- 1.1, 什么是约束?
- 1.2, 表级约束和列级约束?
- 1.3, NOT NULL 约束
- 1.4, UNIQUE 约束
- 1.5, PRIMARY KEY 约束
- 1.6, FOREIGN KEY 约束
- 1.7, 添加约束
- 1.8, 删除约束
- 1.9, 无效化约束
- 1.10,激活约束
- 1.11,查询约束
- 2.1, 视图的概念
- 2.2, 为什么使用视图
- 2.3, 简单视图和复杂视图
- 2.4, 创建,查询,修改,删除视图
- 2.5, 视图中使用DML的规定
- 2.6, 屏蔽 DML 操作
- 2.7, Top-N 分析
约束
1,什么是约束?
- 约束是表级的强制规定
- 有以下五种约束:
NOT NULL
UNIQUE
PRIMARY KEY
FOREIGN KEY
CHECK - 如果不指定约束名 ,Oracle server 自动按照 SYS_Cn 的格式指定约束名
2,表级约束和列级约束?
-
作用范围:
①,列级约束只能作用在一个列上
②,表级约束可以作用在多个列上(当然表级约束也 可以作用在一个列上) -
定义方式:列约束必须跟在列的定义后面,表约束不与列一起,而是单独定义。
-
非空(not null) 约束只能定义在列上
3,NOT NULL 约束
CREATE TABLE employees(
employee_id NUMBER(6),
first_name VARCHAR2(20) NOT NULL,//系统命名
job_id CONSTRAINT ji_nn NOT NULL VARCHAR2(10),//用户命名
CONSTRAINT emp_emp_id_pk PRIMARY KEY (EMPLOYEE_ID)
);
4, UNIQUE 约束
CREATE TABLE employees(
employee_id NUMBER(6),
last_name VARCHAR2(25) UNIQUE,--系统命名
email VARCHAR2(25),
salary NUMBER(8,2),
commission_pct NUMBER(2,2),
hire_date DATE NOT NULL,
CONSTRAINT emp_email_uk UNIQUE(email) --用户命名
);
5,PRIMARY KEY 约束
CREATE TABLE departments(
department_id NUMBER(4),
department_name VARCHAR2(30) CONSTRAINT dept_name_nn NOT NULL,
manager_id NUMBER(6),
location_id NUMBER(4),
CONSTRAINT dept_id_pk PRIMARY KEY(department_id));
6,FOREIGN KEY 约束
CREATE TABLE employees(
employee_id NUMBER(6),
last_name VARCHAR2(25) NOT NULL,
email VARCHAR2(25) UNIQUE,
salary NUMBER(8,2),
commission_pct NUMBER(2,2),
hire_date DATE NOT NULL,
department_id NUMBER(4),
CONSTRAINT emp_dept_fk FOREIGN KEY (department_id)
REFERENCES departments(department_id) on delete cascade
);
- FOREIGN KEY: 在表级指定子表中的列
- REFERENCES: 标示在父表中的列
- ON DELETE CASCADE(级联删除): 当父表中的列被删除时,子表中相对应的列也被删除
- ON DELETE SET NULL(级联置空): 子表中相应的列置空
7,添加约束
ALTER TABLE employees
ADD CONSTRAINT emp_manager_fk
FOREIGN KEY(manager_id) REFERENCES employees(employee_id);
8,删除约束
ALTER TABLE employees DROP CONSTRAINT emp_manager_fk;
9,无效化约束
- 在ALTER TABLE 语句中使用 DISABLE 子句将约束无效化。
ALTER TABLE employees DISABLE CONSTRAINT emp_manager_fk;
10,激活约束
- ENABLE 子句可将当前无效的约束激活
ALTER TABLE employees ENABLE CONSTRAINT emp_manager_fk;
- 当定义或激活UNIQUE 或 PRIMARY KEY 约束时系统会自动创建UNIQUE 或 PRIMARY KEY索引
11,查询约束
- 查询数据字典视图 USER_CONSTRAINTS
SELECT constraint_name, constraint_type, search_condition
FROM user_constraints
WHERE table_name = 'EMPLOYEES';
视图
1,视图的概念
- 视图是一种虚表。
- 视图建立在已有表的基础上, 视图赖以建立的这些表称为基表。
- 向视图提供数据内容的语句为 SELECT 语句, 可以将视图理解为存储起来的 SELECT 语句.
- 视图向用户提供基表数据的另一种表现形式
2,为什么使用视图
- 控制数据访问
- 简化查询
- 避免重复访问相同的数据
3,简单视图和复杂视图
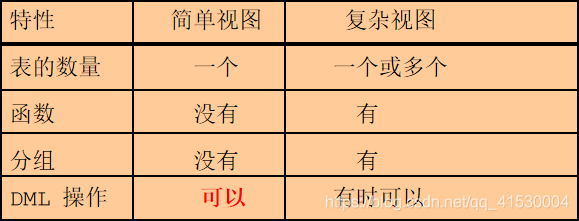
4,创建,查询,修改,删除视图
- 创建视图
create or replace view empview
as
select employee_id emp_id,last_name name,department_name
from employees e,departments d
Where e.department_id = d.department_id
- 查询视图
SELECT * FROM empview;
- 修改视图(使用CREATE OR REPLACE VIEW 子句修改视图)
CREATE OR REPLACE VIEW empview
(emp_id, name, department_id)
AS SELECT employee_id, first_name || ' ' || last_name,
department_id
FROM employees
WHERE department_id = 80;
- 删除视图(删除视图只是删除视图的定义,并不会删除基表的数据)
drop view empview
5, 视图中使用DML的规定
- 可以在简单视图中执行 DML 操作
- 当视图定义中包含以下元素之一时不能使用delete:
组函数
GROUP BY 子句
DISTINCT 关键字
ROWNUM 伪列 - 例如:
create or replace view sal_view
as select
avg(salary) avg_sal from employees
group by department_id
-
当视图定义中包含以下元素之一时不能使用update:
组函数
GROUP BY子句
DISTINCT 关键字
ROWNUM 伪列
列的定义为表达式 -
当视图定义中包含以下元素之一时不能使insert:
组函数
GROUP BY 子句
DISTINCT 关键字
ROWNUM 伪列
列的定义为表达式
表中非空的列在视图定义中未包括
6, 屏蔽 DML 操作
- 可以使用 WITH READ ONLY 选项屏蔽对视图的DML 操作
- 任何 DML 操作都会返回一个Oracle server 错误
CREATE OR REPLACE VIEW empvu10
(employee_number, employee_name, job_title)
AS SELECT employee_id, last_name, job_id
FROM employees
WHERE department_id = 10
WITH READ ONLY;
7, Top-N 分析
`
- 查询最大的几个值的 Top-N 分析:
SELECT ROWNUM, e.empno, e.ename
FROM emp e
WHERE ROWNUM <= 5
ORDER BY e.empno;
- 注意:
对 ROWNUM (伪列)只能使用 < 或 <=, 而用 =, >, >= 都将不能返回任何数据。
序列
1,什么是序列?
- 序列:
可供多个用户用来产生唯一数值的数据库对象
自动提供唯一的数值
共享对象
主要用于提供主键值
将序列值装入内存可以提高访问效率 - 创建序列CREATE SEQUENCE 语句
CREATE SEQUENCE sequence
[INCREMENT BY n] --每次增长的数值
[START WITH n] --从哪个值开始
[{MAXVALUE n | NOMAXVALUE}]
[{MINVALUE n | NOMINVALUE}]
[{CYCLE | NOCYCLE}] --是否需要循环
[{CACHE n | NOCACHE}]; --是否缓存登录
2, 创建序列
- 创建序列EMP_SEQ为表 emp提供主键
CREATE SEQUENCE EMP_SEQ
INCREMENT BY 10
START WITH 120
MAXVALUE 9999
NOCACHE
NOCYCLE;
3,查询序列
- 查询数据字典视图 USER_SEQUENCES 获取序列定义信息
SELECT sequence_name, min_value, max_value,
increment_by, last_number
FROM user_sequences;
- 如果指定NOCACHE 选项,则列LAST_NUMBER 显示序列中下一个有效的值
- NEXTVAL 和 CURRVAL 伪列
- NEXTVAL 返回序列中下一个有效的值,任何用户都可以引用
- CURRVAL 中存放序列的当前值
- NEXTVAL 应在 CURRVAL 之前指定 ,否则会报CURRVAL 尚未在此会话中定义的错误。
Insert into emp(empno,ename) values(seq.nextval,’c’);
4,删除序列
- 使用 DROP SEQUENCE 语句删除序列
- 删除之后,序列不能再次被引用
DROP SEQUENCE emp_seq;
索引
- 一种独立于表的模式对象, 可以存储在与表不同的磁盘或表空间中
- 索引被删除或损坏, 不会对表产生影响, 其影响的只是查询的速度
- 索引一旦建立, Oracle 管理系统会对其进行自动维护, 而且由 Oracle 管理系统决定何时使用索引。用户不用在查询语句中指定使用哪个索引
- 在删除一个表时,所有基于该表的索引会自动被删除
- 通过指针加速 Oracle 服务器的查询速度
- 通过快速定位数据的方法,减少磁盘 I/O
1,创建索引
- 自动创建: 在定义 PRIMARY KEY 或 UNIQUE 约束后系统自动在相应的列上创建唯一性索引
- 手动创建: 用户可以在其它列上创建非唯一的索引,以加速查询
- 在表 EMP的列 LAST_NAME 上创建索引
CREATE INDEX emp_last_name_idx
ON emp(last_name);
2,什么时候需要创建索引
- 以下情况可以创建索引:
列中数据值分布范围很广
列经常在 WHERE 子句或连接条件中出现
表经常被访问而且数据量很大 ,访问的数据大概占数据总量的2%到4%
3,什么时候不要创建索引
-
下列情况不要创建索引:
表很小
列不经常作为连接条件或出现在WHERE子句中
查询的数据大于2%到4%
表经常更新 -
索引不需要用,只是说我们在用name进行查询的时候,速度会更快。当然查的速度快了,插入的速度就会慢。因为插入数据的同时,还需要维护一个索引。
4,查询索引
- 可以使用数据字典视图 USER_INDEXES 和 USER_IND_COLUMNS 查看索引的信息
SELECT ic.index_name, ic.column_name,
ic.column_position col_pos,ix.uniqueness
FROM user_indexes ix, user_ind_columns ic
WHERE ic.index_name = ix.index_name
AND ic.table_name = 'EMP';
5,删除索引
- 使用DROP INDEX 命令删除索引
DROP INDEX emp_last_name_idx;
- 只有索引的拥有者或拥有DROP ANY INDEX 权限的用户才可以删除索引,删除操作是不可回滚的
6,同义词-synonym
- 使用同义词访问相同的对象:
方便访问其它用户的对象
缩短对象名字的长度
CREATE SYNONYM e FOR emp;
select * from e;
7,创建和删除同义词
- 为视图DEPT_SUM_VU 创建同义词
CREATE SYNONYM d_sum
FOR dept_sum_vu;
- 删除同义词
DROP SYNONYM d_sum;
