为了更好地提取信息,我们就需要先了解信息的标记方法,目前网页普遍使用HTML(HyperText Markup Language),可以说明文字,声音,图像,视频和链接的超文本标记语言
HTML基本格式


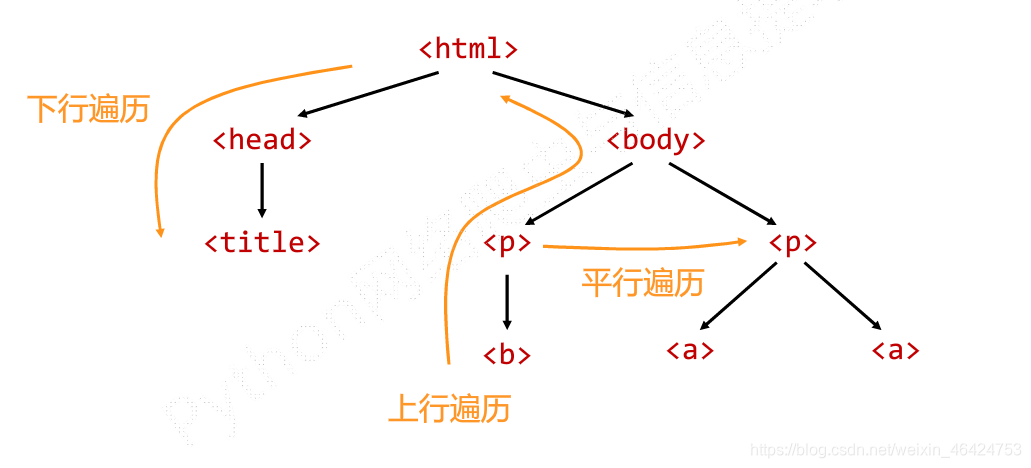 这三个可等同看待
这三个可等同看待

HTML(标签树)内容遍历需要使用beautifulsoup库(安装beautifulsoup4),其是解析,遍历,维护标签树的功能库

beautifulsoup库有四种解析库,我们正常就用第一种解析HTML
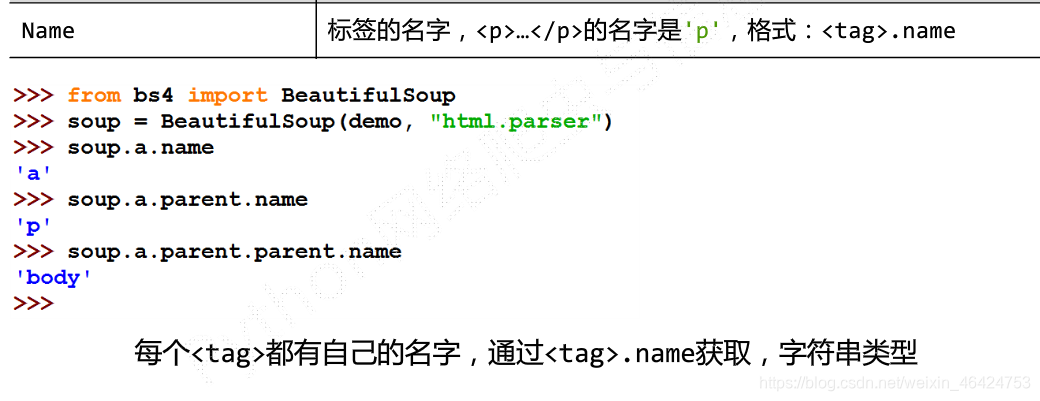
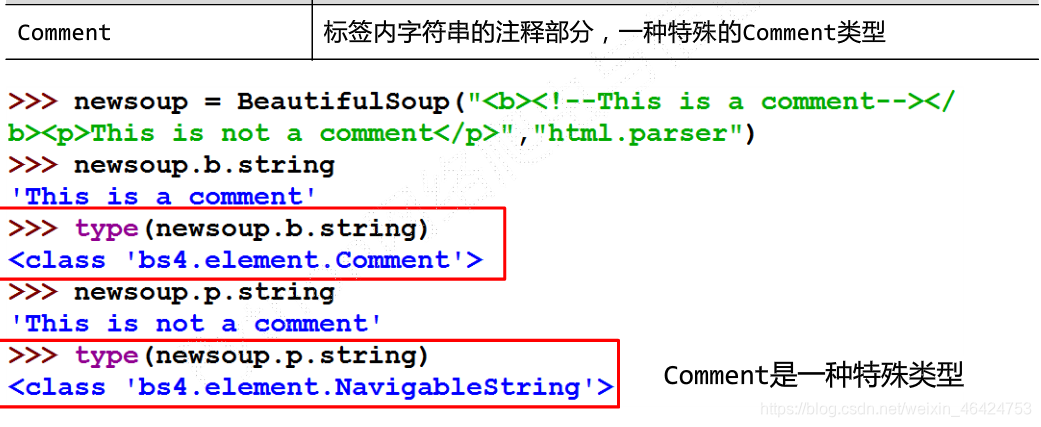
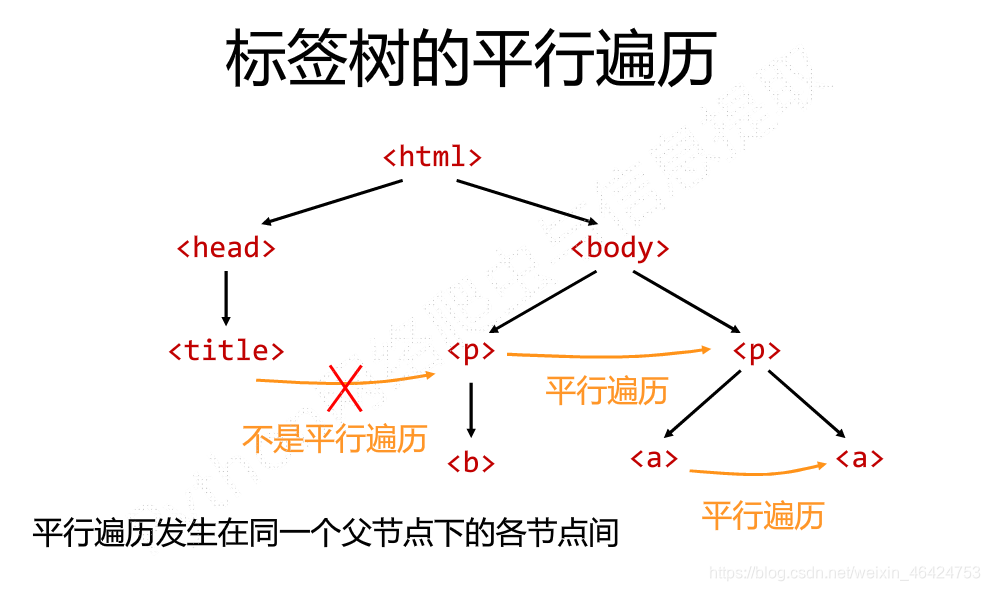
 基本元素
基本元素







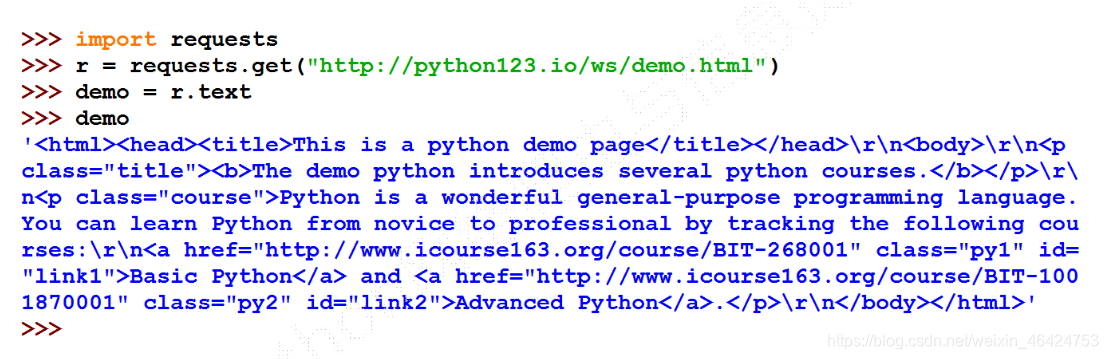
 我们在得到HTML内容后会发现其十分杂乱,内容不清晰
我们在得到HTML内容后会发现其十分杂乱,内容不清晰
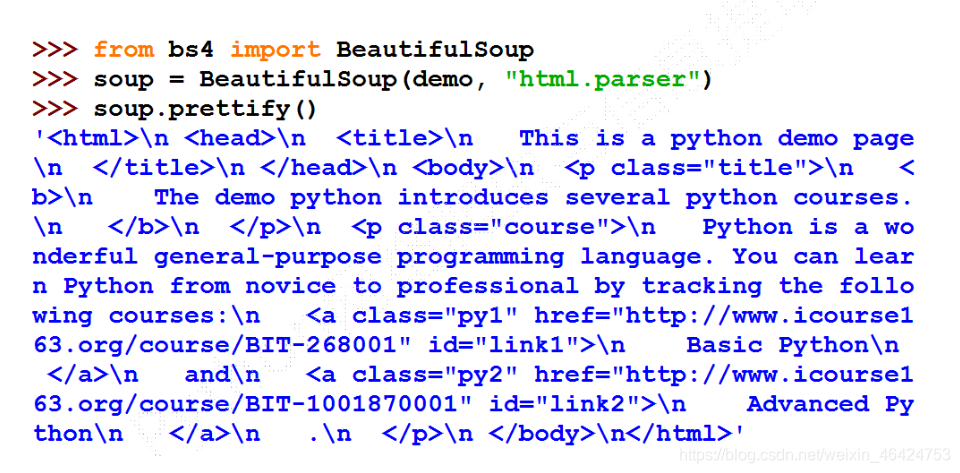
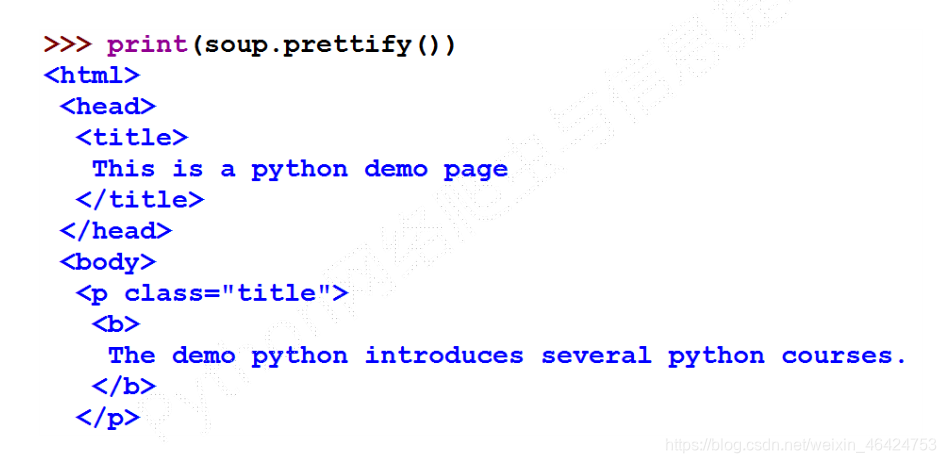
 这是我们可以使用bs4库中的prettify()
这是我们可以使用bs4库中的prettify()

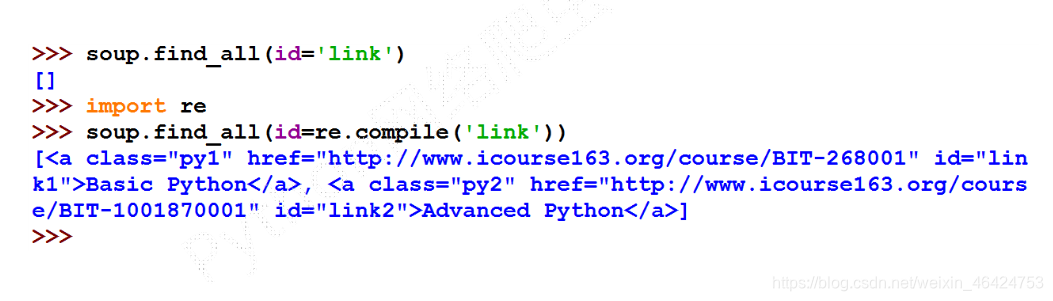
 对特定内容的检索
对特定内容的检索



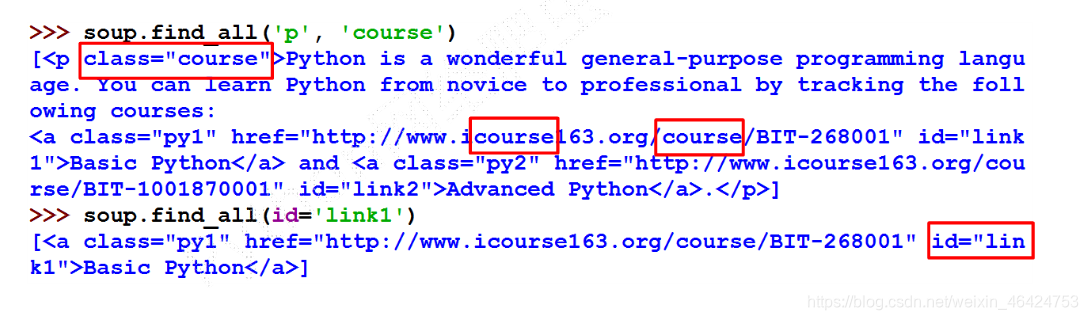


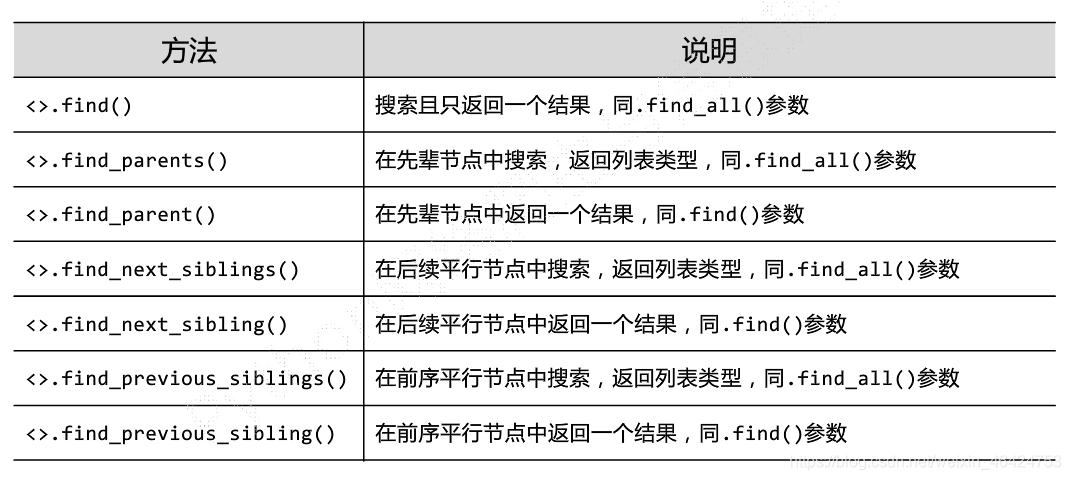 知识点十分多且琐碎,需慢慢消化,下篇文章会讲实例,进行实战。
知识点十分多且琐碎,需慢慢消化,下篇文章会讲实例,进行实战。
