Preface
This article belongs to the column "Big Data Theoretical System". This column is original by the author. Please indicate the source when citing. Please help point out any deficiencies and errors in the comment area. Thank you!
For the directory structure and references of this column, please see Big Data Theory System
Companion
"Detailed Explanation of Distributed Data Model: OldSQL => NoSQL => NewSQL"
"Detailed Explanation of Distributed Computing Models: MapReduce, Data Flow, P2P, RPC, Agent"
"Detailed Explanation of Real-time Data Warehouse"
mind Mapping
Lambda architecture
The origin of Lambda

We usually think of this Greek letter as being associated with this pattern because the data comes from two places.
The batch data and the fast streaming data represent the curved parts of the Lambda symbol and are then merged through the service layer (line segments are merged with the curved parts) as shown in the image above.
WHAT
Lambda Architecture is a big data processing architecture proposed by Twitter engineer Nathan Marz.
Its goal is to build a general and robust big data system that can meet the needs of real-time query and historical data batch processing at the same time.
With the rise of big data, more and more companies are beginning to face the problem of processing massive data. Traditional batch processing systems cannot meet the needs of real-time data processing, and simple stream processing systems cannot perform complex historical data analysis. This requires a hybrid architecture that can balance real-time performance with complex analytics. Lambda architecture came into being.
For details about Lambda architecture, please refer to my blog - "What is Lambda Architecture?" 》
composition
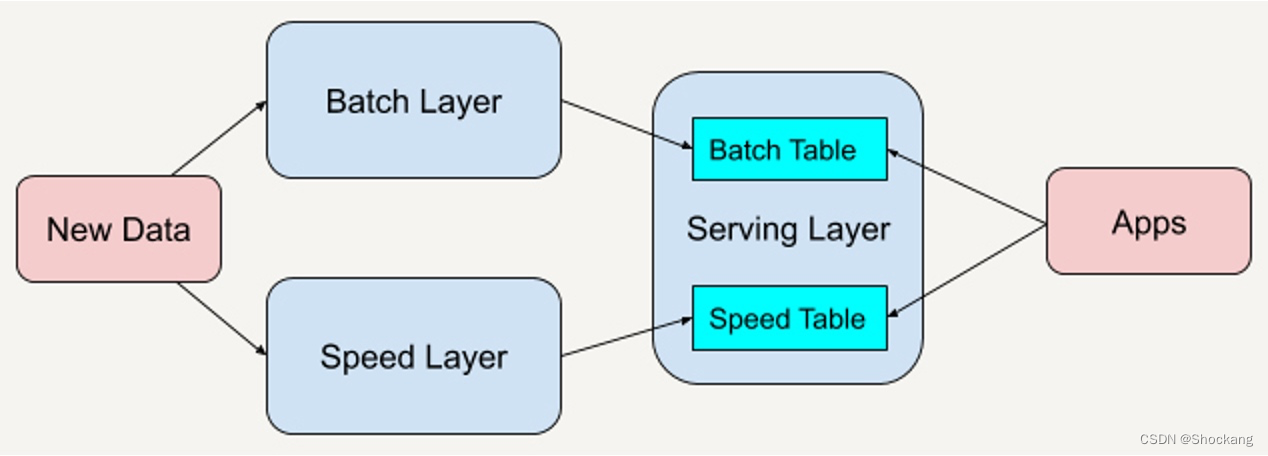
The Lambda architecture consists of a total of three layers of systems: Batch Layer, Speed Layer, and Serving Layer for responding to queries.
In the Lambda architecture, each layer has its own tasks.
batch layer
The batch layer stores and manages master data sets (immutable data sets) and pre-batch computed views.
The batch processing layer precomputes results using a distributed processing system that can handle large amounts of data.
It achieves data accuracy by processing all existing historical data.
This means it is recalculated based on the complete data set, fixing any errors, and then updating the existing data view.
The output is typically stored in a read-only database, and updates completely replace the existing precomputed view.
speed processing layer
The speed processing layer processes incoming big data in real time.
The speed layer minimizes latency by providing a real-time view of the latest data.
The views of data produced by the speed layer may not be as accurate or complete as the views ultimately produced by the batch layer, but they are available almost immediately upon receipt of the data.
When the same data is processed in the batch layer, the data in the speed layer can be replaced.
Essentially, the speed layer makes up for the lag in data views caused by the batch layer.
For example, each task in the batch processing layer takes an hour to complete, and during this hour, we cannot obtain the data view given by the latest task in the batch processing layer.
The speed layer makes up for this one-hour lag because it can process data in real time and provide results.
service layer
All output processed in the batch and speed layers 结果is stored in the service layer, and the service layer responds to queries by returning precomputed data views or constructing data views from speed layer processing .
Kappa architecture
Kappa architecture is an improvement and optimization of Lambda architecture, first proposed by Jay Kreps in 2014.
With the development of streaming computing systems, some problems with the Lambda architecture have gradually emerged:
- High system complexity : batch processing systems and streaming systems need to be developed and maintained at the same time.
- Implementing low-latency queries through log replay can lead to data redundancy .
- There is an issue with latency inconsistency between real-time and batch views .
In order to solve these problems, Jay Kreps proposed the Kappa architecture. The Kappa architecture removes the batch processing layer of the Lambda architecture and implements the entire process directly through the stream processing system.
For details about the Kappa architecture, please refer to my blog - "What is the Kappa Architecture?" 》
composition
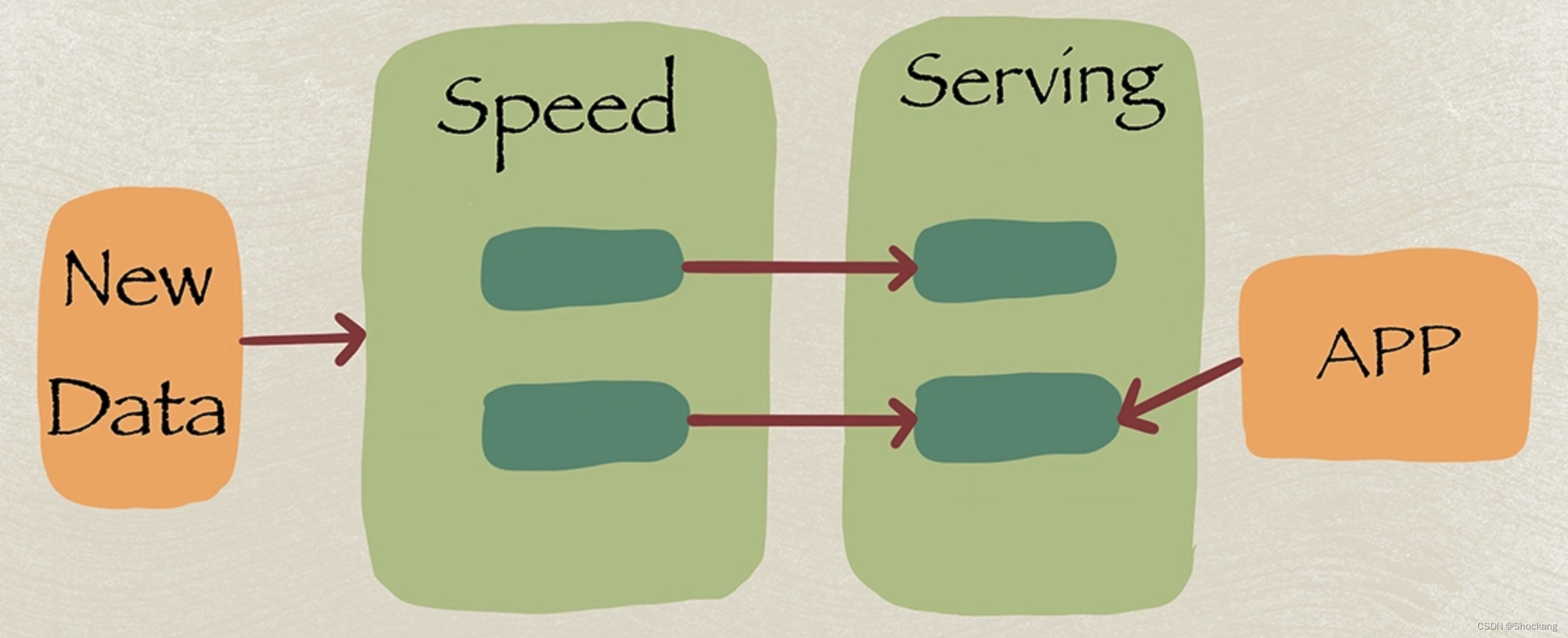
The Kappa architecture mainly consists of two layers:
- Streaming processing layer: receives all data through the streaming system, performs real-time calculations, and updates the result view in storage.
- Service layer: Provides query services to the outside world, and directly performs query returns based on the result view updated by the streaming processing layer.
The Kappa architecture reduces system complexity and avoids data redundancy and data inconsistency. However, the streaming processing system needs to be able to guarantee Exactly-oncesemantics to ensure the correctness of streaming calculations. Moreover, complex calculations on historical data will be more difficult without the batch processing system .
Take Apache Kafka as an example to describe the entire Kappa architecture process
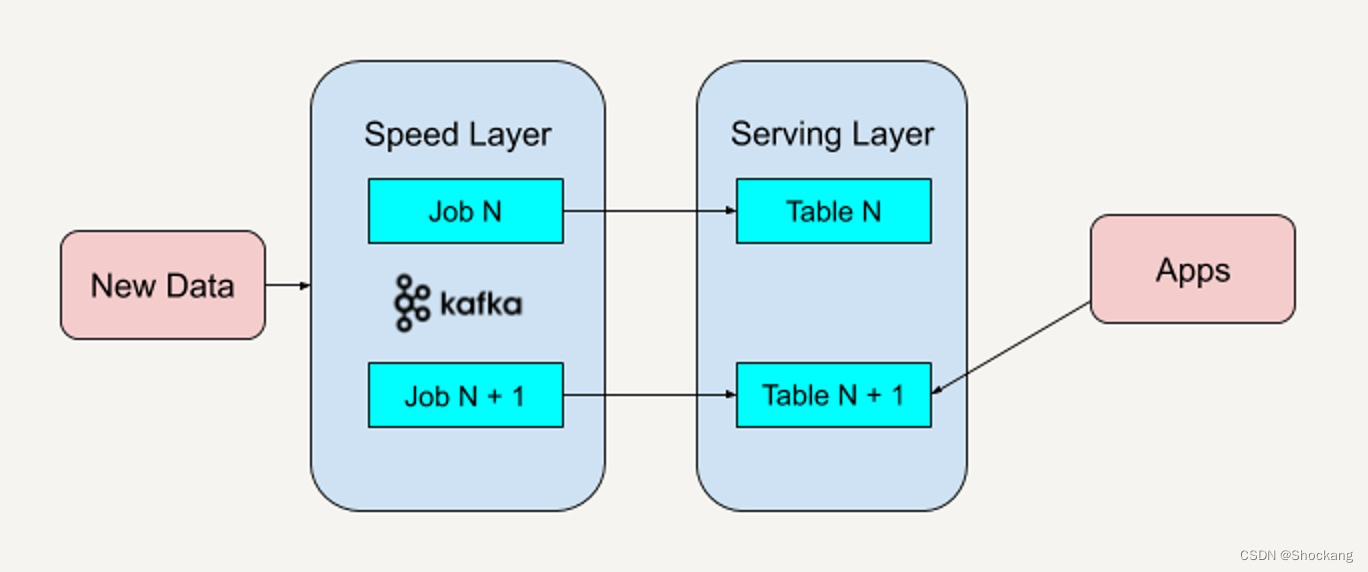
- Deploy Apache Kafka and set the retention period of the data log (Retention Period) . The retention period here refers to the time interval of historical data that you want to be able to reprocess. For example, if you want to reprocess up to one year's worth of historical data, you can set the retention period in Apache Kafka to 365 days. If you want to be able to process all historical data, you can set the retention period in Apache Kafka to "Forever".
- If we need to improve existing logical algorithms, it means we need to reprocess historical data. All we need to do is restart an Apache Kafka job instance (Instance). This job instance will start over, recalculate the retained historical data, and output the results to a new data view. We know that the bottom layer of Apache Kafka uses Log Offset to determine which data block has been processed, so you only need to set the Log Offset to 0 , and the new job instance will start processing historical data again.
- When the data processed by this new data view catches up with the old data view, our application can switch to reading from the new data view.
- Stop the old version of the job instance and delete the old data view .
Different from the Lambda architecture, the Kappa architecture removes the batch processing layer and only retains the speed layer. You only need to reprocess the data when the business logic changes or the code changes.
Of course, you can also make some optimizations in the steps mentioned above. For example, step 4 is not performed, that is, the old data view is not deleted. The advantage of this is that when you find an error in the code logic, you can roll back to the previous version of the data view in time. Or maybe you want to provide A/B testing at the service layer. Keeping multiple versions of the data view will help you perform A/B testing.
Lambda architecture vs Kappa architecture
The difference between Lambda architecture and Kappa architecture can be compared and explained through the following table:
| Comparative item | Lambda architecture | Kappa architecture |
|---|---|---|
| composition | Batch layer speed layer service layer |
Streaming processing layer service layer |
| Data processing methods | Batch systems process historical data and streaming systems process real-time data. |
Only use streaming systems to process all data |
| System complexity | Higher, two systems need to be developed and maintained | Lower, requires only a streaming system |
| Lazy consistency | Yes, there is a latency difference between real-time view and batch view | Better, no batch system |
| Data redundancy | Exists, need to replay the log to the real-time system | Less, no need to replay logs |
| Historical data processing | Batch processing system enables complex historical analysis | Relatively complex, only streaming system |
In conclusion:
The Lambda architecture combines low latency and complex analysis through the combination of batch processing layer and speed layer, but the system is complex and has data redundancy and latency inconsistency issues.
The Kappa architecture only implements all processing through the streaming system, which simplifies the architecture. However, historical data analysis is relatively complex and requires the streaming system to ensure accurate once semantics.
Both have their own advantages and disadvantages, and technical selection and design trade-offs need to be made based on specific scenarios.
Kappa architecture variant
Kappa-S
The Kappa-S architecture is optimized and improved based on the Kappa architecture.
The Kappa architecture enables low-latency real-time computing and historical data processing through a single stream processing system.
But the original Kappa architecture still has some problems:
- The processing of historical data is still relatively complex and not as good as the batch processing system in the Lambda architecture.
- A single streaming system needs to handle all data and faces greater pressure .
- Streaming systems need to ensure exactly-once semantics, which is more complex to implement.
In order to solve these problems, Jay Kreps and others proposed the Kappa-S architecture. This architecture introduces the Stream-Serving layer based on the Kappa architecture.
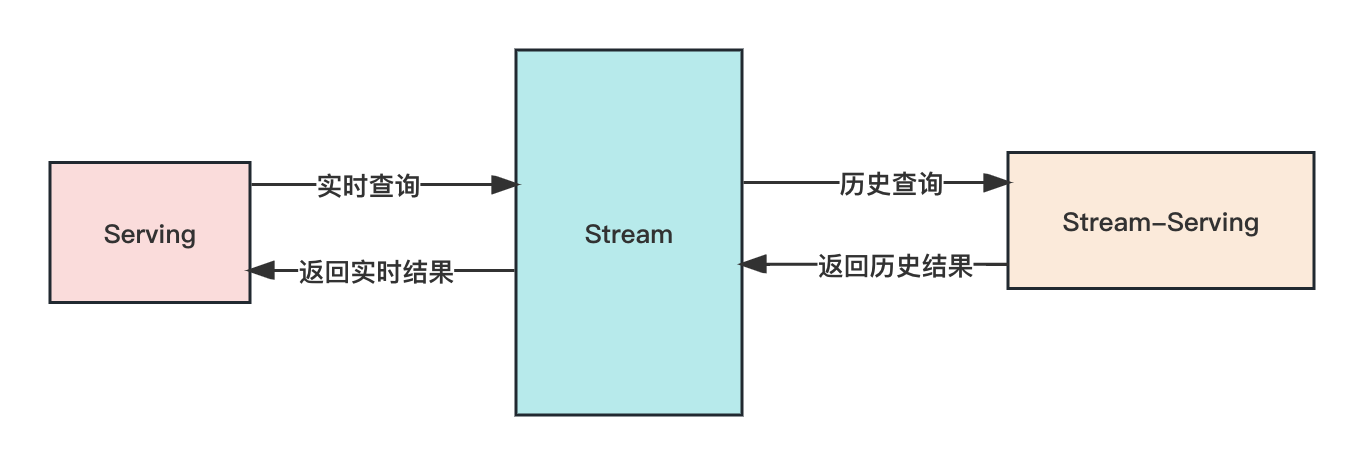
The Kappa-S architecture consists of the following components:
- Stream layer: real-time streaming processing layer.
- Serving layer: query service layer.
- Stream-Serving layer: used to precompute and serve historical data queries to reduce Stream load.
By introducing the Stream-Serving layer to precompute historical data , the Kappa-S architecture reduces the pressure of streaming processing, making the query and analysis of historical data simpler, while also avoiding the complexity of streaming systems that need to provide precise once semantics. . It can be seen as a compromise between Kappa architecture and Lambda architecture.
Kappa-Lambda
The Kappa-Lambda architecture is a hybrid architecture that is based on the Kappa architecture and introduces the batch processing layer components of the Lambda architecture.
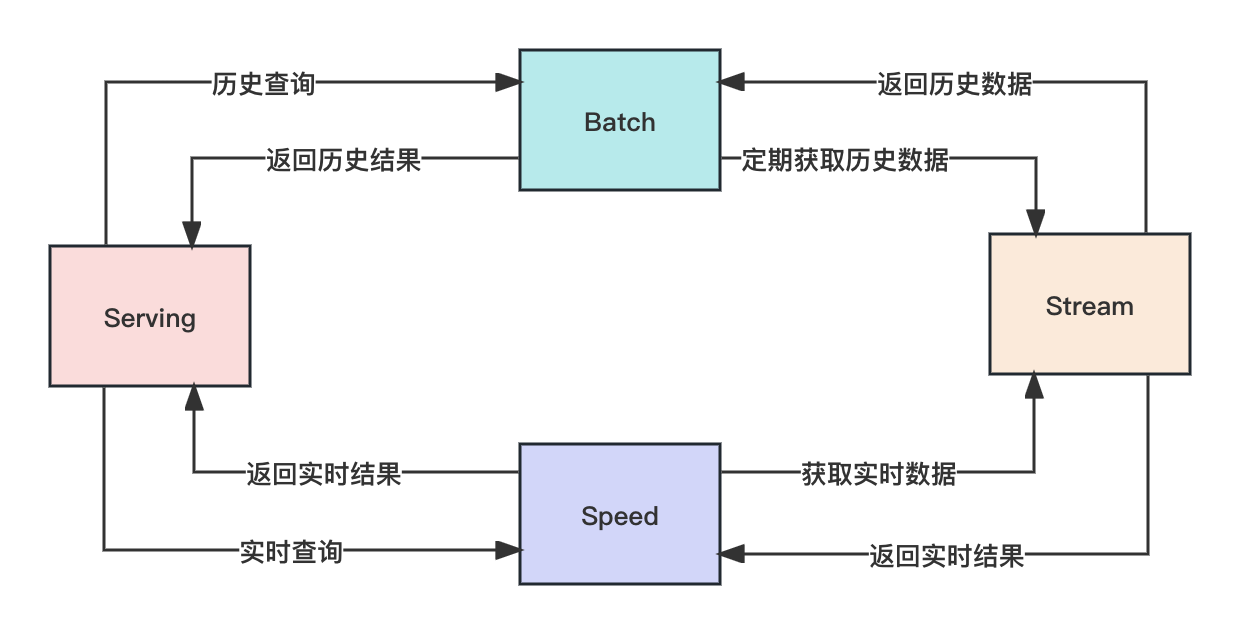
The Kappa-Lambda architecture consists of the following components:
- Stream layer: real-time streaming processing layer.
- Serving layer: query service layer.
- Batch layer: Batch processing layer, used for complex historical data analysis.
- Speed layer: Speed layer for low-latency real-time computing.
The workflow is as follows:
- The Stream layer receives real-time data and performs real-time calculations.
- The Speed layer obtains real-time results from the Stream layer and performs low-latency real-time analysis.
- When querying the Serving layer, the real-time part is obtained from the Speed layer, and the historical part is obtained from the Batch layer.
- The Batch layer regularly obtains data from the Stream layer and performs complex historical data analysis and processing.
It can be seen that compared with the Kappa architecture, the Kappa-Lambda architecture introduces batch processing layer components to facilitate complex historical data analysis. At the same time, the Speed layer is retained for low-latency real-time calculations.
This design takes into account the simplicity of the Kappa architecture and the advantages of the Lambda architecture in complex analysis. It can process both real-time and complex batch processing.
Kappa-DB
The Kappa-DB architecture is an architectural design formed on the basis of the Kappa architecture by introducing database components to achieve persistent storage of streaming data into the database.
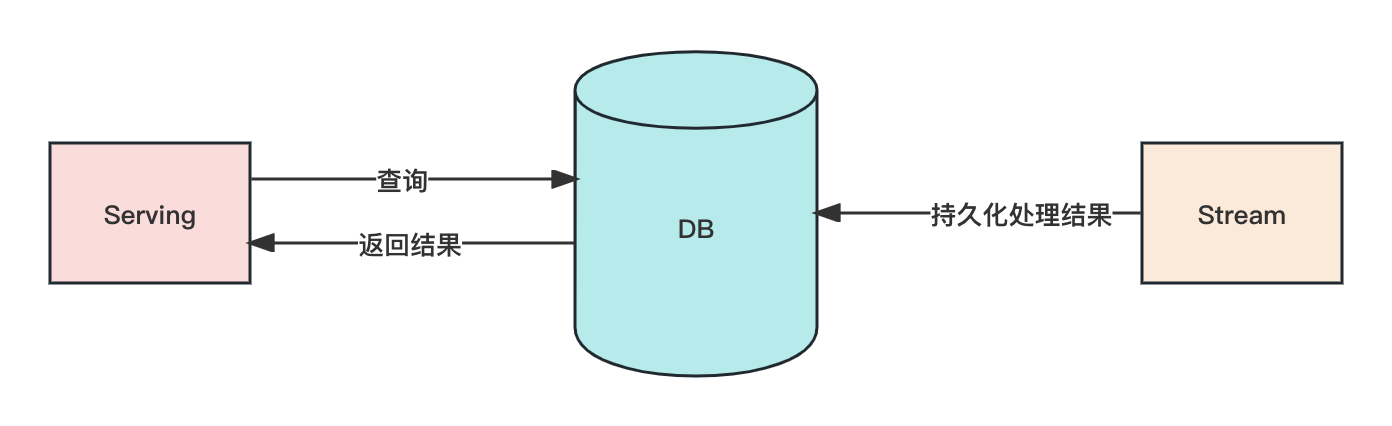
Kappa-DB architecture usually contains the following components:
- Stream layer: real-time streaming processing layer.
- Serving layer: query service layer.
- Database: Database layer, used to store the result data of streaming processing.
The workflow is as follows:
- The Stream layer receives real-time data and performs real-time processing.
- The Stream layer writes the processing results to the database for persistent storage.
- The Serving layer receives query requests, reads data from the database, performs calculations and returns results.
- Archiving or aggregating regularly to avoid database overflow.
The advantages of introducing database components include:
- Avoid data loss through database persistent storage.
- Simplify historical data query, and the database can perform index optimization.
- Storage costs can be reduced through archiving.
- The computing power of the database can be reused to reduce stream computing overhead.
It is necessary to pay attention to the problem that database writing becomes the bottleneck of the system. It is usually necessary to control the frequency of writing to the database and perform archiving optimization.
In general, the Kappa-DB architecture achieves persistent storage of data by integrating streaming processing and databases , while also inheriting the advantages of the Kappa architecture.
Kappa series architecture comparison
| Architecture type | composition | advantage | shortcoming |
|---|---|---|---|
| Kappa | Streaming processing layer service layer |
Simple and consistent | Historical processing is complex |
| Kappa-S | Streaming processing layer Service layer Precomputing layer |
Reduce flow pressure and simplify history processing |
An extra layer of complexity |
| Kappa-Lambda | Streaming layer Service layer Speed layer Batch layer |
Considers both real-time and batch processing | The architecture is more complex |
| Kappa-DB | Streaming processing layer Service layer Database layer |
Data persistence uses DB computing |
DB becomes the bottleneck |
in summary:
- Kappa architecture is simple but historical processing is complex
- Kappa-S reduces real-time traffic pressure through the pre-computation layer, but increases system complexity
- Kappa-Lambda introduces batch processing capabilities, but the architecture is very complex
- Kappa-DB uses a database for persistence, but may face DB bottlenecks
It is necessary to choose a suitable architecture based on specific business needs, balancing the needs of real-time processing, historical processing, consistency, scope, etc.
Integrated flow and batch
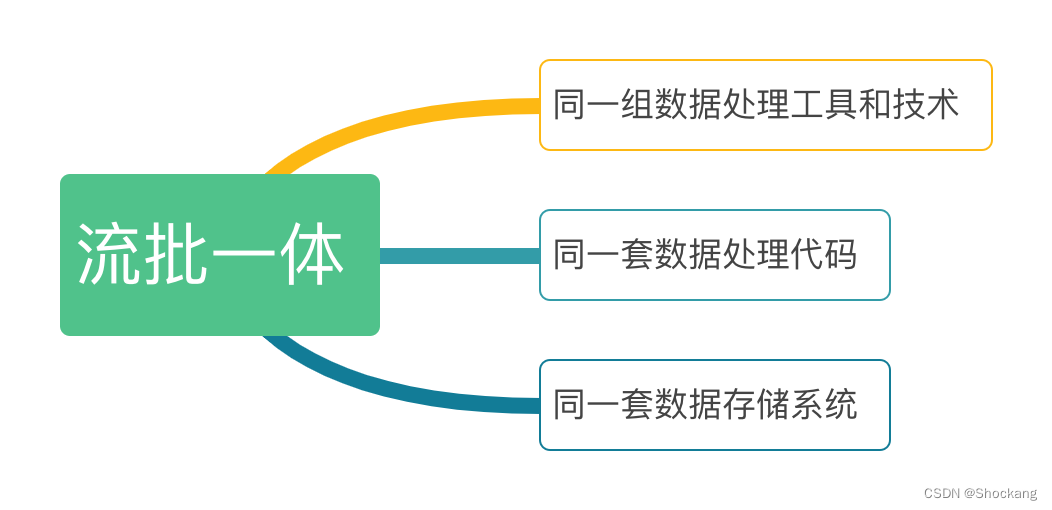
Unified Batch and Streaming Processing refers to unifying streaming processing and batch processing in a runtime framework for integrated processing.
In the streaming-batch integrated architecture, real-time data streaming and historical data batch processing can use the same set of data processing tools and technologies , such as Apache Spark, Apache Flink, etc. The streaming-batch integrated architecture can process and analyze real-time data and historical data in a unified manner to simplify the complexity of data processing and improve the efficiency of data processing.
In the streaming-batch integrated architecture, real-time data streaming and historical data batch processing can use the same set of data processing codes . This means that data processors can use the same programming languages, frameworks, and tools to process both real-time and historical data. This can reduce the learning and usage costs of data processing personnel and improve the efficiency and accuracy of data processing.
The streaming-batch integrated architecture can also store real-time data and historical data in the same data storage system , such as Apache HBase, Apache Cassandra, etc. This simplifies the management and maintenance of data storage and improves data availability and reliability.
In short, stream-batch integration is a data processing architecture that integrates stream data processing and batch data processing. It can simplify the complexity of data processing and improve the efficiency of data processing. The streaming-batch integrated architecture can achieve seamless switching between real-time data processing and historical data batch processing to meet different data processing needs.
birth background
The birth of Liubatch Integration mainly has the following background:
- The complexity of Lambda architecture: Lambda architecture requires the development and maintenance of batch processing systems and streaming processing systems at the same time. The system is complex and development and operation and maintenance are difficult.
- Integration of real-time computing and historical computing requirements: More and more applications require both real-time data processing and historical data analysis, requiring a unified framework.
- The development of streaming processing systems has matured: The computing model and performance of streaming processing systems have matured and can be used to replace traditional batch processing tasks.
- The emergence of micro-batch streaming technology: Systems such as Spark Streaming use micro-batch streaming to simplify event time management of streaming processing.
- The rise of cloud native technology: Technologies such as Kubernetes provide better resource scheduling and technical support for streaming and batch integration.
In summary, stream-batch integration can be seen as a simplification of the Lambda architecture and a product of the integration of real-time processing and batch processing to cope with scenarios where real-time data and historical data are required.
Dataflow model
The DataFlow model is a computing model used to describe data processing processes. It describes the flow of data from source to destination and specifies the method and sequence of data processing.
The DataFlow model is commonly used in 并行计算and 数据流处理fields. For example, the stream processing framework Apache Flink is implemented based on the DataFlow model.
In the DataFlow model, data is regarded as a flowing entity, and data processing is regarded as a series of data transformation operations . Data can flow into the data processing system from one or more input sources, undergo a series of processing operations, and finally be output to one or more output destinations. During data processing, data can be divided into multiple data blocks, and these data blocks can be processed in parallel to improve the efficiency of data processing.
Data processing operations in a DataFlow model are typically described as nodes in a directed graph , and data flows are described as directed edges . Each node can perform some specific data processing operations, such as data filtering, data transformation, data aggregation, etc. The edges between nodes represent the flow direction of data and the order of data processing. In the DataFlow model, data processing operations can be combined into complex data processing processes to achieve different data processing requirements.
In short, the DataFlow model is a computing model used to describe the data processing process. It describes the flow of data from source to destination and specifies the method and sequence of data processing. The DataFlow model is often used in the fields of parallel computing and data flow processing. For example, the stream processing framework Apache Flink is implemented based on the DataFlow model.
For more details about the Dataflow model, please refer to my blog - "What is the DataFlow model?" 》
birth background
The main background of the Dataflow model:
- The explosion of data scale in the era of big data requires parallel computing capabilities
- Fusion of requirements for streaming computing and batch processing
- Limitations of the MapReduce model: The MapReduce model is not friendly to iterative calculations and DAG support, while the Dataflow model is more suitable for expressing complex data processing processes through Operator graphs.
- Advances in distributed resource management and cluster scheduling technologies: YARN, Mesos, Kubernetes and other technologies provide better runtime support for the Dataflow model.
- The development of in-memory computing: In-memory computing frameworks such as Spark are more suitable for the Dataflow model.
In summary, the Dataflow model is an important development and extension of the MapReduce model. It can better handle complex data processing tasks such as iteration, streaming, and DAG, and has been widely used in the big data era.
For information about the MapReduce model, please refer to my blog - "What is the MapReduce programming model?" 》
The whole process of Dataflow model

The entire process of the DataFlow model can be divided into the following steps:
- Data source input: Data sources can be various types of data, such as files, databases, message queues, etc. In the DataFlow model, the data source is regarded as the starting point of the data processing process, and data flows from the data source into the data processing system.
- Data cutting: In the DataFlow model, data can be divided into multiple data blocks, and these data blocks can be processed in parallel to improve the efficiency of data processing. Data cutting can be performed based on data size, timestamp, key value, etc. to better achieve parallel data processing.
- Data transformation: In the DataFlow model, data can undergo a series of data transformation operations, such as data cleaning, data filtering, data aggregation, etc. Data transformation operations are described as nodes in a directed graph. Each node can perform some specific data processing operations. The edges between nodes represent the flow direction of data and the order of data processing.
- Data aggregation: In the DataFlow model, data can be aggregated after multiple data transformation operations to better implement data analysis and mining.
- Data output: In the DataFlow model, data output can be various types of data destinations, such as files, databases, message queues, etc. Data output is considered the end point of the data processing process, where data is output from the data processing system to the data destination.
In the DataFlow model, data processing operations can be combined into complex data processing processes to achieve different data processing requirements. The data processing process can be implemented using various data processing frameworks and tools, such as Apache Flink, Apache Beam, Apache Kafka, etc.
How the Dataflow model ensures data accuracy and consistency
DataFlow models can ensure data accuracy and consistency in the following ways:
- Data verification: Before data flows into the data processing system, data verification can be performed, such as data format, data type, data range, etc. This ensures data accuracy and completeness.
- Data cleaning: During the data processing process, data cleaning can be performed, such as removing duplicate data, filling in missing data, etc. This ensures data consistency and accuracy.
- Transaction processing: During data processing, transaction mechanisms can be used to ensure data consistency. For example, if data processing on a node fails, the entire data processing process can be rolled back to the previous state to ensure data consistency.
- Data partitioning: During data processing, data can be divided into multiple data blocks, and each data block can be processed in parallel. This can improve the efficiency of data processing, while also avoiding data competition and data conflicts to ensure data consistency.
- Data retry: During data processing, if a node fails to process, data can be retried until the data is processed successfully. This ensures data integrity and accuracy.
Real-time data warehouse
The real-time data warehouse is a modern data warehouse with small data semantics and performance at the scale of big data . It can process real-time data, latest data and historical data, and can perform correlation analysis across data domains. The real-time data warehouse has faster data arrival and query speed, and can complete all functions on an integrated and secure platform.
The benefits of a real-time data warehouse include faster decision-making, data democratization, personalized customer experience, increased business agility and unlocking new business use cases. However, real-time data warehouses also face challenges such as ETL performance and complex real-time computing scenarios.
A typical real-time data warehouse architecture includes a data collection layer, a data storage layer, a real-time computing layer and a real-time application layer. The data collection layer is responsible for receiving and transmitting data, the data storage layer is used for real-time data storage, the real-time computing layer is used for real-time calculation and analysis, and the real-time application layer is used for data analysis and mining.
Real-time data warehouse can be used in scenarios such as real-time OLAP analysis, real-time data dashboard, real-time business monitoring and real-time data interface services. Its technical implementation usually includes message bus, real-time storage, stream processing and analysis, and application layer.
Commonly used real-time data warehouse technologies include Apache Kafka, Apache Druid, Apache Spark, Hadoop, TiDB, etc. The specific choice depends on needs and preferences.
For more details about real-time data warehouse, please refer to my blog - "Real-time Data Warehouse Detailed Explanation"
birth background
The main birth background of real-time data warehouse are:
- Growing demand for real-time data analytics: More and more businesses want to be able to analyze operational data instantly to make timely decisions.
- The problem of large delays in traditional data warehouses: Traditional data warehouses are updated regularly in batches, which cannot meet the needs of real-time data analysis.
- Development of streaming computing technology: Big data technology makes it possible to collect, transmit and calculate streaming data.
- Advances in in-memory computing: In-memory computing technologies such as Spark make memory-level interactive analysis possible.
- Requirements for improving user experience: Users want to obtain analytical insights immediately and cannot wait for the delay of traditional data warehouses.
- Advances in cloud computing technology: Cloud computing provides the ability to elastically expand real-time data warehouses.
Architecture
Real-time data warehouse usually has four components: data collection layer, data storage layer, real-time computing layer and real-time application layer. These components work together to support the processing and analysis of event data immediately or shortly after an event occurs. All data processing stages (data ingestion, enrichment, analysis, AI/ML-based analysis) are continuous with minimal latency and enable real-time reporting and ad hoc analysis.
A typical real-time data warehouse architecture is as follows:
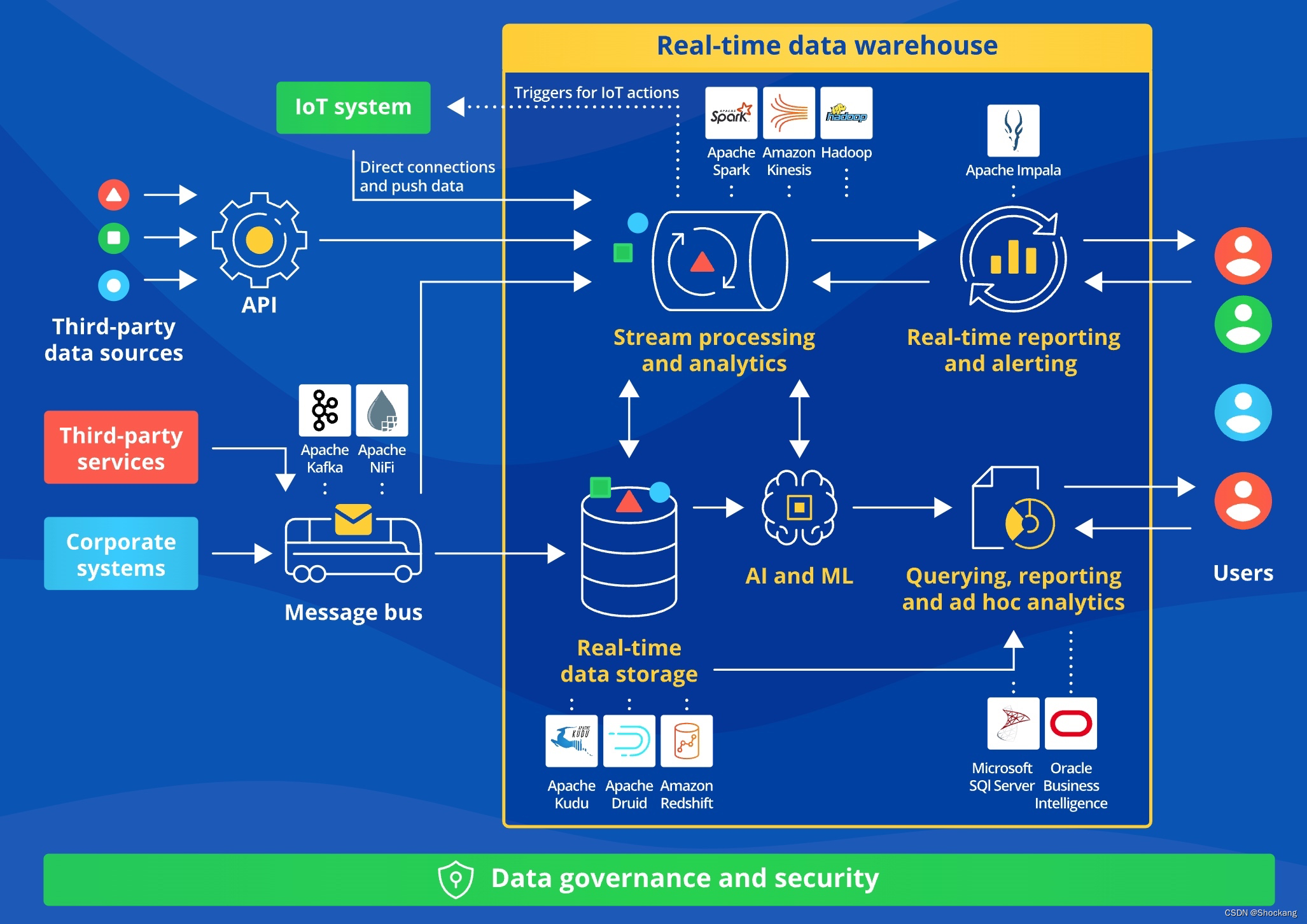
- Data collection layer: Third-party services and collaborative systems transmit data to the real-time data warehouse through message buses such as Apache Kafka/Apache Nifi; third-party data sources call the API of the real-time data warehouse; IoT systems directly connect and push data Method to transfer data
- Data storage layer: Use Apache Kudu/Apache Druid/Amazon Redshift for real-time data storage
- Real-time computing layer: Use Apache Spark/Amazon Kinesis/Hadoop for real-time computing and analysis
- Real-time application layer: Use AI and machine learning technology to analyze and mine data, use SQL Server/Oracle BI to support queries, reports and ad hoc queries; use Apache Impala to support real-time reporting and alarms.
Compared
| Architecture type | composition | advantage | shortcoming |
|---|---|---|---|
| Lambda architecture | Batch layer speed layer service layer |
Balance low latency with complex analytics | Complex system and redundant data |
| Kappa architecture | Streaming processing layer service layer |
The system is simple and consistent | Historical processing is relatively complex |
| Integrated flow and batch | Unified runtime framework | Simplified processing and high efficiency | Real-time discount |
| Dataflow model | Data sources, transformation operations, data aggregation | Strong flexibility and good scalability | Issues such as consistency need to be addressed |
| Real-time data warehouse | Collection layer, storage layer, computing layer, application layer |
Real-time analysis, low latency | High infrastructure requirements |
Summarize
This article details several major big data processing architectures:
- Lambda架构:组合批处理层和速度层,兼顾低延迟和复杂分析,但系统较复杂,存在数据冗余和延迟不一致问题。Lambda架构的批处理层可以基于Hadoop、Spark等技术来实现,速度层可以基于Storm、Flink等流式处理系统来实现。服务层需要实现查询接口,可以使用REST API。Lambda架构适合大数据场景,但维护批处理层和速度层的重复开发较为麻烦。
- Kappa架构:仅通过流式处理实现所有处理,简化了架构,但历史数据分析相对复杂。Kappa架构还有几种变种,如Kappa-S、Kappa-Lambda、Kappa-DB。Kappa架构中的流式处理层可以基于Flink、Spark Streaming等来实现,需要实现Exactly-once语义。服务层同样需要查询接口。Kappa架构简单高效,但对实时流有较高要求,历史数据处理不如Lambda架构方便。
- 流批一体:将流式处理和批处理统一在一个运行时框架中,可以简化处理,提高效率。流批一体需要统一运行时框架,如Flink、Spark等,可以通过DataStream和DataSet在流式处理和批处理之间无缝切换。计算模型也需要统一,如Dataflow模型。流批一体简化系统,但实时性不如纯流式处理。
- Dataflow模型:将数据处理视为数据流经转换操作的流程,可以表达复杂的数据处理流程。Dataflow模型通常用有向图表达,并基于并行运行时框架实现,如Flink。需要解决数据一致性、容错等问题。Dataflow模型可以灵活表示复杂处理流程。
- Real-time data warehouse: Rapid storage and calculation analysis of real-time data are realized through streaming processing, which meets the demand for real-time analysis. The message bus in the real-time data warehouse can be implemented using Kafka, the storage system can use HBase, Druid, etc., and the calculation uses Spark Streaming and Flink. Real-time data warehouse can quickly analyze data and update it in real time, but it has higher infrastructure requirements.
In general, the development trend of big data processing architecture is 实时性增强, 处理统一简化, 满足复杂分析需求. It is necessary to choose an appropriate architectural solution based on the needs of specific business scenarios. In the future, the architecture may be based on streaming processing, while batch processing capabilities will be introduced for complex analysis.