前言
学完了基本的语言语法之后,接下来就应该学习数据结构这个让人脑壳大的的东西了,如果是计算机专业的同学一般都是在大二上学期学习数据结构这门课程,且肯定是学习的用C语言或者C++来实现的版本。用C语言实现的数据结构中一个非常重要的工具就是指针,但是大家在学C的时候肯定看到指针就头痛,我也一样,所以我的数据结构算是白学了,会做题就是不会敲代码。当我在学Python数据结构之前就在想,Python当中并没有指针这个东西啊,该怎么像C语言那样来实现链表、二叉树这些需要存储结点地址才能实现的数据结构呢?
什么是数据结构
在解决上面这个疑惑之前,我们首先要了解什么是数据结构?所谓数据结构啊就是研究数据之间的关联和组合形式,总结其中的规律,然后找出有用的结构,并将这些结构运用于数据的组织中,实现更高效的程序。说白了就是数据之间的的关系形式,像线性表、二叉树、图这些数据结构就是表示数据之间的关系,数据怎么在计算机中存储、我们怎么高效的表示和利用这些数据。当然我也不可能讲的很详细,具体的东西大家可以看看书。
为什么要学数据结构
这里我简单打个比方哈,如果将写好的程序比作战场,我们程序猿就是领军作战的将领,而我们所写的代码就是士兵和武器。那么数据结构这些东西是什么?我想肯定是兵法!
如果我们没有兵法在战场上拼刺刀,如此这般我们可能会胜利,可能会失败,即便胜利也会付出惨重的代价。我们写程序也是一样,解决一个问题的方式有很多种,有的时候虽然我们想到办法解决了这个问题,但是可能没有注意到程序的时间开销和效率问题,导致性能低下;有的时候虽然凭借某些别人开发的工具解决了效率问题,但是碰到其他的问题时又不知道如何解决,就知道暴力搜索啥的。
如果我们知道兵法,打仗时便课胸有成竹;同样如果我们学好了数据结构,写代码的时候就能游刃有余,找到问题的根源。
当然,如果我们只知兵法而不知实际情况就可能会成为纸上谈兵的赵括;同样,如果我们只去学数据结果而不去运用他,不去解决实际问题,不去写代码,不去刷题,到最后也是无用功。数据结构只是我们程序员的基本功,冰冻三尺非一日之寒,需要不断地努力学习积累。
时间复杂度和空间复杂度
时间复杂度
时间复杂度指的是代码的运行时间快慢的量级,有的代码运行时间快,那么他的时间复杂度就高;有的代码运行时间慢,那么他的时间复杂度就低。下面请看这一段代码就是来直观的描述代码的时间复杂度的:a+b+c=1000,a2+b2=c2求解满足这样要求的所有a,b,c的值。
import time
start_time = time.time()
for a in range(0, 1001):
for b in range(0, 1001):
for c in range(0, 1001):
if a + b + c == 1000 and a**2 + b**2 == c**2:
print("a, b, c:%d, %d, %d" % (a, b, c))
end_time = time.time()
print("%d" % (end_time - start_time))
print("finished")
运行时间大家可以看到是548s,当然有点夸张,因为我这是在虚拟机里面运行的所以有点慢,正常9代i7的话应该几十秒左右就解决了。

如果我们换个方式来写这个代码会有啥反应呢?
import time
start_time = time.time()
for a in range(0, 1001):
for b in range(0, 1001):
c = 1000 - a - b
if a**2 + b**2 == c**2:
print("a, b, c:%d, %d, %d" % (a, b, c))
end_time = time.time()
print("%d" % (end_time - start_time))
print("finished")
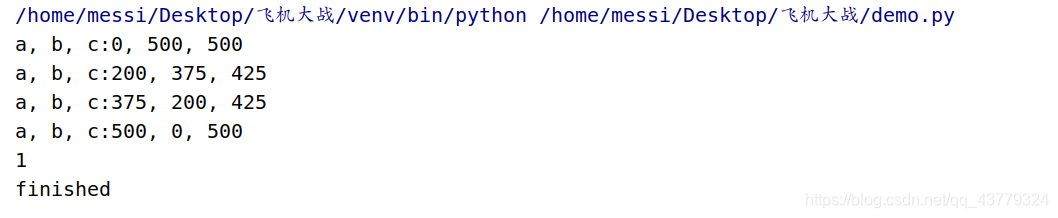
大家可以看到这里的运行时间只有1s,前面是548s,代码只是稍微改了一点,运行时间却相差了几百倍,由此可见代码的效率是有多么重要,这里只是求1000以内的,要是后面几万甚至更大的数字,代码孰优孰劣一对比便知。这就是我们学习数据结构的意义啊!高效的数据组成形式,其反应的时间就能节省几百倍,大大降低了延迟,你总不想以后开发的应用程序在那里等着几百秒不动,被用户骂吧。
时间复杂度的计算规则
- 基本操作,即只有常数项,认为其时间复杂度为O(1)。
- 顺序结构,时间复杂度按加法计算。
- 循环结构,时间复杂度按乘法计算。
- 分支结构,时间复杂度取最大值。
- 判断一个算法的效率时,往往只需要关注操作数量的最高项,其他次要项和常数项可以忽略。
- 没有特殊说明,我们分析是都是计算的最坏时间复杂度。
常见时间复杂度
| 执行函数举例 | 时间复杂度 |
|---|---|
| 12 | O(1) |
| 2n+3 | O(n) |
| 3n2+2n+3 | O(n2) |
| 5lg2n+20 | O(logn) |
| 2n+3nlgn+100 | O(nlogn) |
| 3n3+2n+3 | O(n3) |
| 2n | O(2n) |
 )
)
这个曲线图就可以明显的感受到时间复杂度的快慢排序是:O(1)<O(logn)<O(n)<O(nlogn)<O(n2)<O(n3)<O(2n)。
递归算法的时间复杂度
其实循环语句的时间复杂度大都可以看成是简单的递归算法,但是比较简单,不用这里的方法也可以解决。递归算法通常具有如下的模式:
def recur(n):
if n == 0:
return g(...)
somework
for i in range(a):
x = recur(n/b)
somework
somework
也就是说,n值为0时直接得到结果,否则原问题将归结为a个规模为n/b的子问题,其中a和b是由具体问题决定的两个常量。另外,在本层递归中还需要做一些工作,上面描述的用somework表示,其时间复杂度可能与n有关,设为O(nk)。这个k也应该是常量,k=0表示这部分的工作与n无关。这样就得到了递归方程:T(n)=O(nk)+a*T(n/b)
有如下结论:
- 如果a>bk,那么T(n)=O(n(logba))。
- 如果a=bk,那么T(n)=O(nklogn)。
- 如果a<bk,那么T(n)=O(nk)。
这些结论可以涵盖很大一部分递归定义算法的时间复杂度情况。
注意,因为这里要求a,b,k为常量,由此有关结论不能处理行列式的递归运算,在这里规模为n的问题归结为n个规模为n-1的问题。
空间复杂度
在程序里使用任何类型的对象都要付出空间的代价,建立一个元组,至少要占用元素个数个空间。如果一个表的元素个数与问题规模线性相关,建立他的空间付出至少为O(n)(如果元素是新建的,还要考虑元素本身的存储开销)。
相对而言,列表和元组是比较简单的数据结构。字典需要支持快速查询等操作,其结构更加复杂,包含n个元素的字典至少需要占用O(n)的存储空间。
注意:
Python的各种组合数据对象都没有预设最大元素个数,在实际使用中,这些结构能根据元素个数的增长自动扩充存储空间。从空间占用的角度看,其实际存储空间在数据的存续期间可能变大,但通常不会自动缩小(即使后来元素变得很少了)。举个例子,假设程序里面建立了一个列表,而后不断地加入元素导致表变大,而后又不断地删除元素,表中的元素又变得很少,但占用的存储空间并不减少。
不过在当今时代,随着大存储容量的硬盘的开发,以空间换时间的做法还是值得的,也不失为一个好办法,在我们目前的学习中,时间复杂度可以不用考虑,毕竟我们写的代码是不会导致内存不够用的,但是也不是说硬盘很大就随便瞎用,在你已知的方法中还是要选择空间复杂度小的结构。
最后
今天就记录这么多了,后续还会继续更新的!
