1. Database constraints
1.1 Constraint objects
- not null - the column cannot be empty
- unique - ensures that each row of this column is unique
- default - specifies the default value when no value is assigned to the column (custom)
- The combination of primary key - not null and unique will add an index to the column to improve query speed.
- foreign key - ensures that data in one table matches data in another table
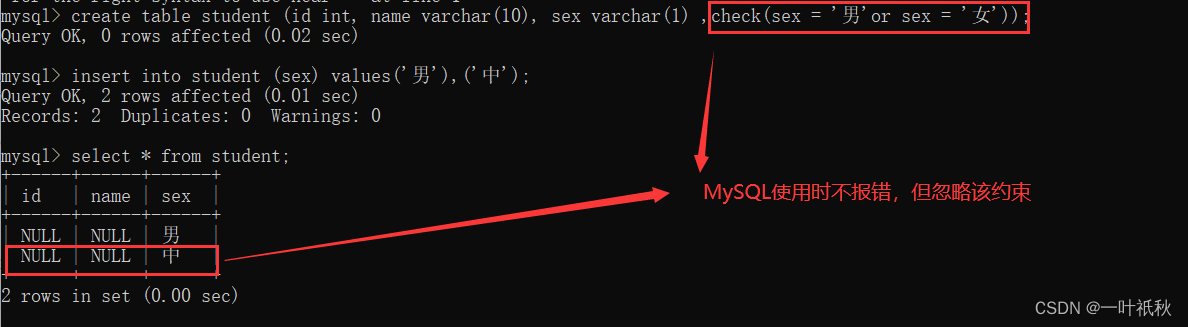
- check - ensures that the value in the column meets the specified conditions. For MySQL database, the check clause is stacked for analysis, but the check clause is ignored.
1.2 null constraints
When creating a table, specify that a column is not empty.

1.3 unique
Ensure that each value in this column is unique, that is, there are no duplicate values in this column.

1.4 default
If the column is not assigned a value, it will be assigned the value after default:

1.5 primary key - primary key constraints
The primary key has the characteristics of not null and unique at the same time, and can also be used with auto_increment (when the inserted field is not assigned a value, the maximum value + 1 is used, which is somewhat similar to the enumeration in JAVA).

Note: auto_increment can only be used on integer types! ! ! !
1.6 foreign key - foreign key constraints
Foreign keys are used to relate primary keys or unique keys of other tables. Syntax:
foreign key (field name) references main table (column name)

Indicates that class_id is linked to id. The added class_id must exist in id, otherwise the addition fails, that is, the child table must depend on the parent table. And the class table cannot be deleted separately. If you want to delete the class table, you must first delete the student table, because if you delete the class table first, then there will be no reference for the class_id column in the student table.
1.7 check constraints
MySQL does not report an error when used, but ignores the constraint
2. Table design
- One-to-one: Similar to a person and an ID number, a person can only have one ID number.
- One-to-many: Similar to classes and students, a class can have many students
- Many-to-many: similar to subjects and students and teachers

Three, add
insert into table name [column name....] select....

Four, query
4.1 Aggregation query
4.1.1 Aggregation functions
| function | illustrate |
| count ([distinct] column name) | Returns the quantity of queried data |
| sum ([distinct] column name) | Returns the sum of the queried data |
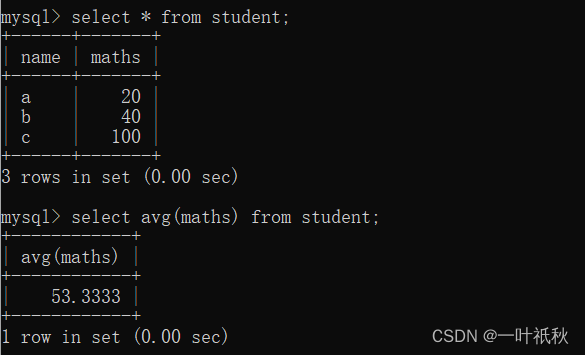
| avg ([distinct] column name) | Returns the average value of the queried data |
| max ([distinct] column name) | Returns the maximum value of the queried data |
| min ([distinct] column name) | Returns the minimum value of the queried data |
- count

Note: count(*) has the same effect as count(0)! ! !
- sum
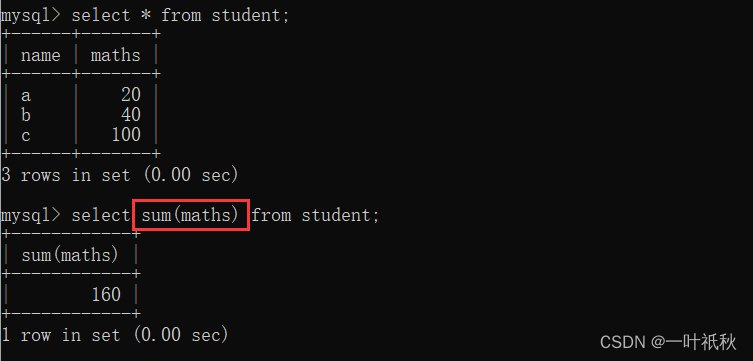
- avg
- max

- min

Note: When encountering null, the aggregate function will ignore it, that is, it will not allow null to be calculated! ! !
4.1.2 group by words
Grouping query: Group the data in the table according to columns. It must be used with aggregate functions. For example, group students in a class into one group.
select column1,sum(column2),...... from table group by column3...
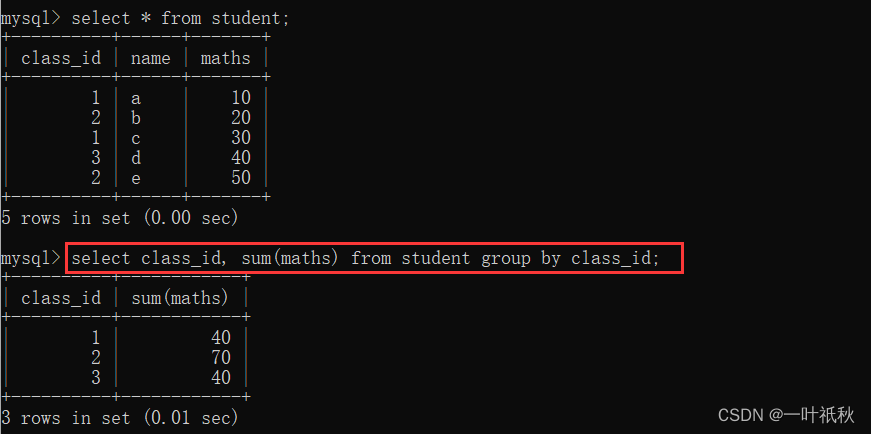
4.1.3 having
After grouping by the group by clause, when you need to conditionally filter the grouped results, you cannot use the where statement, but need to use having

4.2 Joint query
In actual development, the data we need often comes from different tables, so we need joint queries of multiple tables. To understand joint queries, we must first understand the Cartesian product. Simply put, it means arranging and combining multiple tables to form a new table. , and then filter out the content we want to find based on the relationship between tables (such as the relationship between primary key and foreign key mentioned before) and our needs. However, it should be noted that this operation is generally not used if possible, because the content to be searched is too large and will cause server congestion (of course, it will be fine if you try it in your own library, after all, there is not much data)
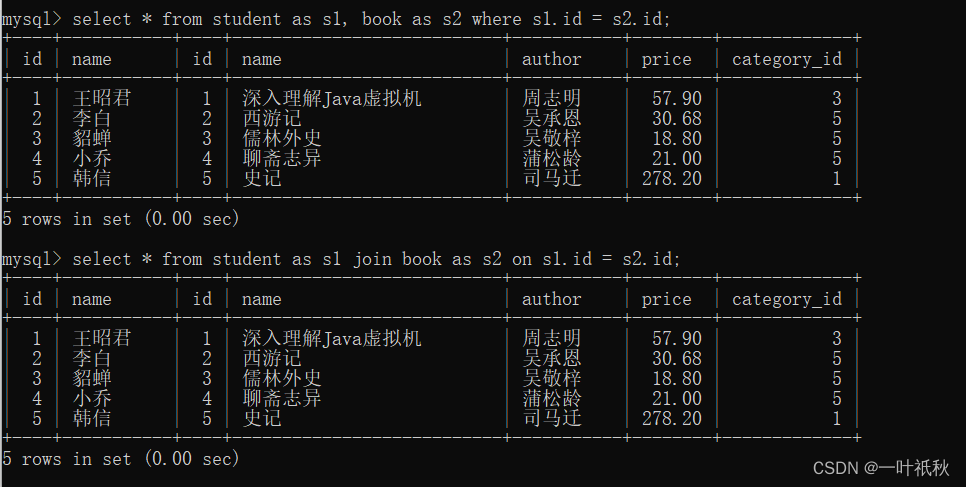
- inner join
Two ways of writing:
select column... from table 1 join table 2 on condition 1 and condition 2...;
select column... from table 1, table 2... where condition 1 and condition 2...;
//You can use aliases
- outer join
select column... from table 1 left/right join table 2 on condition 1 and condition 2...;

Draw a picture to see the difference between inner joins and outer joins:

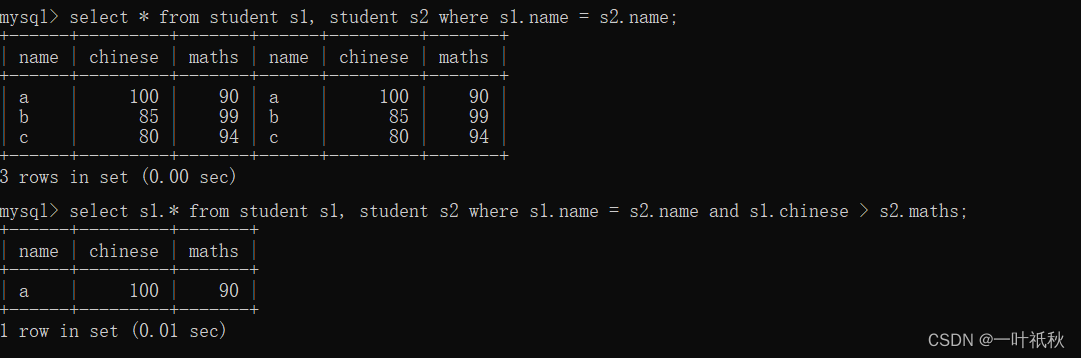
- self link
As the name suggests, it means that the same table is connected to itself for query
- subquery
To put it simply, select and select can be applied
For example:
select * from student where class_id = (select class from student where id in(1,2,3));
- merge query
In practical applications, in order to merge the execution results of multiple selects, you can use the set operators union and union all. When using union and union all, the fields in the result sets of the previous and subsequent queries need to be consistent.
For example:
select * from stduent where age < 20 union / union all select * from student where id < 10;
Union can automatically remove duplicates, while union all does not.