Author|Li Ang, senior data R&D engineer of an industrial and commercial information business query platform
The information service industry can provide diversified, convenient, efficient and secure information services, providing important support and reference for personal and business decision-making. For industry-related companies, the importance of data collection, processing, and analysis capabilities is self-evident. Taking an industrial and commercial information business inquiry platform as an example, it faces the challenge of constantly changing corporate public information, such as changes in registered capital, changes in equity structure, transfers of debts and claims, changes in foreign investments, etc. Changes in these information require the platform to be updated in a timely manner. However, in the face of huge and frequent data changes, how to ensure the accuracy and real-time nature of data has become a difficult task. In addition, as the amount of data continues to increase, how to process and analyze this data quickly and efficiently has become another problem that needs to be solved.
In order to cope with the above challenges, the commercial query platform began to build a data analysis platform in 2020, and successfully realized the evolution from the traditional Lambda architecture to the integrated lake and warehouse architecture based on Doris Multi-Catalog. This innovative architectural change enables the platform to unify the data entry and query exit of offline and real-time data warehouses, meet business needs such as BI analysis, offline computing, and C-end high concurrency, and provide services for internal enterprises, product marketing, Scenarios such as customer operations provide powerful data insight and value mining capabilities.
Architecture 1.0: Traditional Lambda Architecture
When the business query platform was first established, it was mainly dedicated to the two business lines of ToC and ToB. The ToC business line mainly provides personalized and precise services for C-side users; while the ToB business line focuses on providing data interface services and delivery services for B-side customers. It also handles some internal data analysis needs of the company and is data-driven. Enterprises optimize their business.
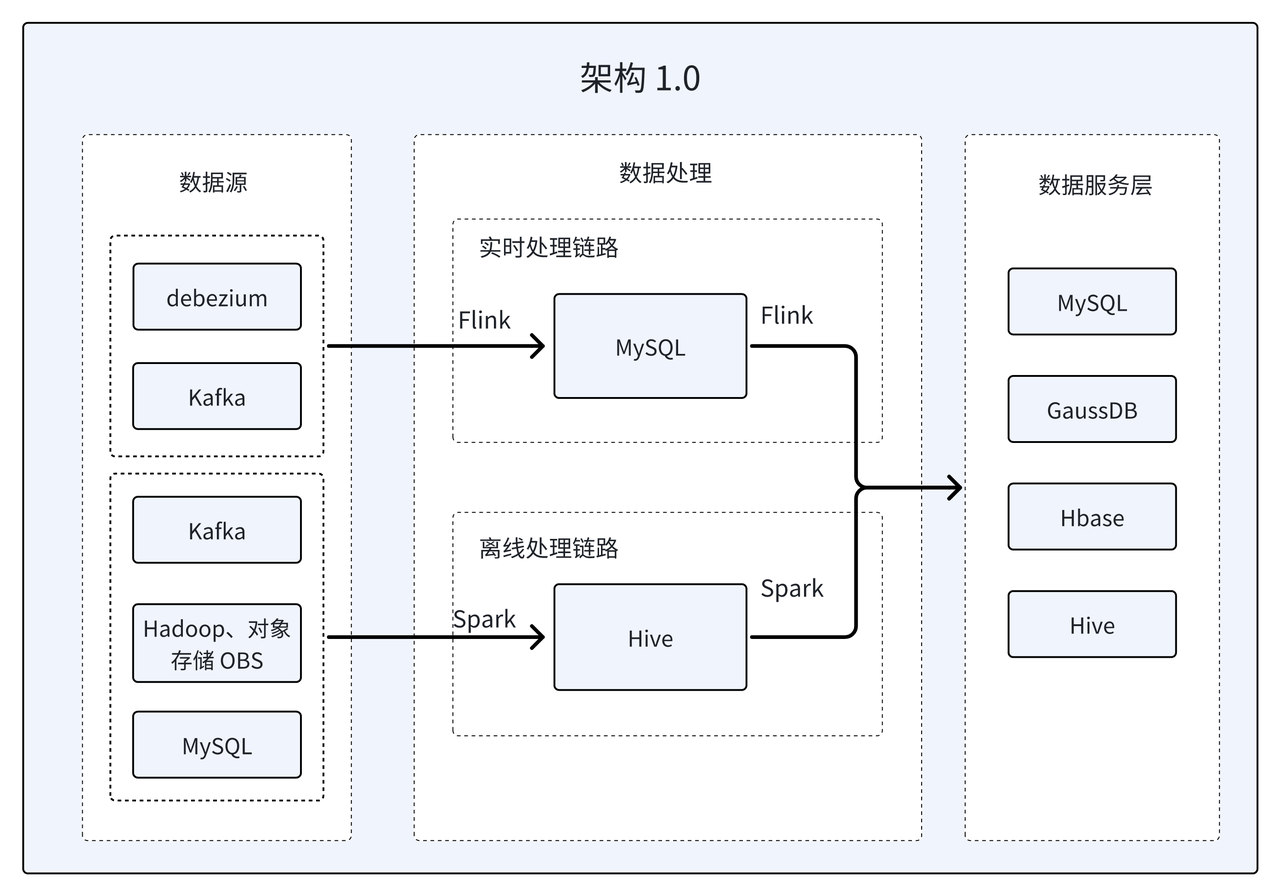
In the early days, the traditional Lambda architecture was adopted, which was divided into two sets of offline and real-time processing processes. The real-time architecture serves the ToC business line that has higher data timeliness requirements, while the offline architecture focuses on existing data repair and ToB data delivery services at T+7 and T+15. The advantage of this architecture is that project development can be flexibly segmented and tested, and it can quickly respond to changes in business needs. However, there are obvious deficiencies in data development, operation and maintenance management, etc.:
- Logic redundancy: The same business solution requires the development of two sets of offline and real-time logic, and the code reuse rate is very low, which increases the cost of demand iteration and the development cycle. In addition, the difficulty and complexity of task handover, project management, and architecture operation and maintenance are also relatively high, which brings great challenges to the development team.
- Data Inconsistency: In the current architecture, when there are multiple links to the application layer data source, data inconsistency is very easy to occur. These problems not only increase the time for data troubleshooting, but also have a negative impact on the accuracy and reliability of the data.
- Data silos: In this architecture, data is stored dispersedly in different components. For example: ordinary business query tables are stored in MySQL, which mainly supports high-concurrency query operations on the C side; for data like DimCount that involves frequent changes in wide tables, choose HBase's KV storage method; for annual dimensions with a single table data volume exceeding 6 billion The table query is implemented with the help of GaussDB database. Although this method can meet data needs individually, it involves many components and the data is difficult to reuse, which can easily create data islands and limit the in-depth mining and utilization of data.
In addition, as the commercial query platform business continues to expand, new business needs continue to emerge, such as the need to support minute-level flexible crowd selection and coupon issuance calculations, order analysis, push information analysis and other new data analysis need. In order to meet these needs, the platform began to look for a powerful engine that can integrate data integration, query, and analysis to achieve true All In One.
OLAP engine research
During the selection and research phase, the platform conducted an in-depth investigation of three databases: Apache Doris, ClickHouse, and Greenplum. Combining early architectural pain points and new business needs, the new engine needs to have the following capabilities:
- Standard SQL support: functions can be written using SQL, with low learning and usage costs;
- Multi-table joint query capability: supports real-time intersection and difference operations of crowd packets, and supports flexible configuration of crowd packet selection;
- Real-time Upsert capability: Supports the Upsert operation of pushing log data, and the amount of data that needs to be updated every day is up to 600 million pieces;
- Operation and maintenance difficulty: simple architecture, lightweight deployment and operation and maintenance.
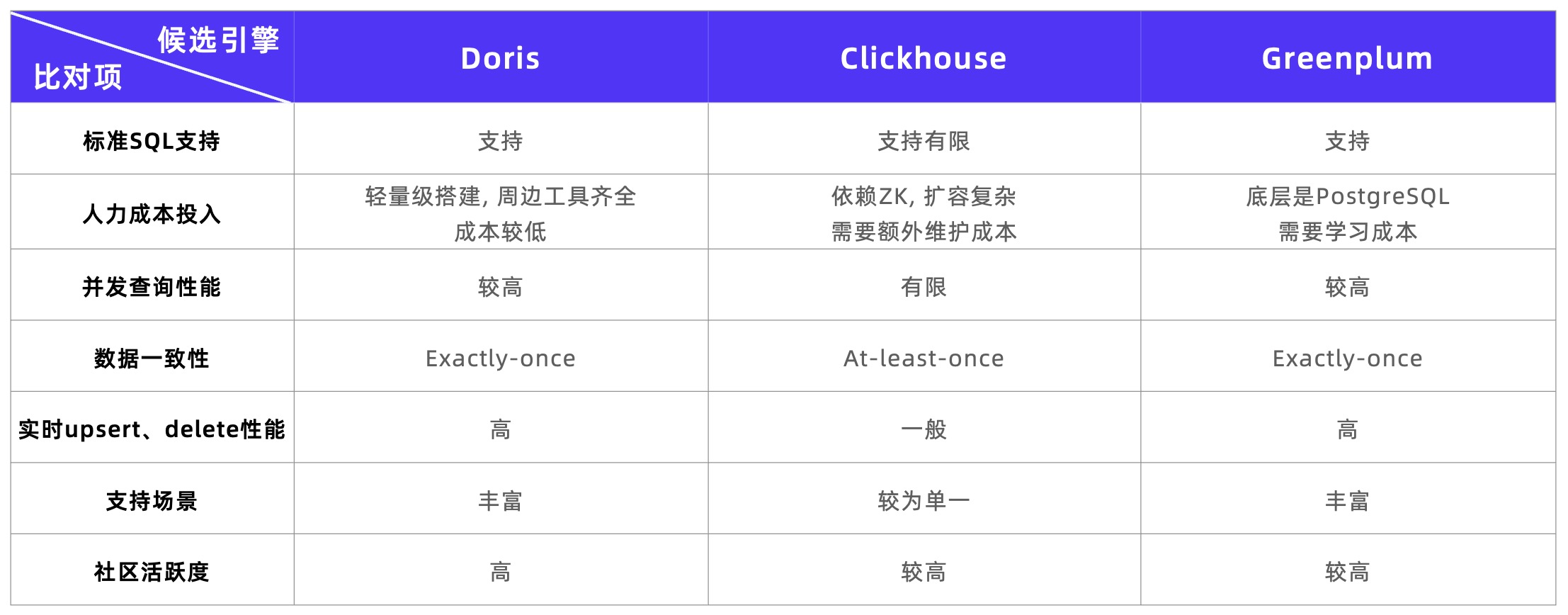
According to the survey results, it can be found that Apache Doris has obvious advantages and meets the platform selection goals:
- Multiple Join logic: Through Colocation Join, Bucket Shuffle Join, Runtime Filter and other Join optimization methods, efficient multi-table joint OLAP analysis can be performed based on the Snowflake model.
- High-throughput Upsert writing: The Unique Key model adopts the Merge-on-Write merge mode, supports real-time high-throughput Upsert writing, and can guarantee Exactly-Once writing semantics.
- Support Bitmap: Doris provides a rich Bitmap function system, which can easily filter out the intersection and union of IDs that meet the conditions, which can effectively improve the efficiency of crowd selection.
- Extremely easy to use: Doris meets lightweight deployment requirements and has only two processes, FE and BE, which makes horizontal expansion simple, reduces the risk of version upgrades, and is more conducive to maintenance. In addition, Doris is fully compatible with standard SQL syntax and provides more comprehensive support for data types, functions, etc.
Architecture 2.0: Data Services Layer All in Apache Doris
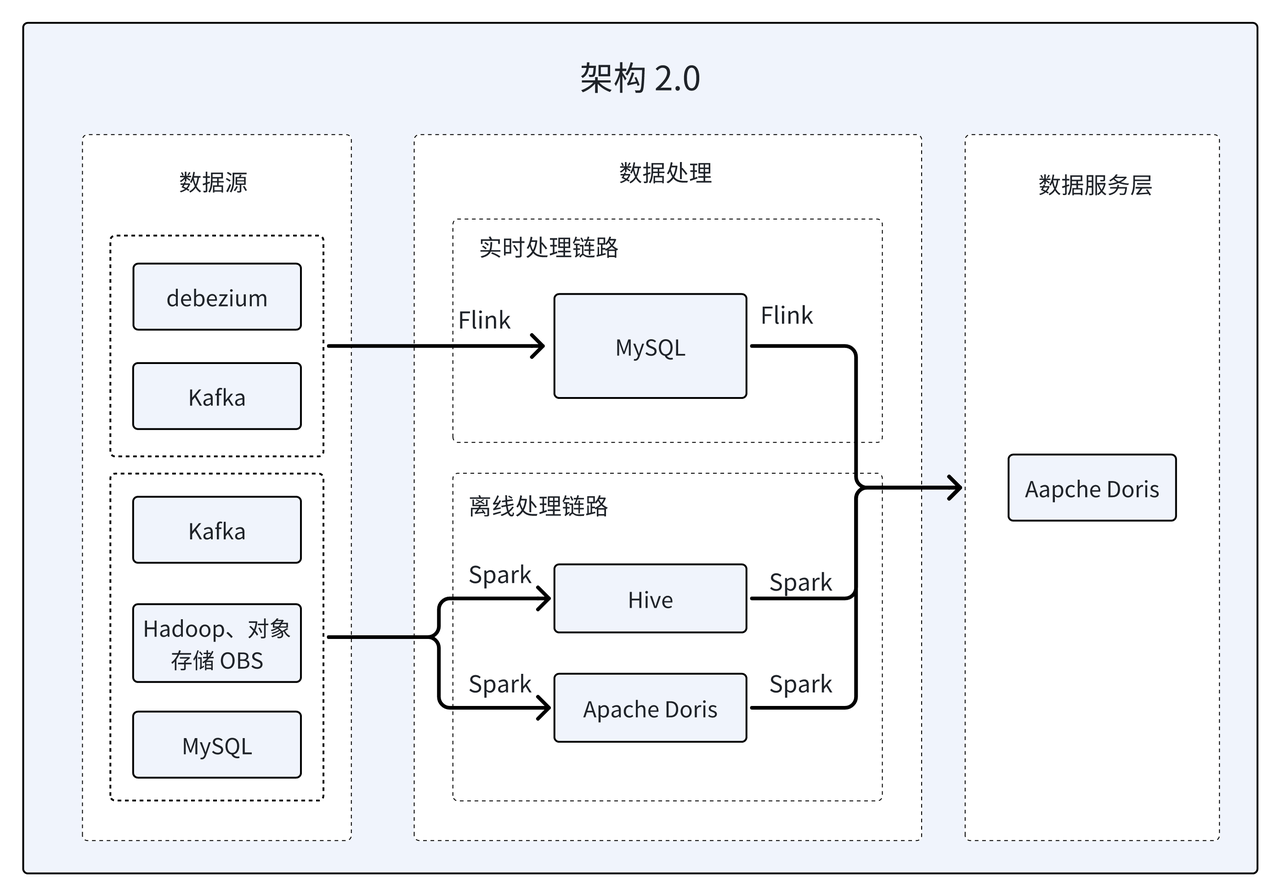
This business query platform has an upgraded data architecture based on Apache Doris. First, Apache Doris was used to replace Hive in the offline processing link. Secondly, through the trial and practice of features such as Light Schema Change and Unique Key write-time merging, Doris alone replaced the three databases of GaussDB, HBase, and Hive in the early architecture. , breaking the data island and realizing the data service layer All in Doris.
- Introducing the Unique Key merge-on-write mechanism: In order to meet the query requirements of large tables under normal C-side concurrency, by setting up multiple copies and adopting the Unique Key merge-on-write mechanism, Ensure the real-time and consistency of data. Based on this mechanism, Doris successfully replaced GaussDB and provided more efficient and stable services.
- Introduction of Light Schema Change mechanism: This mechanism enables the completion of new operations on DimCount table fields within seconds, improving the efficiency of data processing. Based on this mechanism, Doris successfully replaced HBase and achieved faster and more flexible data processing.
- Introduction of PartialUpdate mechanism: Accelerate the development of two-table association through Aggregate model
REPLACE_IF_NOT_NULL. This improvement makes multi-table cascade development more efficient .
After Apache Doris went online, its business coverage expanded rapidly and remarkable results were achieved in a short period of time:
- In March 2023, after Apache Doris was officially launched, it ran two clusters with more than ten BEs. These two clusters were responsible for the commercial analysis of the digital team and the optimization of the data platform department architecture, and jointly supported large-scale The important task of data processing and analysis,supports up to 1 billion pieces of data every day and 500+ calculation indicators, supporting crowd package selection, coupon push, recharge order analysis, data delivery and other needs< /span>.
- In May 2023, with the help of Apache Doris, the streaming overwrite of the ETL tasks of the commercial analysis cluster of several teams was completed. Nearly half of the offline scheduled scheduling tasks were migrated to Doris, which improved the stability and timeliness of offline computing tasks. At the same time, most of the Most real-time tasks have also been migrated to Apache Doris, and the overall cluster size has reached more than 20 units.
Although All in One of the data service layer is implemented in Architecture 2.0, and Doris is introduced to accelerate offline computing tasks, the offline link and the real-time link are still separated, and they still face the problems of duplicate processing logic and inconsistent data. Secondly, although the introduction of Doris enables real-time updates and instant queries of large batches of data, migrating offline tasks with low timeliness requirements to the Doris cluster may have a certain impact on the cluster load and stability of online businesses. Therefore, the platform plans to undergo further upgrades.
Architecture 3.0: Integrated lake and warehouse architecture based on Doris Multi-Catalog
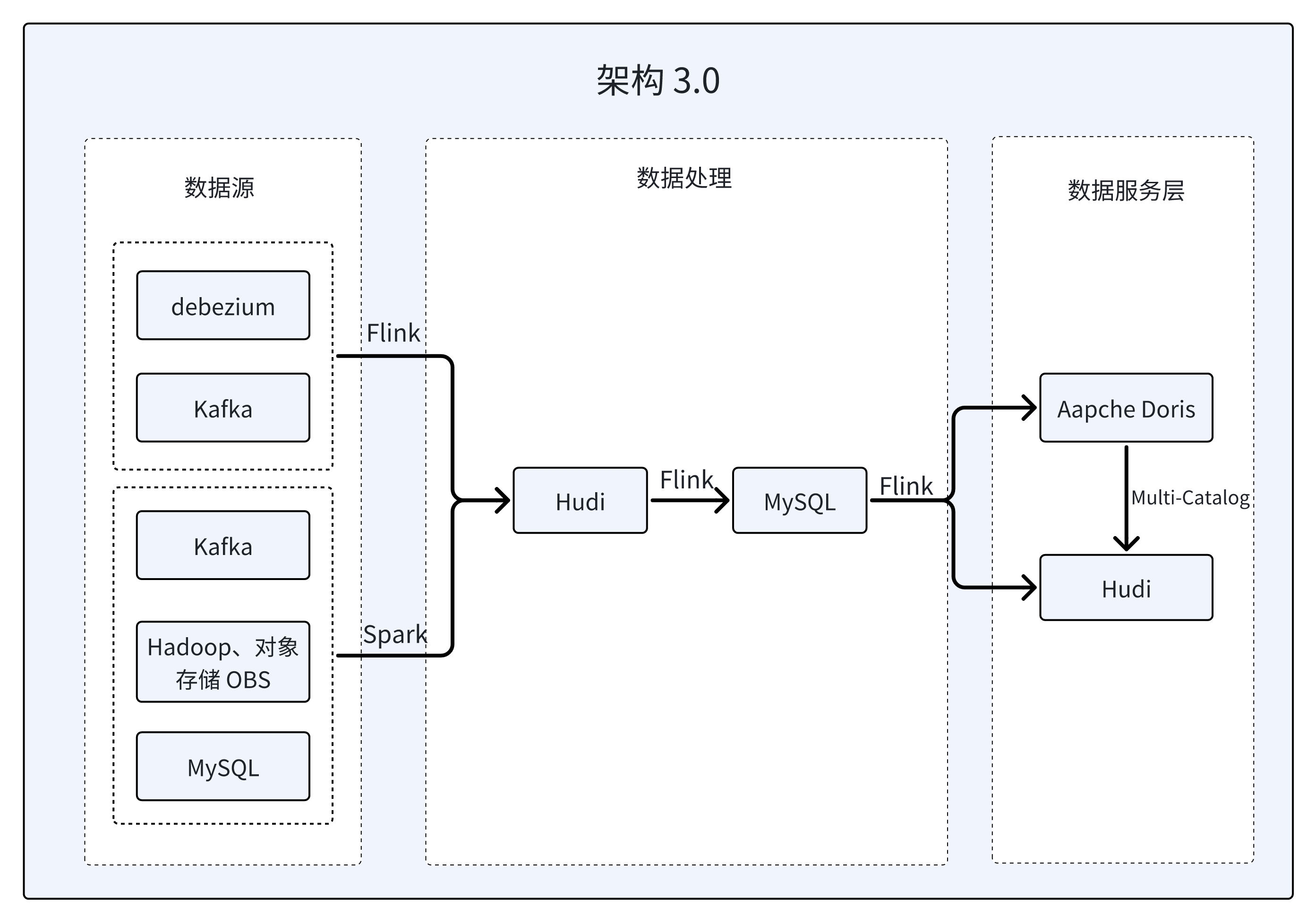
Taking into account the data lake analysis capabilities of Doris multi-source Catalog, the platform decided to introduce Hudi as the data update layer in the architecture, so that Doris can be used as a unified data query entry to query Hudi's Read Optimized table, and adopt streaming and batch integration. The data is written to Hudi in this way, which realizes the evolution from Lambda architecture to Kappa architecture and completes the upgrade of architecture 3.0.
- Taking advantage of Hudi's natural support for CDC, Hudi is used as Queryable Kafka at the ODS layer to achieve data access at the source layer.
- Using MySQL as Queryable State for hierarchical processing, the final results will first be written to MySQL and then synchronized to Hudi or Doris according to the data usage.
- For the entry of existing data, the entire data can be extracted to Hudi exactly once through a customized Flink Source, and it also supports predicate pushdown and state recovery.
According to the importance of different businesses, data will be stored in Doris and Hudi respectively to meet business needs and performance requirements to the greatest extent:
- For online businesses such as crowd selection, push analysis, and C-side analysis, data will be stored in Doris, which can fully utilize the high-performance features of Doris to respond to high-concurrency online queries, while improving overall operational efficiency and customer satisfaction. degree to ensure fast processing and efficient access to critical data.
- Data for other off-line businesses is stored in Hudi and federated through Doris’ Hudi Catalog. The separation of storage and computing can reduce Tablet maintenance overhead and improve cluster stability. At the same time, this architecture can also reduce writing pressure, improve node IO and CPU utilization during computing, and achieve more efficient data processing and analysis.
In Architecture 3.0, the query platform embeds relatively heavy offline calculations into the data lake, allowing Doris to focus on application layer calculations, which can not only effectively ensure the architectural integration and unification of the lake and warehouse, but also Give full play to the respective capabilities and advantages of Hu and Cang. The evolution of this architecture has also promoted the further expansion of the cluster scale. Up to now, Doris has dozens of machines in this query platform, with more than 200 dimensions for data exploration and indicator calculation. The total size of indicators also exceeds 1,200.
Experience
The core challenges faced by an industrial and commercial information business query platform in the C-side query business are as follows:
- High-concurrency query for ultra-large-scale detailed tables: There are over 6 billion ultra-large-scale detailed tables in the platform, and it is necessary to provide high-concurrency query capabilities for these detailed tables.
- Multi-dimensional in-depth analysis: The data analysis team hopes to conduct multi-dimensional analysis of C-side data and dig into more hidden dimensions and data penetration relationships. This requires powerful data processing and flexible data analysis capabilities to extract useful information from large amounts of data. value information.
- Customized real-time dashboard: I hope to customize some fixed template SQL into a real-time dashboard and meet the requirements of concurrent queries and minute-level data freshness. At the same time, we hope to embed the real-time data dashboard into the C-side page to enhance the functionality and convenience of the C-side.
In order to cope with the challenges posed by the C-side, the platform takes advantage of multiple features of Apache Doris.It achieves a 127% increase in single-point query speed and batch/full data conditional query speed. It has been significantly improved by 193% and development efficiency by 100%. In addition, the concurrency capability for the C-side has been significantly enhanced. It can now easily carry online concurrency of up to 3000 QPS.
01 Introducing Merge-on-Write, which speeds up tens of billions of single-table queries by nearly three times
In order to solve the high-concurrency query problem on the C-side for annual report-related tables (with a data volume of 6 billion) and achieve the goal of cost reduction and efficiency improvement, the platform enabled Doris's Unique Key Merge-on-Write merge-on-write function.
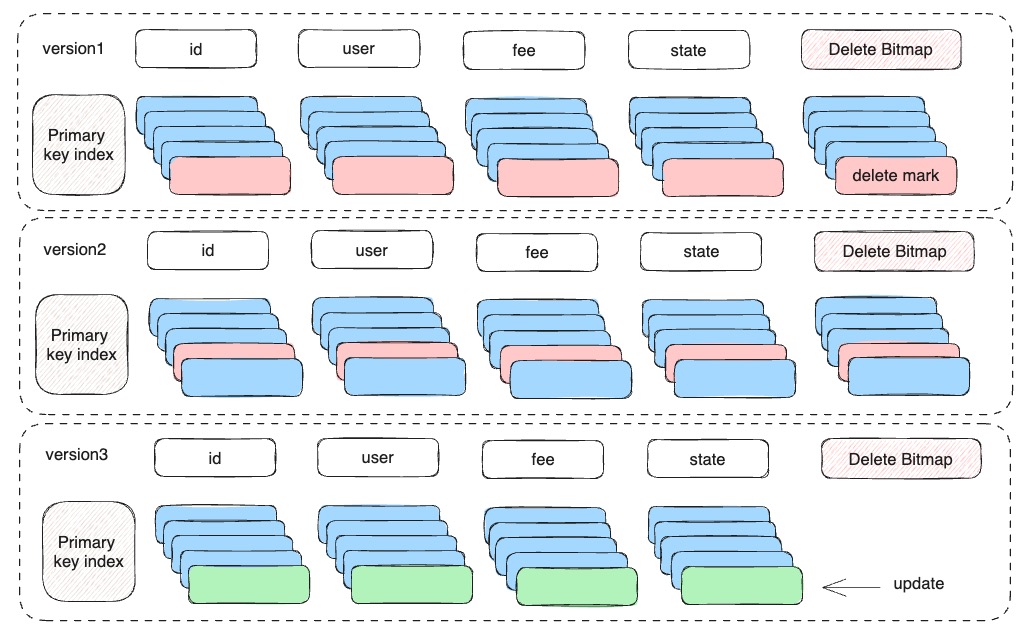
Merge-on-Write is a new feature introduced by Apache Doris in version 1.2.0. It transfers the deduplication of data in the Unique Key table by primary key from the query phase to the write phase, so it can be obtained with Duplicate during query Key table has comparable performance.
Specifically, merging on write can avoid unnecessary multi-way merge sorting, and always ensure that the valid primary key only appears in one file (that is, the uniqueness of the primary key is guaranteed when writing), without the need for reading. At this time, the primary keys are deduplicated through merge sorting, which greatly reduces the consumption of CPU computing resources. At the same time, it also supports predicate pushdown. Doris' rich index can be used to fully trim the data at the data IO level, greatly reducing the amount of data reading and calculation. Therefore, there is a significant performance improvement in queries in many scenarios.
Due to the increased cost of deduplication in the writing process, the import speed of merge-on-write will be affected to a certain extent. In order to minimize the impact of merge-on-write on import performance, Doris uses the following technology to optimize the performance of data deduplication. Therefore, in real-time update scenarios, the cost of deduplication can be made invisible to users.
- Each file generates a primary key index, which is used to quickly locate the location of duplicate data.
- Each file maintains a min/max key interval and generates an interval tree. When querying duplicate data, you can quickly determine which file a given key may exist in, reducing search costs.
- Each file maintains a BloomFilter. When the Bloom Filter is hit, the primary key index will be queried.
- Use multi-version DeleteBitmap to mark the deleted line number of the file
Unique Key The use of write-time merge is relatively simple. You only need to enable it in the Properties of the table. Here, we take the company_base_info table as an example. The data volume of a single table is about 300 million rows and the data size of a single row is about 0.8KB. It takes about 5 minutes to write the entire data in a single table. After turning on Merge-on-Write, the time it takes to execute a query is reduced from the previous 0.45 seconds to 0.22 s, and the time it takes to perform a conditional query on batch or full data is reduced from 6.5 seconds to 2.3 seconds. The average performance improvement is nearly 3 times.
Through this technical means, high-performance single-point query is achieved, which greatly improves query efficiency and response speed, while reducing query costs. This optimization measure not only meets users' high requirements for data query, but also provides a strong guarantee for the stability and sustainable development of the platform.
02 Some column data are updated, and the data development efficiency is increased by 100%.
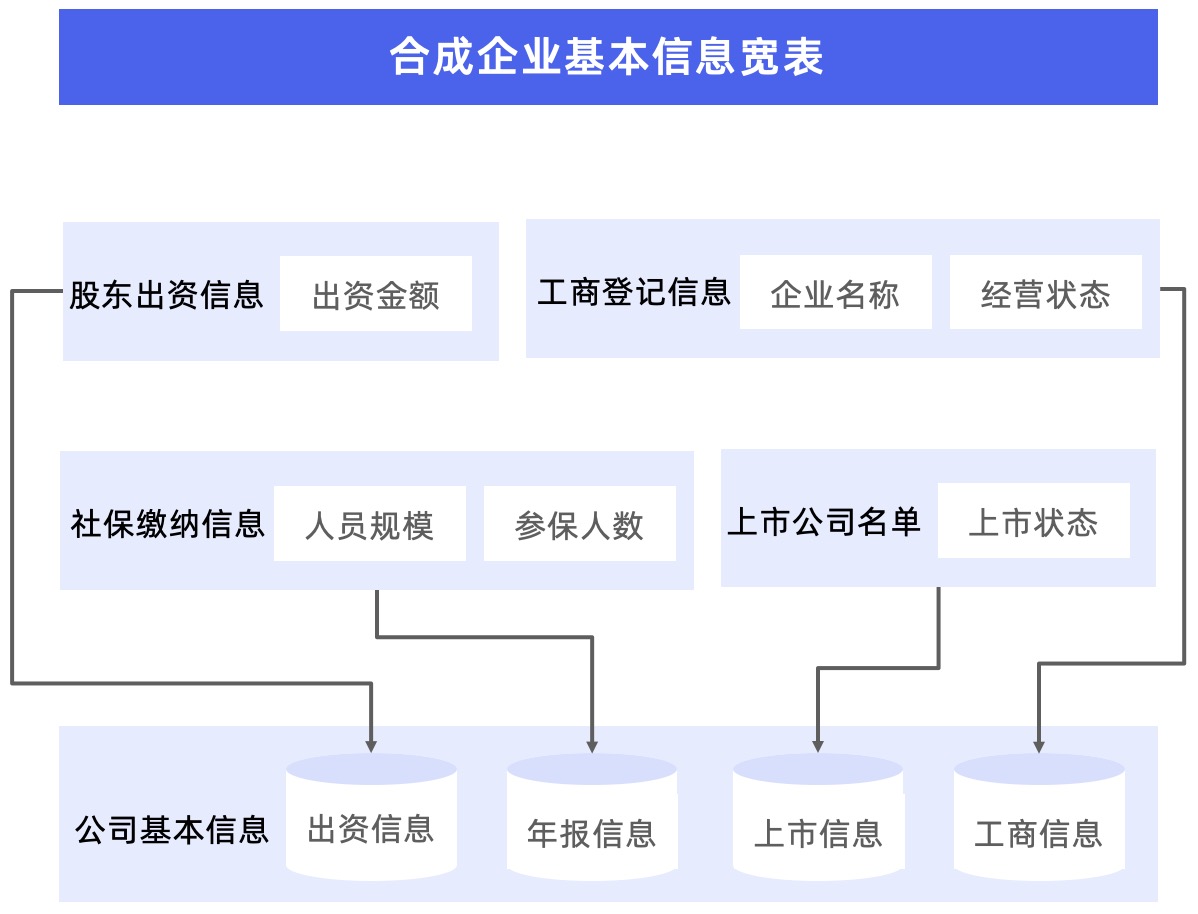
In the business scenario of this commercial query platform, there is a large table containing various dimensions of the enterprise, and the platform requires that data changes in any dimension be reflected in the landing table. In previous development, it was necessary to develop a set of logic similar to Lookup Join for each dimension to ensure that changes in each dimension can be updated in time.
However, this approach also brings some problems. For example, every time a new dimension is added, the logic of other dimensions also needs to be adjusted, which increases the complexity and workload of development and maintenance. Secondly, in order to maintain the flexibility of going online, the platform did not merge all dimensions into one table, but split 3-5 dimensions into an independent table. This This splitting method also makes subsequent use extremely inconvenient.
@RequiredArgsConstructor
private static class Sink implements ForeachPartitionFunction<Row> {
private final static Set<String> DIMENSION_KEYS = new HashSet<String>() {
{
add("...");
}};
private final Config config;
@Override
public void call(Iterator<Row> rowIterator) {
ConfigUtils.setConfig(config);
DorisTemplate dorisTemplate = new DorisTemplate("dorisSink");
dorisTemplate.enableCache();
// config `delete_on` and `seq_col` if is unique
DorisSchema dorisSchema = DorisSchema.builder()
.database("ads")
.tableName("ads_user_tag_commercial").build();
while (rowIterator.hasNext()) {
String json = rowIterator.next().json();
Map<String, Object> columnMap = JsonUtils.parseJsonObj(json);
// filter needed dimension columns
Map<String, Object> sinkMap = columnMap.entrySet().stream()
.filter(entry -> DIMENSION_KEYS.contains(entry.getKey()))
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
dorisTemplate.update(new DorisOneRow(dorisSchema, sinkMap));
}
dorisTemplate.flush();
}
}
To solve this problem, the platform uses a custom DorisTemplate (which internally encapsulates Stream Load) to process existing data. The core idea is to refer to the implementation of Kafka Producer, use Map to cache data, and set up a dedicated Sender thread to send data regularly based on time intervals, number of data pieces, or data size.
Write the required columns into Doris' enterprise information dimension tables by filtering them out from the source. At the same time, for the join scenario of two tables, we choose to use REPLACE_IF_NOT_NULL of the Agg model for optimization, making the update work of some columns more efficient.
This improvement has brought 100% efficiency improvement to the development work. Taking a single table and three dimensions as an example, it used to take 1 day to develop, but now it only takes 0.5 sky. This change improves development efficiency, allowing it to process data and meet business needs more quickly.
It is worth mentioning that Apache Doris implemented some column updates of the Unique Key primary key model in version 2.0.0. When multiple upstream source tables are written to a wide table at the same time, there is no need for Flink to perform multi-stream Join widening and write directly. Just enter the wide table, which reduces the consumption of computing resources and greatly reduces the complexity of the data processing link.
03 Enrich the optimization methods of Join, and the overall query speed is increased by nearly four times.

In the business scenario of this platform, more than 90% of the tables contain the field of entity ID, so a Colocation Group is constructed for this field so that the execution plan can hit Colocation Join during query, thereby avoiding data shuffle bring computational overhead. Compared with ordinary Shuffle Join, the execution speed is increased by 253%, greatly improving query efficiency.
For some secondary dimensions under the first-level dimension, since only the primary key ID of the first-level dimension is stored and there is no entity ID field, if traditional Shuffle Join is used for query, both tables A and B are required Participate in Shuffle operations. In order to solve this problem, the platform has optimized the query syntax so that the query can hit Bucket Shuffle Join, thereby reducing the amount of shuffle by more than 50% and increasing the overall query speed by at least 77% a>.
04 Light Schema Change, online QPS up to 3000+
In order to improve C-side concurrency, the platform maintains a count value for each dimension of each entity. Before back-end students query data, they will first query the count value. Only when the count value is greater than 0, will they continue to obtain detailed data. In order to adapt to the iterative needs of continuously expanding dimensions, we chose an HBase cluster with SSD storage and used its KV storage feature to maintain this set of count values.
Doris Light Schema Change can also achieve second-level field increases when facing 500 million data volumes. Therefore, the platform migrated the DimCount program from writing HBase to writing Doris in Architecture 3.0. With the combined help of multiple copies and write-time merging, can easily handle up to 3000 online concurrency.
When new dimensions that need to be calculated are introduced, the processing flow is as follows:
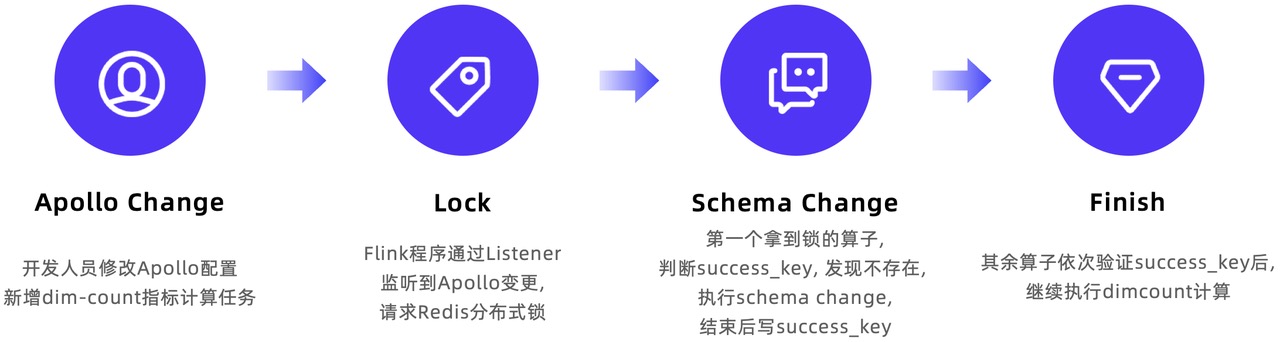
- Enter its KafkaTopic, query SQL and other information into the Apollo configuration platform
- The Flink program detects new indicators through Apollo's Listener and requests the Redis distributed lock.
- Query the dimension
success_keyto determine whether initialization has been completed - Complete initialization through
alter tablestatement and setsuccess_key - Other subtasks perform steps 2-4 in sequence.
- The program continues execution and the new count value can be written
05 Optimize the real-time Join scenario and reduce development costs by 70%
The pain point of real-time wide table Join is the foreign key association of multiple tables, for example:select * from A join B on A.b_id=B.id join C on B.c_id = C.id When building a real-time model, tables A, B, and C may each undergo real-time changes. To make the result table respond in real time to changes in each table, there are two implementation methods under the Flink framework:
- There are three tables A, B, and C. Each table develops a set of Lookup Join logic that associates the other two tables.
- Set the TTL of State storage in Flink to a longer time, such as 3 days. This ensures that data changes within 3 days can be sensed and processed in real time. At the same time, through daily offline calculation, it can be ensured that updates 3 days ago can be processed and reflected in the data within T+1 time.
The above is not the optimal way, and there are still some problems: - As the number of subtables required for a wide table grows, the additional development cost and maintenance burden also rise linearly.
- The setting of TTL time is a double-edged sword. Setting it too long will increase the additional overhead of Flink engine state storage, while setting it too short may cause more data to only enjoy T+1 data freshness.
In the previous business scenario, the platform considered combining Option 1 with Option 2 and made appropriate compromises. Specifically, only the logic of A join B join C is developed, and the output data is first stored in MySQL. Whenever data changes occur in tables B and C, all changed table A IDs are obtained through the JDBC query result table, and the calculation is recalculated accordingly.
However, after the introduction of Doris, through technologies such as write-time merging, predicate pushdown, hit index, and high-performance Join strategy, the platform is provided with an on-site correlation method at query time, which not only reduces the The complexity of development is still in the scenario of three-table association. The workload was reduced from the original 3 man-days to only 1 man-day, and the development efficiency was greatly improved .
Optimization experience
In the process of production practice, the platform also encountered some problems, including excessive file versions, transaction squeeze, FE suspended animation and other error reports. However, through parameter adjustment and program debugging, these problems were finally solved. The following is a summary of optimization experience.
01 E-235 (Too many file versions)
When scheduling Broker Load in the early morning, due to congestion of scheduling system tasks, multiple tasks may be concurrently executed at the same time, causing a sharp increase in BE traffic, causing IO jitter and the problem of too many file versions (E-235). Therefore, the following optimizations have been made. Through these changes, the E-235 problem no longer occurs:
- Use Stream Load instead of Broker Load to distribute BE traffic throughout the day.
- Custom writers package Stream Load to achieve asynchronous caching, current limiting and peak shaving, etc., fully ensuring the stability of data writing.
- Optimize system configuration, adjust Compaction and write Tablet version related parameters:
- max_base_compaction_threads : 4->8
- max_cumu_compaction_threads : 10->16
- compaction_task_num_per_disk : 2->4->8
- max_tablet_version_num : 500->1024
02 E-233 (transaction squeeze)
During the in-depth use of Doris, I found that when multiple Stream Loads are written to the database at the same time, if the upstream performs multi-table data cleaning and the speed limit is difficult to control, a large QPS problem may occur, which will trigger the E-233 error. . In order to solve this problem, the platform made the following adjustments. After the adjustments, when facing real-time writing of 300+ tables, the E-233 problem no longer reappears:
- Divide the tables in the DB into more detailed databases to achieve transaction amortization for each DB
- Parameter adjustment: max_running_txn_num_per_db : 100->1000->2048
03 FE fake death
Through Grafana monitoring, it was found that FE often experienced downtime. The main reason was that in the early days, the platform adopted a mixed deployment of FE and BE. When BE performed network IO transmission, it may occupy the IO and memory of FE on the same machine. Secondly, because the Prometheus of the operation and maintenance team is connected to many services, its stability and robustness are insufficient, resulting in false alarms. The following adjustments have been made to address these issues:
- The current memory of the BE machine is 128G. Use a 32G machine to migrate the FE node.
- During the Stream Load process, Doris will select a BE node as the Coordinator node to receive data and distribute it to other BE nodes, and return the final import result to the user. Users can submit import commands to FE through HTTP protocol or directly specify BE nodes. The platform uses the method of directly specifying BE to achieve load balancing and reduce FE's participation in Stream Load to reduce FE pressure.
- Scheduling
show processlistcommand to detect activity, and at the same time kill timeout SQL or timeout connection in a timely manner.
Conclusion
So far, the data platform based on Doris has satisfied the commercial query platform's unified writing and querying in real time and offline, supports multiple business scenarios such as BI analysis, offline computing, C-side high concurrency, etc., and provides product marketing, customer operations, Scenarios such as data analysis provide data insight capabilities and value mining capabilities. In the future, the business query platform also plans to carry out the following upgrades and optimizations:
- Version upgrade: Upgrade to Apache Doris 2.0 version to further implement the latest features such as high-concurrency enumeration and partial column updates, further optimize the existing architecture, and improve query efficiency.
- Scale expansion: Further expand the cluster size and migrate more analysis calculations to Doris;
- Log analysis: As the number of nodes increases, log data continues to be generated. In the future, the platform plans to connect cluster logs to Doris for unified collection, management and retrieval. , which facilitates prompt detection of problems, so inverted index and log analysis are also important expansion scenarios later;
- Automated operation and maintenance: In some specific query scenarios, the cluster BE node may be down. Although the probability of occurrence is low, manual startup is still troublesome and will be followed later. Introducing automatic restart capabilities so nodes can quickly recover and get back into operation.
- Improve data quality: At present, the platform focuses most of its time on business realization, unified collection and completion of data entrances, and there are still shortcomings in data quality monitoring, so It is hoped that data quality can be improved in this regard.