第一章 MySQL基础-简单查询
数据库的概念
数据库: 存储数据的大型仓库, 数据库由表,视图,触发器,函数,存储过程,事件等组成的. 表是存储数据的核心.
数据库服务器:
软件服务器,不是硬件服务器, 安装mysql之后启动的服务. 如果提到硬件服务器, 一般会说: CPU 16核, 内存: 128G, 硬盘:2T
一个数据库服务器包括若干数据库, 一个数据库包括若干张表;
数据库是“按照数据结构来组织、存储和管理数据的仓库”。是一个长期存储在计算机内的、有组织的、有共享的、统一管理的数据集合。
数据库是以一定方式储存在一起、能与多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合,可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据进行新增、查询、更新、删除等操作。 [1] —–百度百科
表是由行和列组成, 一行数据表示的一个对象, 一个记录; 一列数据描述一个对象的属性, 一个记录字段.一张表描述一个类.
book表----Book类. ORM: Object relation Mapping: 对象关系映射 .
我们现在主流的数据库都是关系型数据库: 最早的数据库是文件数据库,用普通的文件存储数据, 后来发展到网状数据库, 层次型数据库.
发展的三个阶段:
1、 层次型和网状型:
代表产品是1969年IBM公司研制的层次模型数据库管理系统IMS。
2、 关系型数据型库:
目前大部分数据库采用的是关系型数据库。1970年IBM公司的研究员E.F.Codd提出了关系模型。其代表产品为sysem R和Inges。
3、 第三代数据库将为更加丰富的数据模型和更强大的数据管理功能为特征,以提供传统数据库系统难以支持的新应用。它必须支持面向对象,具有开放性,能够在多个平台上使用。
管理技术的3个阶段
1 人工管理
2 文件管理
3 数据库系统
主流的数据库产品
数据库的分类:
参考: https://www.cnblogs.com/cenliang/p/9916803.html 特此感谢.
阿里云的数据库: ocean base 数据库
https://oceanbase.alipay.com/
在 6000 多名蚂蚁员工中,这几十个人辨识度很高,因为只有他们的工牌带是“土豪金”,而其他所有人的工牌带都是清一色蚂蚁蓝。“土豪金”工牌带是蚂蚁金服内部最高荣誉——CEO 大奖。2016 年 5 月,蚂蚁金服董事长彭蕾亲自为这几十位技术明星戴上了“土豪金” 工牌带,理由是这个小团队自主研发的 OceanBase 数据库,以远低于传统数据库的成本,更高的可用性,扛住了支付宝一次又一次自我刷新的支付峰值世界纪录,打破了 IT 核心技术长期被西方垄断的格局。
2019年 54万/秒 高峰, 双11.
MySQL数据库简介
MySQL原本是一个开放源代码的关系数据库管理系统,原开发者为瑞典的MySQL AB公司,该公司于2008年被Sun公司收购。2009年,甲骨文公司收购Sun公司,MySQL成为Oracle旗下产品。
MySQL 官网:https://www.mysql.com/
1990年,TcX公司的的客户,要求为报表工具Unireg的API,提供SQL支持。当时的商用数据库速度很难令人满意。于是,Monty决定自己重写一个SQL支持。
1995年,Michael Widenius(Monty), David Axmark and Allan Larsson,在瑞典创立了MySQL AB公司。
1996年,瑞典 MySQL AB 公司发布了MySQL 1.0版本。
1996年10月,MySQL 3.11.1发布。
2001年,MySQL集成Heikki Tuuri的存储引擎InnoDB,这个引擎不仅能持事务处理,并且支持行级锁。
2003年3月,MySQL 4.0 发布,支持查询缓存、集合并、全文索引、InnoDB存储引擎。
2004年10月,MySQL 4.1 发布,增加了子查询,utf8字符集,GROUP BY语句增加了ROLLUP,mysql.user表采用了更好的加密算法。
2005年10月,MySQL 5.0 发布,增加了视图、存储过程、游标、触发器、分布式事务。
2008年1月,MySQL AB公司 被Sun公司以10亿美金收购。
2008年11月,MySQL 5.1 发布,增加了分区、事件管理,以及基于行的复制和基于磁盘的NDB集群系统,同时修复了大量的Bug。
2009年4月20日,Oracle公司以74亿美元收购Sun公司。
2010年12月,MySQL 5.5 发布,增加了半同步复制、信号异常处理、unicode字符集,InnoDB成为默认存储引擎。
2011年4月,MySQL 5.6 发布,增加了GTID复制,支持延时复制、行级复制。
2013年4月,MySQL 5.6 GA 发布,支持在线DDL、并行复制。
2013年2月,MySQL 5.7 发布,支持原生JSON数据类型。
2015年8月,MySQL 5.7 GA 发布,支持原生JSON数据类型。
2016年9月12日,MySQL 8.0.0 发布,速度要比 MySQL 5.7 快 2 倍;增加了SQL窗口函数,公用表表达式,NOWAIT和SKIP LOCKED,降序索引,分组,正则表达式,字符集,成本模型和直方图;JSON扩展语法,新功能,改进排序和部分更新。使用JSON表函数,可以使用JSON数据的SQL机制;GIS地理支持。空间参考系统(SRS),以及SRS感知空间数据类型,空间索引和空间功能。可靠性 DDL语句已变得原子性和崩溃安全,元数据存储在单个事务数据字典中。
2018年4月19日,MySQL 8.0.11 GA 发布,支持NoSQL文档存储、原子的奔溃安全DDL语句、扩展JSON语法,新增JSON表函数,改进排序、分区更新功能。
https://dev.mysql.com/downloads/mysql/ 下载地址, 下载社区版, 开源免费.
连接到MySQL服务器
mysql安装之后是一个服务器, 我们需要连接到MySQL服务器; 基础的客户端工具Dos版, 还有图形界面: navicat , SQLyog , MySQL WorkBench(MySQL自带).
基于DOS的客户端
基于图形界面的客户端

创建数据库
- 查看当前服务器有多少数据库
mysql> show databases;
- 切换数据库
mysql> use db1; -- 我们操作是表, 表归属于库,所以要先选择数据库
- 创建数据库
mysql> create database erp;
- 查看数据库创建脚本
mysql> show create database erp;
+----------+----------------------------------------------------------------+
| Database | Create Database |
+----------+----------------------------------------------------------------+
| erp | CREATE DATABASE `erp` /*!40100 DEFAULT CHARACTER SET latin1 */ |
+----------+----------------------------------------------------------------+
1 row in set (0.00 sec)
默认的编码是拉丁语,所以不能存储汉字, 如果要存汉字,我们使用UTF8指定编码格式.
mysql> create database student default charset utf8;
Query OK, 1 row affected (0.00 sec)
mysql> show create database student;
+----------+------------------------------------------------------------------+
| Database | Create Database |
+----------+------------------------------------------------------------------+
| student | CREATE DATABASE `student` /*!40100 DEFAULT CHARACTER SET utf8 */ |
+----------+------------------------------------------------------------------+
1 row in set (0.00 sec)
以上的问题是: 有些名字中包含各种图片,LOGO, 微信昵称水果图片, 各种小LOGO. 要使用编码utf8mb4.
删除数据库
mysql> drop database db1;
Query OK, 12 rows affected (1.93 sec)
修改数据库
mysql> alter database erp default charset utf8mb4;
Query OK, 1 row affected (0.00 sec)
mysql> show create database erp;
+----------+-----------------------------------------------------------------+
| Database | Create Database |
+----------+-----------------------------------------------------------------+
| erp | CREATE DATABASE `erp` /*!40100 DEFAULT CHARACTER SET utf8mb4 */ |
+----------+-----------------------------------------------------------------+
1 row in set (0.00 sec)
备份数据库
C:\Users\Administrator>mysqldump -uroot -p123456 db1 > e:\\db1.sql --注意: cmd 普通窗口
C:\Users\Administrator>mysqldump -uroot -p123456 db1 db2 db3 > e:\\db.sql --备份多个数据库
C:\Users\Administrator>mysqldump -uroot -p123456 db1 table1 table2 > e:\\table.sql --备份指定表
恢复数据库
mysql> use db1;
Database changed
mysql> source e:\\db1.sql
Query OK, 0 rows affected (0.00 sec)
创建表
数据库的存储还是以表为单位, 如何创建一个表; 创建表的语法结构:
CREATE TABLE table_name -- 表的名称
(
field1 datatype, -- 字段1 数据类型1
field2 datatype, -- 字段2 数据类型2
field3 datatype, -- 字段3 数据类型3
)character set 字符集 collate 校对规则 engine 存储引擎方式
field:指定列名 datatype:指定列类型
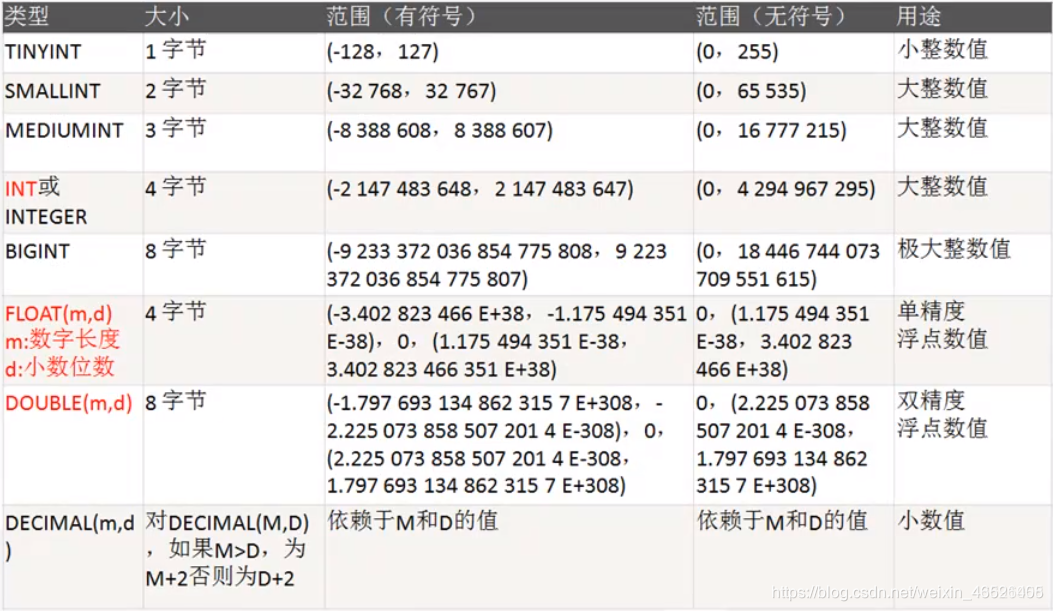
MySql 数据类型,MySQL中除了字符串类型需要设置长度,其他类型都有默认长度.
| 数据类 | Java中数据类型 | MySQL中数据类型 |
|---|---|---|
| 整型 | byte | tinyint |
| short | smallint | |
| int | int | |
| long | bigint | |
| 浮点型 | float | float |
| double | double | |
| 字符串类型 | String | 定长char(); 可变长varchar |
| 时间日期 | date | date/time/datetime |
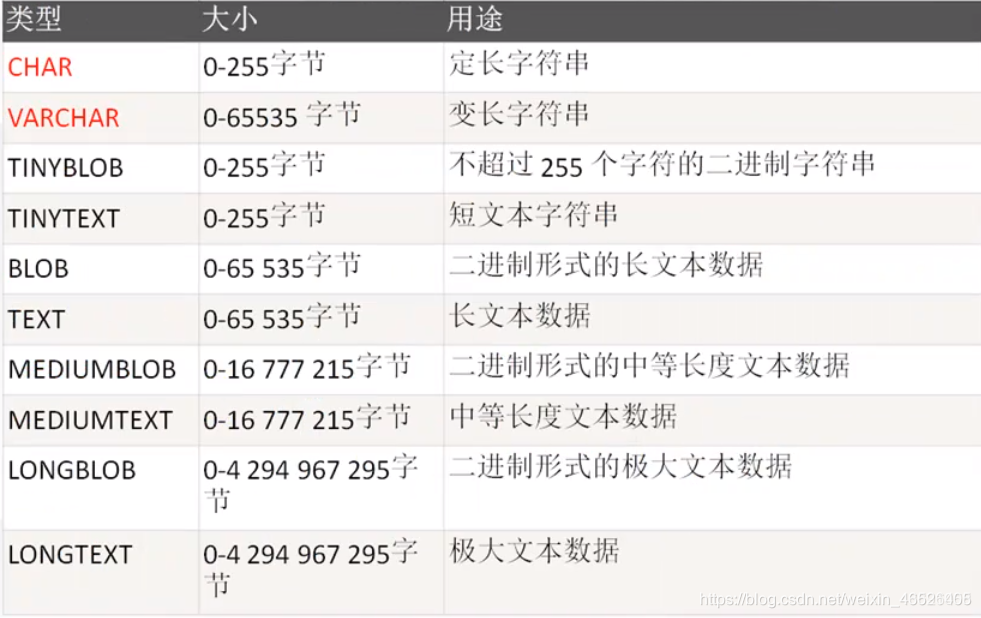
char ( 6 ) 存储邮编, char(11) 手机号 char(18)身份证号, char(10) 学号 固定长度, 不足指定长度,也是占用指定长度空间
varchar(50) 地址, 姓名, 以实际的数据的长度为准.
mysql> use student;
Database changed
mysql> create table stu(
-> stuNo int,
-> stuName varchar(50),
-> stuSex char(2),
-> stuAge int,
-> telephone char(11),
-> address varchar(200)
-> );
Query OK, 0 rows affected (0.30 sec)
--创建表案例2
CREATE TABLE IF NOT EXISTS user1(
--主键id,一般设定无符号位属性,配合主键以及自增属性
id TINYINT UNSIGNED PRIMARY KEY AUTO_INCREMENT COMMENT '主键字段',
--姓名,不确定字符长度,可以有重复数据,不能null
name VARCHAR(30) NOT NULL COMMENT '用户姓名字段',
--年龄,一般为tinyint 设定无符号位,可以添加默认值
age TINYINT UNSIGNED NOT NULL DEFAULT 18 COMMENT '用户年龄字段,默认值为18',
-- 性别,一般为枚举,设定输入数据,一般为男女保密,可以设定默认值
sex ENUM('男','女','保密') DEFAULT '保密' COMMENT '用户性别字段,枚举类型,允许输入值为男,女',
-- 爱好,一般为集合,可以多选,设定输入数据
hoddy SET('吃','喝','玩','乐') COMMENT '用户爱好字段,聚合类型,允许输入数值为吃,喝,玩,乐',
-- 地址,不确定字符长度,不为空
addr VARCHAR(50) NOT NULL COMMENT '用户地址字段',
-- 有关钱的字段尽量使用DECIMAL
pay DECIMAL(10,2) UNSIGNED NOT NULL DEFAULT 0.00 COMMENT '用户薪资',
-- 手机号,11位数字,如果存储为数值,只能是BIGINT类型,会占用大量存储空间,设定为CHAR(11),手机号不能重复
phone CHAR(11) UNIQUE KEY NOT NULL COMMENT '用户手机号字段' ,
-- 邮箱,不确定字符长度,不能重复
email VARCHAR(50) UNIQUE KEY NOT NULL COMMENT '用户邮箱字段' ,
-- 注册时间,自动获取时间
regdate TIMESTAMP COMMENT '用户注册时间字段,自动获取执行时间'
) ENGINE innodb CHARSET utf8 COMMENT '用户表结构2';
修改表
添加列
mysql> alter table stu
-> add column birthday datetime;
Query OK, 0 rows affected (0.48 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> desc stu; -- 查看表信息
+-----------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+--------------+------+-----+---------+-------+
| stuNo | int(11) | YES | | NULL | |
| stuName | varchar(50) | YES | | NULL | |
| stuSex | char(2) | YES | | NULL | |
| stuAge | int(11) | YES | | NULL | |
| telephone | char(11) | YES | | NULL | |
| address | varchar(200) | YES | | NULL | |
| birthday | datetime | YES | | NULL | |
+-----------+--------------+------+-----+---------+-------+
7 rows in set (0.00 sec)
修改列
mysql> alter table stu
-> modify stuName varchar(50) not null;
Query OK, 0 rows affected (0.36 sec)
Records: 0 Duplicates: 0 Warnings: 0
删除列
mysql> alter table stu
-> drop column birthday;
Query OK, 0 rows affected (0.77 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> desc stu;
+-----------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+--------------+------+-----+---------+-------+
| stuNo | int(11) | YES | | NULL | |
| stuName | varchar(50) | NO | | NULL | |
| stuSex | char(2) | YES | | NULL | |
| stuAge | int(11) | YES | | NULL | |
| telephone | char(11) | YES | | NULL | |
| address | varchar(200) | YES | | NULL | |
+-----------+--------------+------+-----+---------+-------+
6 rows in set (0.00 sec)
删除表
mysql> drop table stu;
数据完整性
数据完整性: 数据的有效性, 数据的正确性 ; 年龄: 不能为空, 准确性: 符合一定的业务常识. 出生日期: 只要是 日期类型都可以, 2020-10-10. 如何保证数据完整性: 应该在创建表之前就要做约束, 不能等到创建表之后, 相当于补漏洞(不合适). 数据完整性包括如下几个问题:
①实体完整性: 针对的是一行数据, 一行数据描述一个对象, 一个实例
②域完整性: 域针对的是字段, 表中的列, 对象: 对象的属性
③引用完整性: 是多个实体之间的关系, 添加一个员工要指定 员工所属部门. 张书峰: 小卖部(不合适),应该写公司有的部门: 市场部, 财务部, 行政部, 销售部… 班级和年级之间也是引用关系. 商品和商品的类别也是引用关系.
④自定义完整性: 公司根据自己的业务规则定义的约束机制. 腾讯:QQ 级别, 几个星星—一个月亮—四个月亮—一个太阳 19388483; 阿里公司的淘宝: 皇冠店铺, 钻石店铺, 都是公司内部定义的完整性.
如何实现数据完整性
要保住数据完整性, 一定要在数据库表的设计阶段. 创建表之前.
如何实现实体完整性
实体完整性的概念: 要保证表中的数据不能出现重复的数据. 重复的就记录.但是不能依赖名字,也不能依赖性别,也不能依赖部门信息.; 所以很难找到一个属性可以唯一区分不同的实体.我们可选的是身份证号. 为了 区分不同的实体对象, 仅仅依赖具体属性不合适,所以数据库理论引入键( key )的概念: 包括主键和外键, 其中主键 就是用来唯一区分不同的实体的数据.
主键约束: 一般数据类型选择是整型, 也可以是字符串类型的. 因为主键并不包含实际的意义, 不是对象真正的属性. 所以一般我们可以让主键自动的增长. 由数据库去维护.这种递增方式存在的问题: 如果后面分库分表, 一个订单表不能存储所有数据, 把订单表分成若干张表, 这时就不能用整型数据: 假设有5张订单表: 都是递增就不合适了.在分布式系统中要使用唯一ID这是一个重要的问题. 推特的雪花算法(snowflake): 目前在开发中用的比较多. 根据主机信息, 时间信息, 序列号等等产生一个唯一的ID. 在SpringBoot提供的也有分布式唯一ID产生的算法.
唯一约束: 也可以实现实体完整性.
主键的特征: ①不允许重复②不允许为null
mysql> create table stu1(
-> id int primary key auto_increment,
-> name varchar(50) not null,
-> address varchar(50)
-> );
Query OK, 0 rows affected (0.28 sec)
如何实现域完整性
域完整性是针对列的约束:
①非空约束: name varchar(50) not null,
②默认值约束 province varchar(50) default ‘河南省’, 如果不指定值就是默认值
mysql> alter table stu1
-> add column province varchar(50) default '河南省';
Query OK, 0 rows affected (0.41 sec)
Records: 0 Duplicates: 0 Warnings: 0
③唯一约束 tel char(11) unique, 电话号码唯一约束
mysql> alter table stu1
-> add column tel char(11) unique;
Query OK, 0 rows affected (0.47 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> insert into stu1(name,address,tel) values('赵敏','元大都','13803711122');
ERROR 1062 (23000): Duplicate entry '13803711122' for key 'tel'
mysql>
④检查约束 age int check age >0 and age <120 ,mysql只做语法检查,但是不能实现约束
mysql> create table stu3(
-> id int primary key auto_increment,
-> name varchar(50),
-> age int check (age>0 and age <120)
-> );
Query OK, 0 rows affected (0.27 sec)
mysql> insert into stu3(name,age)values('admin',150);
Query OK, 1 row affected (0.03 sec)
mysql> select * from stu3;
+----+-------+------+
| id | name | age |
+----+-------+------+
| 1 | admin | 150 |
+----+-------+------+
1 row in set (0.00 sec)
只做语法检查,没有实际效果; Oracle和SqlServer都有实际效果.
如何实现引用完整性
员工和部门的关系, 员工要引用部门的数据. 通过主外键关系实现.
mysql> create table dept(
-> deptNo int primary key auto_increment, -- 设置主键
-> deptName varchar(50) not null,
-> loc varchar(200)
-> );
Query OK, 0 rows affected (0.26 sec)
mysql> insert into dept(deptName,loc) values('市场部','郑州市');
Query OK, 1 row affected (0.09 sec)
mysql> insert into dept(deptName,loc) values('财务部','开封市');
Query OK, 1 row affected (0.09 sec)
mysql> insert into dept(deptName,loc) values('人事部','南阳市');
Query OK, 1 row affected (0.09 sec)
mysql> select * from dept;
+--------+----------+--------+
| deptNo | deptName | loc |
+--------+----------+--------+
| 1 | 市场部 | 郑州市 |
| 2 | 财务部 | 开封市 |
| 3 | 人事部 | 南阳市 |
+--------+----------+--------+
3 rows in set (0.05 sec)
引用完整性是在添加员工信息的时候,员工所在部门必须是部门表中存在信息.
mysql> CREATE TABLE emp(
-> empId INT PRIMARY KEY AUTO_INCREMENT,
-> empName VARCHAR(50),
-> birthday DATETIME,
-> deptId INT, -- 外键列
-> FOREIGN KEY (deptId) REFERENCES dept(deptNo) -- 引用部门表的主键
-> );
Query OK, 0 rows affected (0.26 sec)
mysql> insert into emp(empName,birthday,deptId)values('张无忌','1999-10-01',1);
Query OK, 1 row affected (0.05 sec)
-- 没有id为10的部门
mysql> insert into emp(empName,birthday,deptId)values('赵敏','1999-10-01',10);
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`student`.`emp`, CONSTRAINT `emp_ibfk_1` FOREIGN KEY (`deptId`) REFERENCES `dept` (`deptNo`))
mysql>
这就是引用完整性.
如何实现自定义完整性\
通过存储过程和触发器等等实现.
简单查询
结构化查询语言(Structured Query Language)简称SQL,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
结构化查询语言是高级的非过程化编程语言,允许用户在高层数据结构上工作。它不要求用户指定对数据的存放方法,也不需要用户了解具体的数据存放方式,所以具有完全不同底层结构的不同数据库系统, 可以使用相同的结构化查询语言作为数据输入与管理的接口。结构化查询语言语句可以嵌套,这使它具有极大的灵活性和强大的功能。 —百度百科
结构化查询语言包含6个部分:
1、数据查询语言(DQL:Data Query Language):其语句,也称为“数据检索语句”,用以从表中获得数据,确定数据怎样在应用程序给出。保留字SELECT是DQL(也是所有SQL)用得最多的动词,其他DQL常用的保留字有WHERE,ORDER BY,GROUP BY和HAVING。这些DQL保留字常与其它类型的SQL语句一起使用。
2、数据操作语言(DML:Data Manipulation Language):其语句包括动词INSERT、UPDATE和DELETE。它们分别用于添加、修改和删除。
3、事务控制语言(TCL):它的语句能确保被DML语句影响的表的所有行及时得以更新。包括COMMIT(提交)命令、SAVEPOINT(保存点)命令、ROLLBACK(回滚)命令。
4、数据控制语言(DCL):它的语句通过GRANT或REVOKE实现权限控制,确定单个用户和用户组对数据库对象的访问。某些RDBMS可用GRANT或REVOKE控制对表单个列的访问。也称为权限控制语句.
5、数据定义语言(DDL):其语句包括动词CREATE,ALTER和DROP。在数据库中创建新表或修改、删除表(CREAT TABLE 或 DROP TABLE);为表加入索引等。
6、指针控制语言(CCL):它的语句,像DECLARE CURSOR,FETCH INTO和UPDATE WHERE CURRENT用于对一个或多个表单独行的操作。
语法:
SELECT * FROM 表名称 WHERE 条件
GROUP BY 字段
HAVING 聚合条件
ORDER BY 字段 DESC|ASC
LIMIT 起始序号,数量;
SELECT 基本查询
-- 查询所有列
mysql> select * from student;
+----+----------+---------+------+---------+----------+
| id | name | chinese | math | english | grade_id |
+----+----------+---------+------+---------+----------+
| 1 | 迪丽热巴 | 70 | 80 | 90 | 1 |
| 2 | 古力娜扎 | 80 | 90 | 100 | 2 |
| 3 | 佟丽娅 | 60 | 70 | 80 | 1 |
| 4 | 雷佳音 | 50 | 60 | 70 | 3 |
| 5 | 易烊千玺 | 78 | 68 | 88 | 3 |
| 6 | 雷雨 | 90 | 80 | 70 | 1 |
+----+----------+---------+------+---------+----------+
6 rows in set (0.00 sec)
-- 查询指定列
mysql> select id,name from student;
+----+----------+
| id | name |
+----+----------+
| 3 | 佟丽娅 |
| 2 | 古力娜扎 |
| 5 | 易烊千玺 |
| 1 | 迪丽热巴 |
| 4 | 雷佳音 |
| 6 | 雷雨 |
+----+----------+
6 rows in set (0.01 sec)
-- 友好显示,给列指定别名, 在后面MyBatis课程会用到
mysql> select id,name, chinese as 语文,math 数学, english 英语, grade_id 班级编号
-> from student;
+----+----------+------+------+------+----------+
| id | name | 语文 | 数学 | 英语 | 班级编号 |
+----+----------+------+------+------+----------+
| 1 | 迪丽热巴 | 70 | 80 | 90 | 1 |
| 2 | 古力娜扎 | 80 | 90 | 100 | 2 |
| 3 | 佟丽娅 | 60 | 70 | 80 | 1 |
| 4 | 雷佳音 | 50 | 60 | 70 | 3 |
| 5 | 易烊千玺 | 78 | 68 | 88 | 3 |
| 6 | 雷雨 | 90 | 80 | 70 | 1 |
+----+----------+------+------+------+----------+
6 rows in set (0.00 sec)
-- 计算列:求每个同学的总成绩
mysql> select id,name, chinese as 语文,math 数学, english 英语, chinese+math+english as 总成绩, grade_id 班级编号
-> from student;
+----+----------+------+------+------+--------+----------+
| id | name | 语文 | 数学 | 英语 | 总成绩 | 班级编号 |
+----+----------+------+------+------+--------+----------+
| 1 | 迪丽热巴 | 70 | 80 | 90 | 240 | 1 |
| 2 | 古力娜扎 | 80 | 90 | 100 | 270 | 2 |
| 3 | 佟丽娅 | 60 | 70 | 80 | 210 | 1 |
| 4 | 雷佳音 | 50 | 60 | 70 | 180 | 3 |
| 5 | 易烊千玺 | 78 | 68 | 88 | 234 | 3 |
| 6 | 雷雨 | 90 | 80 | 70 | 240 | 1 |
+----+----------+------+------+------+--------+----------+
6 rows in set (0.04 sec)
-- 单例结算. 本次考试,数学成绩都加10分
mysql> select id,name,chinese,math,math+10 from student;
+----+----------+---------+------+---------+
| id | name | chinese | math | math+10 |
+----+----------+---------+------+---------+
| 1 | 迪丽热巴 | 70 | 80 | 90 |
| 2 | 古力娜扎 | 80 | 90 | 100 |
| 3 | 佟丽娅 | 60 | 70 | 80 |
| 4 | 雷佳音 | 50 | 60 | 70 |
| 5 | 易烊千玺 | 78 | 68 | 78 |
| 6 | 雷雨 | 90 | 80 | 90 |
+----+----------+---------+------+---------+
6 rows in set (0.00 sec)
SQL语句的逻辑运算符: 取反 not, 逻辑与 and , 逻辑或 or
关系运算符: = , > , >=, <, <=, != <>
数学运算符: + - * / %
distinct 去重
SELECT DISTINCT sex FROM emp;
where子句:条件
-- 单条件查询
mysql> select id,name, chinese,math,english,grade_id
-> from student
-> where chinese > 60;
+----+----------+---------+------+---------+----------+
| id | name | chinese | math | english | grade_id |
+----+----------+---------+------+---------+----------+
| 1 | 迪丽热巴 | 70 | 80 | 90 | 1 |
| 2 | 古力娜扎 | 80 | 90 | 100 | 2 |
| 5 | 易烊千玺 | 78 | 68 | 88 | 3 |
| 6 | 雷雨 | 90 | 80 | 70 | 1 |
+----+----------+---------+------+---------+----------+
4 rows in set (0.00 sec)
-- 多条件 查询语文>60 并且 数学>70
mysql> select id,name, chinese,math,english,grade_id
-> from student
-> where chinese > 60 and math >70;
+----+----------+---------+------+---------+----------+
| id | name | chinese | math | english | grade_id |
+----+----------+---------+------+---------+----------+
| 1 | 迪丽热巴 | 70 | 80 | 90 | 1 |
| 2 | 古力娜扎 | 80 | 90 | 100 | 2 |
| 6 | 雷雨 | 90 | 80 | 70 | 1 |
+----+----------+---------+------+---------+----------+
3 rows in set (0.00 sec)
order by子句: 排序
mysql> select * from student order by chinese ; -- 按照语文成绩升序 (默认升序)
+----+----------+---------+------+---------+----------+
| id | name | chinese | math | english | grade_id |
+----+----------+---------+------+---------+----------+
| 4 | 雷佳音 | 50 | 60 | 70 | 3 |
| 3 | 佟丽娅 | 60 | 70 | 80 | 1 |
| 1 | 迪丽热巴 | 70 | 80 | 90 | 1 |
| 5 | 易烊千玺 | 78 | 68 | 88 | 3 |
| 2 | 古力娜扎 | 80 | 90 | 100 | 2 |
| 6 | 雷雨 | 90 | 80 | 70 | 1 |
+----+----------+---------+------+---------+----------+
6 rows in set (0.04 sec)
mysql> select * from student order by chinese desc; -- 按照语文成绩降序
+----+----------+---------+------+---------+----------+
| id | name | chinese | math | english | grade_id |
+----+----------+---------+------+---------+----------+
| 6 | 雷雨 | 90 | 80 | 70 | 1 |
| 2 | 古力娜扎 | 80 | 90 | 100 | 2 |
| 5 | 易烊千玺 | 78 | 68 | 88 | 3 |
| 1 | 迪丽热巴 | 70 | 80 | 90 | 1 |
| 3 | 佟丽娅 | 60 | 70 | 80 | 1 |
| 4 | 雷佳音 | 50 | 60 | 70 | 3 |
+----+----------+---------+------+---------+----------+
6 rows in set (0.00 sec)
mysql> select * from student order by chinese asc, math desc; -- 多列排序
+----+----------+---------+------+---------+----------+
| id | name | chinese | math | english | grade_id |
+----+----------+---------+------+---------+----------+
| 4 | 雷佳音 | 50 | 60 | 70 | 3 |
| 3 | 佟丽娅 | 60 | 70 | 80 | 1 |
| 1 | 迪丽热巴 | 70 | 80 | 90 | 1 |
| 2 | 古力娜扎 | 80 | 90 | 100 | 2 |
| 5 | 易烊千玺 | 80 | 68 | 88 | 3 |
| 6 | 雷雨 | 90 | 80 | 70 | 1 |
+----+----------+---------+------+---------+----------+
6 rows in set (0.00 sec)
group by 字句
group 分组的意思, group by 根据某一列分组, 一般分组会结合聚合函数进行统计.
-- 按照性别分组统计人数
mysql> select sex, count(id) from student group by sex;
+------+-----------+
| sex | count(id) |
+------+-----------+
| 女 | 3 |
| 男 | 3 |
+------+-----------+
2 rows in set (0.00 sec)
-- 单列分组
mysql> select grade_id, count(name) 班级人数 from student group by grade_id;
+----------+----------+
| grade_id | 班级人数 |
+----------+----------+
| 1 | 3 |
| 2 | 1 |
| 3 | 2 |
+----------+----------+
3 rows in set (0.00 sec)
-- 单列分组
mysql> select grade_id,sex, count(id) 班级人数 from student group by grade_id;
+----------+------+----------+
| grade_id | sex | 班级人数 |
+----------+------+----------+
| 1 | 女 | 3 |
| 2 | 女 | 1 |
| 3 | 男 | 2 |
+----------+------+----------+
3 rows in set (0.00 sec)
-- 多列分组
mysql> select grade_id,sex, count(id) 班级人数 from student group by grade_id,sex;
+----------+------+----------+
| grade_id | sex | 班级人数 |
+----------+------+----------+
| 1 | 女 | 2 |
| 1 | 男 | 1 |
| 2 | 女 | 1 |
| 3 | 男 | 2 |
+----------+------+----------+
4 rows in set (0.00 sec)
-- having 对分组后的数据进行过滤, 而且having只能用在group by字句后面
mysql> select grade_id, count(name) 班级人数 from student group by grade_id having count(name) > 1;
+----------+----------+
| grade_id | 班级人数 |
+----------+----------+
| 1 | 3 |
| 3 | 2 |
+----------+----------+
2 rows in set (0.00 sec)
mysql> select grade_id,sex, count(id) 班级人数 from student group by grade_id,sex;
±---------±-----±---------+
| grade_id | sex | 班级人数 |
±---------±-----±---------+
| 1 | 女 | 2 |
| 1 | 男 | 1 |
| 2 | 女 | 1 |
| 3 | 男 | 2 |
±---------±-----±---------+
4 rows in set (0.00 sec)
– having 对分组后的数据进行过滤, 而且having只能用在group by字句后面
mysql> select grade_id, count(name) 班级人数 from student group by grade_id having count(name) > 1;
±---------±---------+
| grade_id | 班级人数 |
±---------±---------+
| 1 | 3 |
| 3 | 2 |
±---------±---------+
2 rows in set (0.00 sec)
