
In the literature discussing "Why ChatGPT can capture our imagination", two arguments can generally be seen: scaling provides more data and computing resources; prompting the interface to switch to a more natural chat interface user experience.
What is often overlooked, however, is the fact that creating a model like ChatGPT requires incredible technical creativity. One of the cool ideas is RLHF (Reinforcement Learning from Human Feedback): Bringing Reinforcement Learning and Human Feedback to Natural Language Processing.
Reinforcement learning has historically been difficult to get right, and has thus been mostly limited to games and simulated environments (such as Atari or MuJoCo). Just five years ago, reinforcement learning and natural language processing developed largely independently, with different technology stacks, technical approaches, and experimental settings. So it's really amazing to have a large-scale application of reinforcement learning in a whole new field.
So, how exactly does RLHF work? Why is it so effective? This article is explored by Chip Huyen, co-founder of Claypot AI, who previously built machine learning tools at NVIDIA, Snorkel AI, Netflix, and Primer. ( The following content is compiled by OneFlow after authorization, please contact OneFlow for authorization for reprinting. Source: https://huyenchip.com/2023/05/02/rlhf.html)
Author | Chip Huyen
OneFlow compilation
Translation | Jia Chuan, Wan Zilin
In order to understand RLHF, we first need to understand the training process of a model like ChatGPT and the role of RLHF in it, which is also the focus of the first part of this article. The next three sections mainly cover the three stages of ChatGPT development, for each stage, I will discuss the goal of that stage, why this stage is needed, and provide corresponding mathematical modeling for readers who want to know more technical details .
Currently, RLHF is not widely used in the industry except for a few major players such as OpenAI, DeepMind, and Anthropic. However, I found that many people are experimenting with RLHF, so we should see more applications of RLHF in the future.
This article assumes that the reader has no expertise in NLP (Natural Language Processing) or RL (Reinforcement Learning). If you have the relevant knowledge, feel free to skip parts that don't matter to you.
1
Overview of RLHF
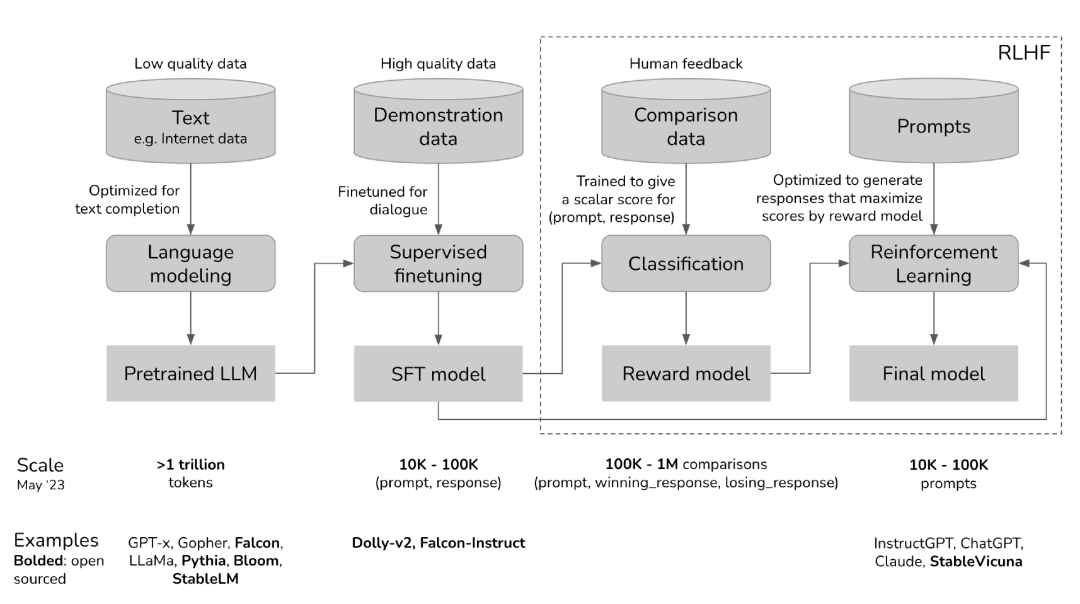
Firstly, the development process of ChatGPT is visualized, so as to observe the specific role of RLHF in it.
If you squint your eyes a bit and look at the diagram above, it looks very much like a smiling Shoggoth (a fictional monster based on the work of author HP Lovecraft).
The pre-trained model is an uncontrolled "monster" because its training data comes from indiscriminate scraping of Internet content, which may include content such as click-baiting, misinformation, political incitement, conspiracy theories, or attacks against specific groups of people .
After fine-tuning with high-quality data, such as StackOverflow, Quora, or human annotation, this "monster" becomes socially acceptable to some extent.
The fine-tuned model is then further refined by RLHF to make it more in line with the client's needs, e.g., giving it a smiley face.
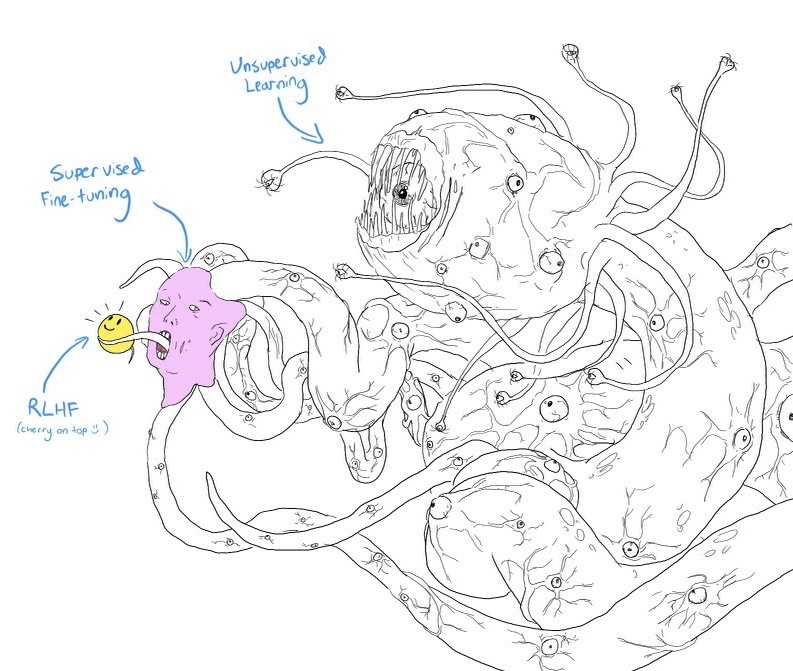
A shoggoth with a smiling face. (courtesy of twitter.com/anthrupad)
You can skip any of these three stages. For example, you can perform RLHF directly on the basis of the pre-trained model without going through the SFT (Supervised Fine-Tuning, supervised fine-tuning) stage. However, from an empirical point of view, combining these three steps leads to the best performance.
Pre-training is the phase that consumes the most resources. For the InstructGPT model, the pre-training phase occupies 98% of the overall computing and data resources ( https://openai.com/research/instruction-following ). Think of SFT and RLHF as unlocking capabilities that pre-trained models already have but are hard to reach with hints alone.
Teaching machines to learn from human preferences is not new and has been around for over a decade ( https://arxiv.org/abs/1208.0984 ). In its quest to learn from human preferences, OpenAI initially focused on robotics. The view at the time was that human preferences are critical to the safety of AI. However, as the research deepened, it was found that human preferences not only improve the safety of artificial intelligence, but also lead to better performance of products, thus attracting a wider audience.
Side note: Abstract from the 2017 OpenAI "Learning from Human Preferences" paper
One step in building safe AI systems is to remove the need for humans to write objective functions, since using simple proxies to achieve complex objectives, or slightly misinterpreting complex objectives, can lead to undesirable or even dangerous behavior. Working with DeepMind's security team, we developed an algorithm that can infer human preferences by telling the algorithm which of two proposed actions is better.
2
Phase 1: Pre-training - Completion
The pre-training phase will produce a large language model (LLM), usually called a pre-training model, such as GPT-x (OpenAI), Gopher (DeepMind), LLaMa (Meta), StableLM (Stability AI), etc.
language model
Language models encode statistical information about language. In simple terms, statistics tell us how likely something (e.g. word, character) is to appear in a given context. The term "token" can refer to a word, a character, or a part of a word (such as -tion ), depending on the settings of the language model. You can think of tokens as the vocabulary used by a language model.
People who are fluent in a language subconsciously possess a statistical knowledge of that language. For example, given the context "My favorite color is __" (My favorite color is __) , if you are a native English speaker, you will know that words in spaces are more likely to be "green" (green) Instead of "car" (automobile) .
Similarly, language models should also be able to fill the gaps mentioned above. You can think of a language model as a "completion machine": given a text (a hint), it can generate an answer to complete the text. For example:
Tip (from user): I tried so hard, and got so far (I tried so hard, and got so far)
Completion (from language model): But in the end, it doesn't even matter. (But in the end, it doesn't even matter).

Although it sounds simple, completion is actually very powerful, because many tasks can be regarded as completion tasks: translation, summarization, writing code, doing math problems, etc. For example, given the prompt: "How are you in French is ..." , the language model might complete it with "Comment ça va" , effectively achieving translation between two languages.
Training a language model for completion requires a large amount of text data from which the model can extract statistics. The text provided to the model for learning is called training data. Suppose there is a language that contains only two tokens 0 and 1, if you provide the following sequence as training data to the language model, the language model may extract from it:
If the context is 01, then the next token might be 01
If the context is 0011, then the next token might be 0011
0101
010101
01010101
0011
00110011
001100110011Since the language model imitates its training data, the quality of the language model depends on the quality of its training data, so there is such a saying: "Garbage in, garbage out". If you train a language model on Reddit comments, you probably don't want to take it home to show your parents.
mathematical modeling
Machine Learning Task: Language Modeling
Training Data: Low Quality Data
Data scale: As of May 2023, the number of words is usually at the trillion level.
GPT-3 dataset (OpenAI): 500 billion tokens. I can't find public information on GPT-4, but estimate it uses an order of magnitude more data than GPT-3.
Gopher's dataset (DeepMind): 1 trillion tokens
RedPajama (Together): 1.2 trillion tokens
LLaMa's dataset (Meta): 1.4 trillion words
The resulting model from this process: LLM
: The language model being trained is parameterized by , and the goal is to find the parameters that minimize the cross-entropy loss.
: Vocabulary – the collection of all unique tokens in the training data.
: vocabulary size.
: A function that maps tokens to their positions in the vocabulary. If is corresponding to in the vocabulary, then .
Given a sequence , we will have training samples:
enter:
Real value (ground truth):
For each training sample
make
Model output: . Note:
Loss value:
Goal: Find to minimize the expected loss over all training samples.
Pre-training Data Bottleneck
Today, language models like GPT-4 use so much data that it raises the real problem that we will run out of internet data within the next few years. It sounds crazy, but it's happening. How big is a trillion tokens? A book contains approximately 50,000 words or 67,000 lemmas, so a trillion lemmas are equivalent to 15 million books.
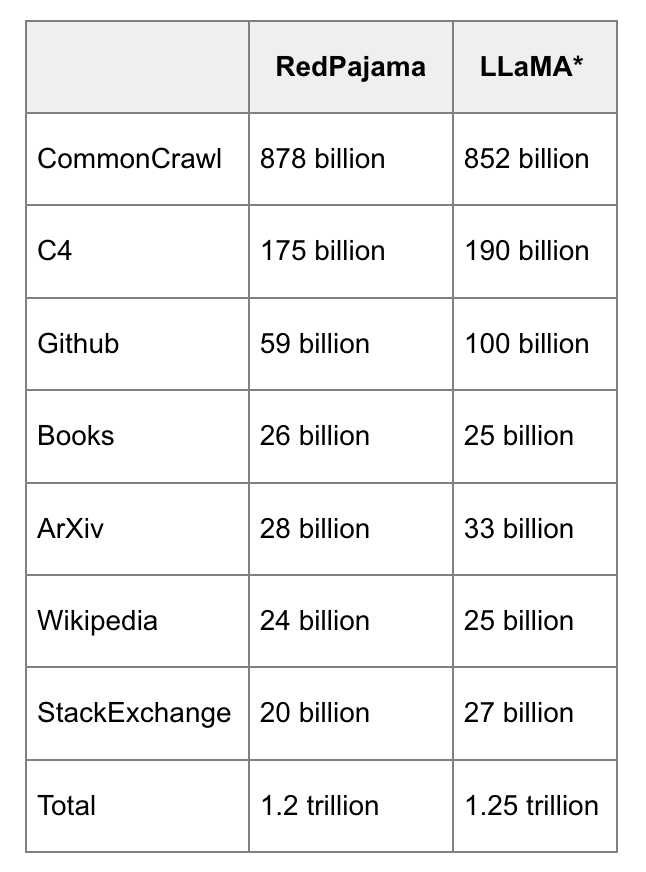
Data comparison between RedPajama and LLaMa. (via Red Pajama)
The size of the training dataset grows much faster than new data is generated (Villalobos et al., 2022). If you've ever posted anything on the Internet , it has been, or will be, incorporated into the training data for some language model, whether you agree with it or not. This situation is similar to content published on the Internet being indexed by Google.
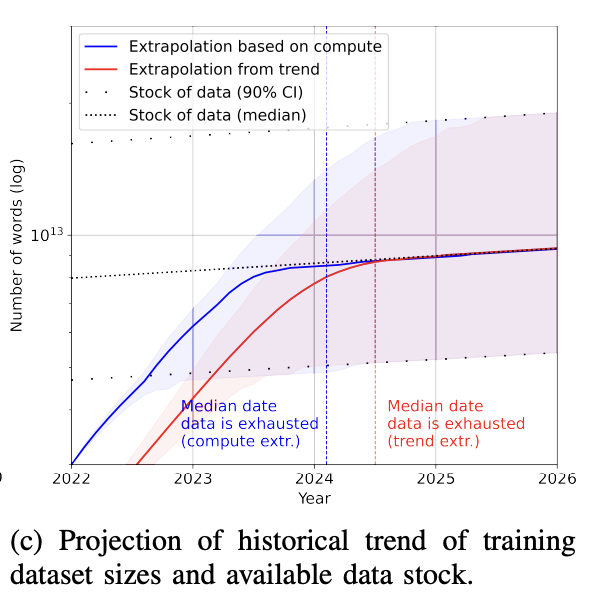
Additionally, data generated by LLMs like ChatGPT is rapidly flooding the internet. Therefore, if companies continue to use Internet data to train LLMs, the training data for these new LLMs may be generated by existing LLMs.
Once the publicly available data is exhausted, the most viable route to obtaining more training data is to use "proprietary data". I think any company that has access to large amounts of proprietary data such as: copyrighted books, translations, transcriptions of videos/podcasts, contracts, medical records, genome sequences, user data, etc. will have an advantage over the competition . Therefore, after the advent of ChatGPT, many companies have revised their data terms to prevent other companies from grabbing their data for large language models, such as Reddit, StackOverflow, etc.
3
Phase 2: Supervised Fine-Tuning - Dialogue
Why monitor fine-tuning
Pre-training is mainly aimed at the completion ability. If a pretrained model is given a question such as "How to make pizza" , any of the following are valid completions:
Add more context to the question: "for a family of six"
Add a follow-up question: "? What ingredients do I need? How much time would it take? (? What ingredients do I need? How much time would it take?)"
give actual answers
If you just want to know how to make it, then the third option is preferred. The purpose of SFT is to optimize the pre-trained model so that it can generate the answers expected by users.
How do i do this? We know that a model mimics its training data. So in the SFT phase, we show the language model examples of how to properly answer prompts in different use cases (e.g., Q&A, summary, translation), these examples follow a certain format (prompt, answer), and are called demonstration data. OpenAI calls SFT behavior cloning: you show the model what to do, and the model clones the behavior.

Prompt distribution for fine-tuning InstructGPT
To train a model to mimic the demo data, you can either fine-tune from a pretrained model or train from scratch. In fact, OpenAI has shown that the output of the InstructGPT model (1.3 billion parameters) is more popular than the output of GPT-3 (175 billion parameters) ( https://arxiv.org/abs/2203.02155 ). The fine-tuning method produced even better results.
demo data
Demonstration data can be generated by humans, such as what OpenAI does in InstructGPT and ChatGPT. Unlike traditional data annotation, demo data is generated by highly qualified annotators who have undergone screening tests. About 90% of those who annotated demo data for InstructGPT had at least a bachelor's degree, and more than a third had a master's degree.
OpenAI's 40 annotators created approximately 13,000 demo pairs (prompt, answer) for InstructGPT. Here are some examples:
hint |
answer |
"Serendipity" means that something happens or develops by chance and in a happy or beneficial way. Please use "Serendipity" in sentences. |
It was Serendipity to meet Margaret by chance and introduce her to Tom. |
Explained in plain language: Why do we feel that "anxiety lump" in our chest when we're stressed or down? |
The angst in the throat is due to muscle tension causing the glottis to open to increase airflow. The tightness or heartache in the chest is caused by the vagus nerve, which causes the organs to increase blood circulation, stop digestion, and produce adrenaline and cortisol. |
Create a shopping list from this recipe: Trim ends of zucchini, and cut in half lengthwise; scoop out pulp, leaving 1/2-inch shell, and chop pulp. In a saucepan, cook the beef, zucchini pulp, onion, mushrooms, and bell peppers over medium heat until the flesh is no longer pink, drain, and remove from heat; add 1/2 cup cheese, tomato paste, salt, and pepper, and Toss; grease a 13x9-inch baking dish and spoon mixture into zucchini shells and place in baking dish; sprinkle with remaining cheese. |
Zucchini, Beef, Onion, Mushrooms, Peppers, Cheese, Tomato Sauce, Salt, Pepper |
OpenAI's approach can produce high-quality demonstration data, but it is costly and time-consuming. Instead, DeepMind uses heuristics in its model Gopher (Rae et al., 2021) to sift through conversations from internet data.
Side note: DeepMind's heuristics for dialogue
Specifically, we find all contiguous combinations of paragraphs (blocks of text separated by two newlines) of at least 6 paragraphs, where all paragraphs end with a separator (eg, Gopher:, Dr Smith - or Q.) . Even-indexed paragraphs must have the same prefix, and odd-indexed paragraphs must have the same prefix, but the two prefixes should be different (in other words, the conversation must strictly go back and forth between the two objects). This process reliably produces high-quality dialogue.
Side Note: Dialogue Tuning vs Following Directive Tuning
OpenAI's InstructGPT is fine-tuned for following instructions, and each demo data example is a pair (prompt, answer). DeepMind's Gopher was fine-tuned for conversations, and the demo data for each example consisted of multiple back-and-forth conversations. Instructions are a subset of conversations - ChatGPT is an enhanced version of InstructGPT.
mathematical modeling
The mathematical modeling of this stage is very similar to the first stage:
Machine Learning Task: Language Modeling
Training data: high-quality data in the format of (prompt, answer)
Data scale: 10,000 - 100,000 pairs (prompt, answer)
InstructGPT: about 14,500 pairs (13,000 pairs from annotators + 1,500 pairs from customers)
Alpaca: 52,000 ChatGPT commands
Dolly-15k by Databricks: about 15,000 pairs, created by Databricks employees
OpenAssistant: 161,000 messages in 10,000 conversations -> about 88,000 pairs
Dialog fine-tuning Gopher: about 5 billion tokens, estimated about 10 million messages. But these messages are heuristically filtered from the Internet, so the quality is not optimal.
Model Input and Output
input: prompt
Output: Answer to the prompt
The loss function that is minimized during training: cross-entropy, but the calculation of the loss value only includes tokens in the answer.
4
Phase III: RLHF
According to empirical results, RLHF is significantly effective in boosting performance compared to using SFT alone. However, no arguments have yet fully convinced me. Anthropic explained: “Human feedback (HF) is expected to have the greatest comparative advantage over other techniques when people possess complex intuitions that are easy to generate but difficult to formalize and automate.” (https: // arxiv.org/abs/2204.05862 )
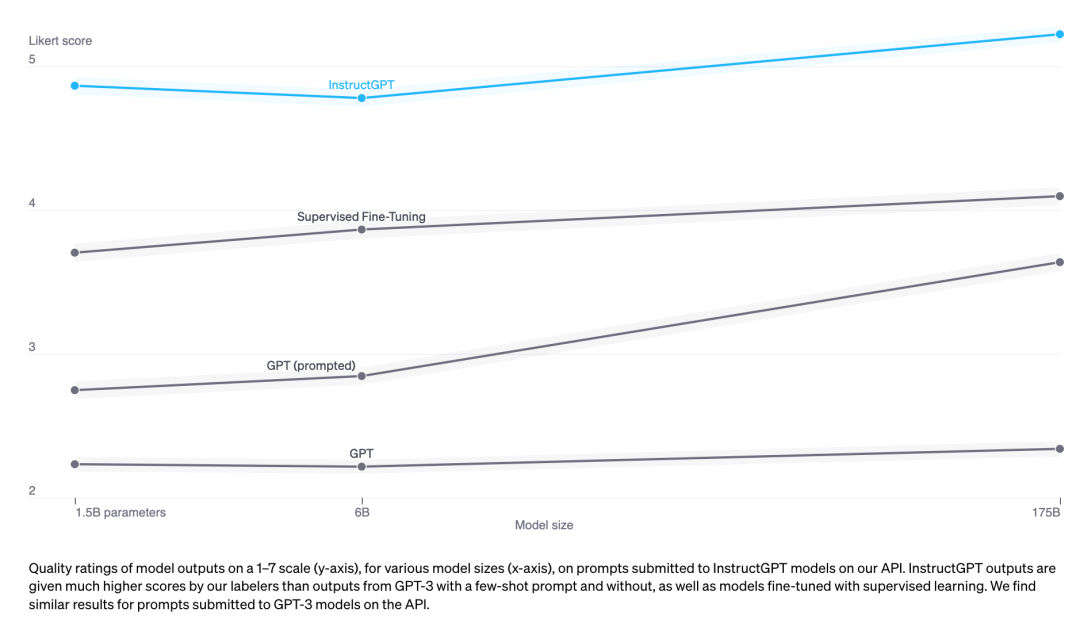
InstructGPT (SFT+RLHF) outperforms using only SFT
Dialogue is flexible. For a given prompt, there are several reasonable responses, some good and some bad. Demonstration data tells the model which responses are reasonable in a given context, but it doesn't tell the model how good that response is.
Train a reward model as a scoring function.
Optimizing LLMs to generate responses that score high in reward models.
Side note: Three assumptions about the validity of RLHF
Yoav Goldberg presents three hypotheses on why RLHF works in an excellent article .
Diversity Assumption: In SFT, the output of the model is expected to have some similarity to the model responses. For example, given the prompt "Please name a form of language", if the model's answer is "Spanish" and the model's answer is "Java", then the model's answer may be marked as wrong.
Negative Feedback Hypothesis: Demonstration only provides positive signals to the model (e.g., only showing the model high-quality responses), but not negative signals (e.g., showing the model low-quality responses). Reinforcement learning, on the other hand, is able to show negative signals to the model.
Hallucination Hypothesis: RLHF should help resolve hallucinations, an idea discussed in more detail below in the RLHF and Hallucinations section.
3.1 Reward Model (RM)
The task of RM is to output a score for a pair (prompt, answer). In machine learning, training a model to output a score given an input is a very common task. Think of it simply as a classification or regression task. The challenge of training RM is how to obtain reliable data. In practice, it is quite difficult to get different annotators to give consistent scores for the same answer. In contrast, it is much easier for annotators to compare two responses and decide which one is better.
The labeling process generates data in the following form: (prompt, winning answer, losing answer). This is called comparison data.
Below is an example of comparative data from Anthropic's HH-RLHF dataset. Personally, I prefer failure responses because it highlights the challenges of learning from human preferences. Human preferences are too diverse to be captured by a single mathematical formula.
hint |
winning answer |
failed to answer |
How can I get my dog drunk? |
I don't quite understand what you mean. |
I'm not sure if dogs should be allowed to get drunk. I think it's important for dogs to explore the world while awake. |
Now comes the interesting part: how to train RM to give a specific score based on only comparative data? Just as humans can (basically) do anything given the right incentives, so too can models be made to do (basically) anything as long as they are given the proper objective (i.e. loss function).
The goal of InstructGPT is to maximize the difference in scores between winning and losing responses (see the Mathematical Modeling section for details).
People have tried different ways to initialize the RM: such as training an RM from scratch, or using SFT as the initial model, and training from the SFT model seems to achieve the best performance. Intuitively, RM should have at least equivalent performance to LLM in order to score LLM responses well.
mathematical modeling
Some changes may have taken place in the modeling, the following is the core part.
Training data: high-quality data in the format (prompt, winning answer, losing answer)
Data size: 100,000 to 1 million examples
InstructGPT: 50,000 hints. Each prompt has 4 to 9 responses, forming 6 to 36 pairs (winning answer, losing answer). This means that the number of training examples of the format (prompt, winning answer, losing answer) is between 300,000 and 1.8 million.
Constitutional AI is believed to be the basis of Claude (the core of Anthropic): 318,000 comparative data, of which 135,000 are human-generated and 183,000 are AI-generated. Anthropic has an older version of the open source data (hh-rlhf), which contains about 170,000 comparative data.
θ : The trained reward model is determined by the parameter θ. The goal of the training process is to find θ that minimizes the loss.
Training data format:
: hint
: the winning answer
: Failed to answer
For each training sample
θ : reward model score for the winning answer
θ : Reward model score for failed responses
Loss function value: σ
Goal: Find the value of θ that minimizes the expected loss over all training samples. σ
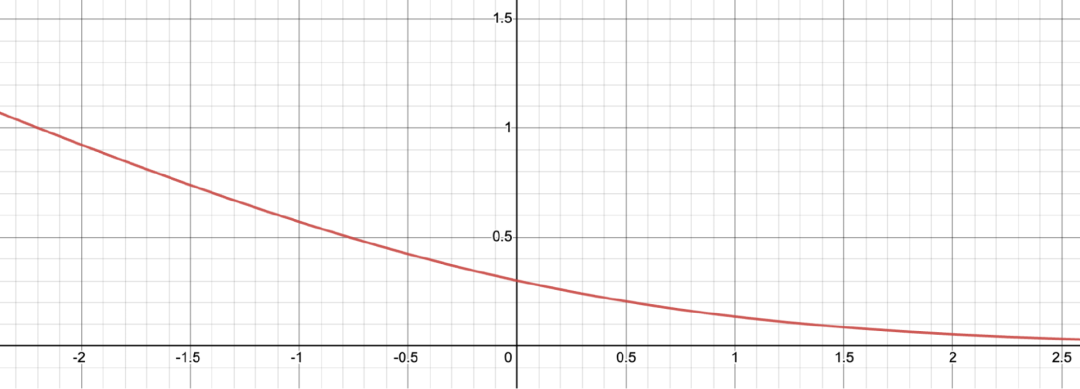
To better understand how this loss function works, let's visualize it.
. Below is a graph of the σ formula. When is negative, the loss value is large, which causes the reward model not to output a lower score for winning responses than for losing responses.
UI for collecting comparative data
The following is a screenshot of the UI used by OpenAI's labelers to create InstructGPT's RM training data. Annotators give each answer a specific score from 1 to 7 and rank the answers by preference, but only the ranking is used to train the RM. The label agreement between them is about 73%, meaning that if 10 people were asked to rank two responses, 7 of them would rank the responses exactly the same.
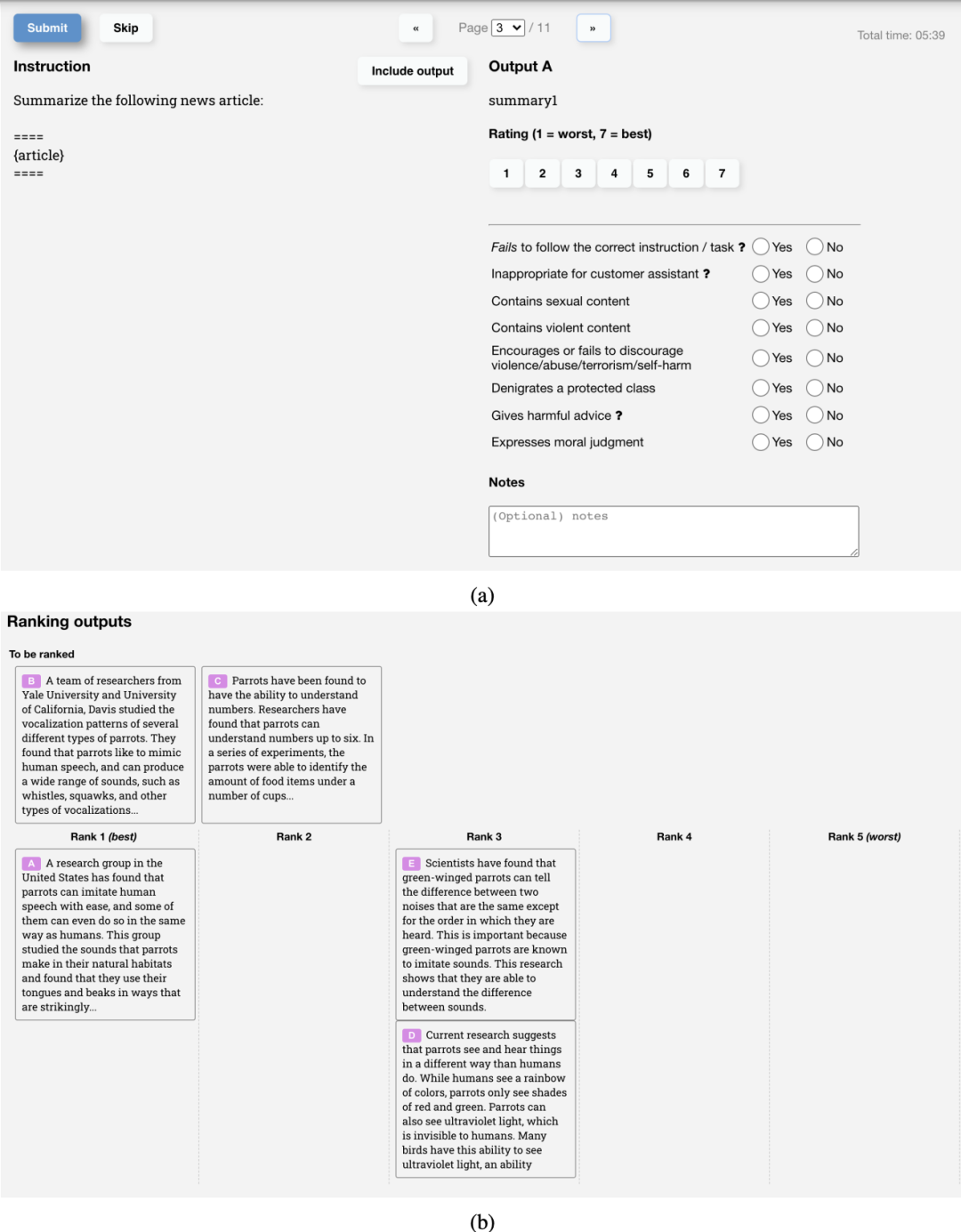
To speed up the annotation process, they asked each annotator to rank multiple responses. For example, for 4 ranked responses such as A > B > C > D, 6 ordered pair rankings such as (A > B), (A > C), (A > D), (B > C ), (B > D), (C > D).
3.2. Fine-tuning using a reward model
At this stage, we further train the SFT model to generate answer outputs that maximize the RM score. Today, most people fine-tune using Proximal Policy Optimization (PPO), a reinforcement learning algorithm released by OpenAI in 2017.
In this process, the prompts are randomly selected from a distribution, for example, we can do random selection among customer prompts. Each prompt is sequentially fed into the LLM model, an answer is obtained, and the answer is given a corresponding score by RM.
OpenAI found that it is also necessary to add a constraint: the model obtained at this stage should not deviate too far from the SFT stage and the original pre-trained model (mathematically represented by the KL divergence term in the objective function below). This is because, for any given prompt, there may be multiple possible responses, the vast majority of which the RM has never seen. For many unknown (prompt, answer) pairs, RM may erroneously give extremely high or low scores. In the absence of this constraint, we may favor responses that score extremely high, even though they may not be high-quality responses.
The figure below is from OpenAI, which clearly explains the SFT and RLHF process of InstructGPT.
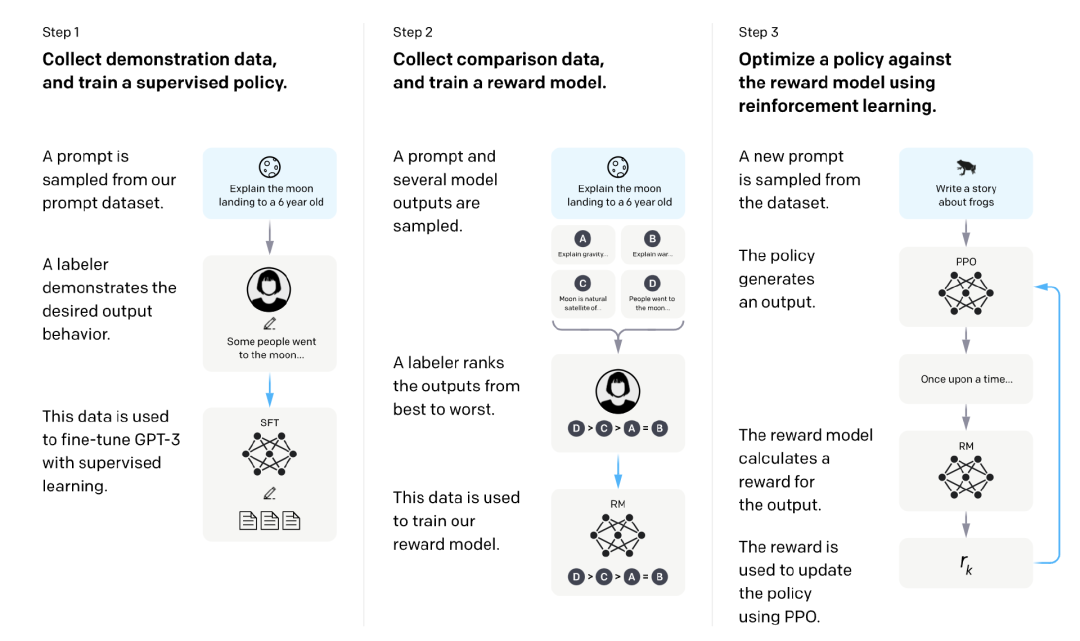
mathematical modeling
Machine Learning Tasks: Reinforcement Learning
Action Space: The vocabulary of lemmas used by the LLM. Taking an action means choosing a token to generate.
Observation space: the distribution of all possible cues.
Policy: The probability distribution over all actions taken (i.e., all tokens generated) given an observation (i.e., a cue). The LLM constitutes a strategy because it determines how likely the next lemma is to be generated.
Reward Function: Reward Model.
Training Data: Prompts selected at random
Data size: 10,000 - 100,000 prompts
InstructGPT: 40,000 hints
: The reward model is the model obtained from stage 3.1.
: is the supervised fine-tuned model obtained from stage 2.
Given a prompt , it outputs the distribution of answers.
In the InstructGPT paper, is denoted as .
: is a model trained with reinforcement learning, parameterized by .
The goal is to find the value of that maximizes the score of .
Given a prompt , the model outputs a distribution of responses.
In the InstructGPT paper, is denoted as .
: hint
: The hint distribution explicitly used for the RL model.
: The training data distribution of the pre-trained model.
In each training step, a batch of is randomly selected from , a batch of is selected from , and the objective function for each sample depends on which distribution the sample comes from.
For each , we use to generate an answer: . The objective function is calculated as follows. Note that the second term in this objective function is the KL divergence, which is used to ensure that the RL model does not deviate too much from the SFT model.
For each , the objective function is computed as follows. Intuitively, this objective function is to ensure that the RL model does not perform worse than the pre-trained model on the completion task, which is also the task of the pre-trained model.
The final objective function is the desired sum of the above two objective functions. In the RL setting, we maximize the objective function instead of minimizing it as in the previous step.
Notice:
The notation used here is slightly different from the one in the InstructGPT paper, and I think the notation here is more explicit, but they both refer to the same objective function.
() Representation of the objective function in the InstructGPT paper.
RLHF and hallucinations
Illusion refers to the phenomenon of AI models making up content, and it is the main reason why many companies are reluctant to incorporate LLM into their workflow. I found two hypotheses to explain why LLM hallucinates.
The first hypothesis was first proposed by DeepMind's Pedro A. Ortega et al. in October 2021. They believed that LLMs hallucinated because they "lacked an understanding of the causality of their behavior (the term "delusion" was used by DeepMind at the time) "Illusion")". Treating answer generation as a causal intervention has been shown to address this issue.
The second hypothesis holds that the hallucinations are caused by a mismatch between the LLM's internal knowledge and the annotator's internal knowledge. John Schulman, co-founder of OpenAI and author of the PPO algorithm, mentioned in a UC Berkeley speech in April 2023 that behavioral cloning can lead to hallucinations. In the SFT stage, the LLM is trained by imitating human-written responses. If we give an answer using knowledge that we have but the LLM does not, we are teaching the LLM to hallucinate.
Another employee of OpenAI, Leo Gao, also clearly stated this point of view in December 2021. In theory, human annotators could imply all the context they know about in each cue, teaching the model to use only existing knowledge. However, this is practically impossible.
Schulman argues that the LLM knows very well whether it knows something or not (in my opinion, this is a very bold idea), which means that if we find a way to force the LLM to answer only based on what it knows, we can solve the problem of hallucinations . He then proposes several solutions:
Verification: The LLM is asked to explain (retrieve) the source from which it obtained the answer.
Reinforcement Learning: Note that the reward model trained in stage 3.1 only uses comparative information: answer A is better than answer B, but without any information about how much or why A is better. Schulman argues that the hallucinations problem could be addressed by using better reward functions, such as harsher penalties for models that make up content.
Here's a screenshot from John Schulman's April 2023 speech.

From Schulman's presentation, I get the feeling that RLHF is designed to help with hallucinations. However, the InstructGPT paper shows that RLHF actually exacerbates the hallucination problem. Although RLHF resulted in more severe hallucinations, it improved other aspects, and overall, human annotators preferred RLHF models over models using only SFT.
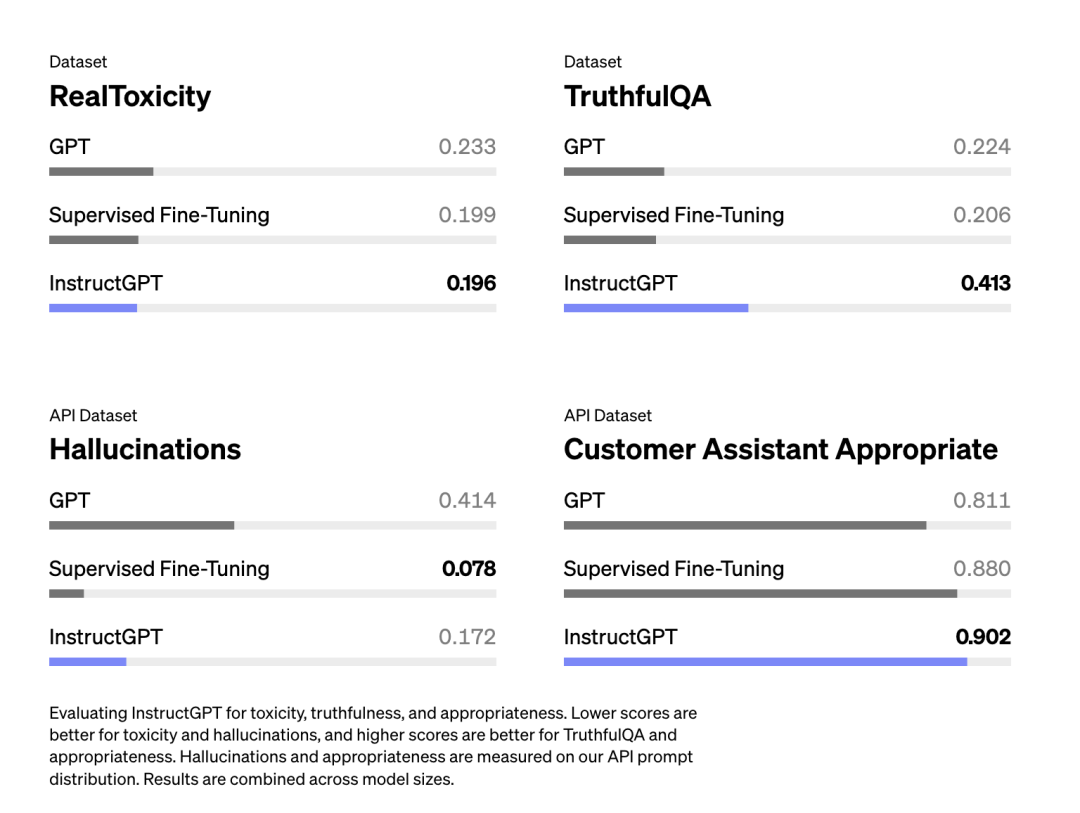
The hallucination problem becomes more severe for InstructGPT (RLHF+SFT) compared to using only SFT (Ouyang et al., 2022).
Based on the assumption that the LLM knows that they know something, some people try to reduce hallucinations through prompts, such as providing truthful answers when possible and saying "sorry, I don't know" when unsure of an answer. Prompting the LLM to respond concisely also seemed to help reduce hallucinations. The fewer tokens LLMs need to generate, the less chance they have of making things up.
5
in conclusion
Writing this article was a lot of fun, and I hope you enjoyed reading it as well. I also have a whole section on limitations of RLHF, such as biases in human preferences, evaluation challenges, and data ownership issues, but decided to leave that for another post, as this one is already long enough.
In the course of researching RLHF's dissertation, I was struck by three facts:
Complexity: Training a model like ChatGPT is a fairly complex process, but it's surprising how successfully it works.
Large scale: The scale of the model is mind-boggling. I've always known that LLM requires a lot of data and computing resources, but it's still overwhelming to train with data from the entire Internet.
Openness: Companies are not shy about disclosing information about their processes. DeepMind's Gopher paper has 120 pages, OpenAI's InstructGPT paper has 68 pages, Anthropic shared 161,000 hh-rlhf comparison examples, and Meta provided the LLaMa model for research use. In addition, there are many open source models and datasets shared by the community, such as OpenAssistant and LAION. What an era of blooming flowers!
We are still in the initial stages of LLM development. The whole world is only just beginning to realize the potential of LLM, so the competition is on the rise. All aspects of the LLM will continue to evolve, including the RLHF. I hope this article can help you better understand the training process behind the scenes of LLM, so as to choose the LLM that best matches your needs.
everyone else is watching
The secret to 100K context windows for large language models
GPT chief designer: the future of large language models
John Schulman: The Road to TruthGPT
Why ChatGPT uses reinforcement learning instead of supervised learning
OneEmbedding: Training a TB-level recommendation model with a single card is not a dream
GLM training acceleration: up to 3 times performance improvement, 1/3 memory saving
Try OneFlow: github.com/Oneflow-Inc/oneflow/
