the computing layer
further encapsulates each service module of the computing layer and transmission layer to provide functions for developing offline data processing workflows, integrating data, developing real-time processing workflows, and developing machine learning engineering implementations. Tool suites and intermediate services to complete development work. The data lake platform manages the information of each data file and data table in the data lake, while the data warehouse platform manages the data warehouse data model, physical model, dimensions, indicators and other information.
At the same time, we provide a variety of management tools and services vertically. For example, the delivery management tool manages meta-information such as Pingback buried specifications, fields, dictionaries, and delivery timings; the metadata center, resource center and other modules are used to maintain data tables or data files. meta-information and ensure data security; the data quality center and link management platform monitor data quality and data link production status, promptly notify relevant teams for safeguards, and respond quickly to online problems and failures based on existing plans.
The underlying services are provided by the cloud service team to provide private cloud and public cloud support.
The upper layer of the architecture provides a data map as a data directory for users to find the data they need. In addition, we provide self-service applications such as Magic Mirror and Beidou to meet the needs of users at different levels for self-service data work.
After the transformation of the entire architecture system, data integration and management are more flexible and comprehensive. We reduce the user threshold by optimizing self-service tools, meet the needs of users at different levels, improve data usage efficiency, and enhance data value.
Application of data lake technology in data center
In a broad sense, data lake is a concept of data governance. In a narrow sense, data lake also refers to a data processing technology.
Data lake technology covers the storage format of data tables and the processing technology of data after entering the lake.
There are three main storage solutions in data lakes in the industry: Delta Lake, Hudi and Iceberg. A comparison of the three is as follows:
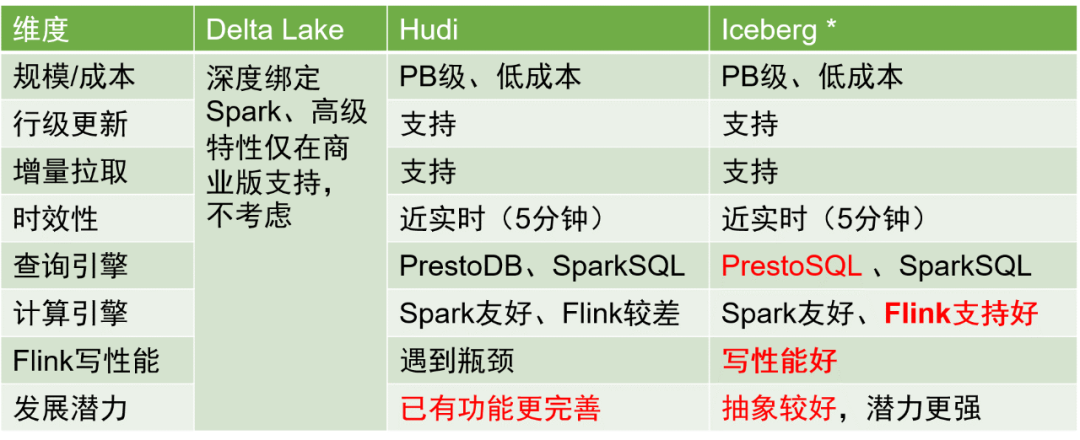
After comprehensive consideration, we chose Iceberg as the storage format of the data table.
Iceberg is a table storage format that organizes data files in the underlying file system or object store.
Here are the main comparisons between Iceberg and Hive:
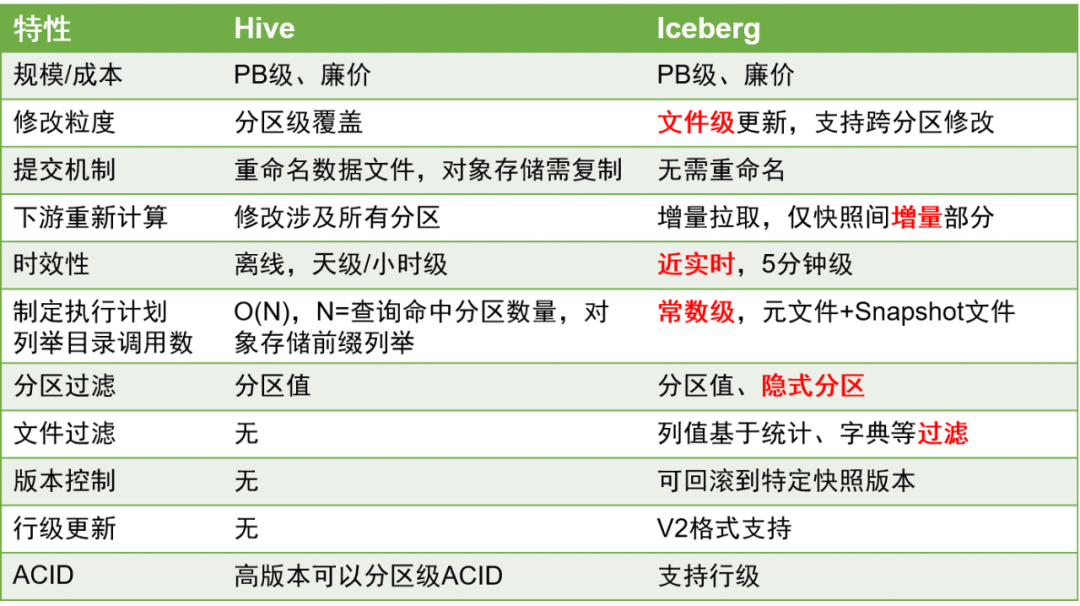
与Hive表相比,Iceberg表具有显著的优势,因为它能够更好地支持行级更新,数据时效性可以提高到分钟级别。
这在数据处理中具有重要意义,因为数据及时性的提升可以极大地改进数据处理ETL的效率。
Therefore, we can easily transform the existing Lambda architecture to achieve a streaming-batch integrated architecture:
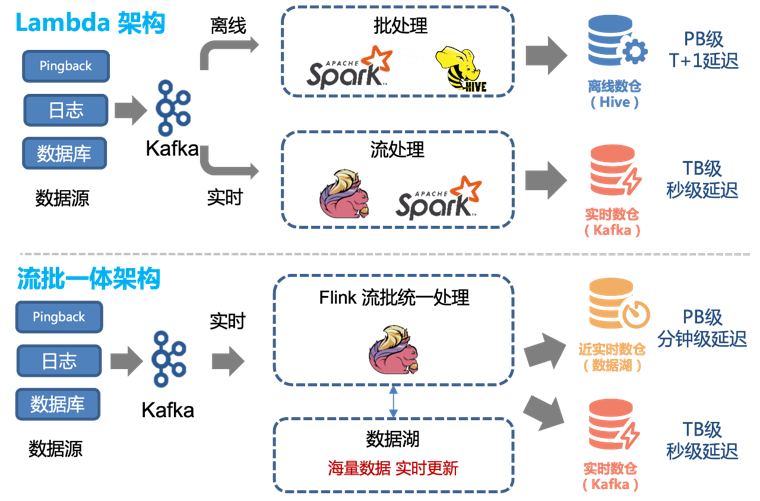
Before the introduction of data lake technology, we used a combination of offline processing and real-time processing to provide offline data warehouse and real-time data warehouse.
The full amount of data is constructed into data warehouse data through traditional offline analysis and processing methods,
and is stored in the cluster in the form of Hive tables.
For data with high real-time requirements, we produce it separately through real-time links and provide it to users in the form of Topics in Kafka.
However, this architecture has the following problems:
-
The two channels, real-time and offline, need to maintain two different sets of code logic. When the processing logic changes, both the real-time and offline channels need to be updated at the same time, otherwise data inconsistency will occur.
-
Hourly updates of offline links and a delay of about 1 hour mean that data at 00:01 may not be queried until 02:00. For some downstream services with high real-time requirements, this is unacceptable, so real-time links need to be supported.
-
Although the real-time performance of the real-time link can reach the second level, its cost is high. For most users, a five-minute update is sufficient. At the same time, consuming Kafka streams is not as convenient as directly operating data tables.
These problems can be better solved by using the integrated data processing method of Iceberg tables and streaming batches.

During the optimization process, we mainly performed Iceberg transformation on the ODS layer and DWD layer tables, and reconstructed the parsing and data processing into Flink tasks.
To ensure that the stability and accuracy of data production is not affected during the transformation process, we have taken the following measures:
1. Start switching with non-core data. Based on actual business conditions, we use QOS delivery and customized delivery as pilot projects.
2. By abstracting the offline parsing logic, a unified Pingback parsing storage SDK is formed, which realizes unified deployment of real-time and offline and makes the code more standardized.
3. After the Iceberg table and new production process were deployed, we ran dual-link parallel operations for two months and performed regular comparative monitoring of the data.
4. After confirming that there are no problems with data and production, we perform an imperceptible switch to the upper layer.
5. For the startup and playback data related to core data, we will carry out the integrated streaming and batch transformation after the overall verification is stable.
After the transformation, the benefits are as follows:
1. The qos and customized delivery data links have been implemented in near real-time as a whole. Data with an hourly delay can be updated at the five-minute level.
2. Except for special circumstances, the integrated streaming and batching link can meet real-time needs. Therefore, we can offline the existing real-time links and offline analysis links related to QOS and customization, thereby saving resources.
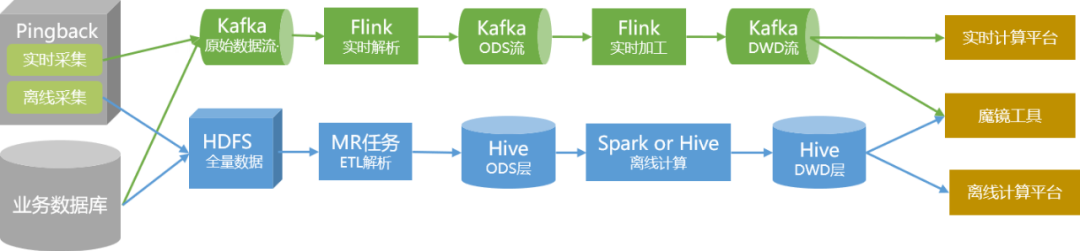
Through the transformation of data processing, our data link will be as shown in the figure below in the future:
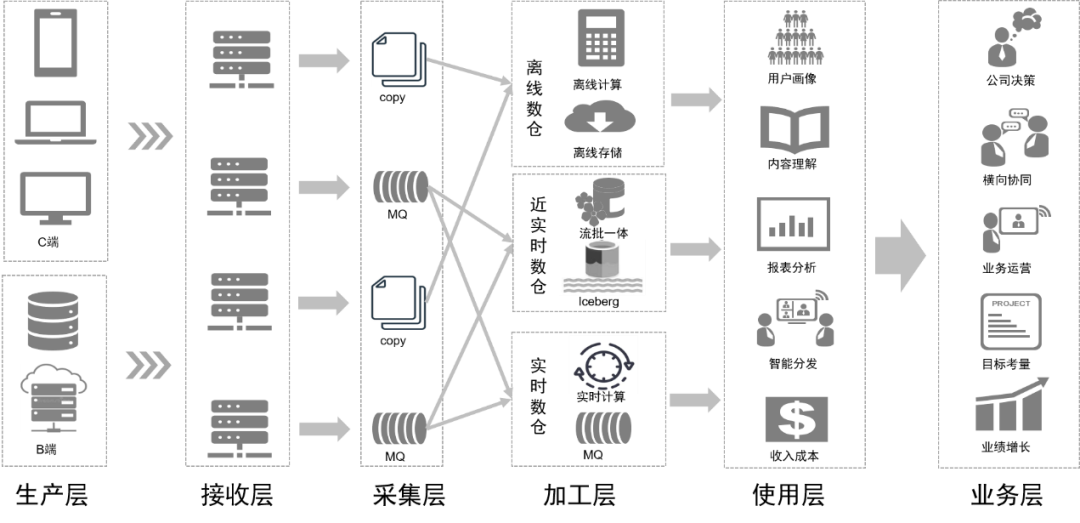
Follow-up planning
For the subsequent planning of data lake application in the data center, there are two main aspects:
From the architectural level, we will continue to refine the development of each module to make the data and services provided by the data center more comprehensive and easier to use, so that different users can use it conveniently;
At the technical level, we will continue to transform the data link into a stream-batch integration, and at the same time continue to actively introduce appropriate data technologies to improve data production and usage efficiency and reduce production costs.
6. Alex Gorelik. The Enterprise Big Data Lake.
Maybe you also want to see
This article is shared from the WeChat public account - iQIYI Technology Product Team (iQIYI-TP).
If there is any infringement, please contact [email protected] for deletion.
This article participates in the " OSC Source Creation Plan ". You who are reading are welcome to join and share together.
