Mistral AI recently released the first open source MoE model Mixtral8x7B and announced its launch in the MoDa community.
Mixtral-8x7B is a mixed expert model (Mixtrue of Experts), consisting of 8 expert networks with 7 billion parameters. In terms of capabilities, Mixtral-8x7B supports 32k token context length and supports English, French, Italian, German and Spanish, has excellent code generation capabilities and can be fine-tuned to an instruction following model.
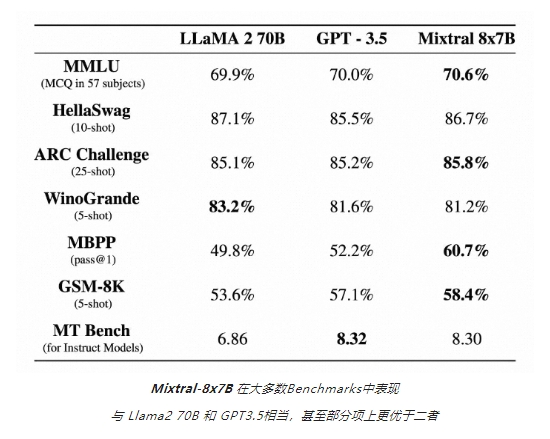
The model achieved a score of 8.3 on the MT-Bench evaluation, which is equivalent to GPT3.5.
Mixtral-8x7B-v0.1 model:
https://www.modelscope.cn/models/AI-ModelScope/Mixtral-8x7B-v0.1/summary
Mixtral-8x7B-Instruct-v0.1 model:
https://www.modelscope.cn/models/AI-ModelScope/Mixtral-8x7B-Instruct-v0.1/summary
Mistral-7B-Instruct-v0.2 new model:
https://www.modelscope.cn/models/AI-ModelScope/Mistral-7B-Instruct-v0.2/summary