
Author | The stone that floats like a dream
guide
With the wide application of real-time computing technology in big data, the timeliness of data has been greatly improved, but in actual application scenarios, in addition to timeliness, it also faces higher technical requirements.
This paper combines the exploration and practice of real-time computing water level technology in the flow-batch integrated data warehouse, focusing on the concept of water level technology and related theoretical practices, especially the characteristics, boundary definition and application of water level in real-time computing systems, and finally focuses on the description An improved design and implementation of accurate water level is presented. The technical architecture is currently mature and stable in Baidu's actual business scenarios, and I would like to share it with you, hoping to be of reference value to everyone.
The full text is 7118 words, and the expected reading time is 18 minutes.
01 Business background
In order to improve the efficiency of product development, strategy iteration, data analysis, and operational decision-making, businesses have higher and higher requirements for timeliness of data.
Although we realized the construction of a real-time data warehouse based on real-time computing very early, it still cannot replace the offline data warehouse. The cost of development and maintenance of a set of real-time and offline data warehouses is high, and the most important thing is that the caliber of the business cannot be 100%. align. Therefore, we have been committed to building a stream-batch integrated data warehouse, which can not only speed up the overall data processing efficiency, but also ensure that the data is as reliable as offline data, and can support 100% business scenarios, so as to achieve overall cost reduction and efficiency improvement.
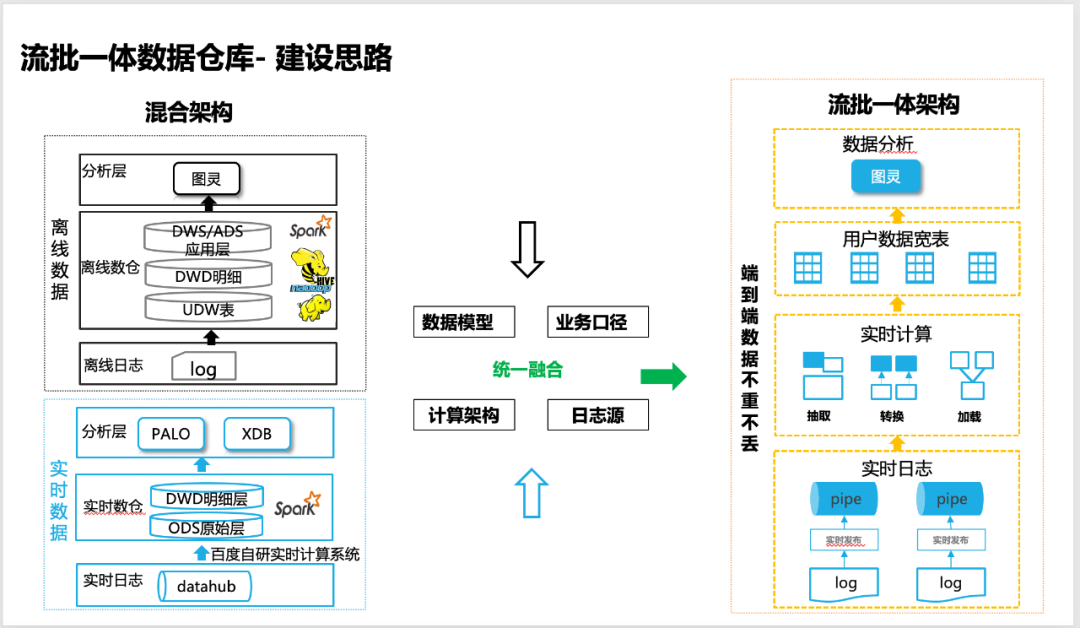
△The idea of building a stream-batch integrated data warehouse
02 Technical Difficulties of Stream-Batch Integrated Data Warehouse
In order to realize the end-to-end integrated streaming and batch data warehouse, as the real-time computing system of the underlying technical architecture, it faces many technical difficulties and challenges:
1. The end-to-end data is strictly not repeated or lost to ensure the integrity of the data;
2. The real-time data window and the offline data window, including the data are aligned (99.9% ~ 99.99%) ;
3. Real-time calculation needs to support accurate window calculation to ensure the accurate effect of real-time anti-cheating strategy;
4. The real-time computing system is integrated with Baidu's internal big data ecology, and there is actual practice of large-scale online stable operation.
The above 2 and 3 points all require a highly reliable water level mechanism to ensure progress awareness and accurate segmentation of real-time data.
Therefore, this article shares with you the exploration and practical experience of accurate water level in the stream-batch integrated data warehouse.
03 Current status of water level concept and general implementation
3.1 Necessity of water level
Before introducing the concept of Watermark, two concepts need to be inserted:
-
Event time, the time when the event occurred. We generally understand it as the time when the user's real behavior occurred, and specifically correspond to the timestamp when the user's behavior occurred in the log.
-
Processing time, data processing time. We generally understand it as the time for the system to process data.
What is the specific use of the watermark?
In the actual real-time data processing process, the data is unbounded (Unbounded), so window computing based on Window or other similar scenarios face a practical problem:
How do you know that the data in a certain window is complete? When can window compute() be triggered?
In most cases, we use Event Time to trigger window calculations (or data partition splitting, and offline alignment). However, the actual situation is that real-time logs always have different degrees of delay (in the stages of log collection, log transmission, and log processing), that is, as shown in the figure below, the skew of the watermark will actually occur (that is, the data will appear out of order). In this case, the Watermark mechanism is necessary to ensure the integrity of the data.
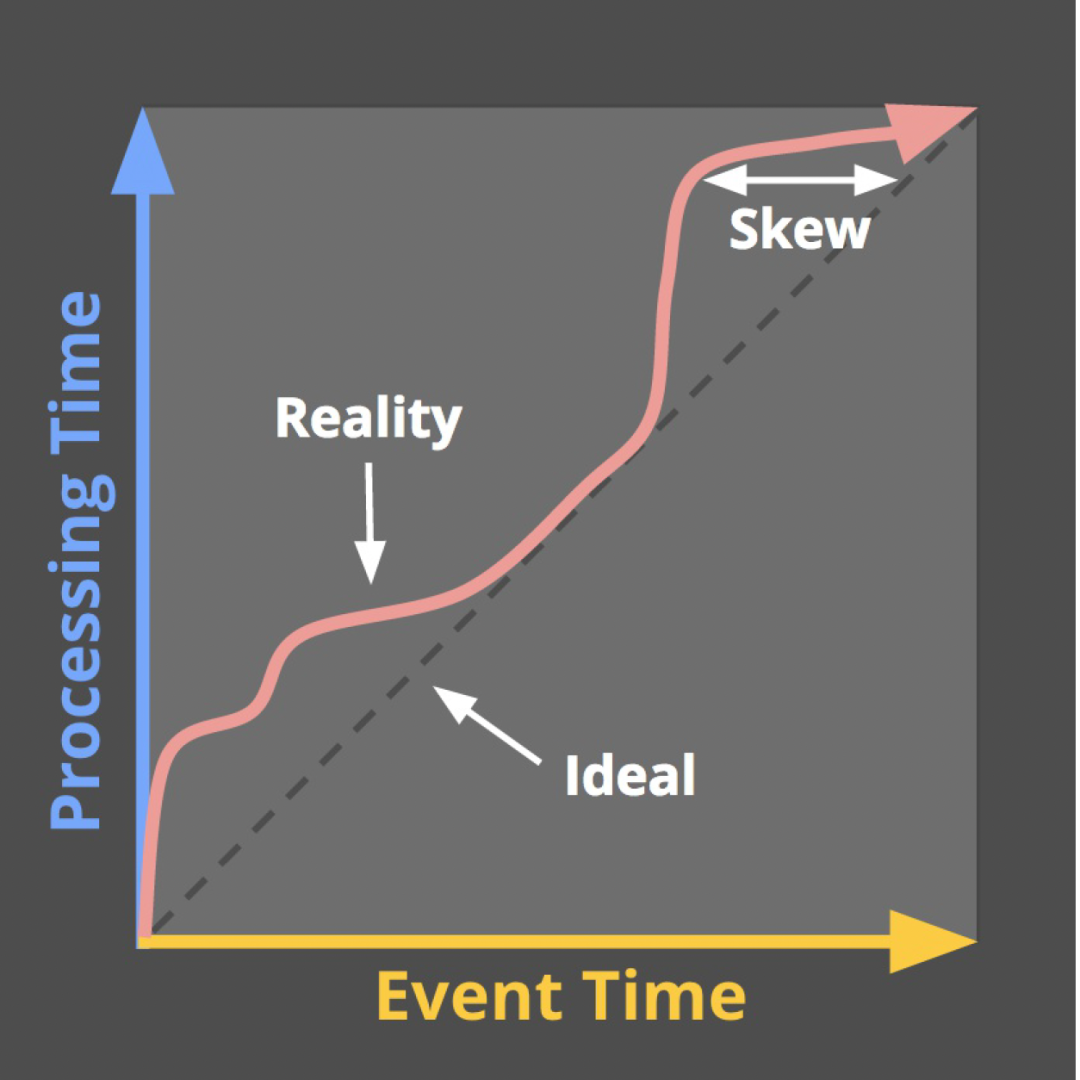 △Water level tilt phenomenon
△Water level tilt phenomenon
3.2 Definition and characteristics of water level
The definition of watermark (watermark) is currently not uniform in the industry. Combined with the definition in the book ** Streaming Systems ** (the author is the Google Dataflow R&D team), I personally think it is more accurate:
The watermark is a monotonically increasing timestamp of the oldest work not yet completed.
From the definition, we can summarize the two basic characteristics of the water level:
-
The water level is continuously increasing (non-returnable)
-
The water level is a timestamp
However, in the actual production system, how to calculate the water level, and what is the actual effect? Combined with different real-time computing systems in the industry, the support for water levels is still different.
3.3 Current water level status and challenges
In the current real-time computing systems in the industry, such as Apache Flink (an open source implementation of Google Dataflow) and Apache Spark (only limited to the Structured Streaming framework), they all support water levels. The following is the most popular Apache Flink in the community. List the water level Implementation Mechanism:

However, the implementation mechanism and effect of the above water level, in the case of a large area of delayed log transmission at the log source, the water level will still be updated (new and old data are transmitted out of order) and advance, which will lead to incomplete data in the corresponding window and inaccurate window calculation. . Therefore, within Baidu, we have explored an improved and relatively accurate water level mechanism based on the log collection and transmission system and the real-time computing system to ensure that real-time data is calculated in the window and data landing (sink to AFS/Hive) and other application scenarios Next, the problem of the integrity of the window data is to meet the requirements of realizing the stream-batch integrated data warehouse.
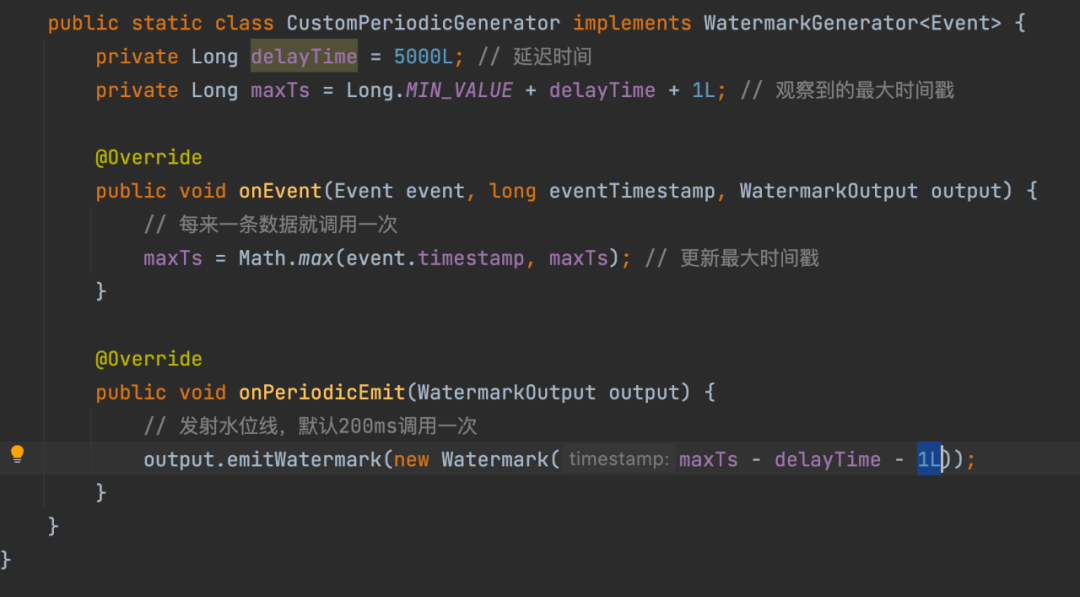
△Flink water level generation strategy
GEEK TALK
04 Design and application of global water level
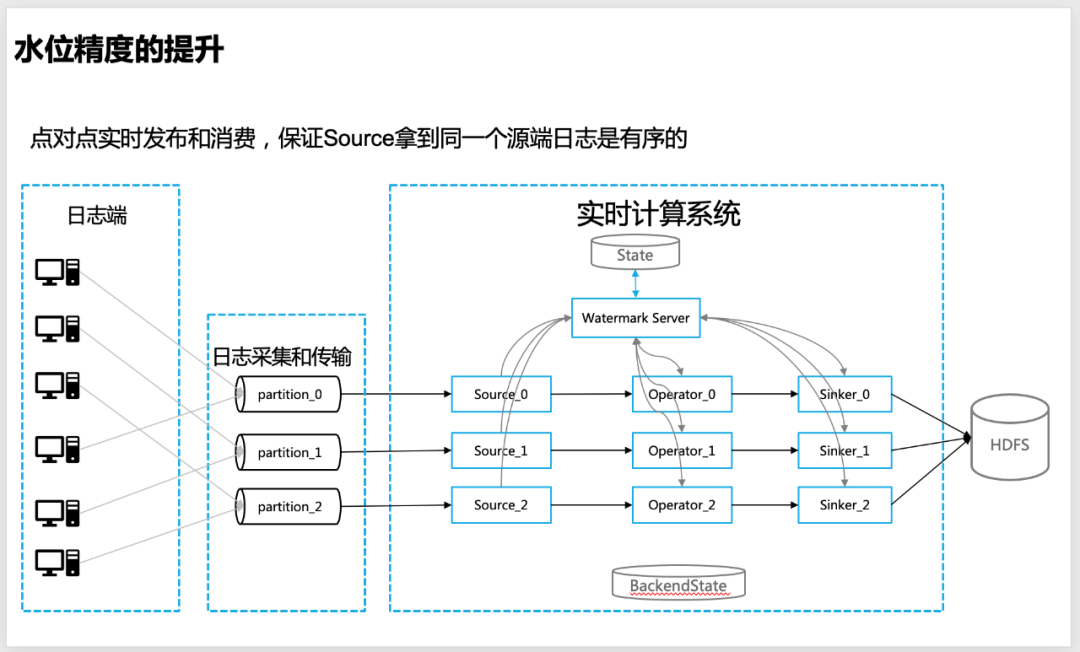
4.1 Design of centralized water level management
In order to make the water level more accurate in real-time calculation, we designed a centralized water level management idea, that is, each node of real-time calculation, including source, operator, sinker, etc., will report the water level information calculated by itself to the global Watermark Server, the unified management of water level information is carried out by Watermark Server.
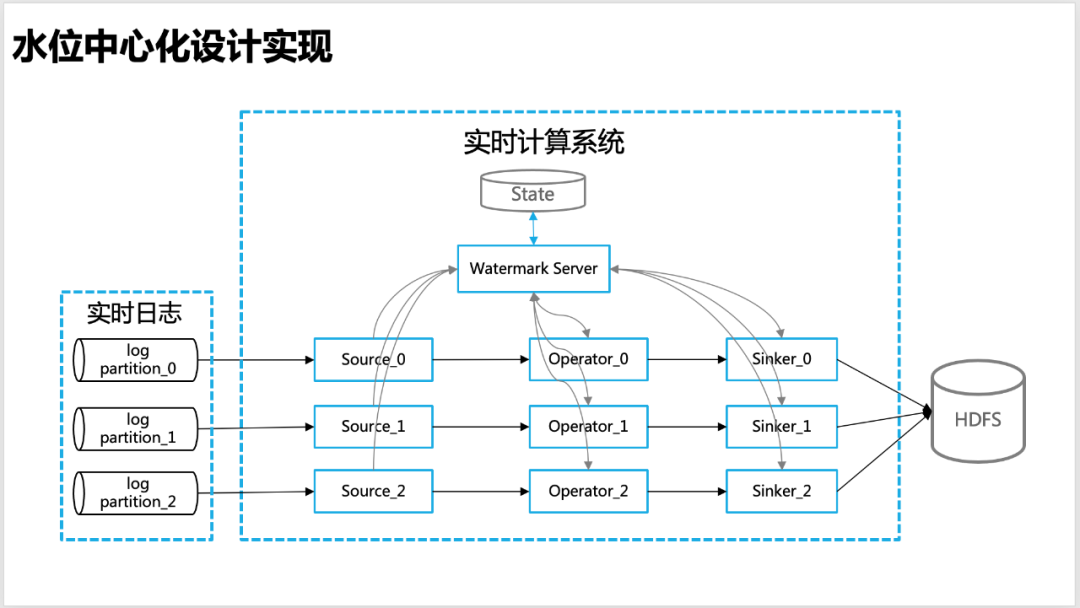
△Centralized water level design
Watermark Server : maintain a water level information table (hash_table), which contains the water level information corresponding to each level of the overall topology information (Source, Operator, Sinker, etc.) of the real-time calculation program (APP), so as to facilitate the calculation of the global water level (such as low watermark) , Watermark Server interacts with the state regularly to ensure that the water level information is not lost.
Watermark Client : Water level update client, in real-time operators such as source, worker and sinker, is responsible for reporting and requesting water level information (such as upstream or global water level) to Watermark Server, and requesting callback through baidu-rpc service.
Low watermark (low water level) : Low watermark is a timestamp used to mark the time of the earliest (oldest) unprocessed data in the real-time data processing process (Low watermark, which pessimistically attempt to capture the event time of the oldest unprocessed record the system is aware of. ). It promises that no future data will arrive earlier than that timestamp. The time calculation here is generally based on eventtime, that is, the time when the event occurs, such as the time when the user behavior in the log occurs, and the data processing time (processing time, which can also be used in some scenarios) is less used. The formula for watermark calculation is (from Google MillWheel Thesis ):
Low Watermark of A = min(oldest work of A, low watermark of C : C outputs to A)
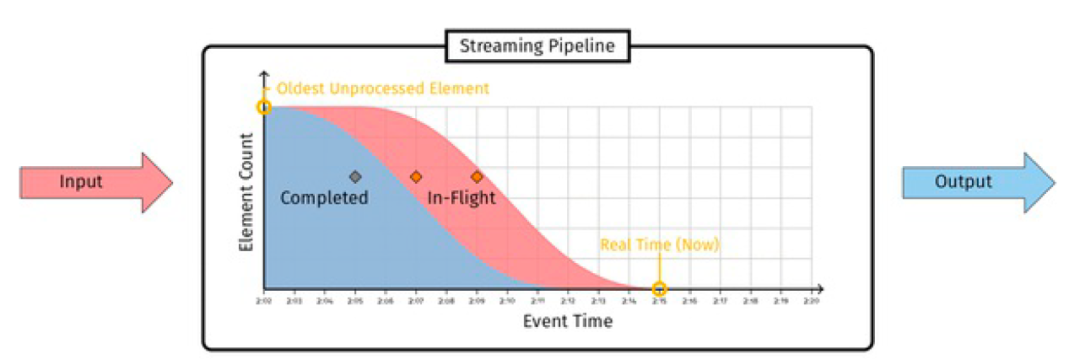
However, in actual system design, low watermark can be distinguished according to the boundary of operator processing as follows:
-
Input Low Watermark: Oldest work not yet sent to this streaming stage.
InputLowWatermark(Stage) = min { OutputLowWatermark(Stage’) | Stage’ is upstream of Stage}
Input the lowest water level, which can be understood as the watermark that will be input to the current operator, that is, the data processed by the upstream operator.
-
Output Low Watermark: Oldest work not yet completed by this streaming stage.
OutputLowWatermark(Stage) = min { InputLowWatermark(Stage), OldestWork(Stage) }
Output the lowest water level, which can be understood as the earliest (oldest) water level of unprocessed data by the current operator, that is, the water level of processed data.
As shown in the figure below, the understanding will be more vivid.
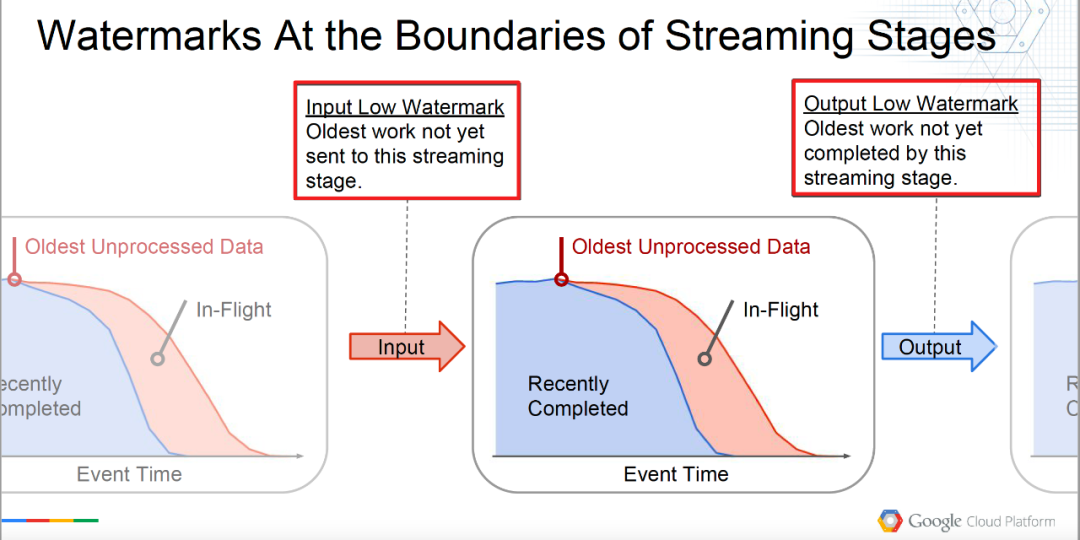 Boundary definition of △Low watermark
Boundary definition of △Low watermark
4.2 How to achieve accurate water level
4.2.1 Preconditions for accurate water level
At present, in the application scenarios of real-time computing systems in real-time data warehouses, we all use low watermark to trigger window calculation (because it is more reliable). From the definition of low watermark in 3.1, we can know that: low watermark is calculated by hierarchical iteration, and whether the water level is accurate , depends on the accuracy of the most upstream (ie source) water level. So in order to improve the accuracy of source water level calculation, we need prerequisites:
-
Logs are produced sequentially according to time (event_time) on a single server on the server side
-
When the log is collected, in addition to the real user behavior log, it also needs to contain other information, such as server tag (hostname) and log time (msg_time), as shown in the following figure

△ Log packaging information
-
The log is published to the message queue in real time point-to-point to ensure that within a single partition of the message queue, the logs of a single server are strictly ordered
△The source log is published point-to-point to the message queue to ensure that the single-partition log is orderly
4.2.2. Calculation method of water level
1、Watermark server
Initialize :
First started as a separate thread (thread). According to the BNS (Baidu Naming Service, Baidu name service, which provides a mapping from the service name to all running instances of the server) of the configured log transmission task, the server list (hostname list) of the log source is parsed; according to the configured APP topology relationship, the watermark is initialized Information table, and persistent write Table (Baidu distributed kv storage engine).
Ordinary water level information update : Receive the water level information from the client and update the water level of the corresponding granularity (processor granularity or keygroup granularity), and update the local water level
Accurate water level calculation :
In reality, if the log at the source is required to arrive 100% accurately, it will cause frequent delays or too long delays (if the global Low watermark logic is used for delivery). The reason is: in the case of too many server instances on the log side (for example, we actually have 6000-10000 instances of logs), there will always be a delay in real-time uploading of logs in instances of wired online services, so this needs to be done in Make a compromise between data integrity and timeliness, such as accurately controlling the number of instances that allow delays in the form of percentages (for example, configure 99.9% or 99.99% to set the proportion that allows source logs to be delayed ), to accurately Controls the accuracy of the water level at the very source.
The precise water level requires special configuration. The output low watermark of the source is calculated according to the mapping relationship between the server and the log progress reported by the source in real time, and the configured ratio of allowed delay instances.
Calculate the global low Watermark : a global minimum water level will be calculated and returned to the client's request
State Persistence : Periodically write global water level information persistence to external storage for easy state recovery
2、Watermark Client
Source end : parse the log package, and obtain information such as the machine name and the original log in the log package. After the original log is processed by ETL, and the latest time stamp (event_timestamps) is obtained according to the original log, Source periodically reports the mapping relationship table resolved to hostname and the latest time stamp (event_timestamps) through the Watermark Client API (currently configured 1000ms) to Watermark Server.
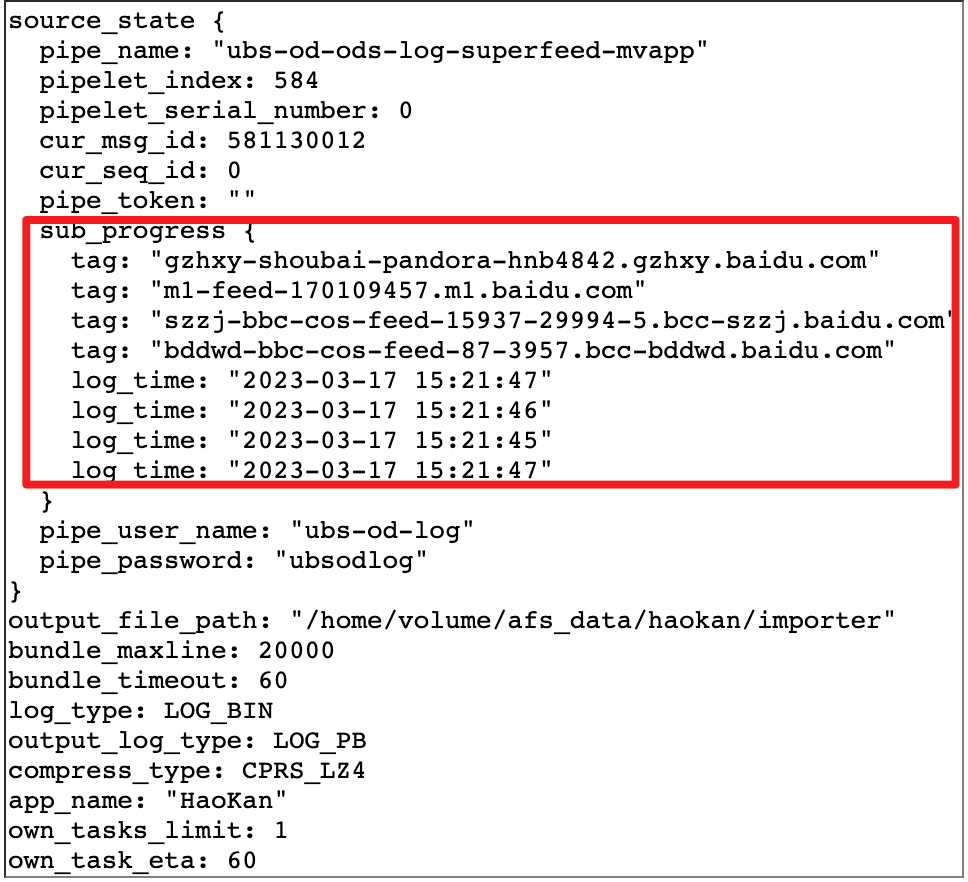
△Source The server and log progress mapping relationship obtained by parsing the log
Operator side :
Input low Watermark calculation: Obtain the output low watermark of the upstream (Upstream) as the input low watermark to determine whether to trigger window calculation and other operations;
Output low Watermark Calculation: Calculate your own output low watermark based on the log, status (state) and other processing progress (oldest work), and report it to the Watermark Server for use by downstream operators (Download Processor).
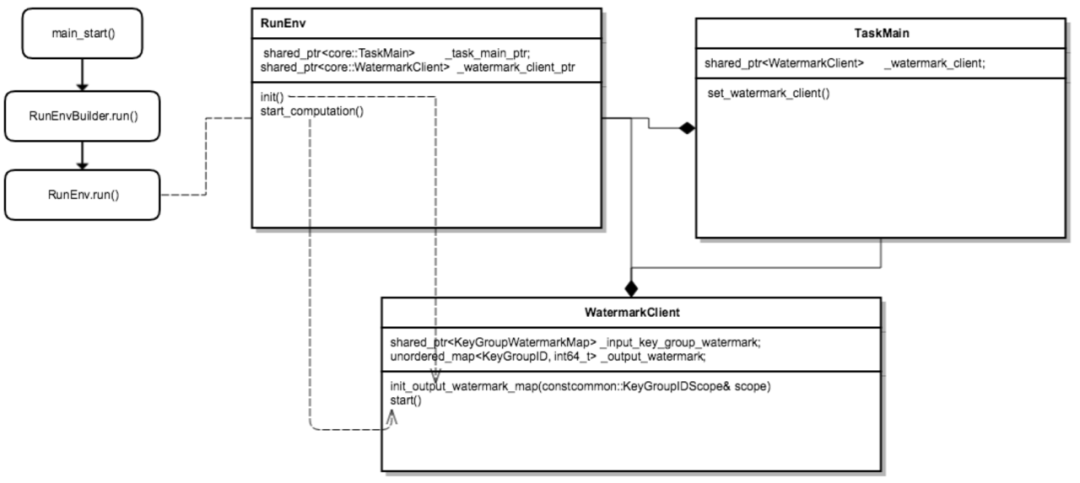
△Watermark Client workflow
Sinker side :
The sinker side is the same as the above ordinary real-time operator (Operator), it will calculate the Input Low Watermark and Output Low Watermark to update its own water level,
In addition, a global Low Watermark needs to be requested to determine whether the data output window is closed.
4.3 Transmission of accurate water level between systems
The necessity of water level transfer
In many cases, real-time systems are not isolated, and there is data interaction between multiple real-time computing systems. The most common way is that two real-time data processing systems are upstream and downstream.
The specific performance is: two real-time data processing systems implement data transfer through message queues (such as Apache Kafka in the community), so in this case, how to achieve accurate water level transfer?
The specific implementation steps are as follows :
1. The log source of the upstream real-time computing system ensures that the log is released point-to-point, which can ensure the accuracy of the global water level (the specific ratio is adjustable);
2. At the output end of the upstream real-time computing system (sinker/exporter to the message queue end), it is necessary to ensure that the global low watermark is issued. Currently, we use the global water level information to be printed on each log to achieve delivery;
3. At the source end of the downstream real-time data calculation system, it is necessary to analyze the water level information field carried by the log (from the upstream real-time calculation system), and start to use it as the input of the water level (Input Low Watermark), and start the iterative calculation of the layer-by-layer water level and the global water level calculation;
4. On the Operator/Sinker end of the downstream real-time data computing system, the event time of the log can still be used to achieve specific data segmentation as the input of window calculation, but the mechanism for triggering window calculation is still based on the global data returned by Watermark Server Low Watermark shall prevail to ensure data integrity.
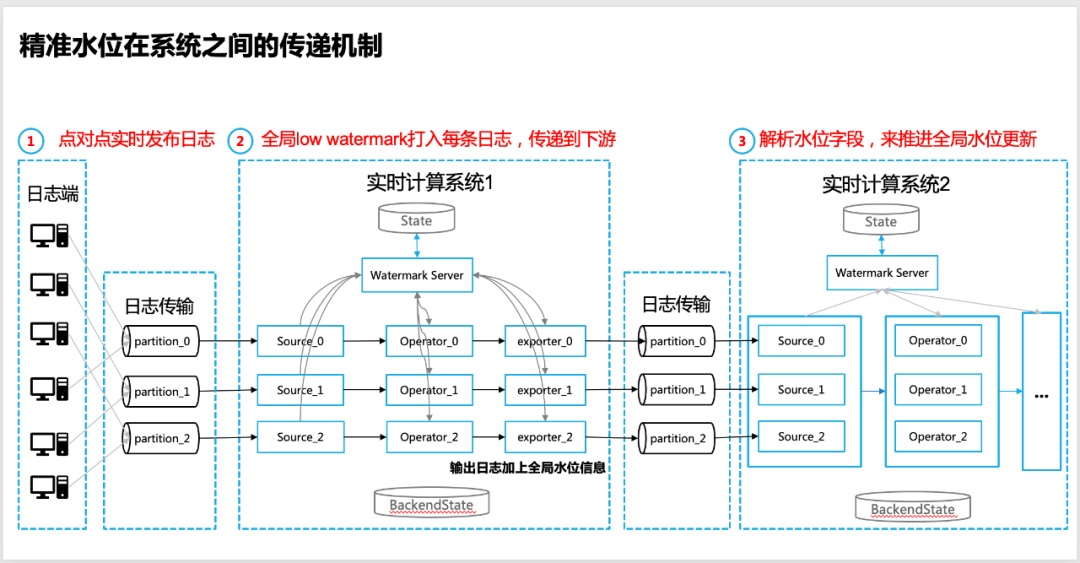
△Transfer mechanism of precise water level between real-time computing systems
05 Actual effects and follow-up prospects
5.1 Actual online effect
5.1.1 The measured effect (completeness) of landing data
The actual online test adopts accurate water level (configured water level accuracy is 99.9%, that is, only one-thousandth of the source instance delay is allowed), and when there is no delay in the log, the real-time landing data and offline data are in the same time window (Event Time) The effect comparison is as follows (basically all below 100,000 points):

△The effect of data integrity when the source log is not delayed
When the source log is delayed (<=0.1% of the source log instance is delayed, the water level will continue to be updated), the overall data diff effect is basically about 1/1,000 (subject to the possibility of the log source point-to-point log itself Influence of data inhomogeneity):

In the case of a large area of delay in the source log (>0.1% of the source log instance delay), due to the use of an accurate water level mechanism (water level accuracy 99.9%), the global water level will not be updated, and real-time data will be written to AFS The window will not be closed, and the window will be closed only after waiting for the arrival of delayed data and the update of the global water level to ensure the integrity of the data. The actual test results are as follows (between 1.1-1.2 per thousand, subject to the log source The instance itself has the effect of unevenness):
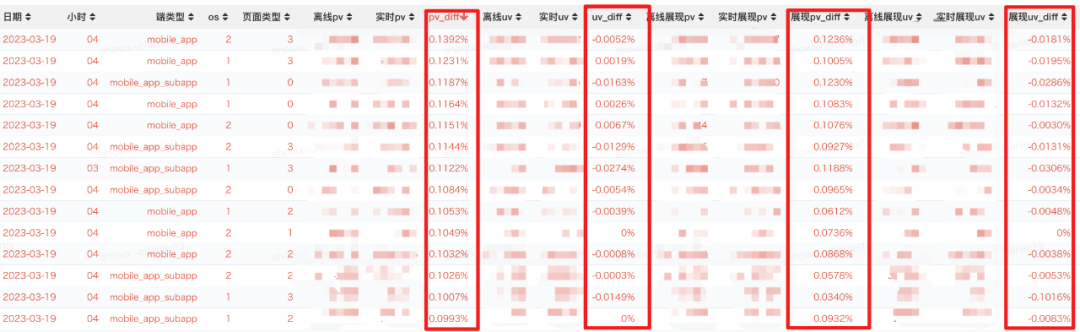
5.2 Summary and Presentation
After research on the actual precise water level and actual online application, the real-time data warehouse based on the precise water level not only improves the timeliness, but also has a higher and flexible data precision mechanism. After the stability optimization, it is actually completely Instead of the previous offline and real-time data warehouse systems, a truly stream-batch integrated data warehouse is realized.
At the same time, based on the centralized water level mechanism, it will also face the challenges of performance optimization, high availability (improvement of fault recovery mechanism), and finer granularity and precise water level (under the window calculation trigger mechanism).
——END——
references:
[1] T. Akidau, A. Balikov, K. Bekiroğlu, S. Chernyak, J. Haberman, R. Lax, S. McVeety, D. Mills, P. Nordstrom, and S. Whittle. Millwheel: Fault-tolerant stream processing at internet scale. Proc. VLDB Endow., 6(11):1033–1044, Aug. 2013.
[2] T. Akidau, R. Bradshaw, C. Chambers, S. Chernyak, R. J. Fernández-Moctezuma, R. Lax, S. McVeety, D. Mills, F. Perry, E. Schmidt, et al. The dataflow model: a practical approach to balancing correctness, latency, and cost in massive-scale, unbounded, out-of-order data processing. Proceedings of the VLDB Endowment, 8(12):1792–1803, 2015.
[3] T. Akidau, S. Chernyak, and R. Lax. Streaming Systems. O’Reilly Media, Inc., 1st edition, 2018.
[4] "Watermarks - Measuring Time and Progress in Streaming Pipelines", Slava Chernyak , Google Inc
[5] P. Carbone, A. Katsifodimos, S. Ewen, V. Markl, S. Haridi, and K. Tzoumas. Apache flink: Stream and batch processing in a single engine. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, 36(4), 2015.
Recommended reading:
Text Template Technical Solution in Video Editing Scenario
Talking about the application of graph algorithm in the activity scene in anti-cheating
Serverless: Flexible Scaling Practice Based on Personalized Service Portraits
Action decomposition method in image animation application
Performance Platform Data Acceleration Road
Editing AIGC Video Production Process Arrangement Practice