一、我们应该制作什么样的数据集?
首先我们应该我们了解到遥感图像的变化检测是建立在多时相的基础上的,也就是说,我们对于神经网络的输入至少是有两张图片的,而且必须有一个标签来知道变化的区域的是那一块。
在双时相变化检测里,一般来说对于遥感图像的标注是在最新的时相里进行的,例如2017和2018年份的两张图片中,我们选择在2018年度的图像上进行标注。
二、双时相遥感图像变化检测的标注
一般来说变化的区域是连通的,是一片一片的,因此对于图像的标注我们可以使用labelme的多边形标注进行标注
1.在conda的环境中运行 conda install labelme指令即可安装
2.运行labelme进行标注
3.选用多边形进行标注
4.如果图片较大,推荐进行裁剪后再标注,因为后来发现,有些细小的区域人眼是很难看出来的,但是经过放大后是可以看出来的
5.注意 得用彩图标注,否则很多变化的细节都会漏掉,例如如下水体的变化

现在将标注的效果展示如下:

启动labelme的py文件可以将json文件变成五组图片 将其中的label.png挑出来即可
三、如何存放?
个人建议将不同时相的图片分别保存在不同的文件夹,加上label总共三个文件夹,推荐命名方式为纯数字,即从0到100如此即可,注意这里存放的是原始的未处理的文件夹
然后在后面进行裁剪的时候在放在其他的文件夹
其中x文件夹存放裁剪好的图片,y存放标签,然后图片的命名为数字+字母
A表示变化 B表示不变化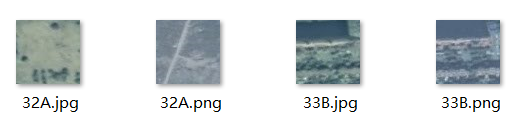
四、裁剪
将其裁剪为64*64的块,采用随机生成的方法,
其中x,y是随机生成的,代码如下:
下面的Import的东西可以忽略 只是将自己的库都Import了一遍,数据增强的东西可以另外放一个Py文件。
步骤为:
1.设定路径
2.读取路径下的所有图片的名字(注意用数字编号开头)
3.裁剪图片
4.裁剪的图片分别以jpg,png进行保存,2017,2018年份的图片分别为两种格式相同名称,标签存在另一个文件夹
5.
import numpy as np
import matplotlib
from matplotlib import pyplot as plt
import cv2
import PIL
import json, os
import sys
from PIL import Image
import labelme
import labelme.utils as utils
import glob
import itertools
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers,optimizers,losses
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.python.keras import backend as K
#存储路径
origin_path=r'F:\BaiduNetdiskDownload\U_net_dataset\eval\origin'
change_path=r'F:\BaiduNetdiskDownload\U_net_dataset\eval\change'
label_path=r'F:\BaiduNetdiskDownload\U_net_dataset\eval\label'
x_path=r'F:\BaiduNetdiskDownload\x'
y_path=r'F:\BaiduNetdiskDownload\y'
#读取列表名
origin_list= glob.glob(origin_path+'/*.jpg')
origin_list.sort()
change_list= glob.glob(change_path+'/*.jpg')
change_list.sort()
label_list= glob.glob(label_path +'/*.png')
label_list.sort()
#设定裁剪大小
cropping_height = 64
cropping_width = 64
#图像编号初始化
number=0
for k in range(len(origin_list)):#对所有图像和标签进行裁剪
origin_position,change_position,label_position=next(zipped)
origin_img=cv2.imread(origin_position,-1)
change_img=cv2.imread(change_position,-1)
label_img =cv2.imread(label_position,-1)
shape = origin_img.shape
zero_mat=np.zeros(shape=[cropping_height,cropping_width,3])
print(zero_mat.shape)
i=0
true_number = 0
false_number = 0
while i <=10000:#每张图片生成一万张图片
y=np.random.randint(0, shape[0]-cropping_height)
x=np.random.randint(0, shape[1]-cropping_width)
cropping1 = origin_img[y:(y + cropping_height),x:(x + cropping_width)]
cropping2 = change_img[y:y+ cropping_height,x:x + cropping_width]
cropping3 = label_img[y:y + cropping_height,x:x + cropping_width]
#判断矩阵是否为0矩阵,来说明是否变化
if ((cropping3==zero_mat).all()) :#A为变化 B为不变化
if((np.abs(true_number-false_number)>50)):
print(true_number,false_number)
continue
cv2.imwrite(x_path + '/' + str(number) + 'B' + '.jpg', cropping1)
cv2.imwrite(x_path + '/' + str(number) + 'B' + '.png', cropping2)
# cv2.imwrite(y_path + '/' + str(number) + 'B' + '.png', cropping3)
false_number += 1
number+=1
else:
cv2.imwrite(x_path + '/' + str(number) + 'A' + '.jpg', cropping1)
cv2.imwrite(x_path + '/' + str(number) + 'A' + '.png', cropping2)
# cv2.imwrite(y_path + '/' + str(number) + 'A' + '.png', cropping3)
true_number+=1
number+=1
i=i+1
print('number',number)
五、数据集
如果想要数据集的可以付5币支援下我,毕竟标注了很久(数个小时)
