以豆瓣电影网中国机长爬取评论为例,采用Jsoup的方式
pom
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.12.1</version>
</dependency>页面链接查看页面元素
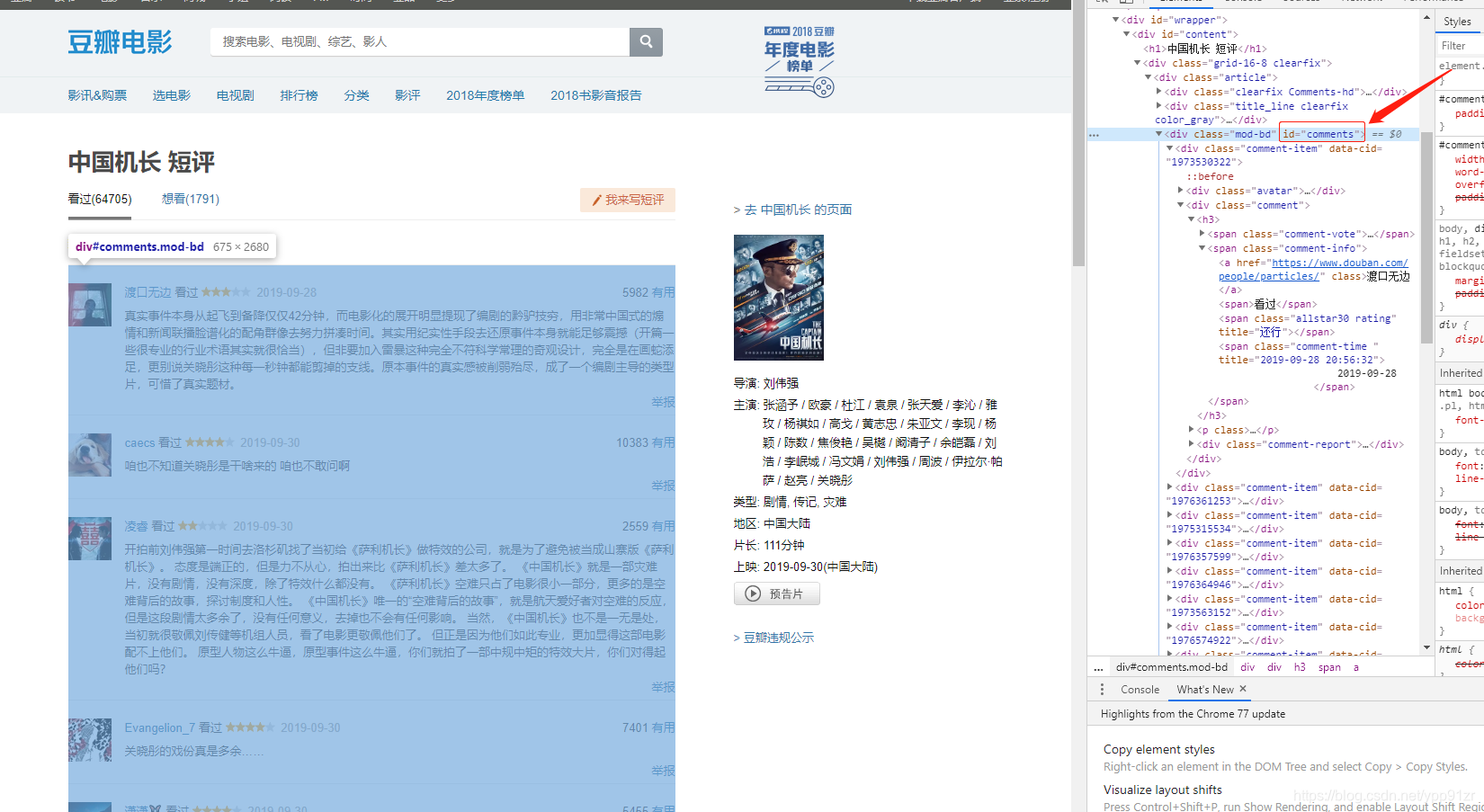
comments是当前页所有的评论,然后一级一级的获取爬取自己需要的数据就行了
package com.shinedata;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
/**
* @ClassName Main
* @Author yupanpan
* @Date 2019/10/11 14:19
*/
public class Main {
public static void main(String[] args) {
try {
Document document = Jsoup.connect("https://movie.douban.com/subject/30295905/comments?status=P").get();
Element comments = document.getElementById("comments");
Elements commentItems = comments.getElementsByClass("comment-item");
for (Element element:commentItems){
Elements commentList = element.getElementsByClass("comment");
Element comment = commentList.get(0);
//获取昵称
Elements h3s = comment.getElementsByTag("h3");
Elements commentInfos = h3s.get(0).getElementsByClass("comment-info");
Elements as = commentInfos.get(0).getElementsByTag("a");
String nickName = as.get(0).text();
//获取评论
Elements shorts = comment.getElementsByClass("short");
String p = shorts.get(0).text();
System.out.println(nickName+":"+p);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
效果

分页处理:同样是获取到请求链接(看下图),拼凑请求获取到数据即可,这里没有总页数,有总页数的话,循环总页数就可以了,但有很多网站会让登陆以及一些验证码等操作,可以利用phantomjs模拟登录网站。

