Source | Xinzhiyuan
Author | Taozi
Overnight, the world’s most powerful open source large model Falcon 180B set off the entire Internet!
With 180 billion parameters, Falcon completed training on 3.5 trillion tokens and directly topped the Hugging Face rankings.
In the benchmark test, Falcon 180B defeated Llama 2 in various tasks including reasoning, coding, proficiency and knowledge testing.
In fact, Falcon 180B is on par with Google PaLM 2, and its performance is close to GPT-4.
Large model research test portal
GPT-4 portal (no wall, can be tested directly, if you encounter the browser warning point, just advance/continue accessing):
https://gpt4test.com
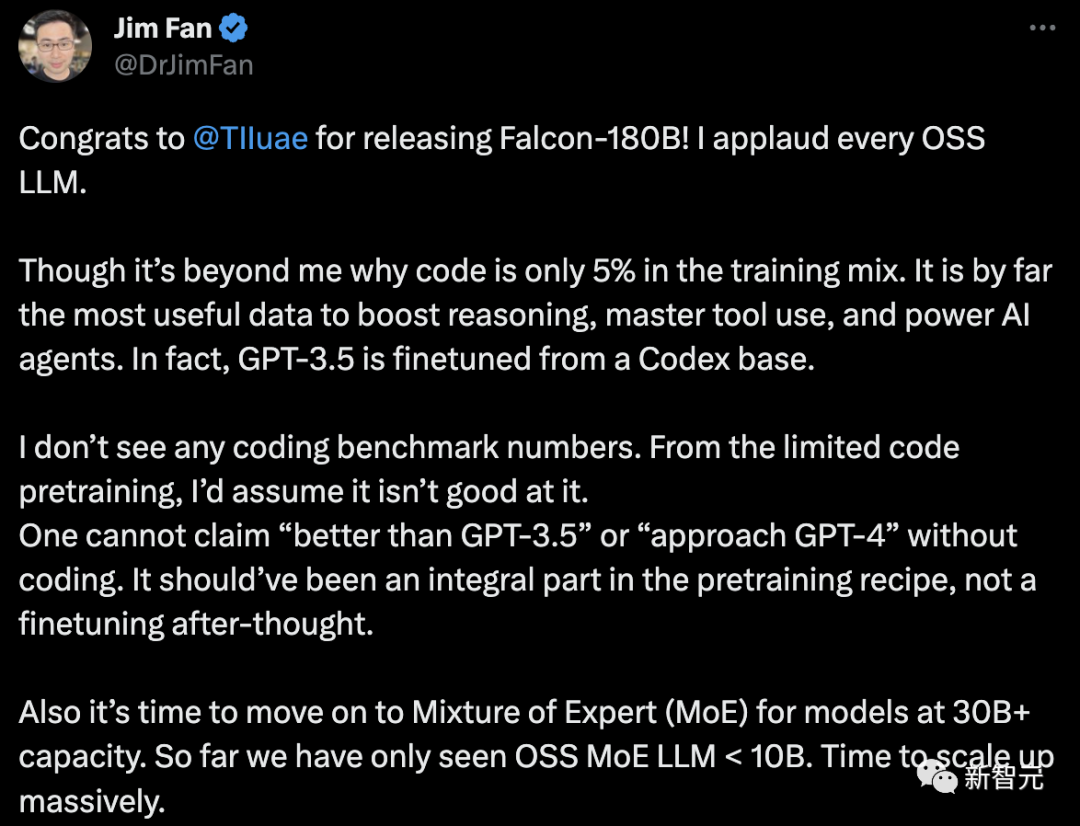
However, Jim Fan, a senior scientist at Nvidia, expressed doubts about this.
- Code accounts for only 5% of the Falcon-180B training data.
And code is by far the most useful data for improving reasoning, mastering tool use, and enhancing AI agents. In fact, GPT-3.5 is fine-tuned based on Codex.
- No encoding reference data.
Without coding capabilities, you cannot claim to be "better than GPT-3.5" or "close to GPT-4". It should be an integral part of the pre-training recipe, not a tweak afterward.
- For language models with parameters larger than 30B, it is time to adopt a hybrid expert system (MoE). So far we have only seen OSS MoE LLM < 10B.
Let's take a look, what is the origin of Falcon 180B?

The world’s most powerful open source model
Previously, Falcon has launched three model sizes, namely 1.3B, 7.5B, and 40B.
According to the official introduction, Falcon 180B is an upgraded version of 40B. It was launched by TII, the world's leading technology research center in Abu Dhabi, and is available for free commercial use.

This time, the researchers made technological innovations on the base model, such as using Multi-Query Attention to improve the scalability of the model.
For the training process, Falcon 180B is based on Amazon SageMaker, the Amazon cloud machine learning platform, and has completed training on 3.5 trillion tokens on up to 4096 GPUs.
Total GPU computation time, approximately 7,000,000.
The parameter size of Falcon 180B is 2.5 times that of Llama 2 (70B), and the amount of calculation required for training is 4 times that of Llama 2.
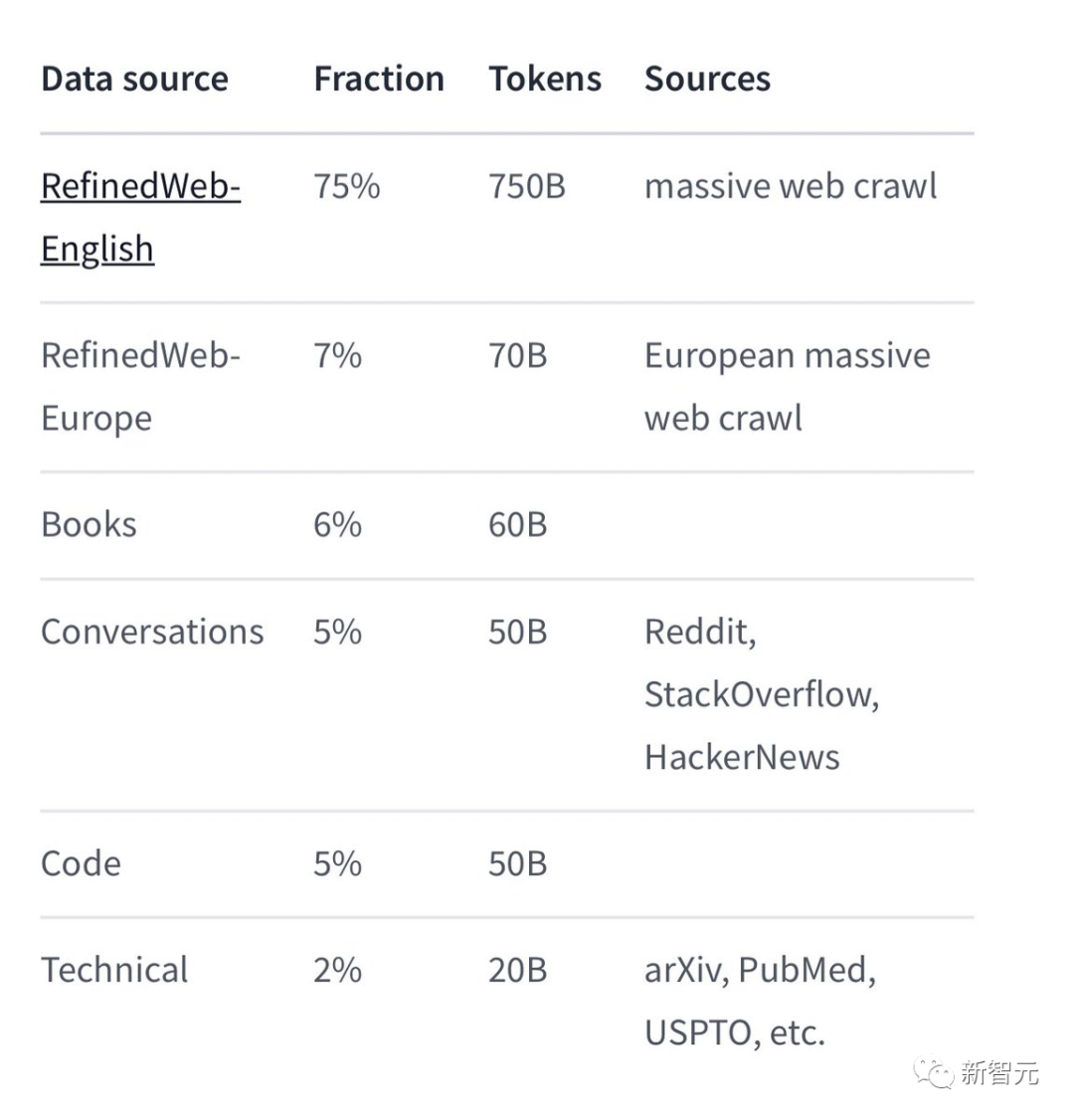
Among the specific training data, Falcon 180B is mainly the RefinedWe data set (accounting for about 85%).
Additionally, it was trained on a curated mix of conversations, technical papers, and a small collection of code.
This pre-training data set is large enough that even 3.5 trillion tokens only occupy less than one epoch.
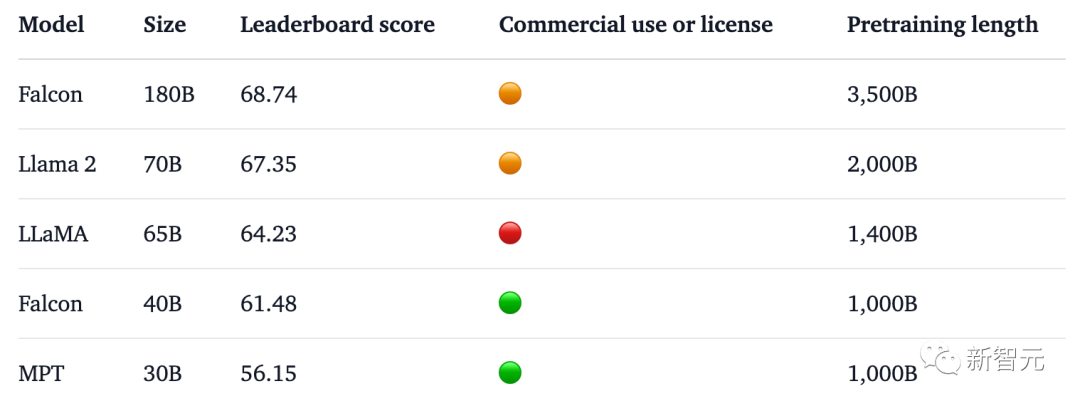
The official claims that Falcon 180B is currently the "best" open source large model. The specific performance is as follows:
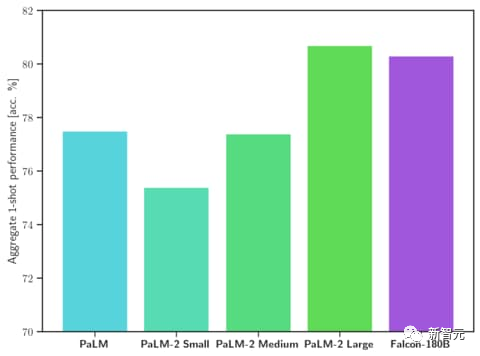
On the MMLU benchmark, Falcon 180B outperforms Llama 2 70B and GPT-3.5.
On HellaSwag, LAMBADA, WebQuestions, Winogrande, PIQA, ARC, BoolQ, CB, COPA, RTE, WiC, WSC and ReCoRD, it is comparable to Google's PaLM 2-Large.
In addition, it is currently the open large model with the highest score (68.74 points) on the Hugging Face open source large model list, surpassing LlaMA 2 (67.35).

Falcon 180B is available for use
At the same time, the researchers also released the chat conversation model Falcon-180B-Chat. The model is fine-tuned on conversation and instruction datasets covering Open-Platypus, UltraChat and Airoboros.

Now, everyone can have a demo experience.
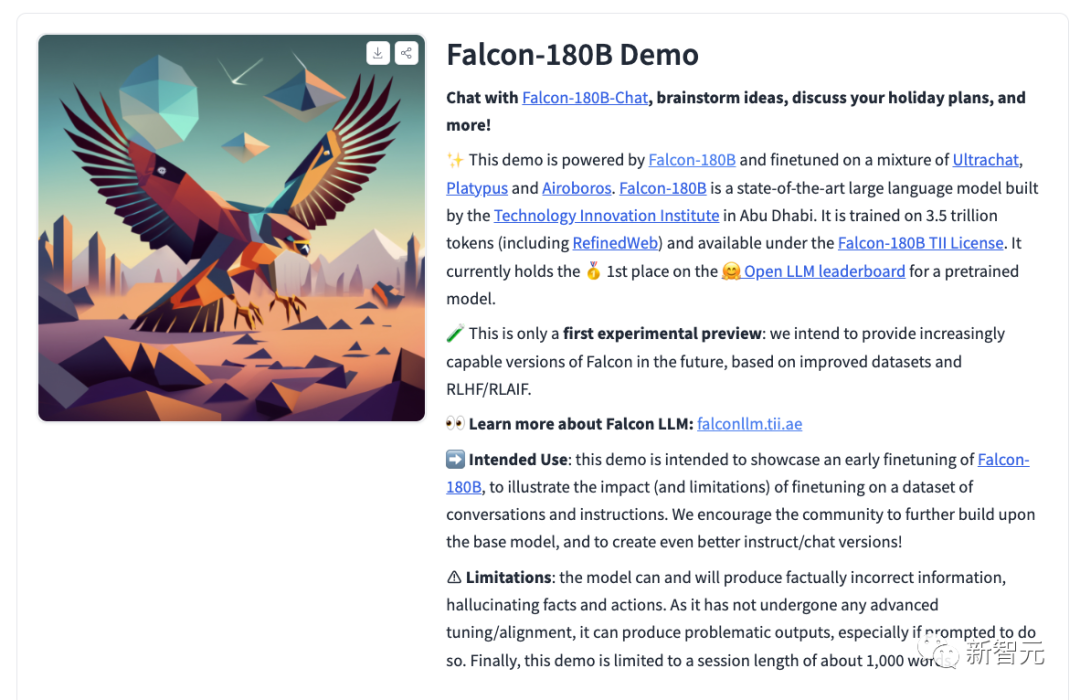
Address:
https://huggingface.co/tiiuae/falcon-180B-chat
Prompt format
The basic model does not have a prompt format because it is not a large conversational model, nor is it trained through instructions, so it does not respond in a conversational manner.
Pretrained models are a great platform for fine-tuning, but you probably shouldn't use them directly. Its dialogue model has a simple dialogue mode.
System: Add an optional system prompt here
User: This is the user input
Falcon: This is what the model generates
User: This might be a second turn input
Falcon: and so on
Transformers
Starting from Transfomers 4.33, Falcon 180B can be used and downloaded in the Hugging Face ecosystem.
Make sure you are logged in to your Hugging Face account and have the latest version of transformers installed:
pip install --upgrade transformers
huggingface-cli login
bfloat16
Here's how to use the base model with bfloat16. The Falcon 180B is a large model, so please be aware of its hardware requirements.
For this, the hardware requirements are as follows:
It can be seen that if you want to fully fine-tune Falcon 180B, you need at least 8X8X A100 80G. If it is just for inference, you also need 8XA100 80G GPU.

from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "tiiuae/falcon-180B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
prompt = "My name is Pedro, I live in"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
do_sample=True,
temperature=0.6,
top_p=0.9,
max_new_tokens=50,
)
output = output[0].to("cpu")
print(tokenizer.decode(output)
The following output may be produced:
My name is Pedro, I live in Portugal and I am 25 years old. I am a graphic designer, but I am also passionate about photography and video.
I love to travel and I am always looking for new adventures. I love to meet new people and explore new places.
Using 8-bit and 4-bit bitsandbytes
Furthermore, the 8-bit and 4-bit quantized versions of Falcon 180B are virtually indistinguishable from bfloat16 in terms of evaluation!
This is good news for inference, as users can safely use quantized versions to reduce hardware requirements.
Note that inference is much faster on the 8-bit version than on the 4-bit version. To use quantization, you need to install the "bitsandbytes" library and enable the corresponding flags when loading the model:
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
**load_in_8bit=True,**
device_map="auto",
)
dialogue model
As mentioned above, the version of the model fine-tuned for tracking conversations uses a very straightforward training template. We have to follow the same pattern to run chatty inference.
For reference, you can take a look at the [format_prompt] function in the chat demo:
def format_prompt(message, history, system_prompt):
prompt = ""
if system_prompt:
prompt += f"System: {system_prompt}\n"
for user_prompt, bot_response in history:
prompt += f"User: {user_prompt}\n"
prompt += f"Falcon: {bot_response}\n"
prompt += f"User: {message}\nFalcon:"
return prompt
As you can see above, user interactions and model responses are preceded by User: and Falcon: separators. We concatenate them together to form a cue that contains the entire conversation history. This way, a system hint can be provided to adjust the generation style.
Hot comments from netizens
Many netizens have heated discussions about the true strength of Falcon 180B.
Absolutely unbelievable. It beats GPT-3.5 and is on par with Google's PaLM-2 Large. This is a game changer!

The CEO of a start-up company said, I tested the Falcon-180B chat robot, it is not better than the Llama2-70B chat system. The HF OpenLLM leaderboard also showed mixed results. This is surprising given its larger size and larger training set.
Take a chestnut:
Give some items and let Falcon-180B and Llama2-70B answer them respectively and see what the effect is?
Falcon-180B mistakenly counted a saddle as an animal. Llama2-70B answered concisely and gave the correct answer.


References
[1]https://twitter.com/TIIuae/status/1699380904404103245
[2]https://twitter.com/DrJimFan/status/1699459647592403236
[3]https://huggingface.co/blog/zh/falcon-180b
[4]https://huggingface.co/tiiuae/falcon-180B