目录
- TensorBoard简介
- TensorBoard主要API
- 面板介绍
- 执行步骤
- 实例说明
在TensorFlow中,最常用的可视化方法有三种途径,分别为TensorFlow与OpenCv的混合编程、利用Matpltlib进行可视化、利用TensorFlow自带的可视化工具TensorBoard进行可视化。这三种方法中,TensorFlow中最重要的可视化方法是通过tensorBoard、tf.summary和tf.summary.FileWriter这三个模块相互合作来完成的。而且需要结合【TF-2-2】Tensorflow-变量作用域,这一篇文章整合使用。
一、TensorBoard简介
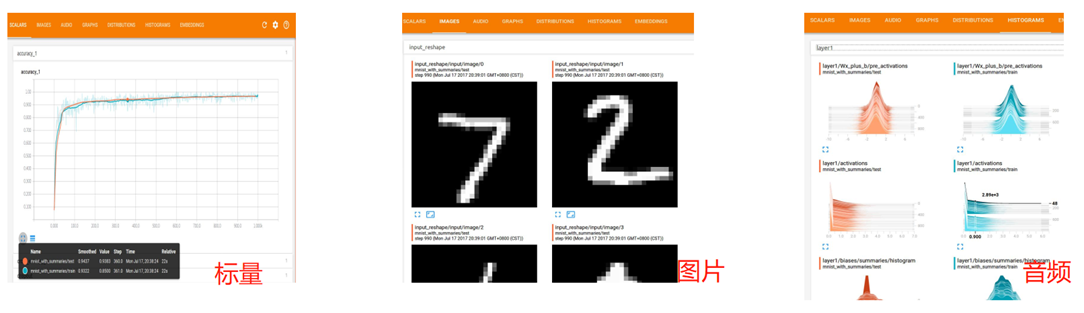
TensorBoard是TensorFlow官方推出的可视化工具,它可以将模型训练过程中的各种汇总数据展示出来,包括标量(Scalar)、图片(Images)、音频(Audio)、计算图(Graphs)、数据分布(Distributions)、直方图(Histograms)和嵌入向量(Embeddings)。在训练大型深度学习神经网络时,中间计算过程非常复杂,为了理解调试和优化我们设计的网络,我们可以使用TensorBoard观察训练过程中各种可视化数据。如果要使用TensorBoard展示数据,我们需要在执行TensorFlow计算图的过程中,将各种类型的数据汇总并记录到日志文件中。然后使用TensorBoard读取这些日志文件,解析数据并生成可视化的Web界面,让我们可以在浏览器中观察各种汇总的数据。
TensorBoard安装:在通过pip安装TensorFlow的情况下,默认也会安装TensorBoard。通过TensorBoard可以展示TensorFlow的图像、绘制图像生成的定量指标以及附加数据等信息
二、TensorBoard主要API
TensorBoard通过读取TensorFlow的事件文件来运行,TensorFlow的事件文件包括了在TensorFlow运行中涉及到的主要数据,比如:scalar、image、audio、histogram和graph等。通过tf.summary相关API,将数据添加summary中,然后在Session中执行这些操作得到一个序列化Summary protobuf对象,然后使用FileWriter对象将汇总的序列数据写入到磁盘,然后使用tensorboard命令进行图标展示,默认访问端口是:6006
API |
描述 |
tf.summary.scalar |
添加一个标量 |
tf.summary.audio |
添加一个音频变量 |
tf.summary.image |
添加一个图片变量 |
tf.summary.histogram |
添加一个直方图变量 |
tf.summary.text |
添加一个字符串类型的变量(一般很少用) |
三、面板介绍
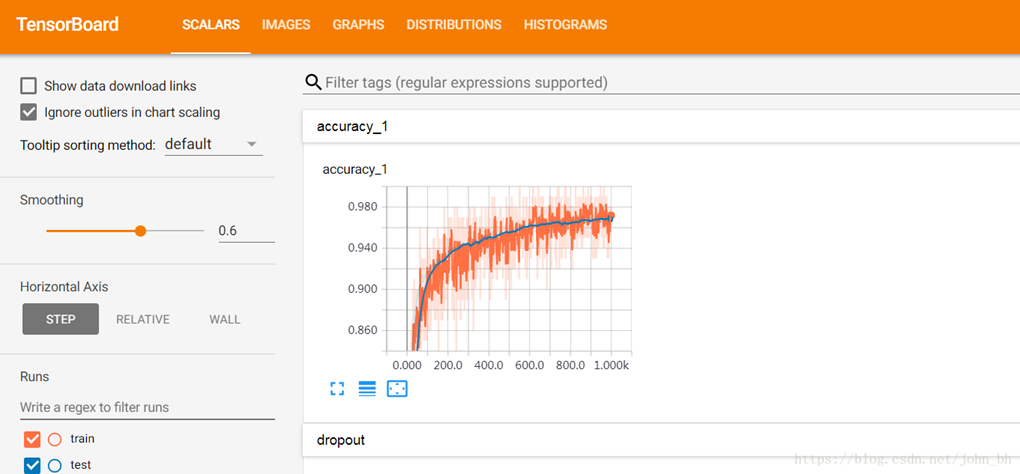
3.1 SCALARS面板
SCALARS 面板,统计tensorflow中的标量(如:学习率、模型的总损失)随着迭代轮数的变化情况。SCALARS 面板的左边是一些选项,包括Split on undercores(用下划线分开显示)、Data downloadlinks(数据下载链接)、Smoothing(图像的曲线平滑程度)以及Horizontal Axis(水平轴)的表示,其中水平轴的表示分3 种(STEP 代表迭代次数,RELATIVE 代表按照训练集和测试集的相对值,WALL 代表按照时间)。图中右边给出了准确率变化曲线。
如下图二所示,SCALARS栏目显示通过函数tf.summary.scalar()记录的数据的变化趋势。如下所示代码可添加到程序中,用于记录学习率的变化情况。
tf.summary.scalar('accuracy', accuracy)
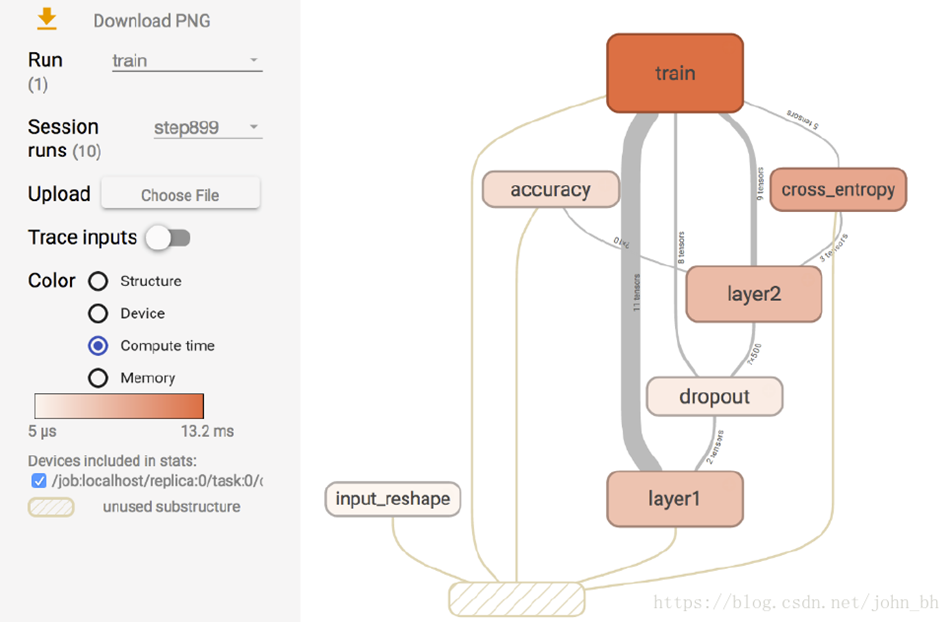
3.2 GRAPHS
GRAPHS 面板是对理解神经网络结构最有帮助的一个面板,它直观地展示了数据流图。下图所示界面中节点之间的连线即为数据流,连线越粗,说明在两个节点之间流动的张量(tensor)越多。
在GRAPHS 面板的左侧,可以选择迭代步骤。可以用不同Color(颜色)来表示不同的Structure(整个数据流图的结构),或者用不同Color 来表示不同Device(设备)。例如,当使用多个GPU 时,各个节点分别使用的GPU 不同。当我们选择特定的某次迭代时,可以显示出各个节点的Compute time(计算时间)以及Memory(内存消耗)。
四、执行步骤
4.1 运行编写好的程序,"logs"文件夹下得到保存文件
4.2 打开cmd(必须给定对应的数据聚合文件路径信息(tensorboard --logdir path/to/logs)),进入logs文件夹同级目录
4.3 运行 tensorboard --logdir=logs (注意不要用"logs")
4.4 打开Google Chrome(其他浏览器不保证),输入:http://localhost:6006.
五、实例说明
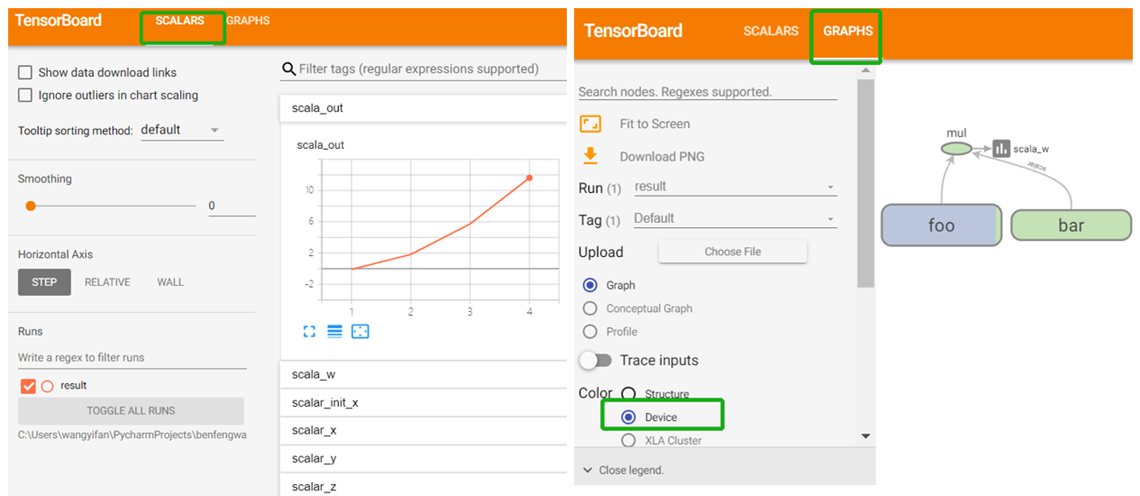
本实例采用tf.summary.scalar API进行说明:
- 代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import tensorflow as tf with tf.variable_scope("foo"): with tf.device("/cpu:0"): x_init1 = tf.get_variable('init_x', [10], tf.float32, initializer=tf.random_normal_initializer())[0] x = tf.Variable(initial_value=x_init1, name='x') y = tf.placeholder(dtype=tf.float32, name='y') z = x + y # update x assign_op = tf.assign(x, x + 1) with tf.control_dependencies([assign_op]): with tf.device('/gpu:0'): out = x * y with tf.device('/gpu:0'): with tf.variable_scope("bar"): a = tf.constant(3.0) + 4.0 w = z * a # 开始记录信息(需要展示的信息的输出) tf.summary.scalar('scalar_init_x', x_init1) tf.summary.scalar(name='scalar_x', tensor=x) tf.summary.scalar('scalar_y', y) tf.summary.scalar('scalar_z', z) tf.summary.scalar('scala_w', w) tf.summary.scalar('scala_out', out) with tf.Session(config=tf.ConfigProto(log_device_placement=True, allow_soft_placement=True)) as sess: # merge all summary merged_summary = tf.summary.merge_all() writer = tf.summary.FileWriter('./result', sess.graph) # 得到输出到文件的对象 sess.run(tf.global_variables_initializer()) # 初始化 for i in range(1, 5): summary, r_out, r_x, r_w = sess.run([merged_summary, out, x, w], feed_dict={y: i}) writer.add_summary(summary, i) print("{},{},{}".format(r_out, r_x, r_w)) writer.close() # 关闭操作 |
1)ensorBoard显示的时候,必须给定对应的数据聚合文件路径信息(tensorboard --logdir path/to/logs)。再浏览器输入:http://localhost:6006.
2)进入对应环境,cmd输入:
tensorboard --logdir C:\Users\wangyifan\PycharmProjects\benfengwangML202003\DeepLearning01

3)浏览器:http://localhost:6006
运行结果:方便查看和趋势和网络。