一步步的了解DOM的来龙去脉
文章目录
一:DOM的定义(Document Object Model)
DOM即文档对象模型,是W3C制定的标准接口规范,是一种处理HTML和XML文件的标准API
二:DOM的解析对象—XML和HTML文件
HTML被创出的原因是用来进行显示数据----所以它的标签形式更为固定
XML被创出的原因是用来进行传输数据----所以它的标签形式更为松散,随意
XML和HTML作为标记语言,它的标签和属性和元素是抽象的形式,不是机器能够读懂的,我们需要用DOM这个API对这两种文件解析成一定的形式,来获取里面所蕴含的具体的内容。
很巧的是,根据XML和HTML的子孙兄弟嵌套结构,我们刚好可以将其划分成树的结构以此来容易的获取标签的属性和内容。
PS:JSON因为它本身就是由类似对象的方式存储的,所以是通过一些公司提供的jar包直接进行解析成对象即可,因为XML使用DOM解析时需要考虑父子节点,而JSON解析成对象只需要考虑键值对和数组,相对来说更为便捷。
DOM解析需要将整个XML文件读入内存,因此很耗内存
因此XML还有另一种解析方式SAX解析,
SAX的设计初衷是不需要整个读入文档就可以对解析出的内容进行处理,是一种逐步解析的方法。程序也可以随时终止解析。
当然,到如今的优化程度,差别已然不大了。
三:DOM的解析原理(种类—常见类型—DOM树)
1.DOM解析种类
核心 DOM - 针对任何结构化文档的标准模型
XML DOM - 针对 XML 文档的标准模型
HTML DOM - 针对 HTML 文档的标准模型XML DOM
(1)°XML DOM
XML DOM 定义了所有 XML 元素的对象和属性,以及访问它们的方法(接口)。
换句话说:XML DOM 是用于获取、更改、添加或删除 XML 元素的标准。
(2)°HTML DOM
HTML DOM 定义了所有 HTML 元素的对象和属性,以及访问它们的方法(接口)。
换句话说:HTML DOM 是关于如何获取、修改、添加或删除 HTML 元素的标准。
非常明显,由于两种文件结构类似,DOM的解析原理几乎不变
所以我接下来两者合二为一讲,我们在了解DOM树前需要了解的是Node接口
2.Node–Element–Document–Attribute(DOM常见类型)
Node:构成DOM树的最基本(小)组成单位------因此也是最抽象的
节点可以是元素节点、属性节点、文本节点,可以是任何一种节点。
DOM这个API里定义了Node接口—下图是Node的继承关系图
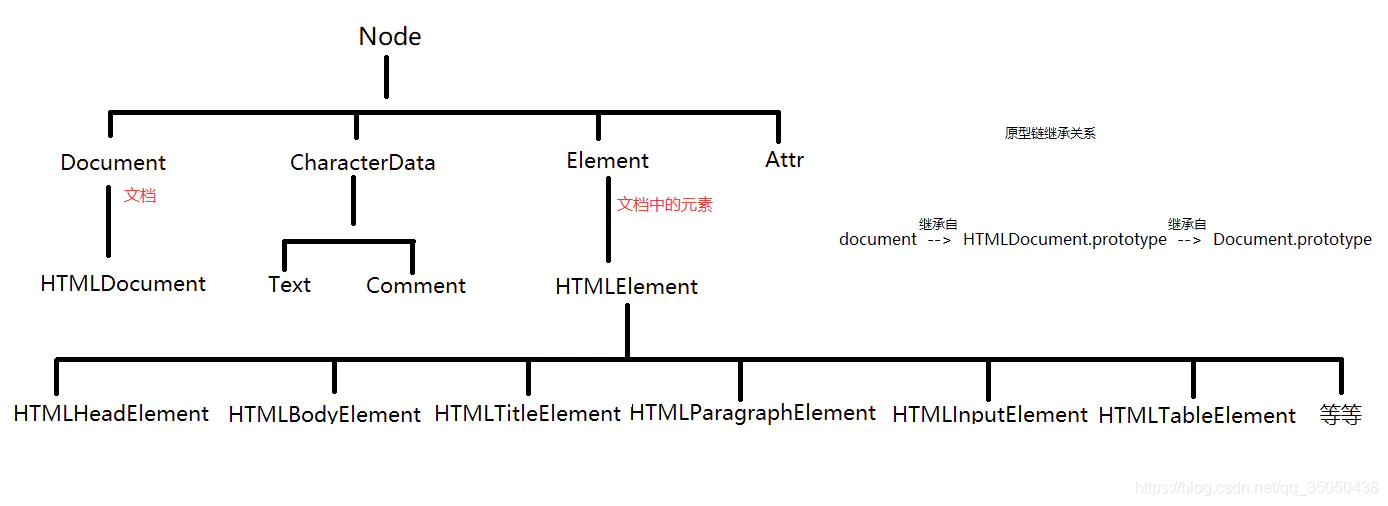
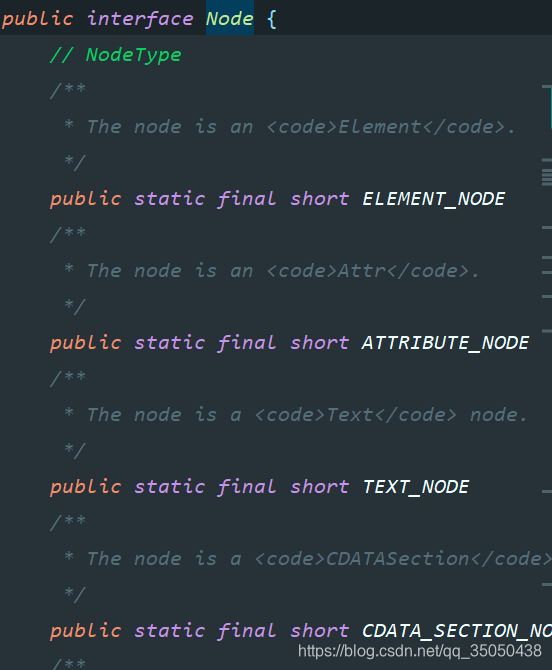
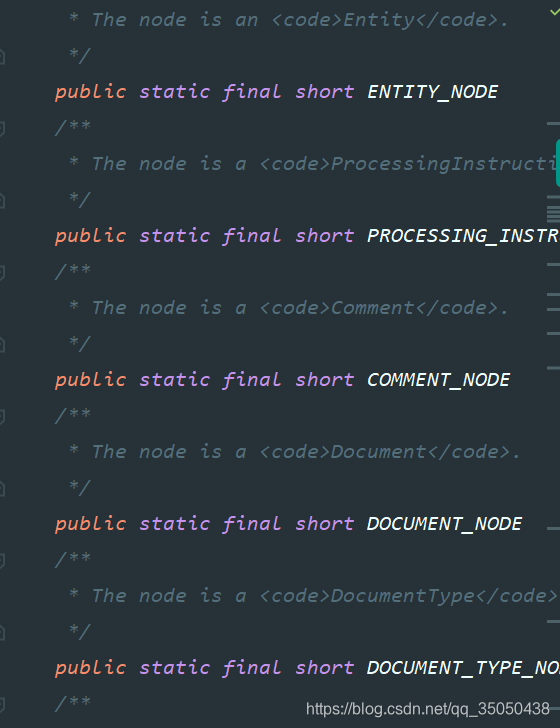
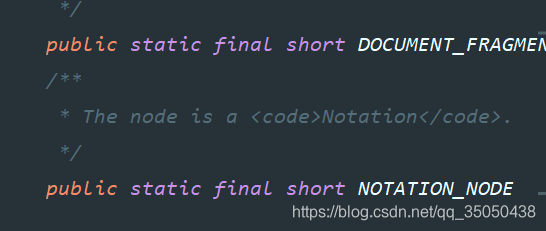
如下图所示,Node远远不止上图几种继承,它定义了12种结点类型,有兴趣的自己去看看源码
只是我们最常用的是Element,Document,Attribute,Text类型
由上述的继承关系可以看出,Node接口作为最高级的抽象,
它涵盖了Element,Document,Attribute,Text类型,
Element,Document,Attribute,Text类型等都为Node结点
举个具体的例子:
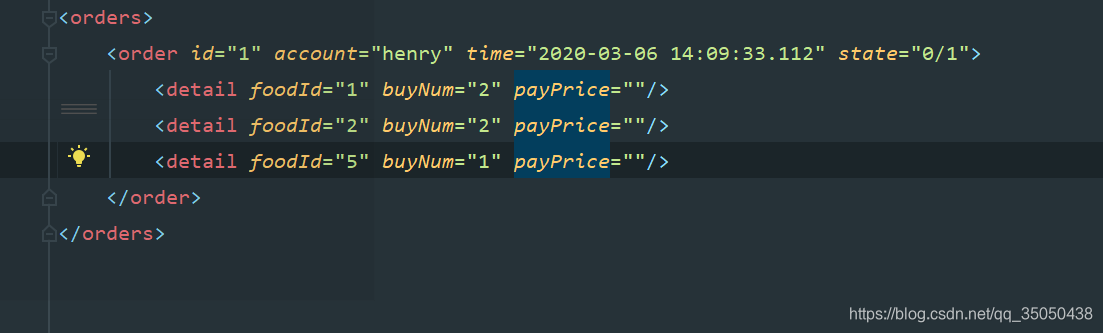
在上图中,orders是Node,id是Node,account是Node,detail也是Node,等等
而<orders>…</orders>, <order>…</order>, <detail .../>一个完整的开闭标签为Element
而account , time等等为Attribute属性
因此,Node作为最基本的单位,最纯粹的一张白纸,当你画上元素的内容,便是元素结点,画上属性的方式,变成属性结点,而这些结点类型之所以会创造出来是因为这样能更好的更方便的获取数据。
Element它不仅继承了 Node的所有方法,还自己扩展了很多,所以我们平常用的最多的是Element。
3.DOM树
XML DOM树
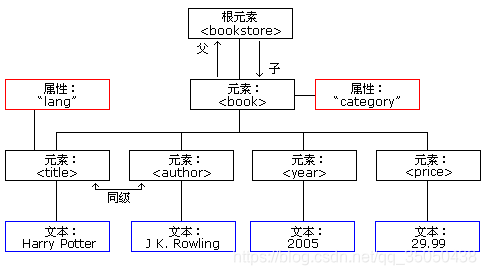
HTML DOM树
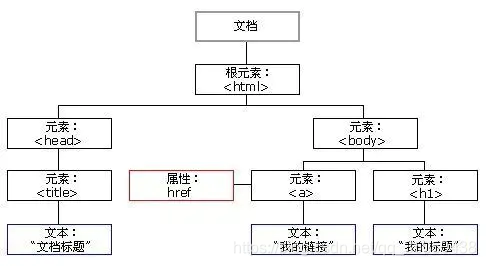
由图看出DOM树是由结点Node构成,简化为以元素结点画出,元素结点包含属性结点文档结点,元素结点的儿子是子元素结点,不断开枝散叶,最后形成了DOM树,而在根结点的上方,则为Document文档节点,它是作为遍历DOM树的入口,通过它可以遍历整颗树,使用Document方法可以找到任意一个结点。
四:常见方法
常见的方法在我的上一篇博文中有提及,仅提供了XML的DOM4jAPI仅供理解。