Article directory
- Review of previous knowledge points
- Body: Perform "add, delete, search and modify" operations on the data table
-
- New operation - insert keyword
- Find statement (basic operation) - select keyword - key! ! ! ! ! ! ! !
-
- 1. The most basic search: full column search
- 2. Specify column query: only query the column of data you want
- 3. Specify the query field as an expression
- 4. Alias (keyword as): Specify the query field as an expression, and give the expression a name
- 5. Deduplication for duplicate results - keyword distinct
- 6. Sort: keyword (order by)
- Knowledge paving - paving the way for the seventh operation of select
- Notice:
- 7. Conditional query in select: keyword where
- In the query statement, compare with NULL
- 8. Paging query: keyword limit
- Edit: keyword update
- Delete
- Next article[Advanced operation of "adding, deleting, checking and modifying" data tables](https://blog.csdn.net/DarkAndGrey/article/details/123359881)
Review of previous knowledge points
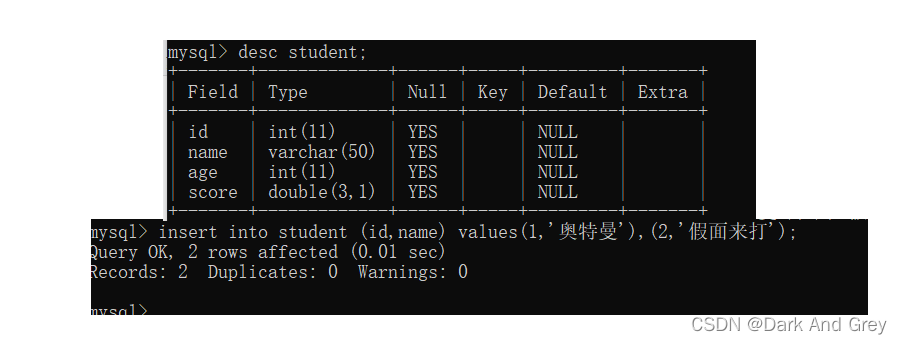
MySQL Second Lecture - Simple Operation of Data Tables and "The Beginning of Addition, Deletion, Search and Modification - Addition" This last blog post mainly talks about the operation of data tables in the database.
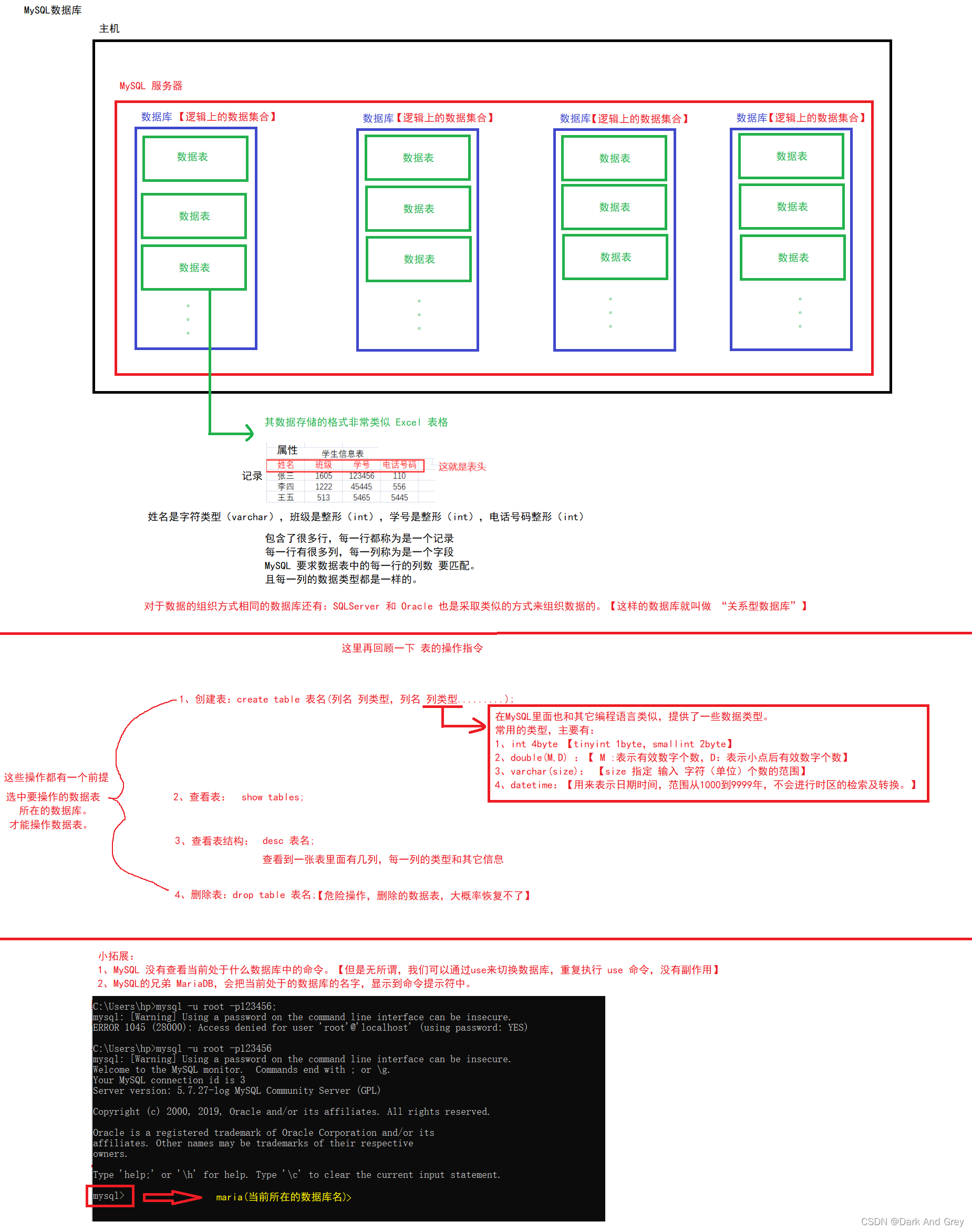
Body: Perform "add, delete, search and modify" operations on the data table
New operation - insert keyword
The last blog only introduced a simple insert operation: insert into table name values (column value, column value...);
the number of column should be equal to the number of columns in the inserted data table, and the corresponding column The type of the value should also match [simply put: to insert data, insert a full row of data directly. Make the number of inserted values equal to the number of columns]
but! Insert When inserting, by specifying the header of the insert, you can directly insert the data of a certain column or several columns (the number of column values does not need to match the number of columns). In this case the other columns will take default values.
Command: insert into table name (specified headers/fields) values (column value, column value...);
However, the insert operation: insert into table name values (column values...);
it can actually insert multiple rows of data at a time, and the last blog post demonstrated only one row of data / several columns in a row at a time.
Let's demonstrate the multi-row insert data of the insert keyword.
Command format: insert into table name values (one row of values), (one row of values), , , , , , ,;
each parenthesis after values corresponds to a row of data, which can have multiple (), multiple Use commas to separate between () .
Of course, we can also specify the column value and number of columns for multi-row insertion. [By specifying the table header to be inserted, you can directly insert data of a certain column or several columns of multiple rows (without matching the number of column values with the number of columns). In this case the other columns will take default values. ]
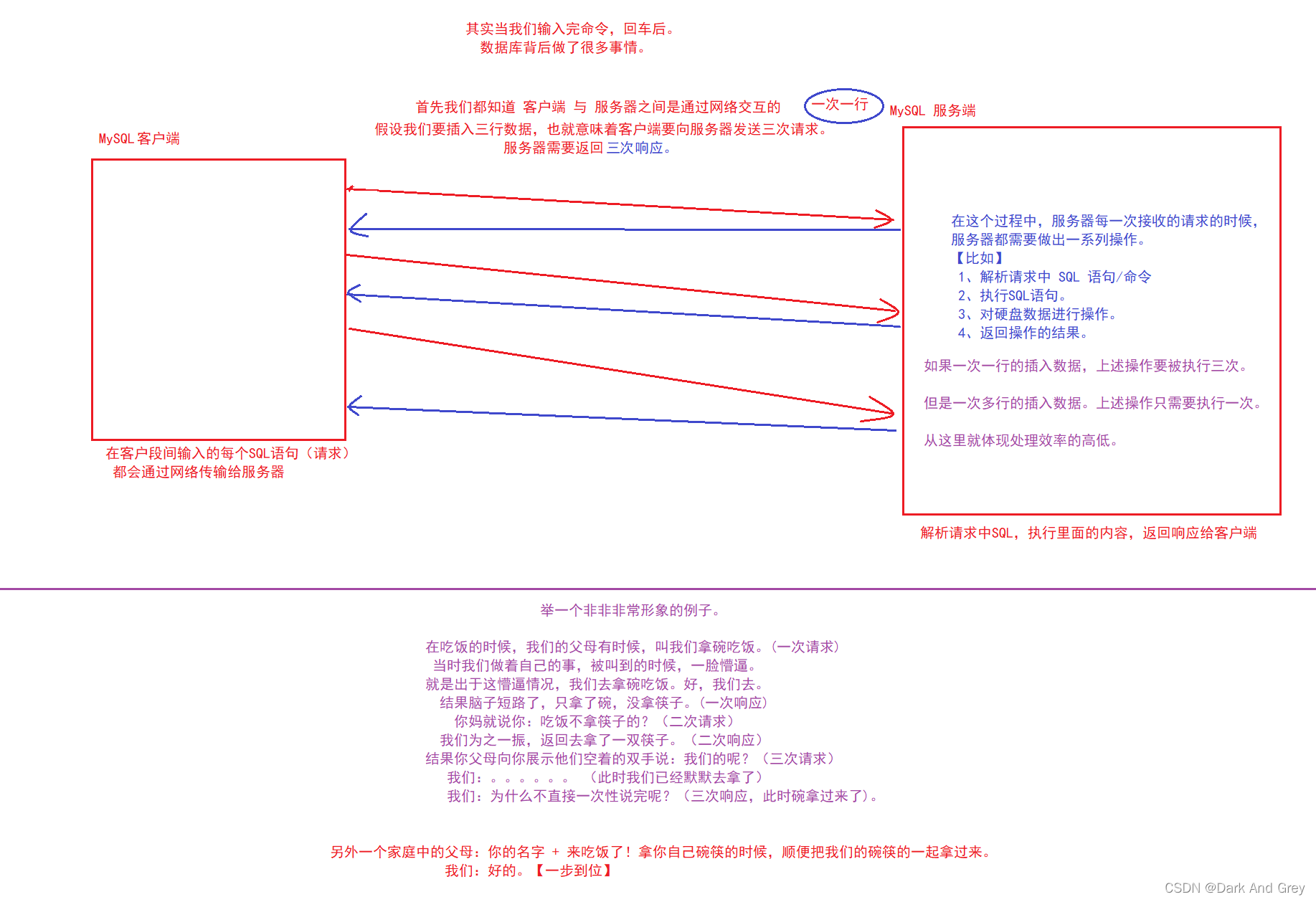
Doubtful moment: when inserting N rows of data, insert insert command: inserting one row at a time (need to insert N times) and inserting multiple rows of data at a time, is there any difference?
First of all, from the data point of view, if two rows of equal data are inserted at the same time, and the operations of inserting one row at a time and inserting multiple rows of data at one time are performed respectively, there will be no difference in the stored data between the two, which is the same.
However, from the perspective of the efficiency of inserting data, inserting multiple rows of data at a time is much higher than inserting one row of data at a time. [The speed of inserting data for multiple rows at a time is several times that of one row at a time]
Through the above analysis: we can easily understand that when the number of rows or columns is too large, the server will take longer to make the corresponding response (because there is a lot of data) ). You are inserting one row at a time, so this time efficiency is very low.
If we insert data in multiple rows at a time, in one step, then the server saves redundant responses and returns the total results at one time.
Time efficiency is greatly improved! ! !
Find statement (basic operation) - select keyword - key! ! ! ! ! ! ! !
We say "add, delete, check and change", but "add, delete and change" are very simple!
Only "check" is difficult.
Find statement is the most core and most complex operation in SQL statement/command .
Let’s put it this way: if we master the lookup statement, we can basically think that MySQL has cleared customs, and there will be no difficulties later.
1. The most basic search: full column search
Full column search: It is to directly find all the data of all columns and all rows in a data table!
Command format: select * from table name;
In MySQL, * is called "wildcard", which means all columns in a data table.
[The blogger just remembers: the concept of wildcards is involved in the syntax of Java's generics . The symbol is?]
can be understood in this way, * is equivalent to the universal wlan key, any wlan can be connected.
It's just that * matches columns/fields.
In order to facilitate the later function demonstration, please create the data table as shown below, and insert the input into the data table.
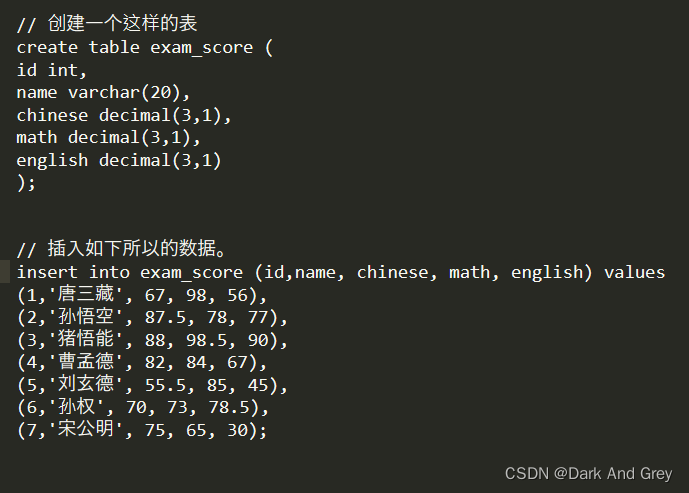
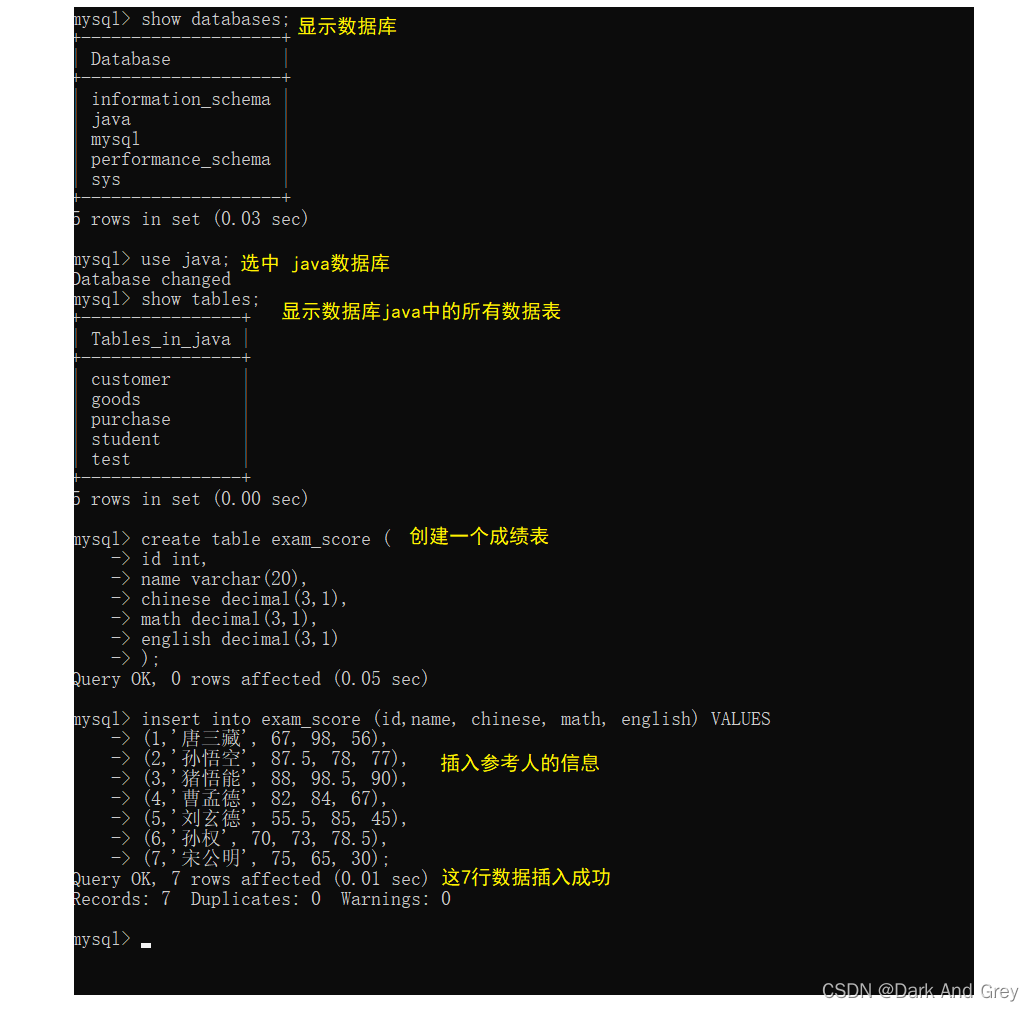
renderings
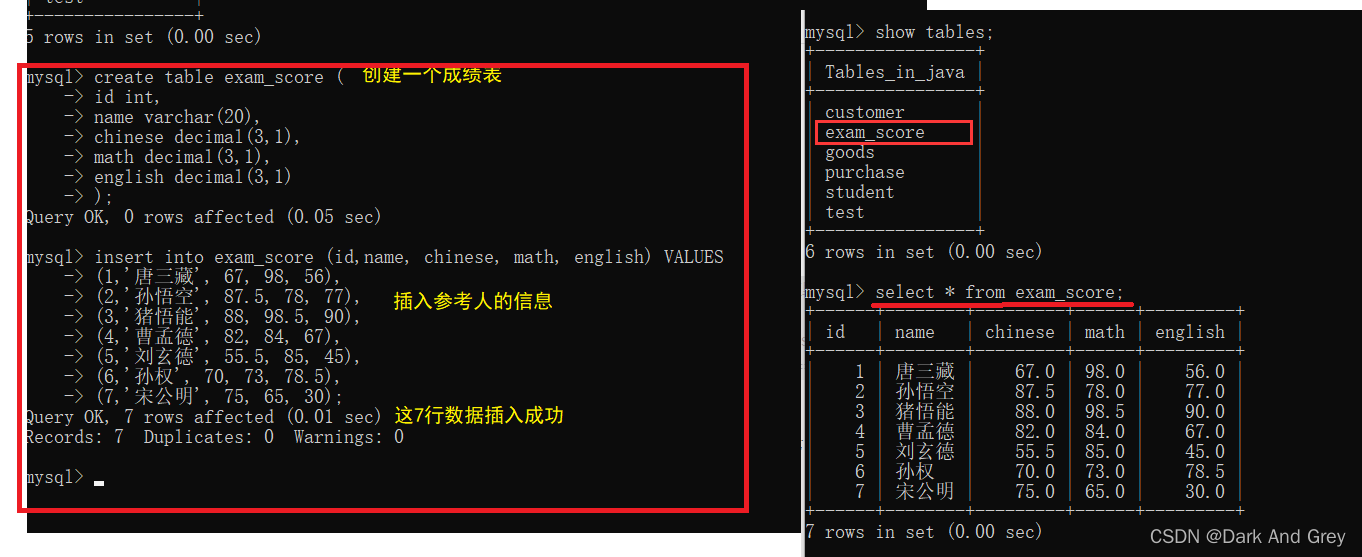
Through the full-column search sensitivity of the select keyword, all the data of all rows and columns in a table can be found.
The results of the search are presented in the form of a table, pay attention! This table is a "temporary table" .
Why do you say that the printed table is a temporary table?
This is because we all know that database tables are stored on the hard disk.
The principle is that when the server receives the "request" from the client, it searches for the data, and sends the found data to the client (the data is still unchanged on the hard disk, you can understand that the client copied this "response"), The client then "receives the response", parses it, and displays it (the data is operated on the memory at this time). After the display, the space for storing the data in the memory is released.
Note! During the operation, There is no change on the hard disk, because the client's operation data at this time is only a copy of the data, which is a one-time consumable.
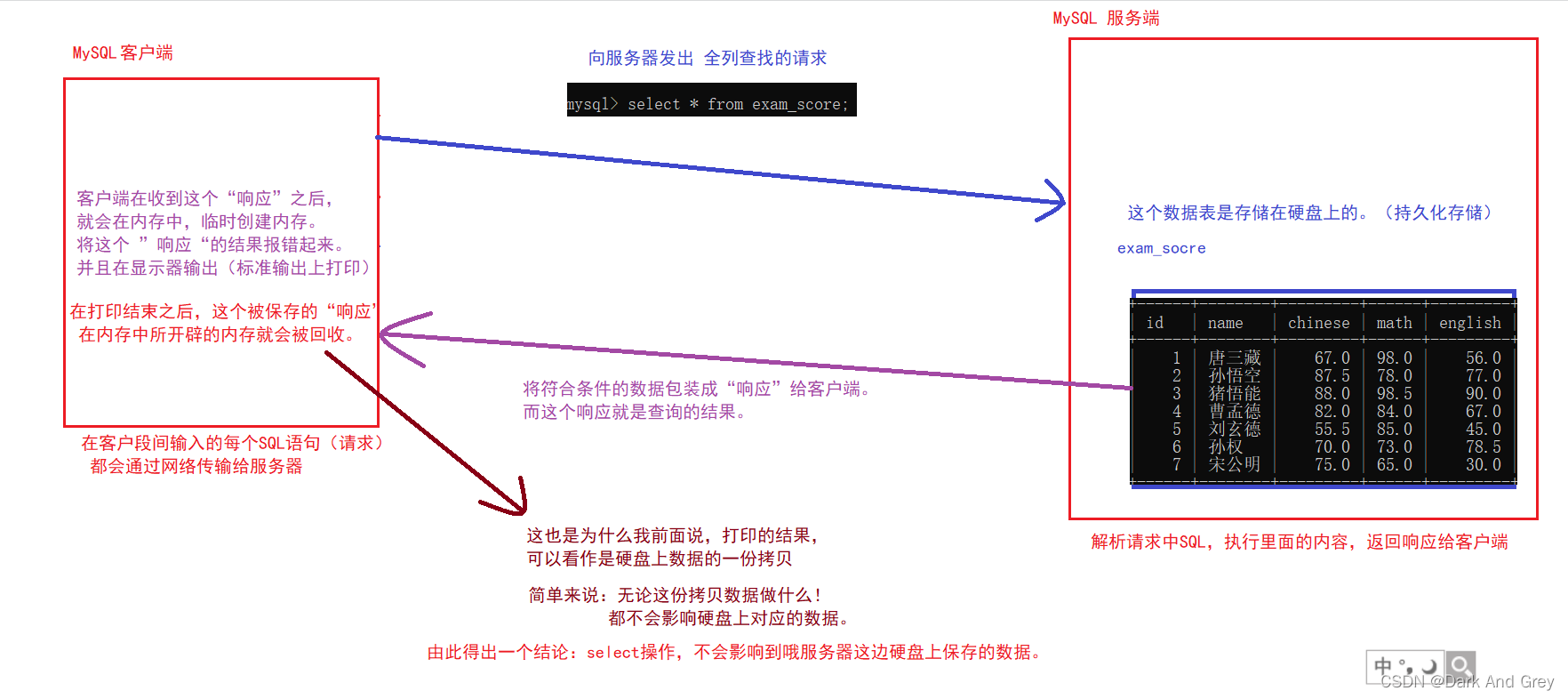
Extension: select * from table name; this operation is actually a dangerous operation!
为什么说 select * from 表名; 是一个危险操作?
理由很简单,我们 上篇博客讲了 “环境”的配置。你可以想象一下:如果是生产环境中的数据,少说也有几个T吧,你这条SQL通过网络发送 服务器,服务器接收到请求就会开始操作起来。
由于数据量庞大,服务器疯狂读取硬盘的数据,而一个机械硬盘的读取速度也就是几百兆左右,也就是说会把硬盘的IO 瞬间吃满,同时MySQL服务器又会立即返回找到数据作为响应给客户端。
【注意MySQL服务器 是找到符合条件的数据,就将其返回。不是说全部找到后,打包给客户端。】
因为 客户端 与 服务器是通过网络来交互的,再结合上面所述:服务器返回数据量也是非常大的。
这就会造成另外一个结果:把你的网速吃干净。专业术语来说:把网卡的带宽吃满。
【网卡的访问速度跟机械硬盘差不多。好的网卡 上 万兆的都有,比如王思聪家的电脑。但是呢,数据量还是很大的】
简单来说:对生存环境的数据,进行select * from 表名; 这个操作,我们的硬盘和 网卡都会被瞬间吃满,导致服务器卡死(繁忙),此时如果有客户想提出的任何“请求”,或者只是想链接服务器,服务器都没有那个时间去处理。
这就跟 LOL 战斗之夜的一区艾欧里亚 登录排队是一个效果。每一个人的账号数据都存储在服务器中。登进去肯定是要访问自己的账号信息的,但是呢,登录的人是在太多,服务器需要处理很多的数据,此时别说玩,你连登录都是一个问题。
得出结论:一旦 服务器的硬盘和网络被吃满,此时我们的数据库服务器就难以对其它客户端的请求作出响应。
而生产环境的服务器,无时不刻要向 普通用户提供响应。这就导致客户进不去,或者说网络不响应,再者就是响应时间太长等问题。
简称: 数据库累成“狗”。
为了预防这种情况的发生。
在实际开发中,一般公司都会对 SQL 的执行时间做出监控
一旦发现出现了这种长时间执行的 ‘慢SQL’,就会强制终止这个SQL 语句的运行,并删除它。
总之:在以后工作的时候,用之前先掂量掂量,以免对公司实施毁灭性打击。同时也是对你自己的毁灭性打击。
2、指定列查询 : 只查询自己想要的那一列数据
命令格式:select 列名,列名… from 表名;
查询的时候,显式的告诉数据库要查的是那些列。
数据库就会针对性的进行返回数据。(返回的结果,还是一个 “临时表”)
简单再说明一下临时表: 在客户端内存上临时保存一个数据表,随着打印的进行,内存就会被释放。
临时表的结果对于数据库服务器中的原始数据没有任何影响。
不要看了下面的结果,就认为改动了原始的数据。
相比于前面的全列查找,这种指定列查询就要高效很多,
后面在工作中接触数据库中,一个表至少有十几列都是很正常的,这种 指定列查询 不仅效率高,涉及到数据传输量不是很大。
因此,,这种 指定列查询 操作,在以后的开发中是会经常用到的。

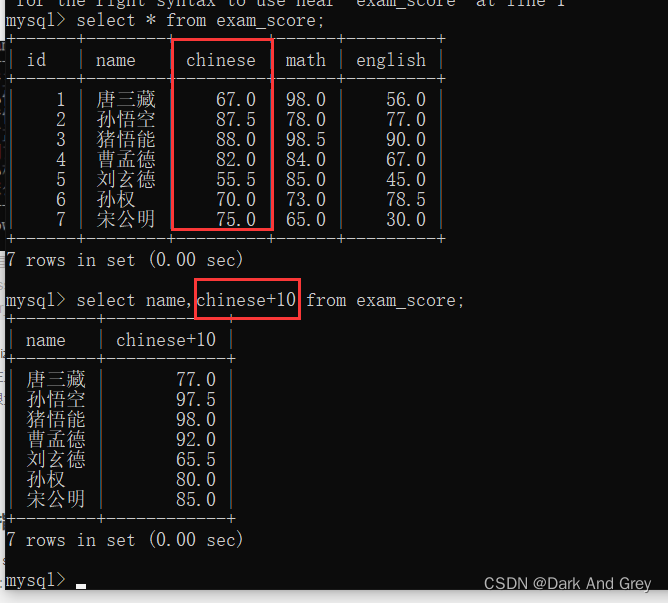
3、指定查询字段为表达式
在查询的时候,同时进行一些运算操作(列与列之间)
例如:考试结束之后,我们预估语文成绩 比实际成绩高10分。
命令格式:select 列名表达式,列名表达式… from 表名
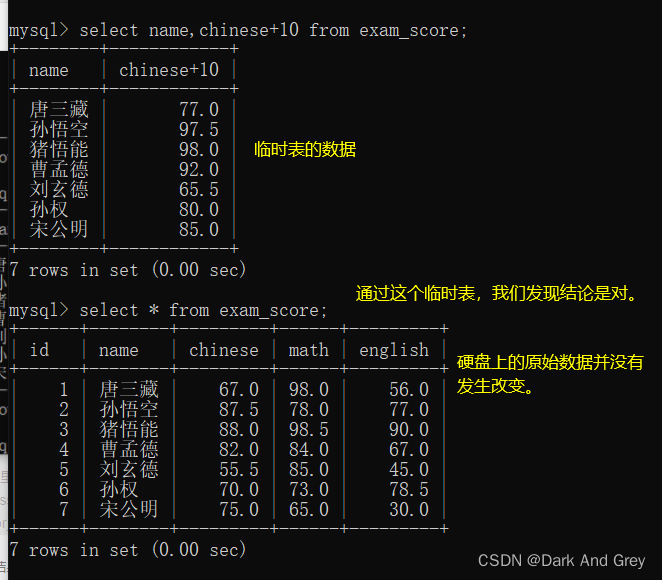
这个结果还是一个临时表,意思就是 硬盘上原始数据并没有改变。改变只是临时表中的数据。
再次强调: select关键字的操作,不会影响到硬盘上的原始数据。
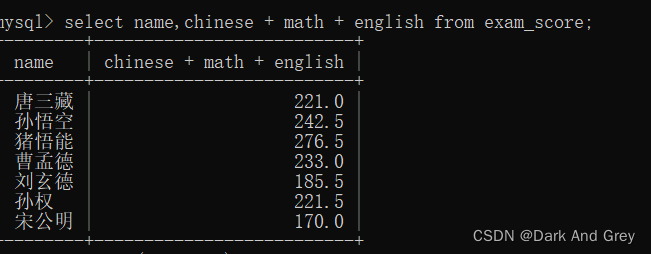
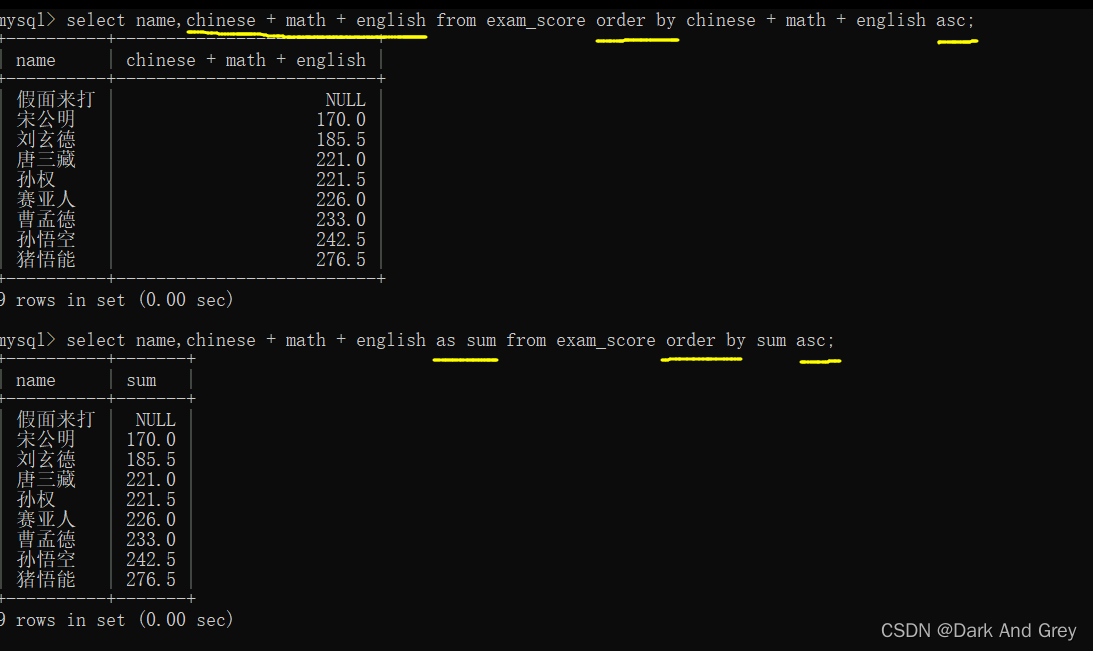
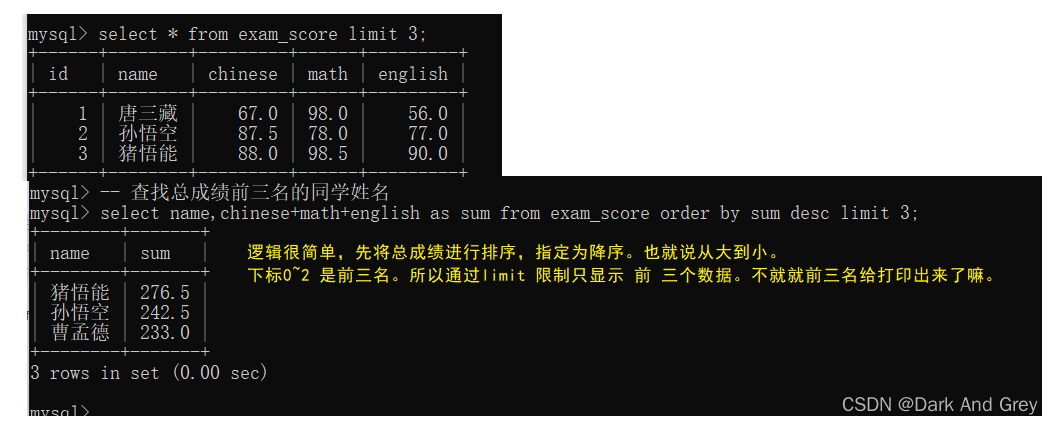
现在我们再练习一个例子,要求这些 “同学“的总成绩
但是,这里面还存在一些细节问题。来看下面
上述操作,都是针对 一列或者多列来进行的运算操作。
也就是针对指定的列中每一行的数据都进行相同的运算。
代入例子中:指定 语数外 三列的成绩相加,也就是将 每一行“同学”的 三列成绩相加。
行与行之间,数据互不影响。【你算你的,我算我的】
另外, 指定查询字段为表达式 的 运算方式,各种算术运算方式都是可以。
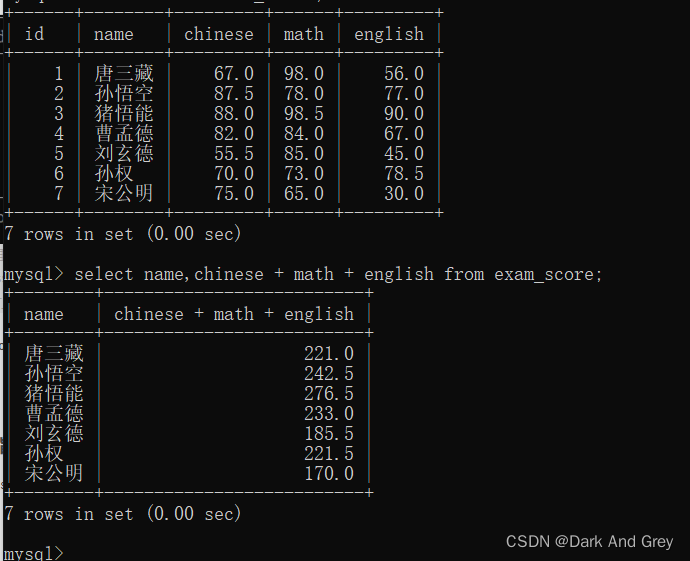
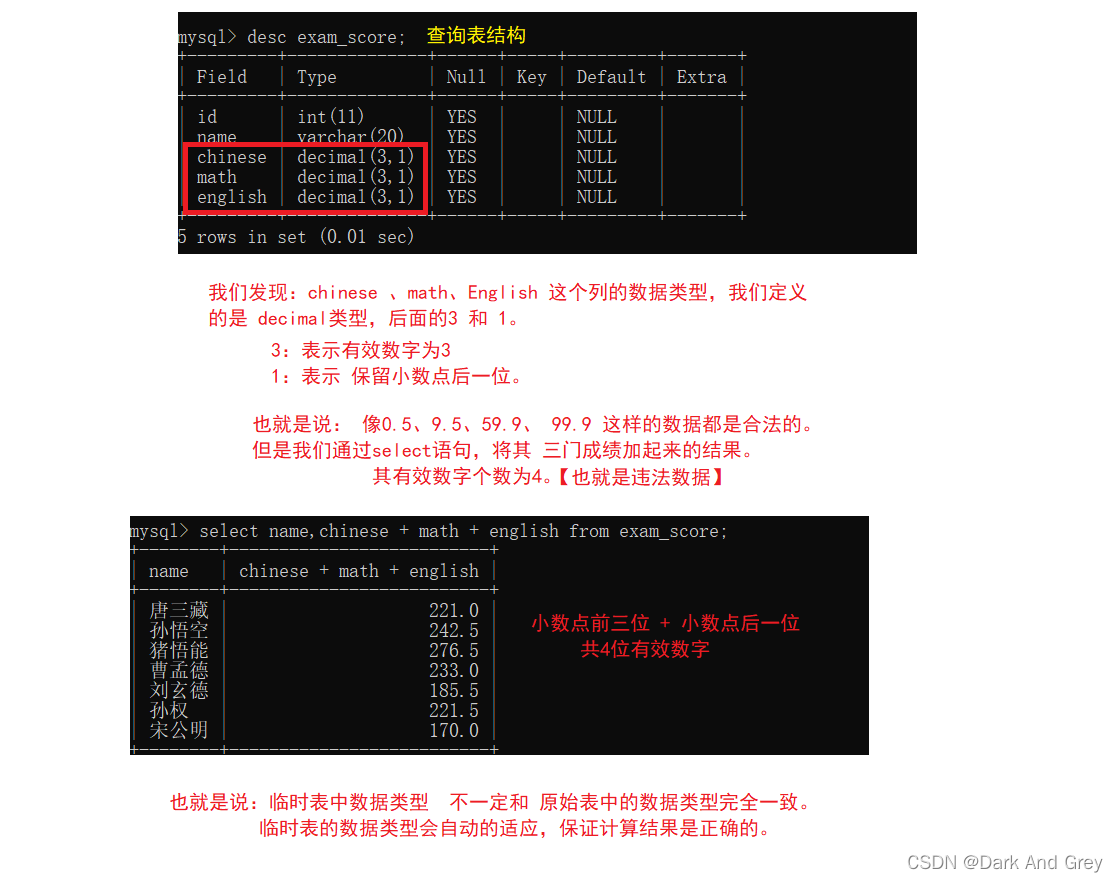
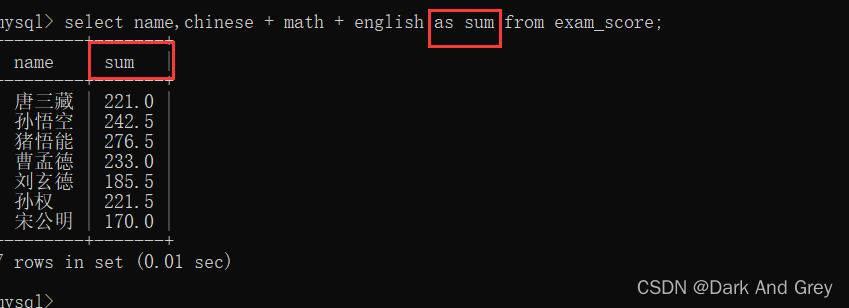
4、别名(关键字 as):指定查询字段为表达式,给表达式取个名字
前面计算总分的时候, 打印出的临时表,总分的表头名很长。
于是乎,我们就想:能不能给这个表达式换个名字,让打印出临时表看起来更舒服一些~
故,便有了别名(关键字为 as)。
它的语法格式:select 字段表达式 as 新名字 from表名;
另外,注意一点: as 是可省略的(表达式 与 别名 之间用空格隔开)。打印效果是一样的,但是代码的阅读性不高。
【ps:不要搞事情,说不写就不写。一个优秀程序员,不是说他的代码不是写得多好,多精简!而是看他代码的可读性高不高!!!!】
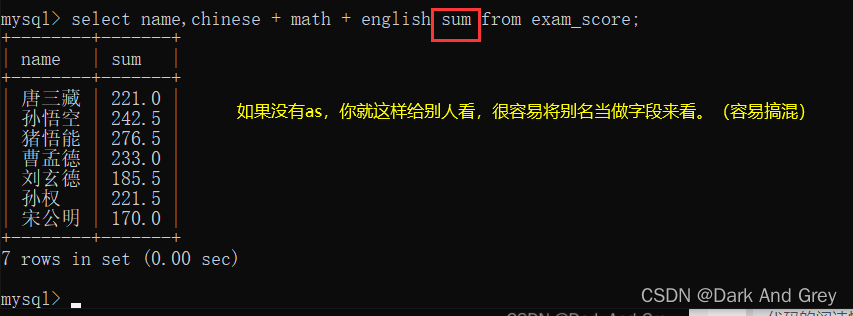
5、针对查重结果 去重 - 关键字 distinct
j针对查询的结果,把重复的记录去掉。【相同的数据,只能存在一个】
语法格式:select distinct 指定的列名 from 表名;
注意!如果是针对多个列来进行去重(上面是对单列进行去重),去重的条件:多个列的值都相同的时候,才视为重复。
你可以这么理解:多列去重的时候,执行去重操作的话。每个列直接就剩一个元素。
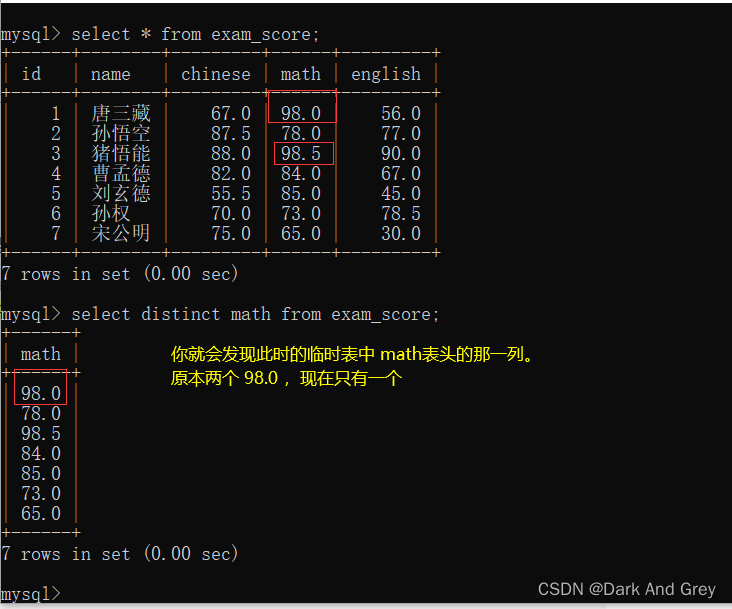

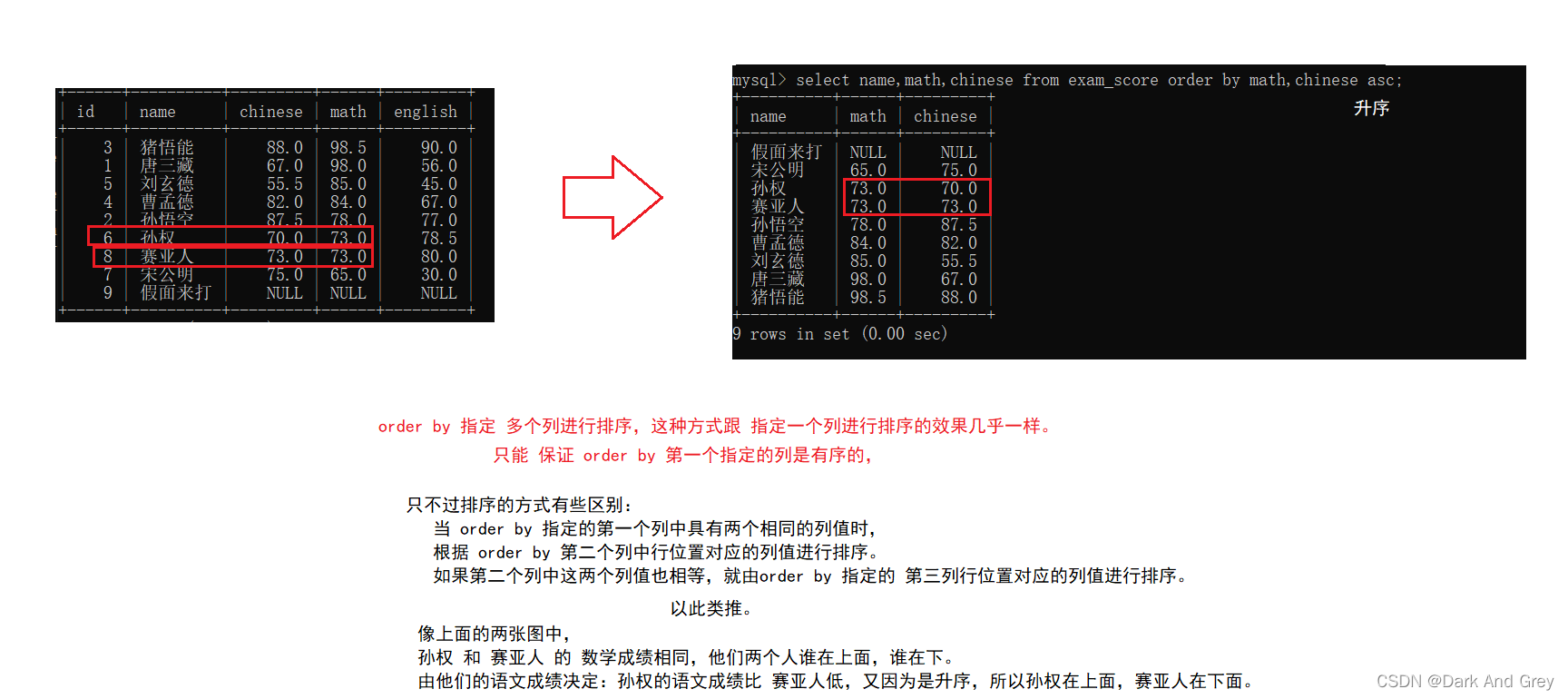
6、排序 :关键字(order by)
这里的排序针对于 查询的结果(临时表)进行排序。【不会影响到数据库服务器上的原始数据。说白了就是不会影响硬盘上的原始数据】
命令格式:select 列名… from 表名 order by 列名 asc(升序) / desc(降序);
意思就是:select选择的列,根据 order by 后面指定列,它的排序方式(sac/desc),进行排序移动。
其结果:就是 order by 后面指定列有序,其他列的数据不一定。
也就是说: order by 这种排序,只能保证至少一列有序。
但是!像数据库查询的结果,如果不去指定排序,此时查询结果的顺序是不可预期的。
【对应的情况是:指定的列中的 列值全部为相同的时候,无法确定谁在上,谁在下】
简单来说就是不要太过于依赖默认的顺序。

细节拓展
当指定排序的列中,含有NULL
有的数据库记录中是带有NULL值得,像这样的 NULL 认为是最小的(升序在最上面,降序在最下面)
【小拓展: NULL 和其他值进行运算,其结果还是 NULL,NULL 可以看作最小值,但和零没关系】
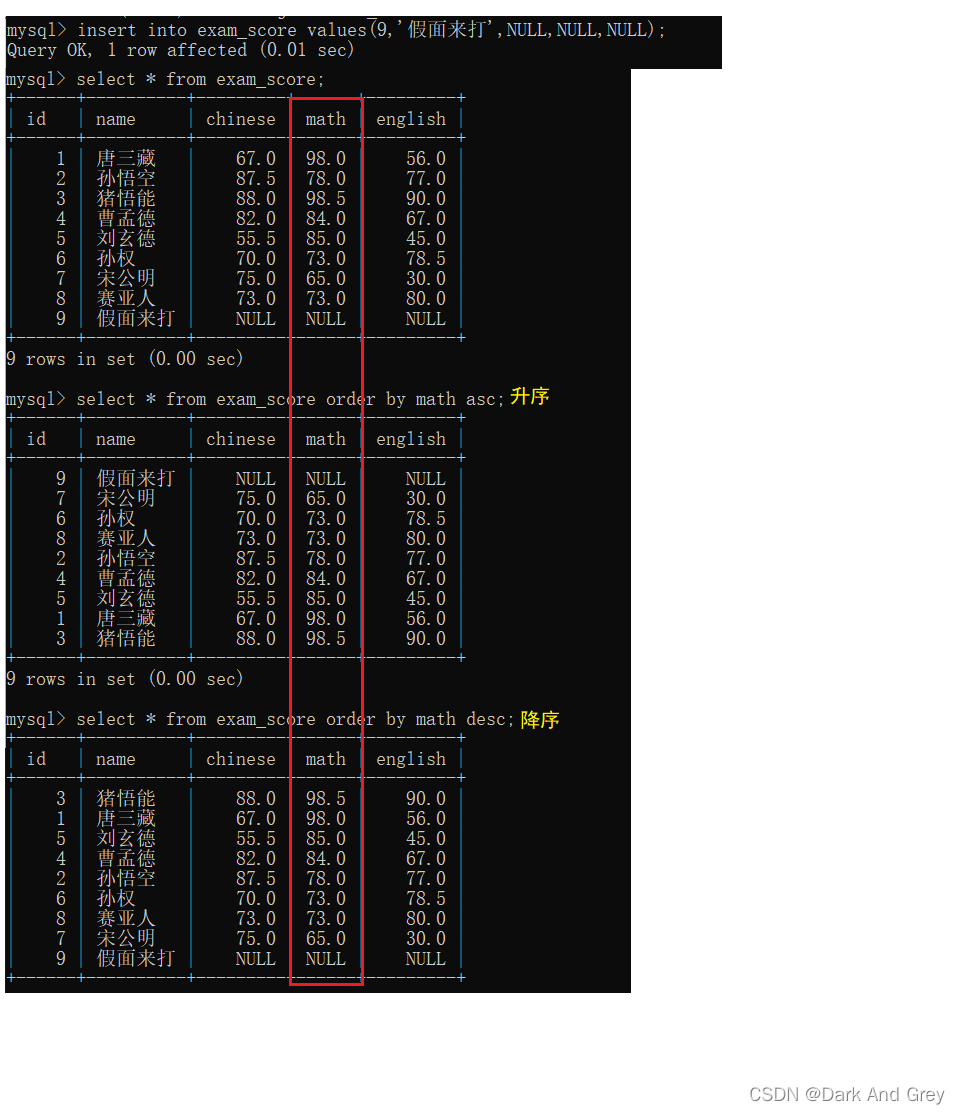
排序也可以依靠表达式或者别名来进行排序
下面我们就以总成绩来进行排序(下面演示升序,降序就没必要了,就把 asc 改成 desc就行了)
排序也可以字符串类型数据库
在创建数据库:可以指定数据字符集的校验规则【命令:collate 校验规则;】
校验规则:描述字符之间的比较关系。
比如 英文之间的比较,忽略大小写,那么这个时候就不是按照字典序进行排序的。
而且字典序只是针对英文,如果你拿个中文,就没有什么作用。
而且 字符集有很多种,并不一定就是字典序。
所以说 字符串类型的数据,排是可以排序的,但不一定是字典序。
话说回来:用字符串去排序还是很少的。主要还是用数字去排序
所以,这里只要了解就行了,就不做过多的讲解。
order by 可以 指定 多个列进行排序
先根据第一个列进行排序,如果第一个列结果相同,相同结果之间再通过第二个排序,以此类推
命令格式:select 列名,列名… from 表名 order by 列名,列名;
指定多个列的目的:就是为了避免指定一个列时,如果这个列中所有的列值都是相同的,那么彼此之间的顺序是无法确定的。
如果指定了多个列的时候,还可以根据其它列的数值进行排序。从而就能预期到彼此之间的顺序。
知识铺垫 - 为select 的 第七种操作铺垫
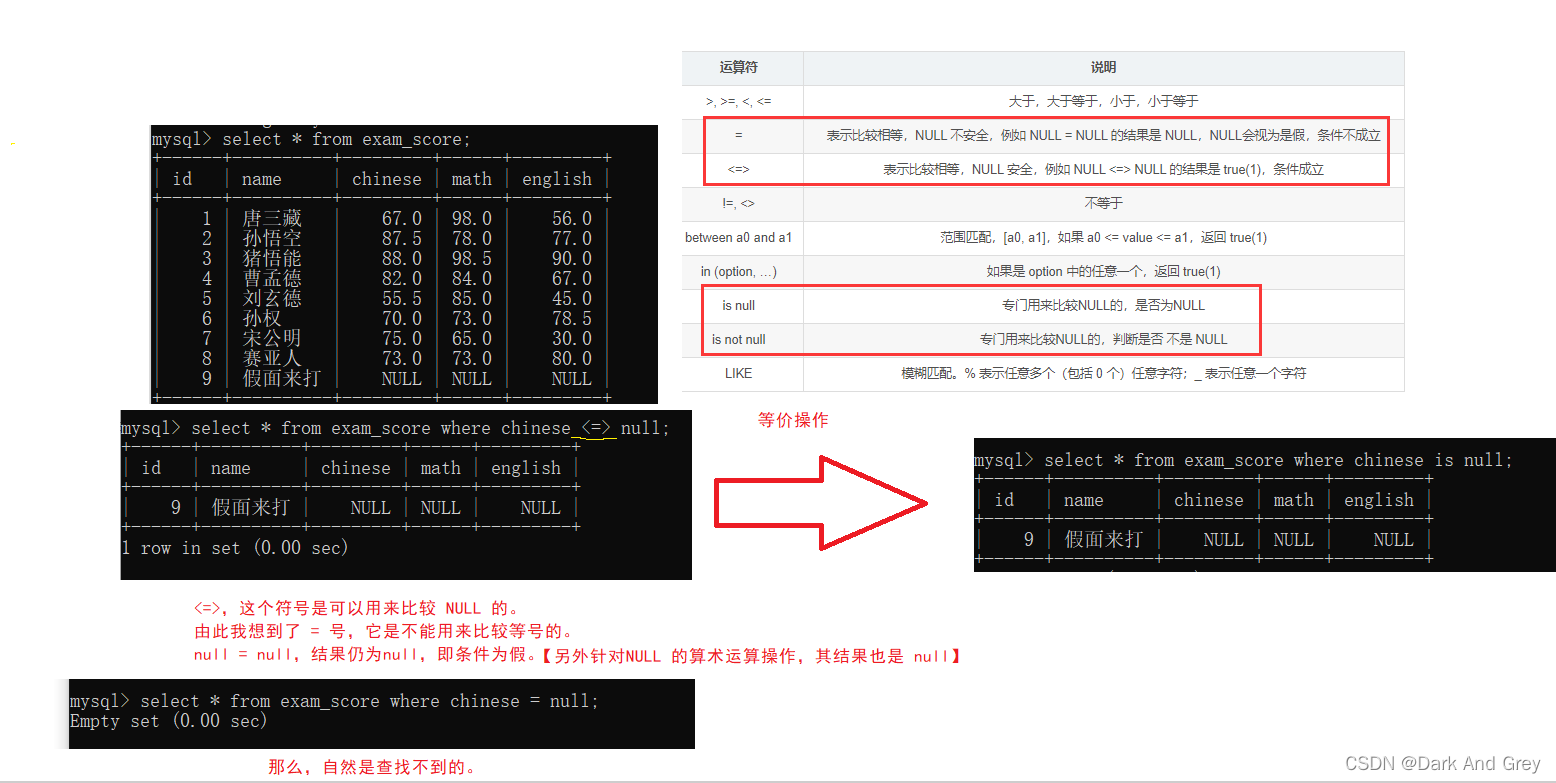
比较运算符
| 运算符 | 说明 |
|---|---|
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 表示比较相等,NULL 不安全,例如 NULL = NULL 的结果是 NULL,NULL会视为是假,条件不成立 |
| <=> | 表示比较相等,NULL 安全,例如 NULL <=> NULL 的结果是 true(1),条件成立 |
| !=, <> | 不等于 |
| between a0 and a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 true(1) |
| in (option, …) | 如果是 option 中的任意一个,返回 true(1) |
| is null | 专门用来比较NULL的,是否为NULL |
| is not null | 专门用来比较NULL的,判断是否 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
逻辑运算符
| 运算符 | 说明 |
|---|---|
| and (逻辑与 &&) | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| or (逻辑或 双竖线) | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| not(逻辑非 !) | 条件为 TRUE(1),结果为 FALSE(0) |
注意:
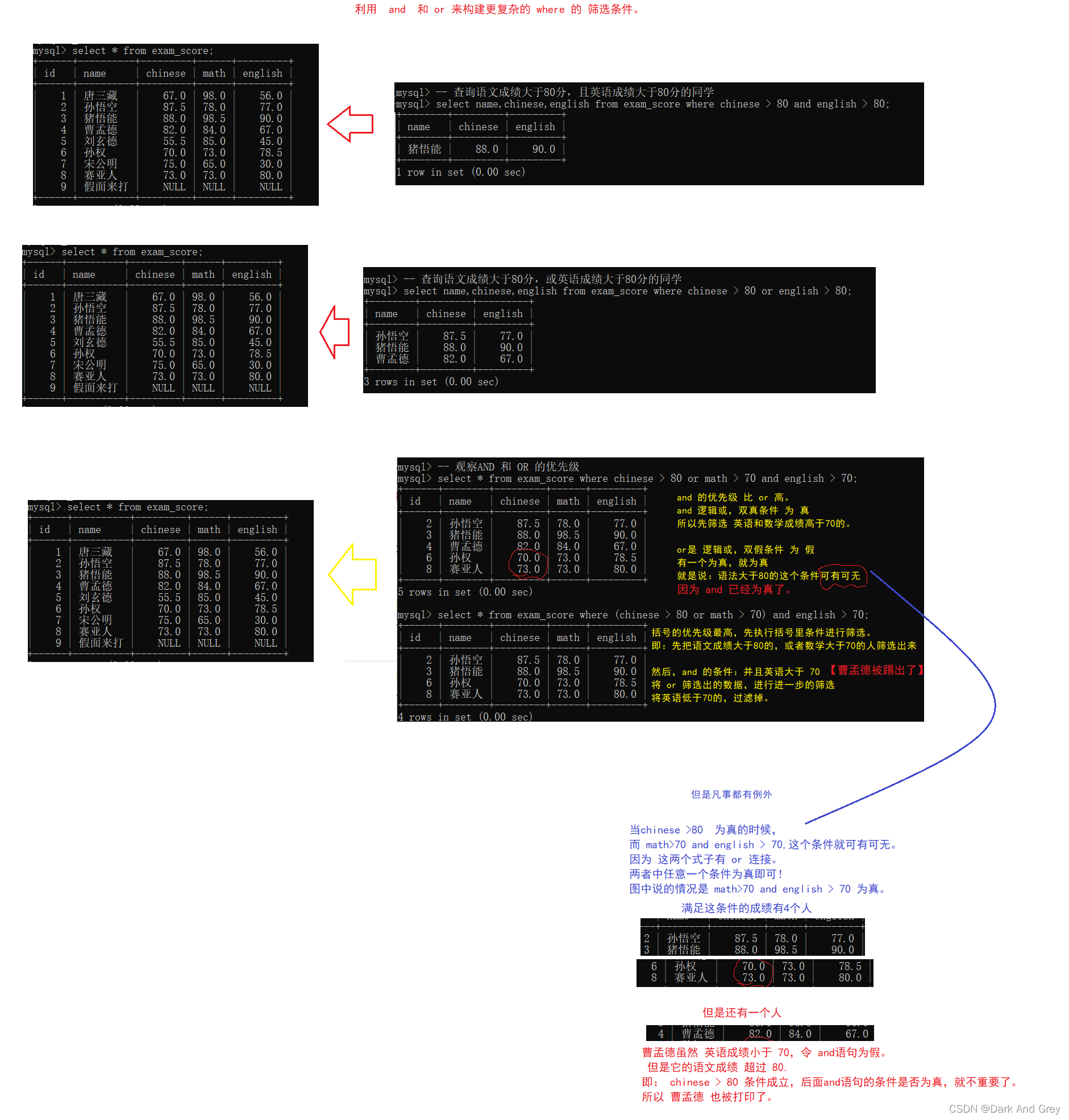
1、where条件可以使用表达式,但不能使用别名。
2、 and的优先级高于or,在同时使用时,需要使用小括号()包裹优先执行的部分
7、select 中的 条件查询:关键字 where
在 select 查询语句的后面加上一个 where 语句,后面跟上一个具体的筛选条件。
命令格式:select 列名,列名… from 表名 where 筛选条件;
作用:把查询结果中满足筛选条件的记录保留,把不满足筛选条件的记录给过滤掉。
基本查询

and与or
范围查询 : between and + in
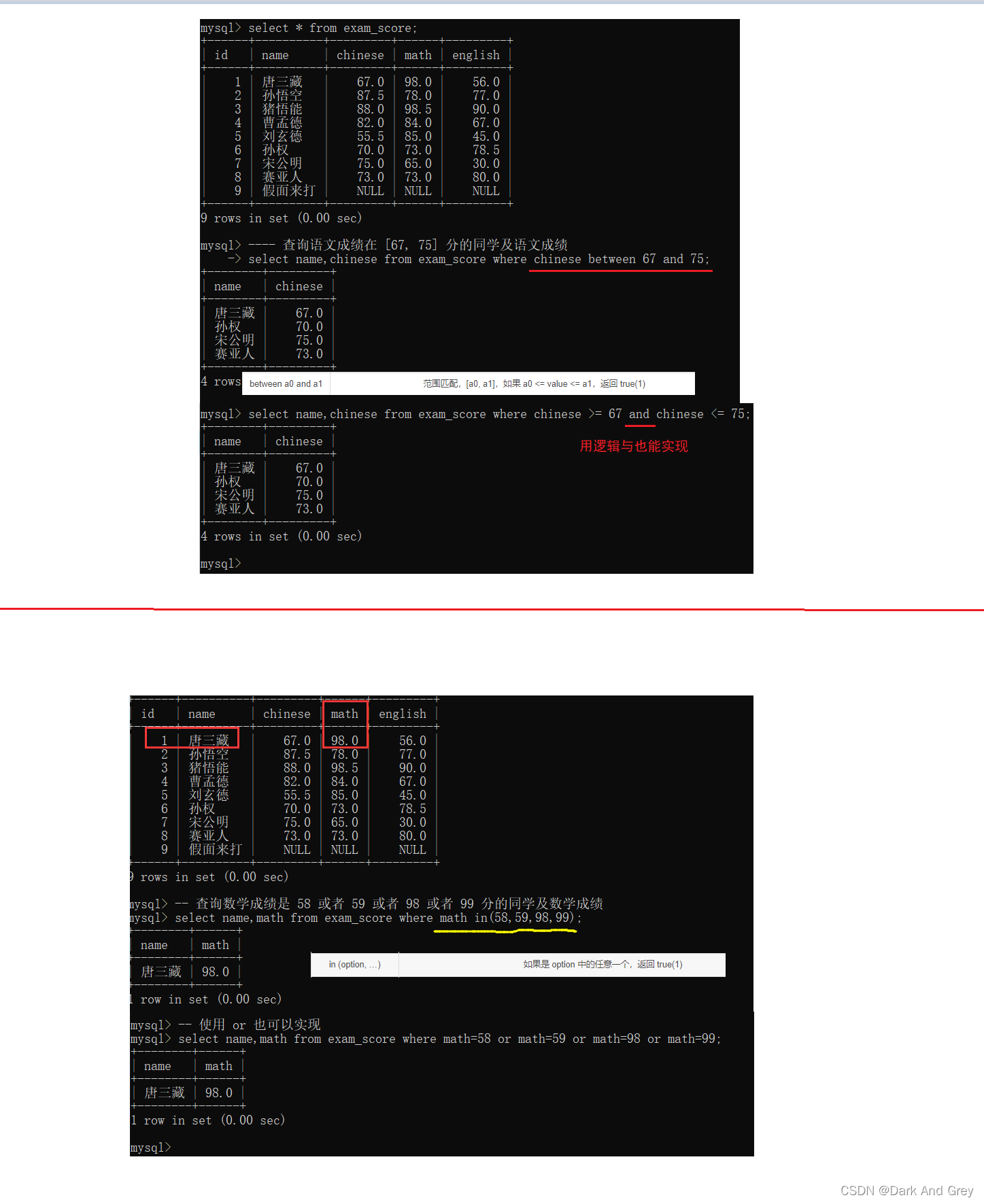
小拓展:MySQL的 between a0 and a1 算是不常见的 闭区间 语法。其他大部分语言都是 左闭右开的区间,比如java的 substring,还有在java的底层代码中,只要见到 form to 这样的字样,就是 左闭右开的区间。

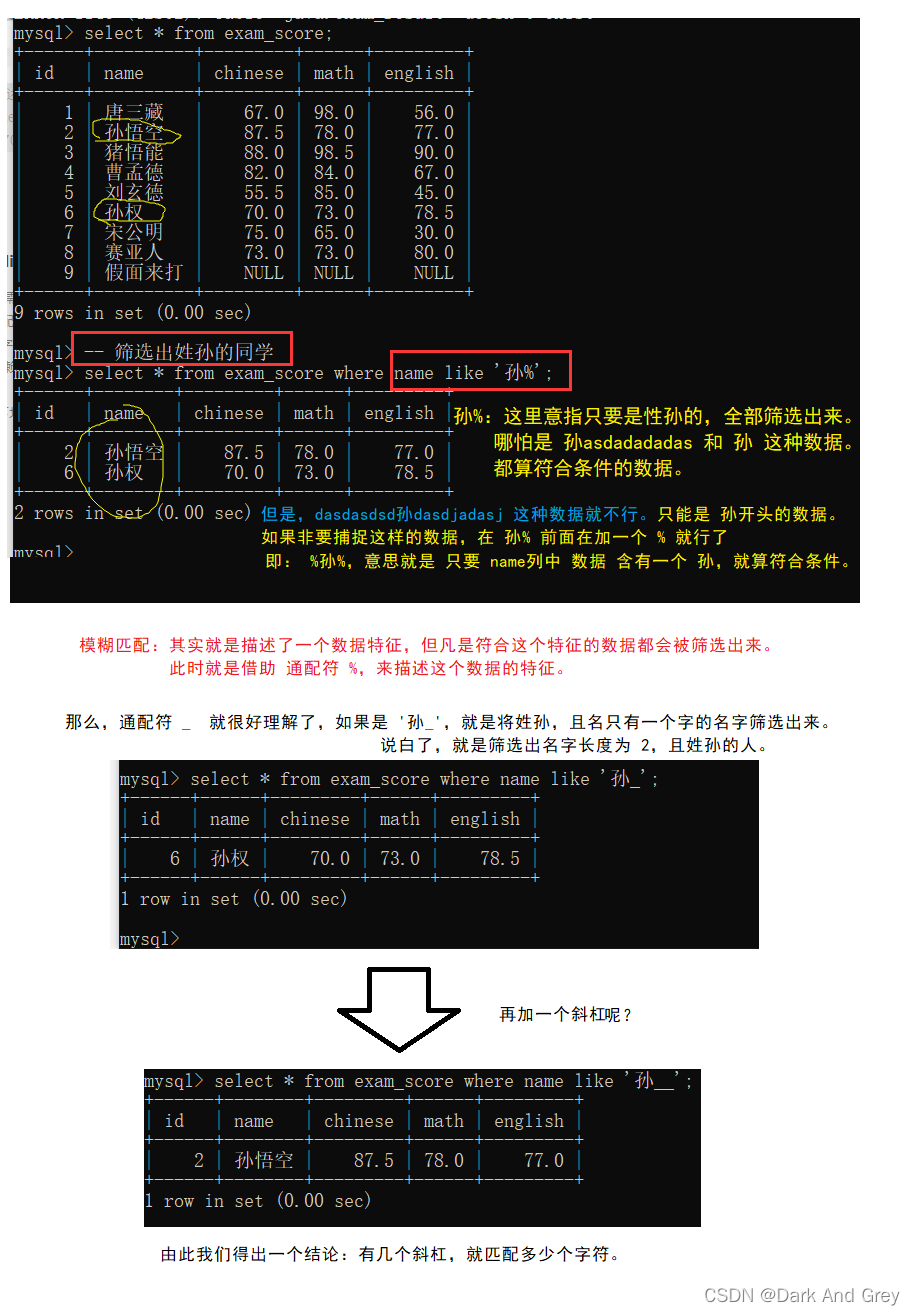
模糊查询:like
like,需要搭配通配符来使用:只需要对方的字符串符合你此处描述的一个形式就ok
这里like使用的通配符有两种 : % 和 _
%: 代表 任意个字符【任意个:大小不做限制,可以是很大或者很小的数。包括0】,且每个字符又可以表示为任意字符(就是打牌中赖子一样,可以将它当做任意一张牌)。
_ :下划线它只能代表一个字符,但是这一个字符是“赖子”,即:可以表示任意字符。
还记得查看字符集的指令吗?
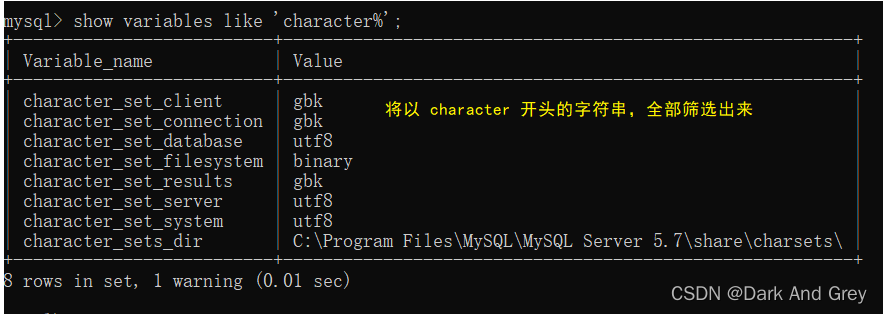
命令格式 :show variables like ‘character%’;
这里其实就是使用了通配符。
如果抛开 SQL,站在更广的角度来看待 通配符体系。编程中还有一个东西叫做“正则表达式”,提供l更多的特殊符号来描述一个字符串的规则/特征。【别问我,我不会。】
查询语句中,和NULL 进行比较
8、分页查询:关键字 limit
分页查询,其实在我们的生活中很常见,比如我们浏览器 搜索资料,它的搜索结果会有很多。
网页呢,会帮我们进行分页。让我们一页一页去翻。这里其实就是运用分页查询。
至于为什么要使用分页查找,是因为如果我们一股脑将数据去不放入一张网页中,由于数据量很大,传输很慢,页面加载速度降低,网速也会被吃很多。
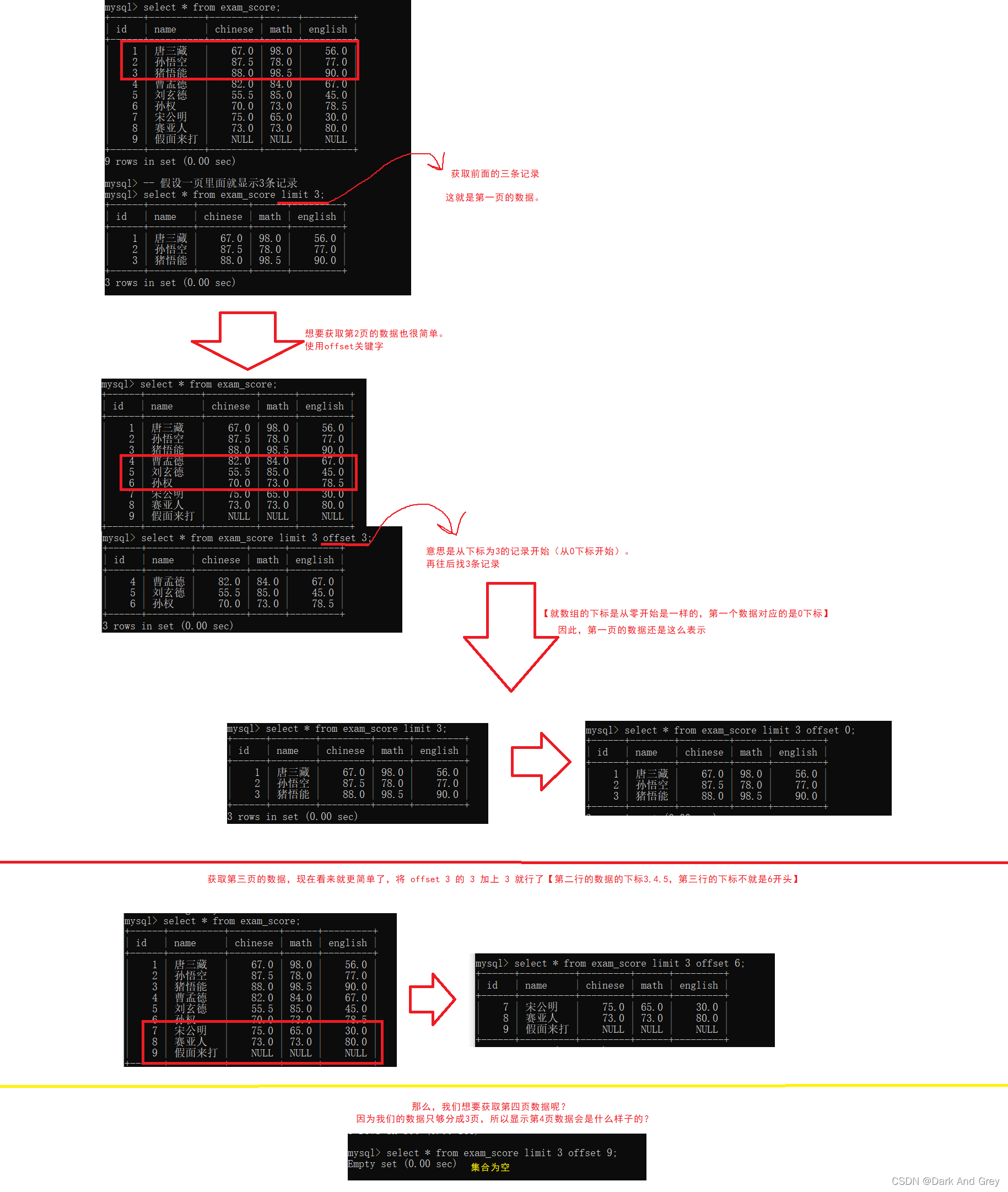
分页查询:就是为了避免这种情况,将数据分割N页,一页中最多显示 k 个结果。
在进行查找的时候,就按照一页的数据量进行返回。
【比如说:一页显示20条记录,第1页:1~20、第二页21 ~40。。。。。。】
这样就提升了网页的加载速度 和 数据量的传输量。
在sql 中可以通过limit来实现分页查询,
limit 同样可以搭配条件,以及 order by 等操作来组合使用。
limit还有一个非常重要的作用。
前面说到 select * from 表名; 这个操作对生产环境的数据库很危险!
但是,有的人呢可能就会疑惑:难道那些指定列 和 列的表达式,还有 排序、条件等操作就不危险了吗?
危不危险 是根据操作指令返回的数据量来决定的。
如果返回的数据量很大,那么这个操作就是危险的,反之,则是安全的操作。
其实我们学习这么的操作指令,就是为避免危险操作。
1、select 指定需要的列数据,缩小数据范围。
2、然后,用严格的限制条件(where)来缩小数据量。,
3、再搭配使用limit,进一步限制数据量,实现更稳妥的操作。
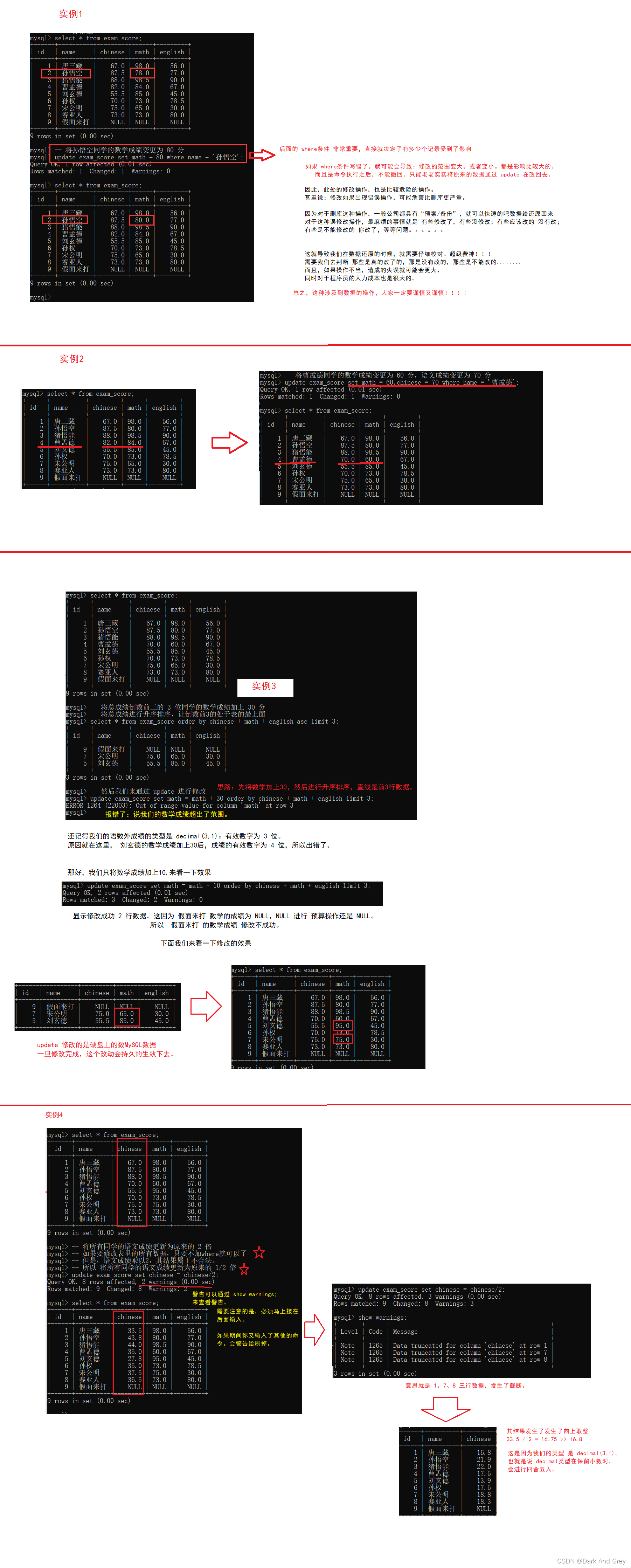
修改:关键字 update
命令格式 update 表名 set 列名 = 值,列名 = 值,列名 = 值… where 条件;
where condition: plays the role of filtering data, in simple terms: when we update data, it is rarely the case that the whole data is updated, but only part of the content is updated.
where is used to handle this situation, to filter the data that needs to be changed.
where condition; mainly for those rows to be modified, the rows that meet the conditions will be modified, and vice versa.
But rest assured, the where condition here is the same as the where condition of the previous select.
This means that the operations mentioned above can be used in the update statement.
The only caveat is: updata will modify the original data on the database server! ! ! ! !
update will not behave like select. It is a real modification of the original data.
Modifying the statement is also a SQL commonly used in our daily development, and everyone must master it.
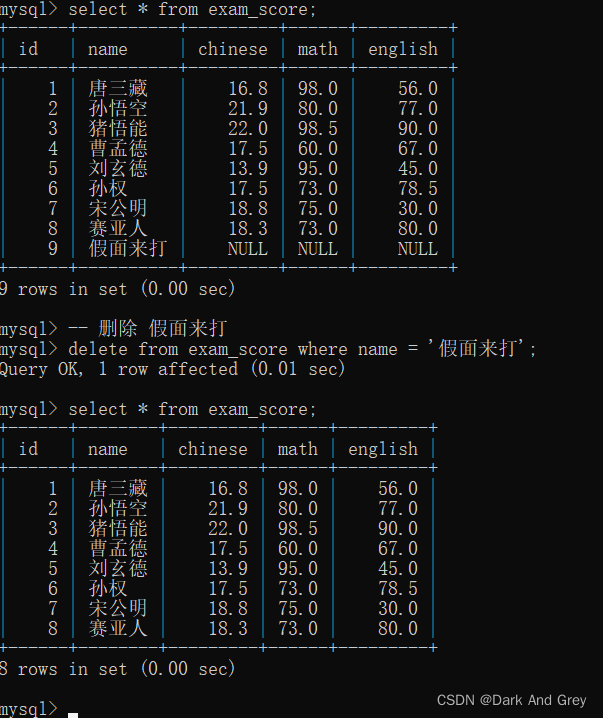
Delete
Syntax format: delete from table name where condition;
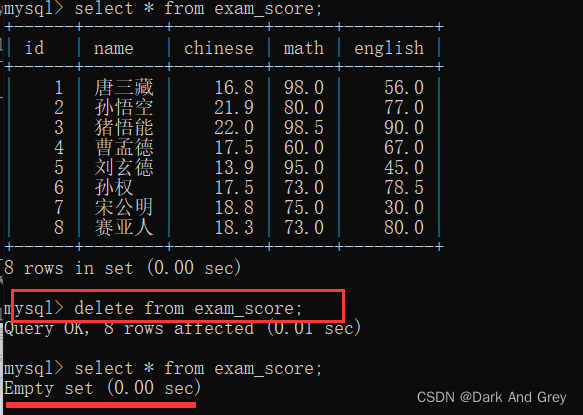
the delete operation of Haihui Temple is very dangerous. Once the condition here is written incorrectly, the scope of influence may be very large. If the condition is not written, the data of the entire table will be deleted. . (That is to say: delete statement, without where condition restrictions, will clear the data in the data table)
and drop table table name; is to delete the entire table.