guide
Doris, a Tencent cloud data warehouse, helped Litchi Microclass build a standardized and unified real-time data warehouse platform. At present, Tencent Cloud Data Warehouse Doris has supported more than 90% of the business scenarios within Litchi Micro-class, and the overall query response can be achieved in milliseconds. The data timeliness has been improved from T+1 to minutes, and the development efficiency has been achieved by 50%. The growth has met the needs of various business scenarios, achieved cost reduction and efficiency improvement, and has been highly recognized by the data departments of Shifang Ronghai.
Author|Chen Cheng, leader of Litchi Micro-class Data Central Group
Shenzhen Shifang Ronghai Technology Co., Ltd. was established in 2016. It is a leading enterprise in digital vocational online education. Its business covers "digital vocational skills courses, knowledge sharing platform "Litchi Micro Class", smart education solution "Nuwa Cloud Classroom" ", has launched a variety of digital literacy and digital skills course services to help users achieve skill advancement and career advancement in the digital age. The Litchi Micro-class launched in 2016 has developed into a top knowledge sharing platform in China. It will be launched in 2021. Wayun classroom has realized the integrated mode of "teaching and training", which has filled the gap in the derailment of online teaching and practical operation in China.
Business introduction
Litchi Micro-class belongs to Shenzhen Shifang Ronghai Technology Co., Ltd. and is a free-to-use online education platform. Litchi micro-class has a large amount of knowledge content, including live video, recorded video, audio and other forms. Through the empowerment of technology and data, the continuous innovation of Litchi Micro-lecture is promoted, and it also provides stronger support for the micro-lecture platform and partners in the innovation and sales of videos. In the process of business operation, we need to conduct a comprehensive analysis of users to efficiently empower the business. The data platform aims to integrate data from various data sources, integrate and form data assets, and provide business with analysis services such as the user's full link life cycle, real-time indicator analysis, and tag circle selection.
Early architecture and pain points
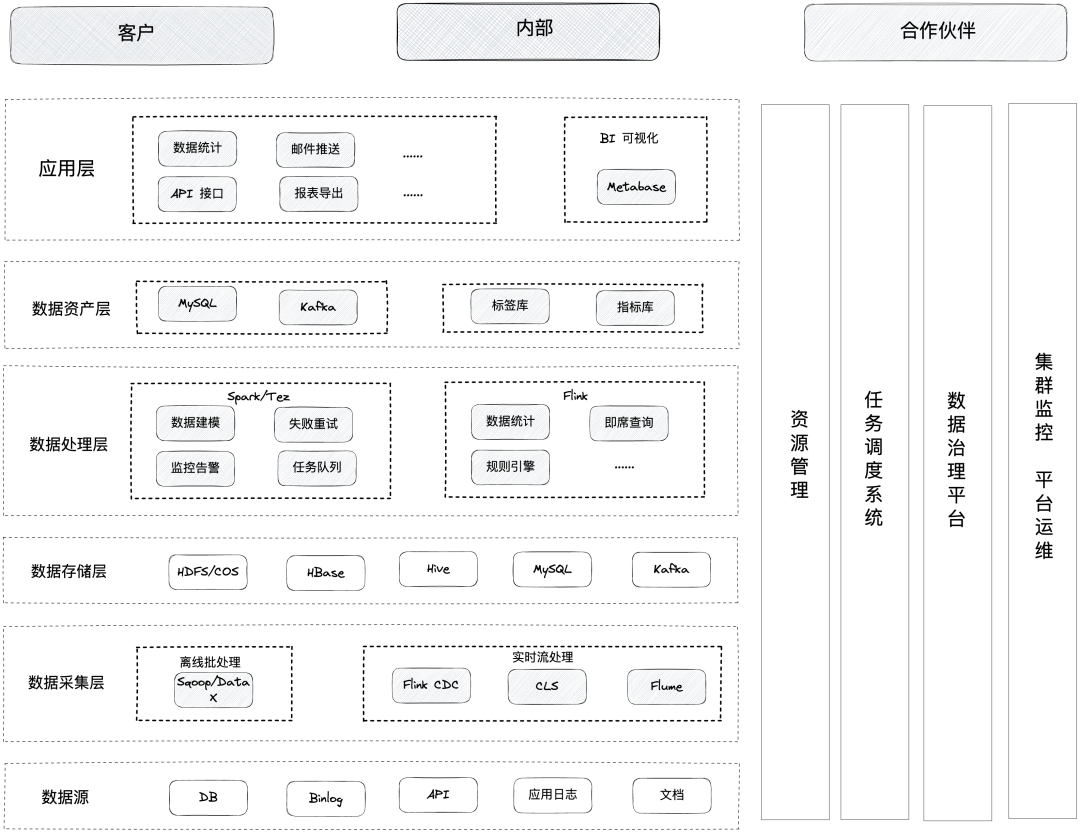
figure 1
The early architecture selected Hadoop ecosystem components, built the original offline data warehouse architecture with the Spark batch computing engine as the core, and performed real-time processing based on the Flink computing engine. The business data and log data collected from the source will be divided into real-time and offline links: in the real-time part, the business database data is accessed through Binlog, the log data is collected in real time using Flume-Kafka-Sink, and Flink Write data calculations to Kafka and MySQL. Inside the real-time data warehouse, the theory of data layering is followed to achieve maximum data reuse.
In the offline part, Sqoop and DataX are used to synchronize the data in the full and incremental business database regularly, and the log data is collected through Flume and log service. When different data sources enter the offline data warehouse, first use Hive on Spark/Tez for timing scheduling processing, and then model the ODS, DWD, DWS, ADS layer data according to the dimension. These data are stored on HDFS and object storage COS. Finally, Presto is used for data query and display, and Metabase is used to provide interactive analysis services. At the same time, in order to ensure data consistency, we will regularly overwrite real-time data with offline data.
Problems and challenges: The early architecture based on Hadoop can meet our preliminary needs, but it seems that we have more than enough power to face more complex analysis demands. In addition, in recent years, the number of users of Litchi Micro-class has been increasing, and the amount of data is increasing. Exponentially rising, in order to better empower the business and improve user experience, the business side also puts forward higher requirements for real-time data, availability, and response speed. In this context, the problems exposed by the early architecture became more and more obvious:
1) There are many components, complex maintenance, and very difficult operation and maintenance
2) The data processing link is too long, resulting in higher query latency
3) When there is a new data requirement, it will affect the whole body, and the required development cycle is relatively long
4) The timeliness of data is low and can only meet the data requirements of T+1, which also leads to low efficiency of data analysis
Technology selection
After evaluating the data scale and the problems existing in the early architecture, we decided to introduce a real-time data warehouse to build a new data platform. At the same time, we hope that the new OLAP engine can have the following capabilities:
1) Support Join operation, which can meet the flexible analysis needs of different business users
2) Support high concurrent query, which can meet the report analysis needs of daily business
3) Powerful performance, can achieve fast response in massive data scenarios
4) Simple operation and maintenance, reducing the input and cost of operation and maintenance manpower, and achieving cost reduction and efficiency improvement
5) Unified data warehouse construction, simplifying the cumbersome big data software stack
6) The community is active, and if you encounter problems during use, you can quickly get in touch with the community
Based on the above requirements, we quickly positioned two open source OLAP engines, Apache Doris and ClickHouse, both of which are currently widely used and have a good reputation. In the survey, it was found that ClickHouse has excellent performance in wide table query, fast writing speed, and is very practical for a large amount of data update; but for join scenarios, it usually requires additional tuning to achieve better performance. In most business scenarios, we need to join large amounts of data based on detailed data. In comparison, Apache Doris has powerful multi-table join capabilities and excellent high concurrency capabilities, which can fully meet our daily business report analysis needs. In addition, Apache Doris can support multiple scenarios of real-time data service, interactive data analysis and offline data processing at the same time, and supports Multi Catalog, which can realize a unified data portal. These features are the core capabilities we consider .
At the same time, we also learned about the product Doris of Tencent Cloud Data Warehouse. As a real-time data warehouse product that supports online business and multi-dimensional analysis, Tencent Cloud Data Warehouse Doris is 100% compatible with the open source Apache Doris. Satisfying various business data analysis scenarios, it can help enterprises quickly build a data analysis platform on the cloud.
In terms of multi-source data processing, Flink has an excellent performance to meet our real-time data processing demands. We chose Tencent Cloud Big Data EMR-Flink. Tencent Cloud EMR is a secure, low-cost, and highly reliable open source big data platform based on cloud-native technology and pan-Hadoop ecological open source technology, and provides a wealth of component options. As a cloud-native big data product, Tencent Cloud Data Warehouse Doris and EMR can be seamlessly integrated and linked.
Based on the above advantages, we finally chose to cooperate with Tencent Cloud Big Data and use Tencent Cloud Data Warehouse Doris + EMR to build a new real-time data warehouse architecture system.
new structure and scheme
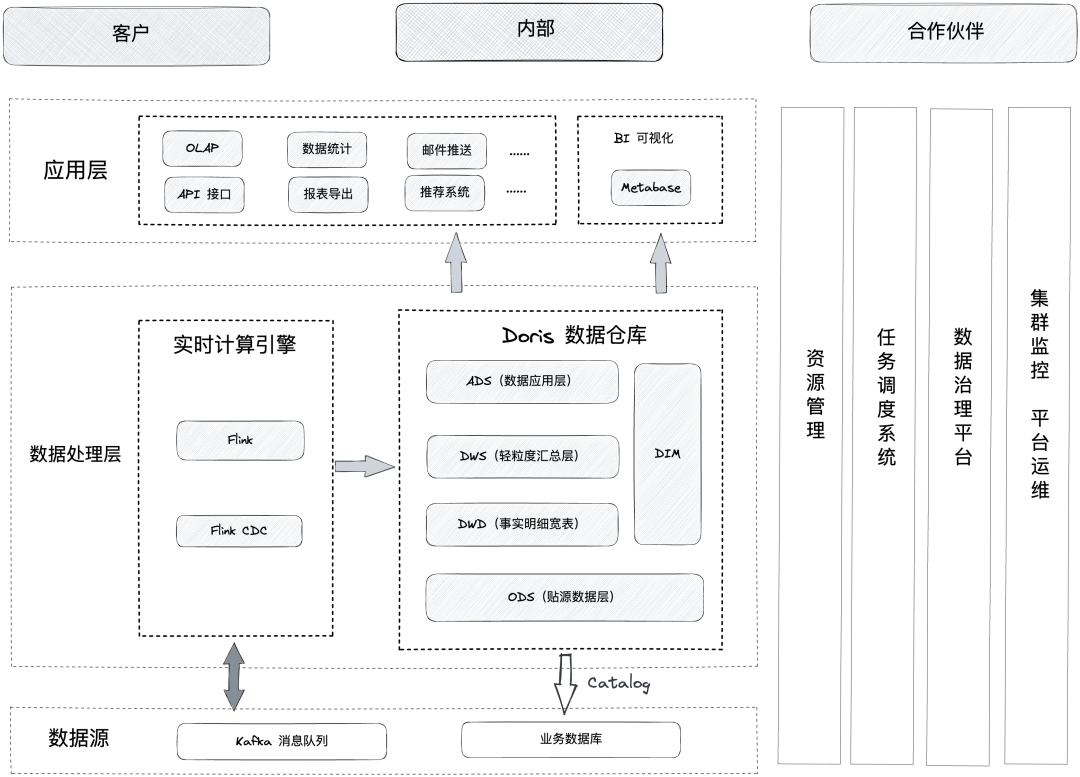
figure 2
In the new architecture, we use Tencent Cloud Data Warehouse Doris and Tencent Cloud EMR-Flink to build a real-time data warehouse. Data from various data sources are processed by Flink CDC or Flink and stored in Kafka and Doris. Finally, Doris Provide a unified query service. In terms of data synchronization, RDS data is generally synchronized to Doris in real time through Flink CDC, and Kafka log data is processed to Doris through Flink. Important index data is generally calculated by Flink, and then written into Doris through Kafka layered processing.
1) On the storage medium, Tencent Cloud data warehouse Doris is mainly used for unified storage of streaming and batch data.
2) Architecture benefits: We have successfully built a standardized and unified real-time data warehouse platform. The Multi Catalog function of Tencent Cloud Data Warehouse Doris helps us unify the export of different data sources and realize federated queries. At the same time, fast data synchronization and repair is performed by inserting external tables, which truly realizes a unified data portal.
3) The real-time performance of data is effectively improved. Through the Flink + Doris architecture, the real-time performance is shortened from the early T+1 to minute-level delay. With strong concurrency capability, it can cover more business scenarios.
4) Greatly reduces the cost of operation and maintenance. Doris has a simple architecture, only two processes of FE and BE, and does not depend on other systems; in addition, cluster expansion and contraction are very simple, and users can realize expansion without perception.
5) The development cycle has been reduced from the week level to the day level, the development cycle has been greatly shortened, and the development efficiency has increased by 50% compared with before.
build experience
1. Data modeling
Combined with the characteristics of Tencent Cloud data warehouse Doris, we modeled the data warehouse in a similar way to traditional data warehouses:
1) ODS layer: The log data of the ODS layer selects the partition table of the Duplicate model. The partition table is convenient for data repair, and the Duplicate model can also reduce unnecessary compaction. The ODS layer business database data adopts the Unique data model (business database MySQL single table data is synchronized to Doris in real time through Flink CDC, Kafka log data is cleaned by Flink, and written to Doris as the ODS layer through Doris’s Routine Load), DISTRIBUTED BY HASH KEY according to the specific Choose from the following business scenarios:
If machine resources are considered, evenly distributed KEYs can be selected to allow tablet data to be evenly distributed, so that each BE resource can be fully utilized during query and avoid the barrel effect;
If you consider the join performance of large tables, you can create it based on the Colocate Join feature to make join queries more efficient;
In the Doris 1.2 version, the Unqiue model began to support Merge On Write, which further improved the query performance of the Unique model;
2) DWD layer: For the scenario where the data is written into Doris and Kafka through Join widening processing through Flink, the Unique data model is selected;
For wide tables with high-frequency queries, choose Doris' Aggregate model, use the REPLACE_IF_NOT_NULL field type, and insert multiple fact tables. Through Doris's Compaction mechanism, it can effectively reduce the problem that the historical data is not updated in time due to the Flink state TTL.
3) DWS layer and ADS layer: The Unique data model is mainly used, and the DWS layer is partitioned by day and month according to the data volume. In addition, we will also use the INSERT INTO statement for 5-minute task scheduling and T+1 task repair to perform data warehouse layering, which facilitates rapid development of requirements and real-time data repair. For the data table of the Duplicate model, we will create a Rollup materialized view, which can speed up the query efficiency of the upper table by hitting the materialized view query.
2. Data development
In the Litchi micro-course business, operators often have operations such as adjusting live course information and modifying column names. For scenarios where the dimensions change rapidly but the dimension columns in the wide table are not updated in time, in order to better meet business needs, we use The REPLACE_IF_NOT_NULL field feature of the Doris Aggregate model is written to some columns of the Doris dimension table through the Flink CDC multi-table. When the course dimension table data changes, you need to query the upper dimension (column and live room), complete the dimension table, and then insert the data into Doris; when the upper dimension (column and live room) changes, you need to drill down Query the curriculum, complete the corresponding course ID, and then insert the data into Doris. In this way, the real-time performance of all fields in the dimension table can be guaranteed. When data is queried, the wide table is used to associate the dimension table to complete the dimension field to display data.
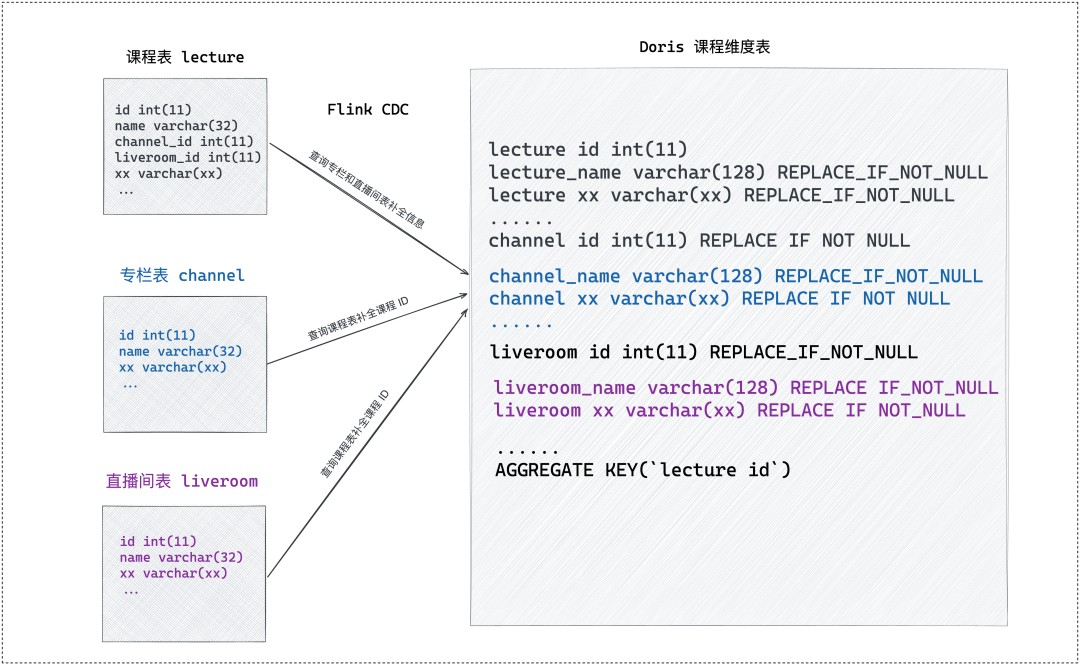
image 3
3. Library table design
In the initial design stage, in order to make better use of the Colocation Join function provided by Tencent Cloud Data Warehouse Doris, we specially designed the primary key of the fact table, as shown in the following figure:

Figure 4
In the business database, the relationship between curriculum A and curriculum B is A.id=B.lecture_id. In order to realize Colocation Join, we set the distributed by hash key of B as lecture_id. When faced with multi-fact tables, perform Colocation Join first, and then dimension Bucket Shuffle Join to achieve fast query response. Using this method may lead to the following problems: when the selected lecture_id is DISTRIBUTED BY, the database primary key ID is not uniformly distributed, which may cause data skew when the amount of data is large, and the tablet size of each machine is inconsistent. During high-concurrency queries, BE machine resources may be unbalanced, which will affect query stability and cause resource waste.
Based on the above problems, we tried to make adjustments, evaluated and weighed query efficiency and machine resource occupancy, and finally decided to improve resource utilization as much as possible without affecting query efficiency as much as possible. In terms of resource utilization, we use the colocate_with attribute when building tables to create different groups with different numbers and types of distributed keys, so that machine resources can be fully utilized.
In terms of query efficiency, the field order of the prefix index is adjusted according to business scenarios and needs. For mandatory or high-frequency query conditions, the field is placed in front of the UNIQUE KEY, and the design is performed in order from high to low according to the dimension . Secondly, we use the materialized view to adjust the order of the fields, and use the prefix index for query as much as possible to speed up data query. In addition, we partition the amount of data by month and day, bucket the detailed data, and reduce the pressure on FE metadata through reasonable database table design.
4. Data management
In terms of data management, we have done the following:
1) Monitoring and alarming: For important single tables, we generally create external tables through Tencent Cloud data warehouse Doris, and compare business database data and Doris data through data quality monitoring to perform data quality inspection and alarming.
2) Data backup and recovery: We will regularly import Doris data to HDFS for backup to avoid accidental deletion or loss of data. For example, when the Flink synchronization task fails for some reason and cannot be started from Checkpoint, we can read the latest data for synchronization, and the historical missing data is repaired through the external table, so that the synchronization task can be quickly restored.
Benefit Summary
In the new architecture, we completely migrated from the Hadoop ecology to Flink + Doris, and built different data applications on the upper layer, such as self-service reports, self-service data extraction, data large screen, business warning, etc. Doris unifies external service projects through the application layer interface Provide API query, and the application of the new architecture has also brought us a lot of benefits: it supports more than 90% of the business scenarios in Litchi Micro-class, and the overall query response can reach millisecond level.
1) It supports tens of millions or even hundreds of millions of large table association queries, and can achieve second or even millisecond response.
2) Doris unifies the data source export, significantly improves query efficiency, supports federated query of multiple data, and reduces the complexity of multi-data query and the cost of data link processing.
3) Doris has a simple architecture, which greatly simplifies the big data architecture system; and is highly compatible with MySQL syntax, which greatly reduces the access cost of developers.
future plan
After the introduction of Tencent Cloud data warehouse Doris, Litchi Micro-class has been widely used internally, meeting the needs of various business scenarios, reducing costs and improving efficiency, and has been highly recognized by the data departments of Shifang Ronghai. In the future, we expect Tencent Cloud Data Warehouse Doris to further improve its capabilities in real-time data processing scenarios, including partial column updates on Unique models, computing enhancements on single-table materialized views, multi-table materialized views with automatic incremental refresh, etc. , through continuous iterative updates, making the construction of real-time data warehouses easier and easier to use. Finally, I would like to thank Tencent Cloud Big Data and selectDB teams for their quick response to problems and active technical support. At the same time, Tencent Cloud will continue to refine its products and explore the road of cloud practice that can benefit more industry scenarios.