Communication Group | To enter the "Sensor Group/Skateboard Chassis Group/Car Basic Software Group/Domain Controller Group" please scan the QR code at the end of the article to add Jiuzhang Assistant . Be sure to note the name of the communication group + real name + company + position (no remarks Unable to pass friend verification)

Author | Zhang Mengyu
The first half of the autonomous driving war is about hardware and algorithms, while the second half is about data and the ability to turn data into gold, that is, data closed-loop capabilities.
However, the author learned from communications with industry insiders that at present, the idea of supporting iterative upgrades of autonomous driving systems through large-scale data collection from mass-produced vehicles has not yet been realized. Some companies have not yet set up such a data closed-loop process; although some companies have set up the process and have collected some data, they have not yet made good use of the data because the data closed-loop system is not advanced enough.
There are a lot of inefficient parts in the traditional closed loop of autonomous driving data. For example, almost every company needs to rely on the "human sea tactic" in the data annotation process, and relies on manual scene classification of the collected data one by one.
Fortunately, we are in an era of rapid technology updates. With the development of deep learning technology, especially, as the potential of large models is gradually released, people are delighted to find that many links in the data closed loop can be realized. With automation or semi-automation, efficiency will also be significantly improved.
Due to the capacity advantage brought by the large number of parameters, the performance and generalization ability of large models are significantly improved compared to small models. In traditional data closed-loop processes such as data preprocessing and data annotation, which require a lot of manpower and are inefficient, the performance of large models is remarkable. Many companies are actively exploring, hoping to apply large models to data closed loops to accelerate algorithm iteration.
Large models may help data closed loop enter the 2.0 era (the era with low automation can be called the data closed loop "1.0" era), thus affecting the competitive situation of autonomous driving in the second half.
However, training large models requires a large amount of data and extremely high computing power, which places high demands on the underlying hardware facilities and AI R&D platforms.
In order to create a highly efficient data closed-loop system, Tesla also developed its own DOJO supercomputing center. Currently, Tesla's Autopilot system has collected more than 2.09 billion kilometers of road mining data. To a certain extent, investment in data closed-loop systems is one of the reasons why Tesla has taken a significant lead in autonomous driving research and development.
However, Tesla’s investment in this approach is also huge. It is reported that Tesla’s investment in DOJO supercomputing will exceed US$1 billion in 2024. In China, there are only a handful of companies with such financial resources.
Then, a more feasible option for domestic OEMs and autonomous driving companies is to go to the cloud and quickly enter the cloud market with the help of large model capabilities, computing power, tool chains and other infrastructure and development platforms opened by cloud vendors. Data closed loop 2.0 era.
In particular, if cloud vendors have full-stack self-research capabilities and can provide a complete set of infrastructure, then OEMs and autonomous driving companies will not need to consider issues such as inconsistent tool interfaces provided by different companies when using them, which can reduce a lot of adaptation efforts. work to further improve development efficiency.
1. How large models accelerate data closed loop 2.0
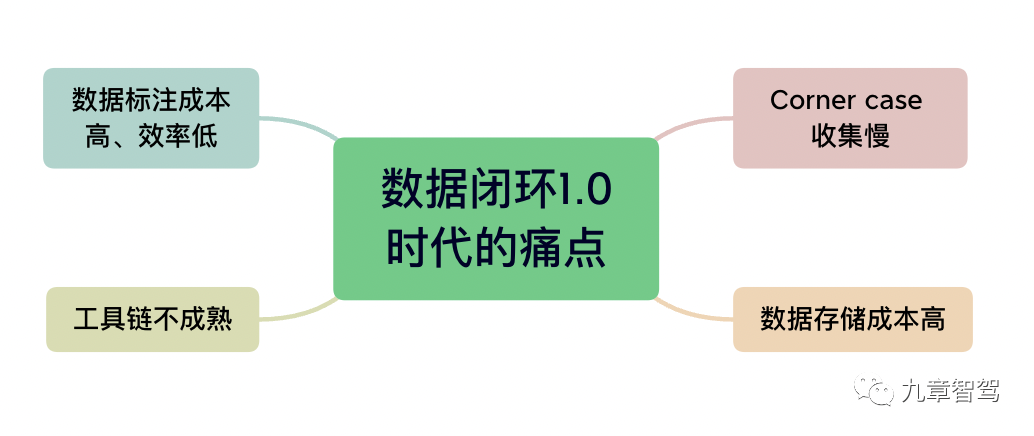
In the data closed-loop 1.0 era, people are not yet ready to deal with the demand for large amounts of data in the development of autonomous driving systems. The degree of automation and efficiency of each module is not high enough.
The Data Closed Loop 2.0 era requires a system that can quickly process large amounts of data, allowing data to flow faster within the system, improving the efficiency of algorithm iterations, and making cars smarter as they drive.
At the 7.21 Huawei Cloud Intelligent Driving Innovation Summit, Huawei Cloud Autonomous Driving Development Platform was launched. With the blessing of the Pangu large model, the platform has excellent corner case solving capabilities, data preprocessing capabilities, data mining capabilities, and data annotation capabilities. , compared with the traditional data closed-loop system, they have shown significant improvement.
1.1 Pangu large model helps solve corner cases
The traditional way to solve corner cases is to collect as much relevant data as possible through actual vehicle road collection, and then train the model so that the model has the ability to respond. This method is more expensive and less efficient. What's more, many special scenes occur very rarely and are difficult to collect in real vehicles.
In recent years, people have discovered that NeRF technology can be used for scene reconstruction, and then by adjusting parameters such as changing the viewing angle, changing the lighting, and changing the vehicle driving path to simulate some scenes (synthetic data) that occur less frequently in the real world. As a supplement to actual vehicle road collection data.
As early as early 2022, Waymo began to use synthetic data generated based on NeRF technology for autonomous driving algorithm training.
One of CVPR's highlight papers this year, UniSim: A Neural Closed-Loop Sensor Simulator, also explores the use of NeRF technology for scene reconstruction. In this article, the authors from self-driving truck company Waabi divide the scene into three parts: static background (such as buildings, roads, and traffic signs), dynamic objects (such as pedestrians and cars), and objects outside the area (such as the sky and very far roads), and then use NeRF technology to model static backgrounds and dynamic objects respectively.
The author found that the scene reconstructed using NeRF technology is not only highly realistic, but also easy to expand. R&D personnel only need to collect data once for reconstruction.
In China, the scene reconstruction large model developed by Huawei Cloud based on the Pangu large model also incorporates NeRF technology. The model can be used for scene reconstruction (synthetic data) based on collected road sampling video data. It is difficult for ordinary users to distinguish the difference between these reconstructed scenes and real scenes with the naked eye. These reconstructed scene data supplement the real road acquisition data and can be used to improve the accuracy of the perception model.
Specifically, the input of the scene reconstruction large model is a segment of road sampling video. After the model reconstructs the scene of these videos, the user can edit the weather, road conditions, and the attitude, position, and driving trajectory of the main vehicle, etc., and then generate a new one. video data.
For example, users can change the weather in the original video from sunny to rainy, change day to night (as shown below), and turn a wide, flat road into a muddy trail.
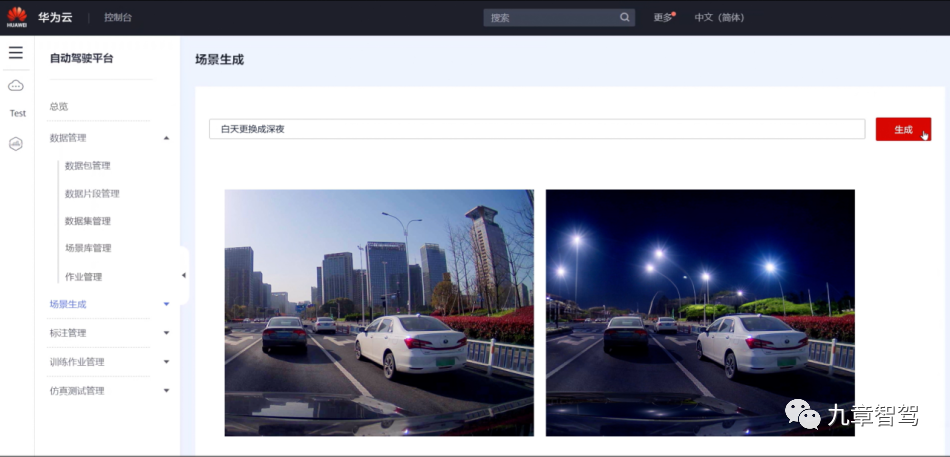
In other words, users can generate more data by editing scene elements without relying entirely on road mining. In particular, for some data that is not convenient to collect, such as scene data under extreme weather, users can use scene reconstruction to generate it.
An engineer from Huawei Cloud told Jiuzhang Zhijia:
When we used scene reconstruction data to train the perception algorithm, we found that the data was indeed helpful for algorithm training. At the same time, our large model is continuously improving the coverage of these virtual scenes, striving to make these data more widely used, so that the automatic driving algorithm can cope with more corner cases.
The improved ability to solve corner cases means that the autonomous driving system will be more involved in vehicle driving and the user experience will be better, which will ultimately lead to an increase in the penetration rate of autonomous driving.
1.2 Pangu large model assists data preprocessing
The data collected by the vehicle terminal generally needs to be pre-processed before entering the mining and annotation process. The main function of preprocessing is to classify data, remove unnecessary data, and retain data of important scenarios.
The traditional method of classifying data using manual playback is very time-consuming. If a large model is used to understand the content of the video and automatically classify the video data, work efficiency can be greatly improved.
The difficulty in using a model to classify videos lies in how to unlock the scene of the video through semantics. The large scene understanding model developed by Huawei Cloud based on the Pangu large model can semantically understand and then classify video data. After the user uploads the video data, the model can identify the key information and mark it according to the video category and the time of occurrence, as shown in the figure below. It also supports combined retrieval.

After testing, the scene understanding large model can recognize weather, time, objects, etc. with an accuracy of more than 90%.
It is reported that this kind of solution has been implemented in a certain main engine factory project. Engineers only need to call the API provided by Huawei Cloud to use the large scene understanding model to complete the work of classifying video data.
1.3 Pangu large model assists data mining
After the vehicle transmits road mining data back to the cloud, engineers usually need to mine higher-value data. Traditional methods of mining long-tail scenes based on tags generally can only distinguish known image categories.
Large models have strong generalization and are suitable for mining long-tail data.
In 2021, OpenAI released the CLIP model (a text-image multi-modal model), which can get rid of dependence on image tags, correspond text and images after unsupervised pre-training, and classify images based on text. .
This means that engineers can use such a text-image multi-modal model to retrieve image data in the drive log using text descriptions, for example, 'an engineering vehicle dragging cargo', 'a traffic light with two light bulbs on at the same time' Wait for long-tail scenarios.
According to the information the author has communicated with industry insiders, some autonomous driving technology companies have begun to implement text-based image searches based on CLIP, thereby improving the efficiency of mining long-tail data.
Huawei Cloud has developed a large multi-modal retrieval model based on the Pangu large model. The multi-modal retrieval large model can not only search for pictures by pictures and search for pictures by text, but also search for videos by text. For example, if an engineer wants to find video clips of the vehicle in front stopping abnormally, he can directly use "vehicle in front stopped abnormally" to search for relevant video clips.
1.4 Pangu large model helps data annotation
According to estimates, leading autonomous driving companies may need to label hundreds of terabytes or even petabytes of data every year, with labeling costs reaching tens of millions or even hundreds of millions.
In order to reduce labeling costs and improve labeling efficiency, many companies are developing automatic labeling models.
But at present, most companies' automatic labeling models (small models) have problems that are not versatile enough.
In practice, engineers usually need to train different labeling models for different scenarios (for example, the model for labeling traffic lights cannot be used to label lane lines). The retraining process may consume a lot of data and computing power, and the cost is high.
Based on the Pangu large model, Huawei Cloud developed a pre-annotated large model. With the help of pre-labeled large models, when facing new scenarios, engineers do not need to train from scratch, but only need to "fine-tune" the basic model to obtain pre-labeled large models for new scenarios.
According to the introduction of Huawei Cloud engineers, for different types of autonomous driving scenarios, the pre-labeled large model only needs to use a small amount of data (hundreds to thousands of pictures) for 1-2 weeks of training to achieve a more ideal pre-labeling effect .
Moreover, for 2D and 3D annotation tasks, pre-annotated large models can achieve high-precision annotation. After using pre-labeled large models for pre-labeling, the labeling company basically only needs to do some quality inspections, which can significantly reduce labeling costs.
2. How can users easily call large models?
To put it bluntly, large models must ultimately be tested by users. So, how do users call large models?
In fact, no matter how versatile a large model is, it will not be omnipotent. The "big" of the large model mainly emphasizes its versatility in terms of underlying capabilities, rather than saying that it has the ability to solve "every detail in every subdivided scene". In the process of concrete landing, large models are often divided into multiple levels. At the final execution end, the real "work" may be the "medium model" or even the "small model".
Here, we take Pangu Model 3.0 released by Huawei Cloud as an example to make a simple explanation.
Pangu Large Model 3.0 is a layered, decoupled open architecture, divided into 3 layers in total, as shown in the figure below:
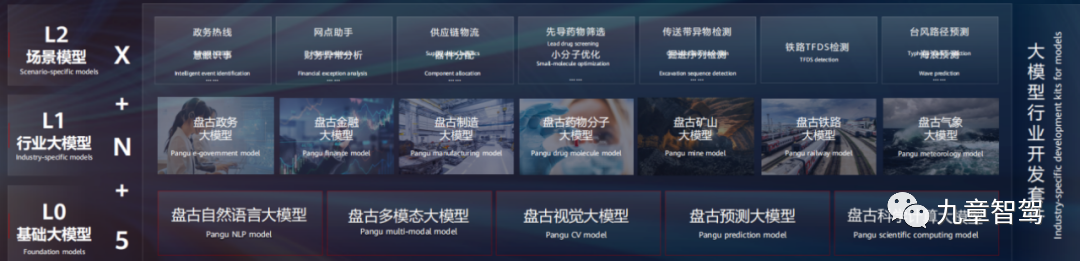
The bottom layer is the L0-level basic large model, which includes five large models, including language large model, visual large model, multimodal large model, prediction large model, and scientific computing large model. The abilities corresponding to the L0-level basic large-scale model are similar to the basic abilities of human beings such as seeing, listening, speaking, reading, writing, calculating, and thinking. They are needed no matter what industry or job they are in.
Based on the L0-level model, HUAWEI CLOUD has developed L1-level industry models for different industries, including government affairs models, financial models, manufacturing models, and mine models. Each large L1 industry model is strongly coupled with a specific industry.
On the basis of the L0-level basic model and the L1-level industry large model, Huawei Cloud has also generated some task models for solving specific problems for users in subdivided scenarios, namely the L2-level scenario model in the figure above. The pre-annotated large models and scene reconstruction large models mentioned in the first chapter of this article all belong to L2 level scene models.
In addition, based on the L0-level and L1-level large models, Huawei Cloud provides users with a model development kit. Users can use their own collected data to fine-tune the L2-level scene understanding model and obtain their own scene model.
Taking the large scene understanding model as an example, users can directly call Huawei Cloud's API to use the large scene understanding model, or they can add their own data to train their own large scene understanding model.
From this point of view, the evolution of Huawei's Pangu Large Model 3.0 is a "two-wheel drive": on the one hand, Huawei Cloud continuously collects public data to allow basic large models to learn general knowledge, and allows industry large models to learn industry knowledge (it is reported that Huawei The training data of each industry large model in the cloud exceeds 50 billion tokens); on the other hand, users can also continuously collect data suitable for the scenarios they face to improve the ability of fine-tuned scenario large models to solve specific problems. .
Under this mechanism, a large trained model can be quickly migrated to new scenarios with only a small amount of supplementary training samples, greatly reducing the cost and threshold of application promotion and improving usage efficiency.
3. In order to pursue the "ease of use" of large models, what has Huawei Cloud done?
In practice, if users want to truly make good use of the capabilities of large models to empower data in a closed loop, they also need a series of infrastructure.
At present, the autonomous driving industry is seriously fragmented. Even if we narrow the scope to a data closed-loop system, we will see that different suppliers occupy a small part of the entire ecosystem. Reflected in R&D, there are various data formats and different tool chain interfaces. OEMs and autonomous driving companies have to do a lot of adaptation work, and the synergy effect of R&D is poor.
If there is a supplier that can provide a full-stack solution for the data closed-loop tool chain, it will be much easier for downstream customers to use large models to do data closed-loop.
In China, Huawei Cloud is one of the very few cloud vendors that has the capability to develop full-stack autonomous driving data closed-loop tool chains. In addition to providing users with large model capabilities, Huawei Cloud can also provide a series of supporting facilities such as digital intelligence fusion architecture, ModelArtsAI development production line, and Shengteng AI cloud services. Users can simultaneously achieve data acceleration, Algorithm acceleration and computing power acceleration.
3.1 Digital intelligence fusion architecture achieves data acceleration
In actual use, "data islands" are a major problem that troubles R&D engineers. Data island problems include but are not limited to inconsistent data formats, inconsistent tool chain interfaces, and tools scattered on different platforms, resulting in difficulty in collaboration.
In response to these problems, Huawei Cloud has tried its best to find the "common denominator" of the needs of various OEMs and autonomous driving companies, making the tool chain more versatile and eliminating a lot of adaptation work; on the other hand, it has integrated the data production line and the AI production line Together, the seamless flow of data is achieved through a unified original data management platform. On this platform, engineers can easily use preset AI algorithms in global data to integrate the Pangu large model through APIs and workflows. into the overall digital intelligence fusion architecture, so that the capabilities of the Pangu large model can be easily invoked.
3.2 ModelArts AI development production line realizes algorithm acceleration
The ModelArts AI development production line consists of three parts: DataTurbo, TrainTurbo, and InferTurbo, which provide acceleration tools for data loading, model training, and model reasoning respectively, doubling the efficiency of model training.
3.2.1 DataTurbo realizes data loading acceleration
When the model becomes larger, the data used to train the model will also increase accordingly. Correspondingly, data reading and writing efficiency becomes a factor that greatly affects the model training speed.
DataTurbo combines the local high-speed SSD disks of the computing cluster into a unified distributed cache system. When the algorithm first reads the training data from the back-end OBS, the system will automatically cache the data. Subsequent training data will be obtained directly from the near-computing cache, greatly improving data loading. performance. DataTurbo's distributed cache data reading bandwidth can expand linearly with the expansion of computing cluster nodes, up to a maximum of 1TB/s.
3.2.2 TrainTurbo realizes model training acceleration
Neural networks are composed of many basic operators. Therefore, optimizing operators is an important way to improve model training efficiency.
Mainstream AI training frameworks (such as PyTorch, TensorFlow, etc.) need to ensure versatility as much as possible, and the operators provided are generally very basic.
In practice, enterprises can make some targeted optimization of operators according to their own needs. Companies such as Huawei, SenseTime, ByteDance, and Baidu have developed their own AI training frameworks and made targeted optimization of operators to improve model training efficiency.
Among them, because Huawei has achieved full-stack autonomy from the underlying hardware to the tool chain to the training framework of the AI model, it is easier for engineers to perform joint software and hardware tuning of operators. Therefore, in TrainTurbo, users can enjoy to achieve more extreme training performance.
3.2.3 InferTurbo realizes model inference acceleration
In the model inference process, InferTurbo uses operator parallelism, multi-stream parallelism, memory reuse, low-bit quantization and other methods to optimize for different frameworks and operating systems.
Taking multi-stream parallelism as an example, inference tasks usually require several operations such as function calculation and data copying or transferring between multiple GPU devices. InferTurbo splits the above parts of a large task into multiple streams. It only copies, calculates and writes back a part of the data at a time. It synchronizes the data copy and function calculation to form a pipeline, which can achieve very good results. Big performance improvements.
After optimization in various ways, InfeTurbo can improve inference performance by 2-5 times while ensuring model accuracy.
3.3 Shengteng AI cloud service achieves computing power acceleration
In order to cope with the computing power demand for model training, various technology companies, OEMs, etc. have begun to build their own or jointly build computing power centers to create computing power clusters. Huawei Cloud has simultaneously launched Ascend AI cloud services in Ulanqab and Gui'an data centers, providing huge computing power for model training. The performance of a single cluster can reach 2000P Flops, providing the industry with a better choice.
Large-scale computing clusters usually face business continuity problems, because a single point of failure may cause the entire large-scale distributed task to fail.
Of course, this problem is not unsolvable. At least, Huawei Cloud will not be troubled by this problem.
To ensure that training tasks are not interrupted, Huawei Cloud has developed a method to resume training at breakpoints. If a single point of failure occurs during the training process, the system will eliminate this point, replace the failed node with a new node, and restart in place. It is reported that Shengteng AI cloud service can achieve uninterrupted kilocalorie training for more than a month, and the recovery time from breakpoints does not exceed 10 minutes.
Conclusion:
Since this year, major car companies have been actively entering urban NOA. Autonomous driving technology is expected to "cross the chasm" and break through from the circle of technology early adopters to the circle of the masses.
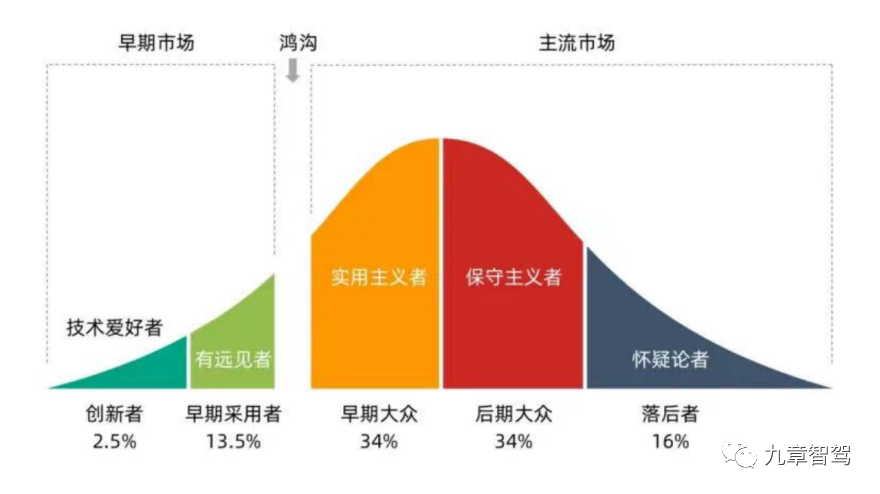
Of course, not all companies are equipped to seize this opportunity.
If nothing unexpected, we will see that after autonomous driving enters the second half, those companies that cannot make breakthroughs in data closed-loop capabilities will be dragged down by "high costs" and "low efficiency" on the one hand. Because it is unable to achieve breakthroughs in solving corner cases, it is difficult to satisfy end consumers.
In fact, only those companies that have truly mastered the data closed-loop capabilities, or more closely, those companies that can make good use of large model and other technologies to create an efficient data closed-loop system, can be considered to have won the second half of autonomous driving. "Ticket".
Of course, mastering data closed-loop capabilities does not necessarily require everything to be achieved through self-research. Because, when ordinary companies do not have particularly abundant resources, putting too much emphasis on self-research may lead to a weakening of competitiveness. In this case, it is a more feasible choice to only develop the application layer of the data closed-loop system by ourselves, and to cooperate with powerful suppliers for the underlying infrastructure.
At such an industry turning point, Huawei Cloud has opened up the Pangu large model, computing power, tool chain and other data closed-loop infrastructure and development platforms, which will help OEMs and autonomous driving technology companies accelerate the algorithm iteration of autonomous driving.
We hope that with the efforts of all parties in the industry, autonomous driving technology will achieve an early breakthrough, allowing everyone to feel the convenience brought by technology.
END

Communication Group | To enter "Sensor Group/Skateboard Chassis Group/Car Basic Software Group/Domain Controller Group" please scan the QR code above and add Jiuzhang Assistant . Be sure to note the name of the communication group + real name + company + position (no remarks) Unable to pass friend verification)
write at the end
Communicate with the author
If you want to communicate directly with the author of the article, you can directly scan the QR code on the right and add the author's WeChat account.

Note: When adding WeChat, be sure to note your real name, company, and current position. Thank you!
About submission
If you are interested in contributing to "Nine Chapters of Intelligent Driving" ("knowledge accumulation and compilation" type articles), please scan the QR code on the right and add the staff WeChat.

Note: When adding WeChat, be sure to note your real name, company, and current position. Thank you!
Quality requirements for "knowledge accumulation" manuscripts:
A: The information density is higher than most reports of most brokerage firms, and not lower than the average level of "Nine Chapters Smart Driving";
B: Information must be highly scarce, and more than 80% of the information must not be seen in other media. If it is based on public information, it must have a particularly powerful and exclusive perspective. Thank you for your understanding and support.
Recommended reading:
◆ One of the self-driving data closed-loop series: full of ideals and skinny reality
◆ A 10,000-word long article explaining the application of large models in the field of autonomous driving