文章目录
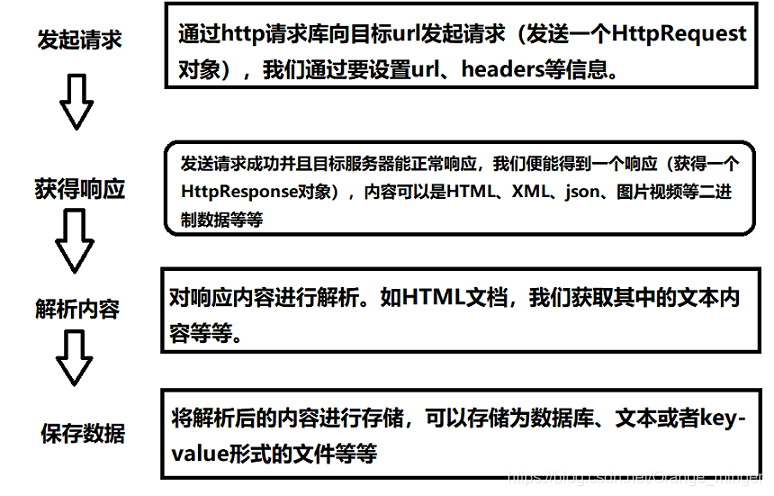
爬虫整个过程主要由三部分组成:抓取页面、解析页面、存储数据。抓取页面需要请求库的支持,解析页面需要解析库的支持,数据存储需要数据库以及连接数据库的包的支持。
1、常用请求库
- requests库:Python3内置了另外一个请求库urllib,但这个库使用起来比较繁琐,一些方法语义上也不是很明确。所以有了requests库,这个库属于第三方库,需要自己另外安装。
- Selenium库:Selenium是一个可以实现自动化爬虫的库,这个库非常强大,可以利用这个库驱动浏览器完成爬取。我们可以写上一些自动化脚本,然后便可以放任程序为我们爬取页面。
- ChromeDriver:ChromeDriver是一个驱动器,想要实现自动化爬虫只有Selenium还不够,还需要驱动器。ChromeDriver是谷歌浏览器的驱动。
- 像驱动的话还有火狐浏览器的驱动,但我觉得火狐用起来没有谷歌那么流畅,就没再用过了。想要爬取简单的页面,通常使用requests + Selenium + ChromeDriver的组合就足够了。
2、常用解析库
- lxml库:lxml库支持HTML和XML的解析,支持XPath的解析方式,而且解析效率非常高。
- Beautiful Soup库:这个库支持HTML和XML的解析,它的优点在于它拥有强大的API,比lxml方便很多,功能也更加强大。
- pyquery库:同样很强大,它的API和jQuery(一款js框架)很相似,熟悉前端的使用起来特别方便。我个人也比较喜欢使用这个库。
- tesserocr库:tesserocr是Python的一个OCR识别库,主要用于识别验证码等等。
3、常用数据库
- 数据库包括关系型数据库和非关系型数据库。我常用的就是MySQL、Redis和MongoDB。
- PyMySQL、PyMongoDB、redis-py库:这三个库都是连接数据库的,类似于Java的数据库驱动。
4、爬取APP相关库
- Charles:是一种抓包修改工具,容易上手,数据请求容易控制,修改简单,抓取数据方便。
- mitmproxy:是一个支持HTTP和HTTPS的抓包程序,能够拦截请求,发起请求等等。
- Appium:类似于Selenium,属于APP端的自动化测试工具。
5、框架
- 框架:如果爬取量不大,速度要求也不大,使用requests+selenium等库完全是满足要求的。但是如果爬取量上来了,许多代码都是重复代码,这时候框架就应运而生了。
- pyspider:pyspider带有WebUI、脚本编辑器、任务监控器、项目管理等等强大功能。
- Scrapy:是一个为了爬取网站数据,提取结构性数据而编写的应用框架。
有错误的地方敬请指出!觉得写得可以的话麻烦给个赞!欢迎大家评论区或者私信交流!
