1.1 ID positioning
The id attribute value of HTML Tag is unique, so there is no possibility of locating multiple elements based on id. The following is an example of entering the text "python" in the search box on Baidu homepage. The id attribute value of the search box is "kw", as shown in Figure 1.1:
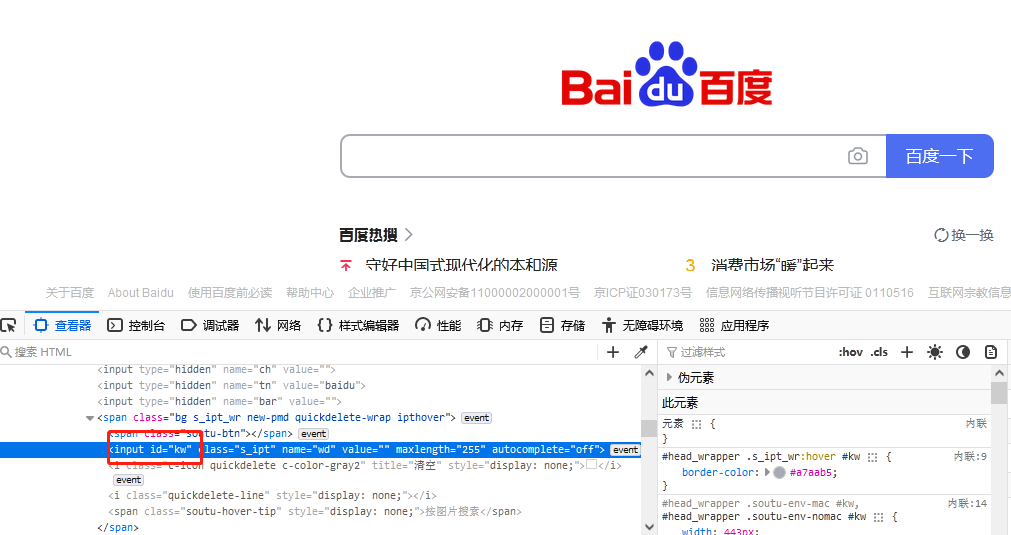
The code is as follows, the "find_element_by_id" method is obsolete, use find_element(By.ID, 'kw')
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Firefox()
# 需要将浏览器驱动添加到环境变量中
# 打开百度
driver.get('https://www.baidu.com/')
# 通过id,在搜索输入框中输入文本“python”
driver.find_element(By.ID, 'kw').send_keys('python')
# 点击搜索
driver.find_element(By.ID, 'su').click()
# 关闭浏览器
driver.close()1.2 name positioning
The above Baidu search box can also be implemented using name, as shown in Figure 1.1. Its name attribute value is "wd", and the method "find_element(By.NAME, 'wd')" means positioning by name
code show as below:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 通过name,在搜索输入框中输入文本“自动化测试”
driver.find_element(By.NAME, 'wd').send_keys('自动化测试')
# 点击搜索
driver.find_element(By.ID, 'su').click()
# 关闭浏览器
driver.close()Note: Positioning using the name method must ensure that the name value is unique, otherwise the positioning will fail.
1.3 class positioning
Take the Baidu homepage search box as an example, as shown in Figure 1.1, its class attribute value is "s_ipt", "By.CLASS_NAME, 's_ipt'" means positioning by class_name
code show as below:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 通过class,在搜索输入框中输入文本“web测试”
driver.find_element(By.CLASS_NAME, 's_ipt').send_keys('web测试')
# 点击搜索
driver.find_element(By.ID, 'su').click()
# 关闭浏览器
driver.close()1.4 link_text positioning
link_text uses the entire name of the hyperlink as a keyword to locate the element. Take the "News" hyperlink on Baidu's homepage as an example, as shown in Figure 1.2, the keyword is "News".
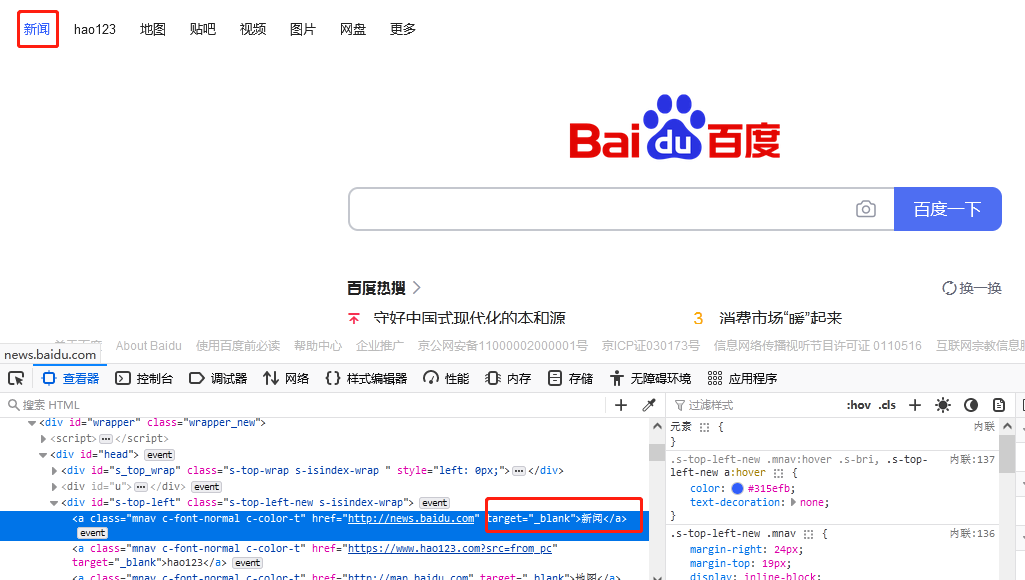
code show as below:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 通过link_text定位,点击‘新闻’超链接
driver.find_element(By.LINK_TEXT, '新闻').click()
# 关闭浏览器
driver.close()Note: To use this method to locate element hyperlinks, the Chinese characters must be written in full.
1.5 partial_link_text positioning
That is, part of the hyperlink text is used to locate the element, similar to a fuzzy query in a database. Taking the "news" hyperlink as an example, only the word "new" is needed, which is a subset of the entire text of the hyperlink.
code show as below:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 通过partial_link_text定位,用超链接文字的部分文本来定位元素,类似数据库的模糊查询
driver.find_element(By.PARTIAL_LINK_TEXT, '新').click()
# 关闭浏览器
driver.close()1.6 tag_name positioning
Tag_name positioning means positioning through the tag name. As shown in Figure 1.6, locate the tag "form" and print the tag attribute value "name".
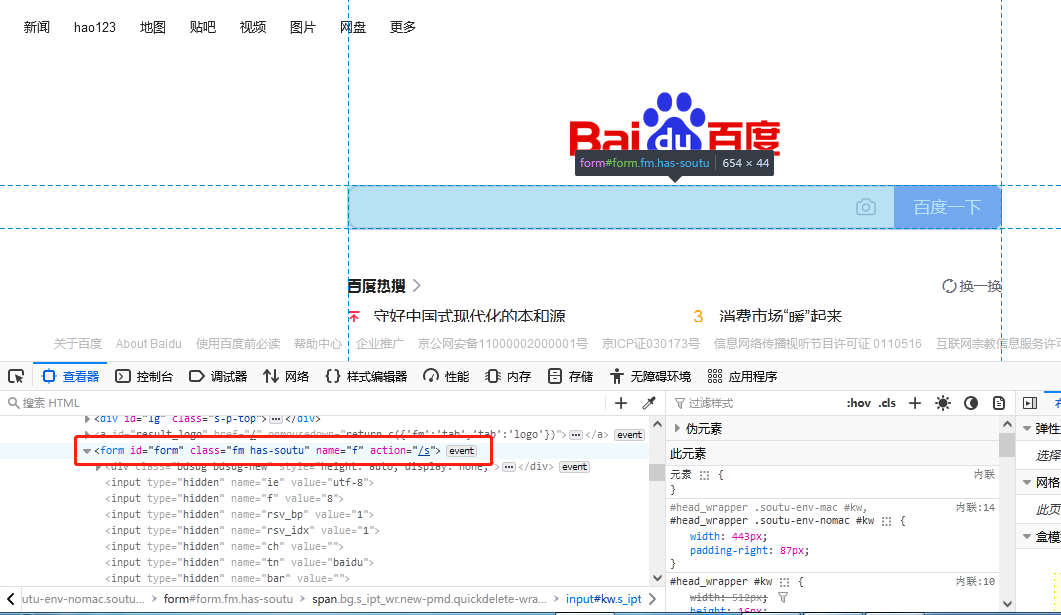
code show as below:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# tag_name 定位即通过标签名称定位
print(driver.find_element(By.TAG_NAME, 'form').get_attribute('name'))The console outputs "f" after success:

1.7 CSS positioning
The advantages of CSS positioning are fast speed and concise syntax. The content in Table 1.1 comes from W3School’s CSS Reference Manual. There are more than a dozen selectors for CSS positioning. This section mainly introduces several commonly used selectors.
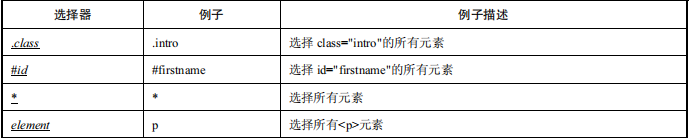
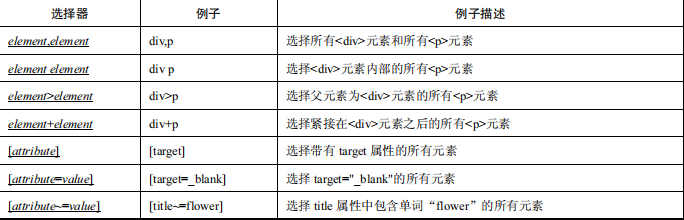
Still taking the Baidu search box as an example, the code is as follows:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 以class选择器为例,实现CSS定位,在搜索框输入“python3”
driver.find_element(By.CSS_SELECTOR, '.s_ipt').send_keys('python3')
# 以id定位语法结构为:#加 id 名,实现CSS定位,在搜索框输入“python3”
driver.find_element(By.CSS_SELECTOR, '#kw').send_keys('python3')
# CSS 定位主要利用属性 class 和 id 进行元素定位。也可以利用常规的标签名称来定位,如输入框标签“input”,在标签内部又设置了属性值为“name=’wd’”
driver.find_element(By.CSS_SELECTOR, "input[name='wd']").send_keys('python3')
# CSS 定位方式可以使用元素在页面布局中的绝对路径来实现元素定位。百度首页搜索输入框元素的绝对路
# 径为“html>body>div>div>div>div>div>form>span>input[name="wd"]”
driver.find_element(By.CSS_SELECTOR, 'html>body>div>div>div>div>div>form>span>input[name="wd"]').send_keys('python3')
# CSS 定位也可以使用元素在页面布局中的相对路径来实现元素定位。相对路径的写法和直接利用标签名称来定位,两者
# 的代码实现的功能是一致的
driver.find_element(By.CSS_SELECTOR, "input[name='wd']").send_keys('python3')
# 点击搜索
driver.find_element(By.ID, 'su').click()
# 关闭浏览器
driver.close()1.8 XPath positioning
The method of locating elements through XPath is very effective for elements that are difficult to locate, and can be solved in almost all cases, especially for some elements that do not have attributes such as id and name.
XPath is the abbreviation of XML Path language, which is a language used to determine the location of certain parts of XML documents. It searches through element names and attributes in XML documents, and its main purpose is to find nodes in XML documents. XPath positioning has greater flexibility than CSS positioning. XPath can search forward or backward, while CSS positioning can only search forward, but XPath positioning is slower than CSS.
The XPath language contains root nodes, elements, attributes, text, processing instructions, namespaces, etc. The following text is an XML example document used to demonstrate various node types of XML and facilitate understanding of XPath.
<?xml version = "1.0" encoding = "utf-8" ?>
<!-- 这是一个注释节点 -->
<animalList type="mammal">
<animal categoruy = "forest">
<name>Tiger</name>
<size>big</size>
<action>run</action>
</animal>
</animalList>Among them, <animalList> is the document node and also the root node; <name> is the element node; type="mammal" is the attribute node.
Relationship between nodes:
• Parent node. Each element has a parent node. In the XML example above, the animal element is the parent node of the name, size, and action elements.
• Child nodes. Contrary to the parent node, we will not go into details here.
• Sibling nodes, some are also called sibling nodes. It represents nodes that have the same parent node. As shown in the above code, the name, size and action elements are all sibling nodes.
• Ancestor nodes. It refers to the parent node of a node, or the parent node of a parent node, and so on. As shown in the above code, the ancestor nodes of the name element node are animal and animalList.
• Descendant nodes. It represents the child nodes of a node, the child nodes of child nodes, and so on. As shown in the above code, the descendant nodes of the animalList element node include animal, name, etc.
Still taking the Baidu search box as an example, the code is as follows:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# XPath 有多种定位策略,最简单直观的就是写出元素的绝对路径。
driver.find_element(By.XPATH, '/html/body/div/div/div/div/div/form/span/input').send_keys('python3')
# XPath还可以使用元素的属性值来定位。//input 表示当前页面某个 input 标签,[@id='kw'] 表示这个元素的 id 值是 kw。
driver.find_element(By.XPATH, "//input[@id='kw']").send_keys('python3')
# 如果一个元素本身没有可以唯一标识这个元素的属性值,我们可以查找其上一级元素。
# form[@class='fm has-soutu']通过 class 定位到父元素,后面的/span/input 表示父元素下面的子元素。
driver.find_element(By.XPATH, "//form[@class='fm has-soutu']/span/input").send_keys('python3')
# 如果一个属性不能唯一区分一个元素,那么我们可以使用逻辑运算符连接多个属性来查找元素
driver.find_element(By.XPATH, "//input[@id='kw' and @class='s_ipt']").send_keys('python3')
# 点击搜索
driver.find_element(By.ID, 'su').click()
# 关闭浏览器
driver.close()This chapter mainly introduces the eight positioning of Selenium elements. Each positioning method has its own special usage. Readers only need to master its particularity. You need to use more, think more, and summarize experience in the project. Over time, you will have a deeper understanding of these positioning methods.