1 Introduction
In the previous article, we introduced Arm’s Cortex-X1 to Cortex-X3 series processors. At the end of May 2023, Arm released the new year’s processor architecture as scheduled, which are super large core Cortex-X4 and large core A720 and small core A520. In the smartphone industry, Arm has always maintained an iterative processor architecture upgrade rhythm every year, so that users can continue to experience the most advanced product design. This article mainly introduces the changes in the new processor architecture in 2023, focuses on the analysis of the Cortex-X4 core that has changed a lot, and discusses the changes that are worthy of attention in the core processor architecture this year.
2. Overall introduction
From the promotional data of Arm, it can be seen that this year's three processor architectures have different focuses. The Cortex-X4 focuses on performance improvement, which is 15% higher than the previous generation Cortex-X3. The A720 and A520 focus on improving energy efficiency. Compared with the previous generation A715 and A520, the energy efficiency is improved by 20% and 22% respectively. It is worth noting that this year's processor does not have an upgraded process, and these data should be calculated based on the same process (eg TSMC 4nm).

In addition to the new processor architecture, Arm also brought a new Armv9.2 instruction set this year, including the new QARMA3 PAC algorithm, increased floating-point capabilities, and PMU enhancements. The most critical change is that Arm plans to completely abandon 32bit applications this year. Support, the three new cores are not compatible with 32bit applications.

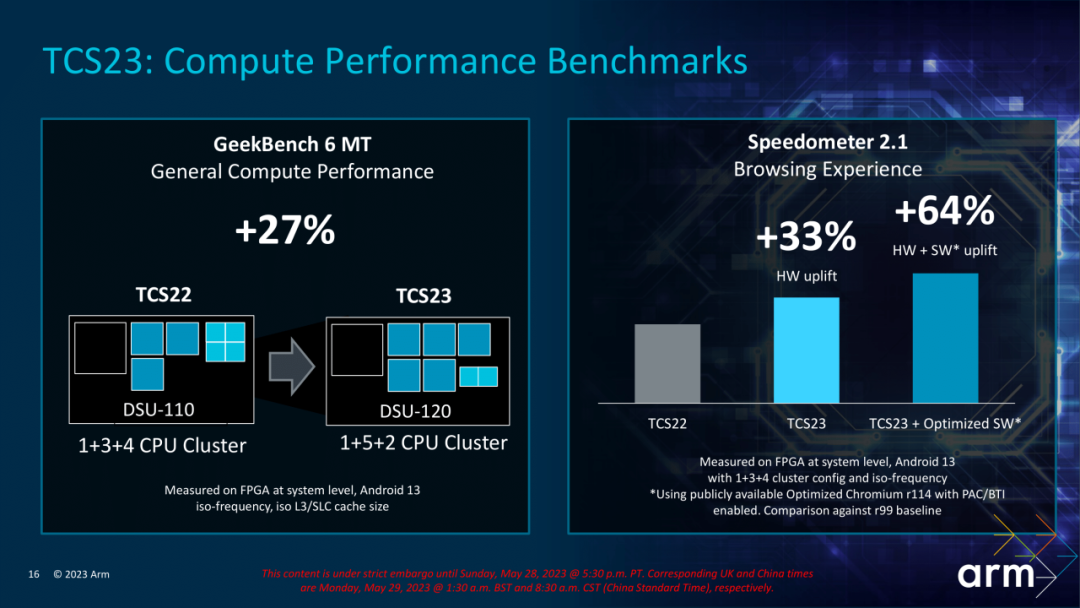
Arm also updated the DSU120 module this year to better manage data between processor cores and support up to 14 cores and up to 32MB of L3 cache design. As can be seen from the picture below, this year’s processor design has also undergone significant changes. Last year, Qualcomm’s 8Gen2 processor adopted a 1+4+3 architecture. This year we will see fewer small-core 1+5+2 architectures (refer to Link 3, Qualcomm 8Gen3 processor), multi-core performance has been greatly improved.
3. Cortex-X4 Microarchitecture Analysis
The code name of Cortex-X4 is Hunter-ELP. The picture below is the microarchitecture diagram of X4. The first feeling is that it has become "bigger". The core of X4 is getting bigger and bigger. If you have read the previous articles, you should be able to I feel that this micro-architecture design is more and more like another industry-leading processor. Different routes lead to the same goal. There is often only one choice for the best design. Below we will analyze the core changes this year in detail.
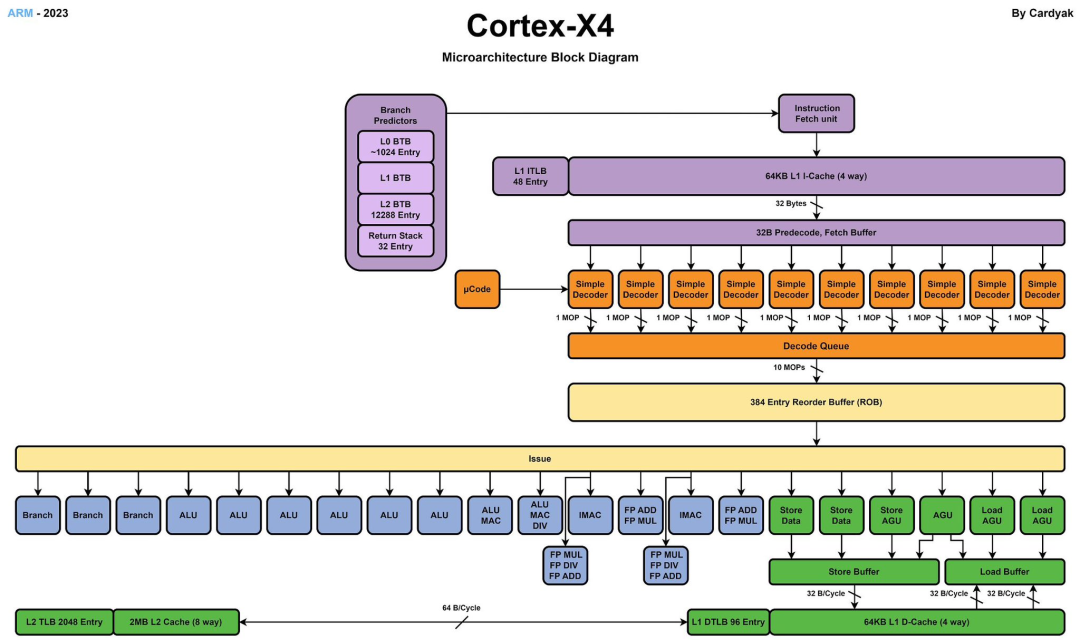
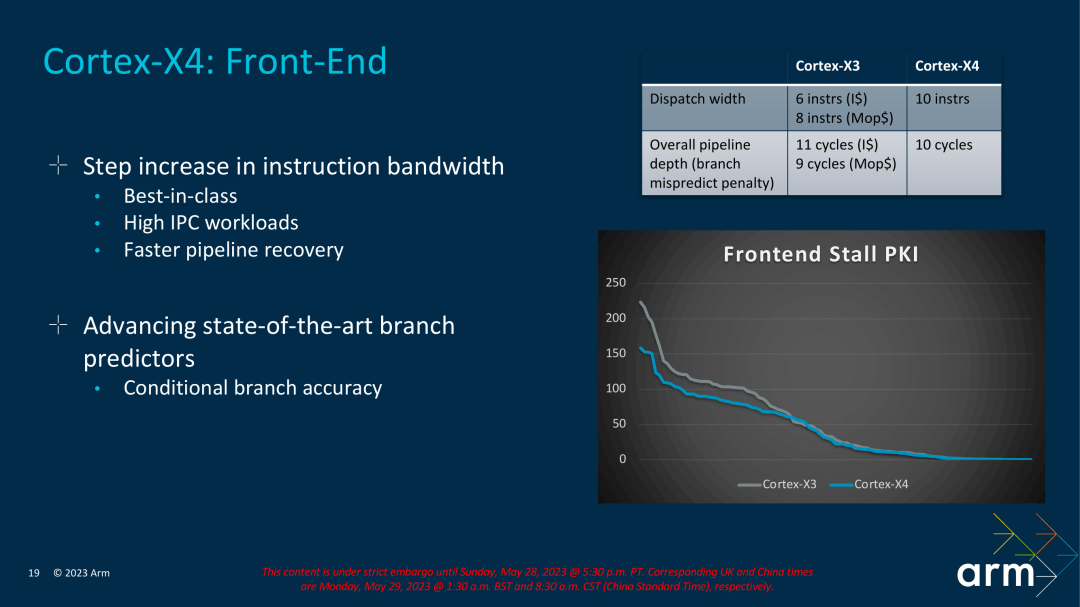
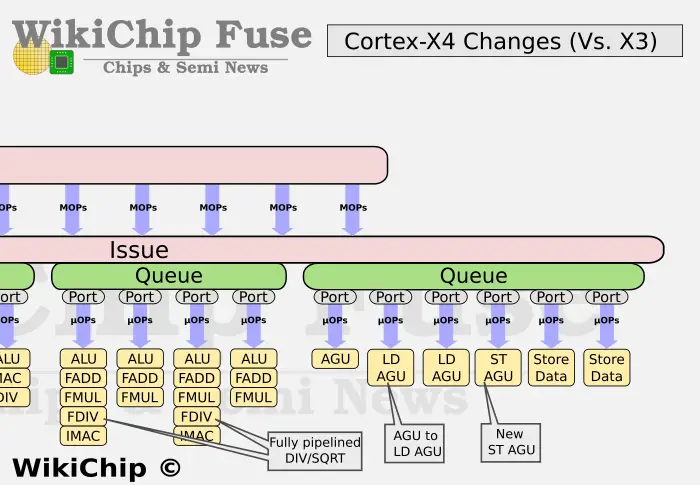
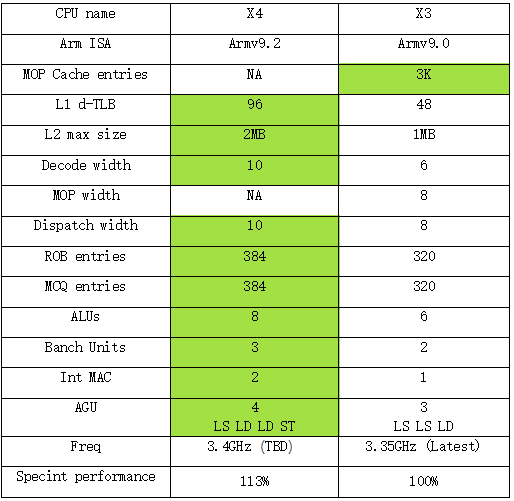
In terms of front-end design, X4 cancels L0-level MOP Cache. Note that this change started from the big core A715. This is a big change. It also shows that the cost of MOP Cache may be really high. economy. In order to compensate for the impact of canceling the MOP Cache, X4 increased the number of Decoders from 6 to 10 this time. In the previous generation of X3, if the data fetched from the MOP Cache was 8-wide, and the data fetched from the L1 was 6-wide, this time the X4 is uniformly 10-wide. In terms of pipeline length, if X3 fetches data from L1, it takes 11 stages, and if it fetches data from MOP, it takes 9 stages. This time, due to the cancellation of MOP, X4 specially optimized the pipeline, and the data fetched from L1 was reduced from 11 stages to 10 stages.
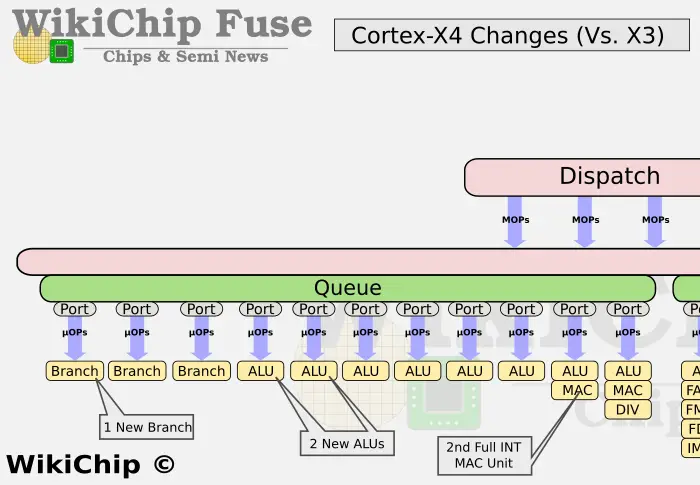
In terms of the back-end design, the X4 has also changed a lot this time, especially the computing unit, adding a new Branch unit, 2 new ALU units, and providing a second complete MAC ALU unit, which is very important for the overall performance. improvement has been significantly helpful.
In order to support the newly added 10 decoders and computing units, the size of the X4's reorder buffer (ROB) has also been increased from 320 to 384, an increase of 20%.

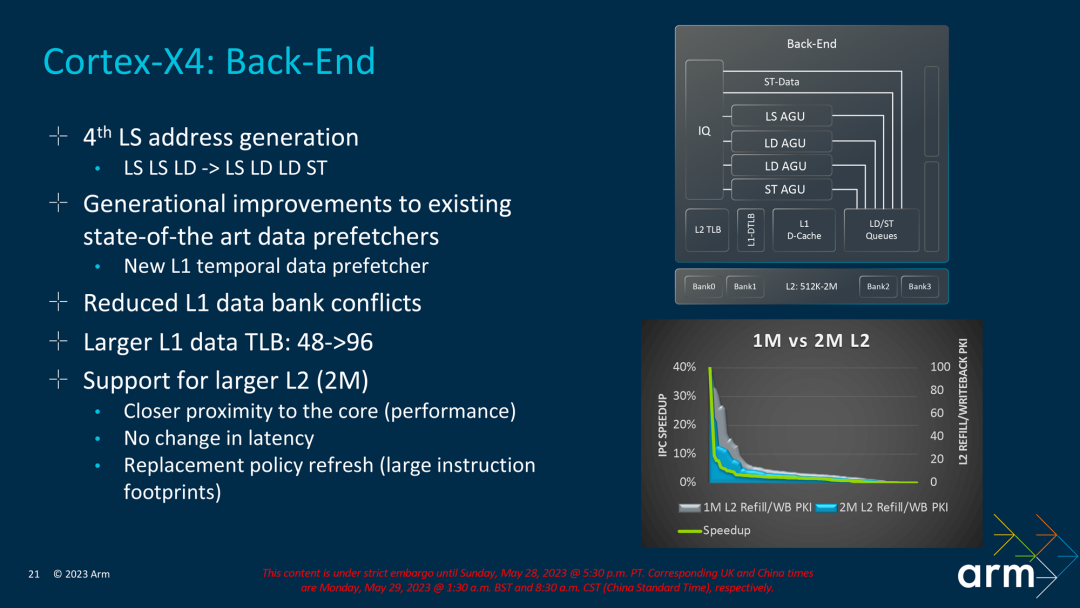
In terms of storage modules, Arm has re-adjusted the number of Load and Store units. The X3 has an LS AGU and one LD AGU, while the X4 is adjusted to one LS AGU, two LD AGUs and one ST AGU. From 3 AGUs to 4 AGUs, but the functions are slightly different. In addition, the d-TLB of L1 has also been increased from 48 to 96, which enhances the data processing capability.
Another feature of the X4 core this time is that it supports a larger L2 cache, which has been upgraded from the maximum support of X3 to 1MB to the maximum support of X4 to 2MB. According to the data given by Arm, the 2MB L2 cache can effectively reduce the weight of every thousand instructions. Filling and write-back rates, but not all vendors are willing to increase to the maximum cache size because increasing the cache will increase the cost.
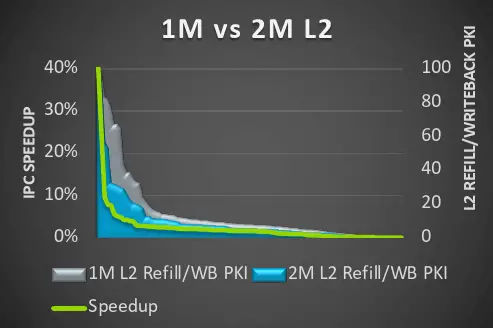
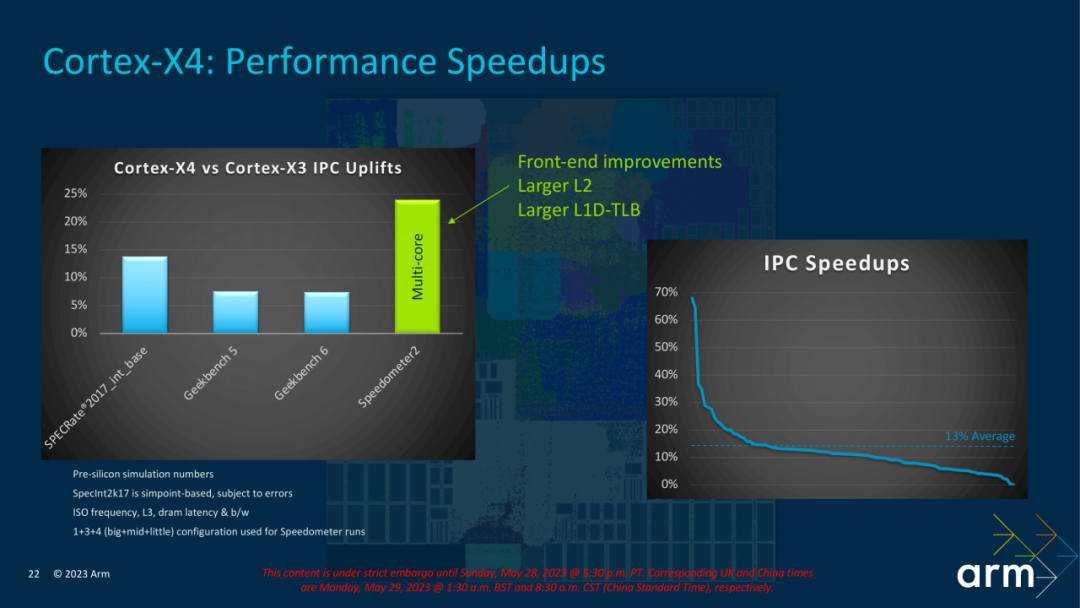
Judging from the overall performance data of X4, Sepcint2K7 has achieved a double-digit improvement, while the Geekbench series has only a single-digit improvement between 6-8%. It is speculated that Geekbench is not very sensitive to L2, but Sppdometer2, which relies on L2 cache The improvement of this benchmark is relatively obvious. Note that the test data here is obtained using the 2MB L2 test.
In addition, Arm data shows that the typical CPU frequency of X4 can run to about 3.4G. Although the actual processor frequency of the manufacturer has not been confirmed, it is speculated from the previous generation Dimensity 9200+ running at 3.35G that 3.4G should be a comparison that can be achieved by 4nm. high frequency levels.
Summarize the key changes of Cortex-X4:
1. Canceled MOP Cache;
2. Increase the number of Decoders from 6 to 10;
3. The assembly line is unified to 10 levels;
4. Branch units increased from 2 to 3;
5. The number of ALU units has been increased from 6 to 8;
6. One AGU unit has been added and its functions have been adjusted;
7. ROB size increased from 320 to 384;
8. The d-TLB of L1 is increased from 48 to 96;
9. The maximum supported L2 cache is increased from 1MB to 2MB;
10. 32bit is not supported.
The overall performance of Sepcint2K7 parameters has been improved by 13%-14%.
4. A720 microarchitecture analysis
In the previous section, we listed 10 microarchitecture changes of the X4 core. Compared with the big moves of the X4, the changes of the A720 and A520 are not so big, but there are some worthy of our research and discussion.
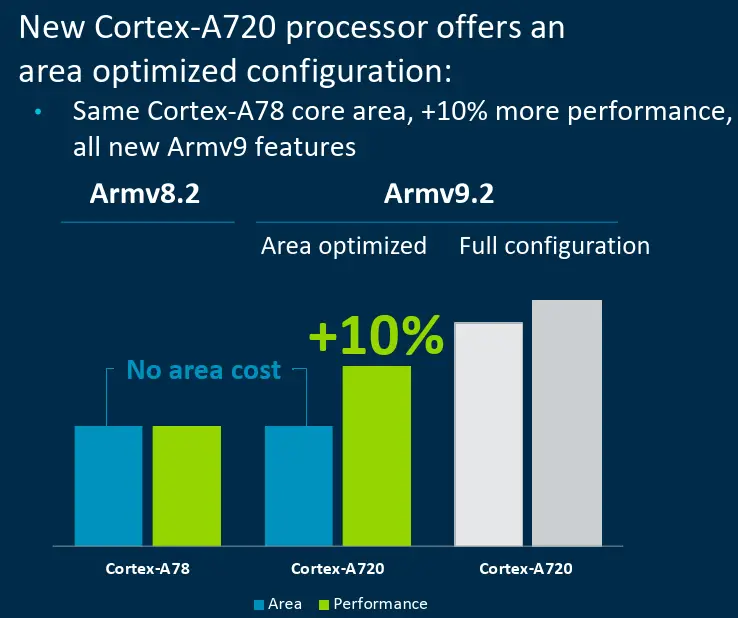
First of all, let's look at the A720. The code name of the A720 is Hunter. The design goal of the A720 is to improve the energy efficiency by 20% compared with the A715. Under the same power consumption, the A720 can provide stronger performance.
The overall microarchitecture of the A720 is not much different from that of the A715. Arm did not increase the fetch-decode width, nor did it increase optimization such as ROB size, but went further into the details of the microarchitecture to optimize energy efficiency.

In terms of front-end design, A720 continues to optimize the branch prediction capability, which in layman's terms is the ability to take one step and see two steps. The recovery cycle of A720's branch misprediction is reduced from 12 to 11 cycles. This optimization is very helpful for cases that cannot be accurately predicted in actual user scenarios. In terms of branch prediction capabilities, the large core of the A710 can predict two unconditional branches per cycle, the A715 additionally supports conditional branches, and the A720 further optimizes power consumption. Arm claims that it can reduce power consumption without affecting performance.

In the back-end design, the A720 improves the energy efficiency of instruction execution through pipelined sorting of FDIV\FSQRT units (division and square root). At the same time, the A720 optimizes the transmission efficiency of data in integer and floating-point units, reducing the delay of data transmission and the delay of storing data. The A720 also improves the launch queue and execution unit, and simplifies the data transmission from the network point to the AGU.

An obvious optimization on the storage module of the A720 is to reduce the delay of L2 access from 10 cycles to 9 cycles, which will be more helpful for scenarios with a lot of memory access. In addition, the maximum amount of L2 cache supported by the A720 is still 512KB.

Finally, I will introduce the biggest change of A720 this year. This year, Arm’s A720 is not a single person, but a pair of twins. Arm provides another A720min (temporarily called this) core. This core is different from the A720, and the area has been reduced to a certain extent. The overall core area is close to that of the A78, and its performance is also weaker than the A720, but it is about 10% stronger than the A78. In summary, the area of A720min is close to that of A78 (power consumption should also be close), and its performance is 10% stronger than that of A78, which belongs to a branch of A720.
Finally, briefly summarize the key changes of the A720:
1. The recovery cycle of branch misprediction is reduced from 12 cycles to 11 cycles;
2. L2 access latency is reduced from 10 cycles to 9 cycles;
3. Provide an option of A720min, the area is close to A78, and the performance is 10% stronger than A78.
5. A520 microarchitecture analysis
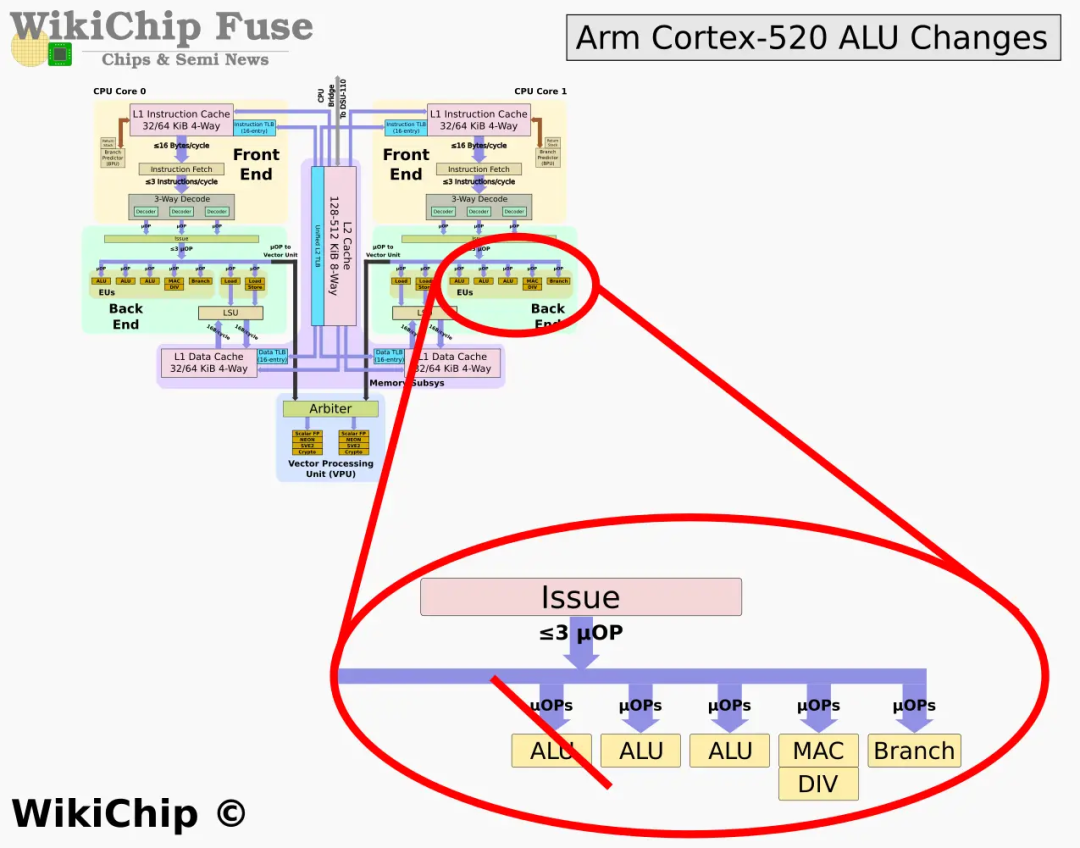
Let's take a look at the small core A520. The code name of the A520 small core is Hayes. It still does not support out-of-order execution. The design is relatively simple and the focus is on improving energy efficiency. A520 still inherits the design of A510's two small cores spliced together to share the SIMD unit. This time, the A520 only supports 64bit and no longer supports 32bit. The A520 provides a new QARMA3 PAC algorithm designed to reduce the impact of PAC to within 1%.

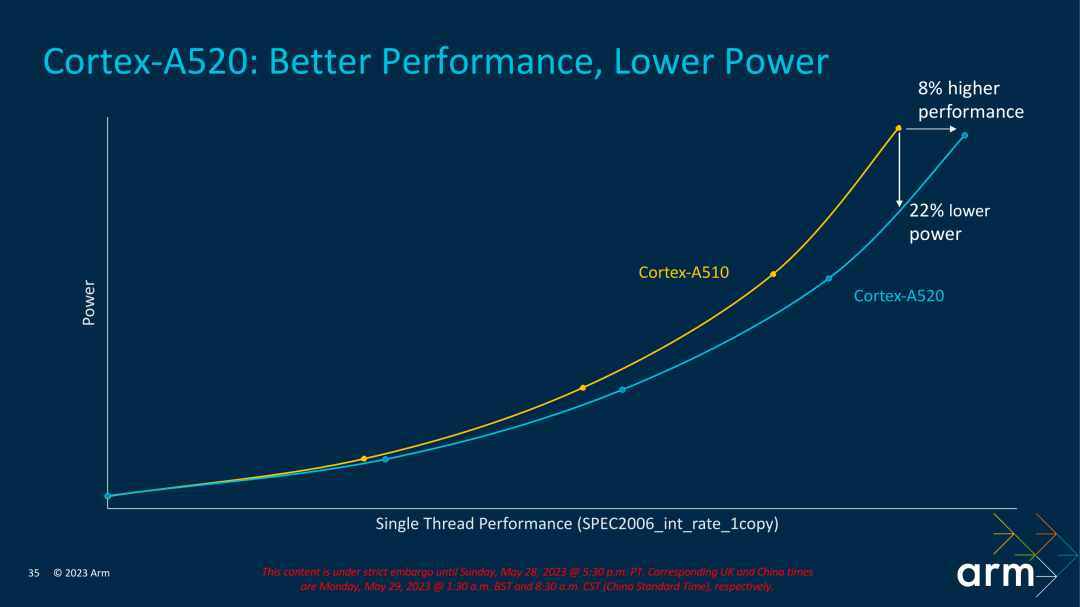
Compared with the A510, the A520 has also made a subtraction in order to improve energy efficiency. The main change is to reduce the ALU of an execution unit. The A510 has 3 ALUs, the A520 only has 2. Of course, Arm said that through global optimization, the performance loss can be compensated. According to the data provided by Arm, the power consumption of A520 can be reduced by 22% under the same performance; under the same power consumption, the performance can be improved by about 8 %, we will also actually test it.
Unfortunately, the 8% performance improvement still has a certain gap compared with the demand for flagship processors. We have seen that in this year's flagship processor design, chip manufacturers continue to reduce the use of A520 small cores, and some manufacturers even do not use A520 small cores at all. core.
6. Analysis of DSU120
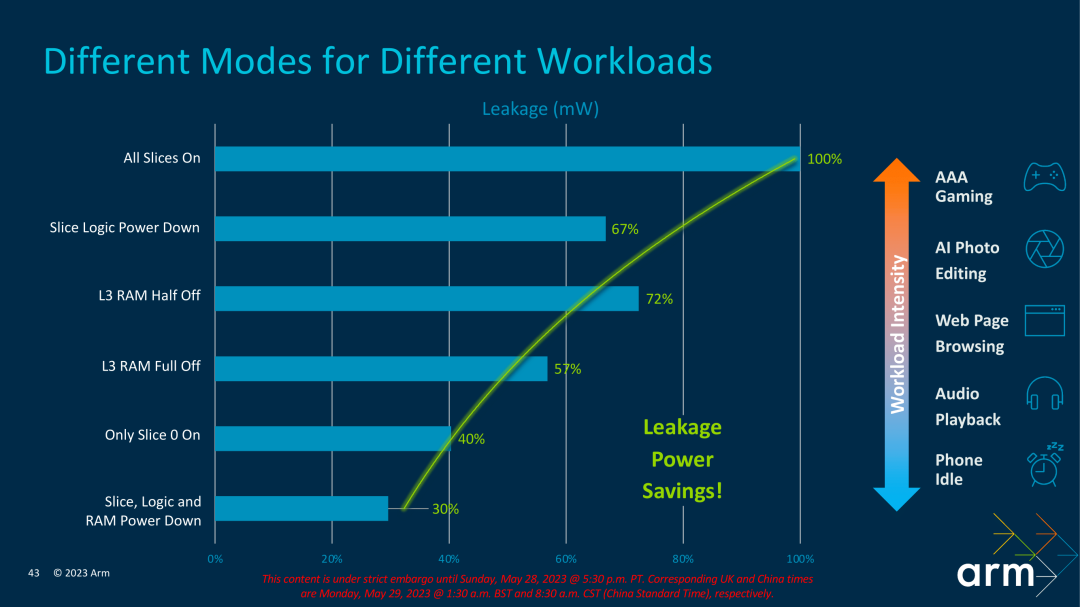
Finally, let's take a look at the DSU module used to coordinate processor cores and caches. Arm has upgraded the latest DSU120 module, which can support up to 14 cores in a Cluster and support up to 32MB of L3 cache management.
DSU120 provides a valuable function. As the L3 cache becomes larger and larger, static leakage becomes an influencing factor that needs to be considered, which will affect the standby power consumption scenario of the mobile phone. The DSU120 provides a partial L3 shutdown function. In some scenarios that do not need to use such a large cache, turning off part of the L3 cache can reduce static leakage.
7. Summary
This article mainly analyzes the latest processor architectures such as Cortex-X4, A720 and A520 released by Arm in 2023. This year is the fourth-generation X-series processor released by Arm. Through the previous analysis, we can see that Arm is continuously improving the computing performance of its core processors, challenging the industry's most advanced architecture design. At the same time, Arm also provides users with a more competitive product portfolio in terms of chip energy efficiency by optimizing the energy efficiency of A720 and A520.
In 2023, chip manufacturers are not satisfied with the traditional core configuration, and began to reduce the number of small cores and increase the architecture upgrade of large cores. We can see more multi-core SOC designs this year, with further improvements in multi-core performance. Undoubtedly, the processor competition in 2023 will be more intense. The introduction of multiple cores also requires vigilance against the risk of increased power consumption and heat generation. As a developer of chips and smart device terminals, it is necessary to fully understand the processor architecture and use reasonable software and hardware scheduling. Design, optimize the energy efficiency of the chip to the best, and provide users with the best and sustainable performance.
Review of previous articles:
1. From A76 to A78 - learning ARM micro-architecture in changes
2. Arm micro-architecture learning series 2 - opening the Armv9 era
3. Arm microarchitecture analysis series 3 - Arm's X plan
Reference link:
1、https://www.anandtech.com/show/18871/arm-unveils-armv92-mobile-architecture-cortex-x4-a720-and-a520-64bit-exclusive
2、A720 https://fuse.wikichip.org/news/7531/arm-introduces-the-cortex-x4-its-newest-flagship-performance-core/
3、8Gen3 https://www.xda-developers.com/qualcomm-snapdragon-8-gen-3/
4、Cortex-X4 https://twitter.com/Cardyak/status/1664753062487941120
5、A720 https://fuse.wikichip.org/news/7529/arm-introduces-a-new-big-core-the-cortex-a720/
6、A520 https://fuse.wikichip.org/news/7527/arm-launches-next-gen-efficiency-core-cortex-a520/
Past
Expect
push
recommend
ShaderNN 2.0: An efficient and lightweight mobile inference engine based on GPU full graphics stack
Chromium multi-process architecture, how much do you know?
On the importance of a good name: the change from Linux kernel page to folio

Long press to follow Kernel Craftsman WeChat
Linux Kernel Black Technology | Technical Articles | Featured Tutorials