理论介绍
Kmeans算法
k-means算法又称k均值,是一种无监督的机器学习方法,通过多次求均值实现聚类。即无需知道所要搜寻的目标,而是直接通过算法来得到数据的共同特征。如图所示,通过找到合适的K值和合适的中心点,来实现目标的聚类。

其具体算法思想实现过程如下:
1.指定簇的个数
2.随机选取K个中心点
3.将每条记录归到离它最近的中心点所在的簇中
4.以各个簇的记录均值的中心点取代之前的中心点
5.不断迭代,直到收敛
优化目标
k-means的损失函数是平方误差:
其中表示第k个簇,表示第k个簇的中心点,是第k个簇的损失函数,表示整体的损失函数。优化目标就是选择恰当的记录归属方案,使得整体的损失函数最小。
K值选取
k-meams算法的能够保证收敛,但不能保证收敛于全局最优点,当初始中心点选取不好时,只能达到局部最优点,整个聚类的效果也会比较差。可以采用以下方法选取k-means中心点:
1、选择彼此距离尽可能远的那些点作为中心点;
2、先采用层次进行初步聚类输出k个簇,以簇的中心点的作为k-means的中心点的输入。
3、多次随机选择中心点训练k-means,选择效果最好的聚类结果
k-means的误差函数有一个很大缺陷,就是随着簇的个数增加,误差函数趋近于0,最极端的情况是每个记录各为一个单独的簇,此时数据记录的误差为0,但是这样聚类结果并不是我们想要的,因此在数据训练过程中需要选取合适的K值。
实验过程
1.数据处理
实验数据集是从新浪新闻THUCNews中筛选的150篇新闻,分为三类:体育,星座,游戏。
读取数据集。按文件夹遍历每篇文章,把每一条新闻进行分词,保存为wordlist,所有记录保存在datalist,所有类别保存在label.
for file in files:
with open(os.path.join(new_floder_path,file),mode="r",encoding="utf-8") as fp:
Word = fp.read()
list = []
word_1 = Word.replace("\n"," ")
seglist = jieba.cut(word_1)
for word in seglist:
word = word.strip()
if word not in stopword:
list.append(word)
a = ' '.join(list)
list_all.append(a)
if floder == "体育":
label.append(0)
elif floder == "星座":
label.append(1)
else:
label.append(2)
return list_all,label
打乱排序,并按2:1比例划分为训练集和测试集。
#todo:划分训练集,测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(TFIDF,label,test_size=0.33,random_state=1)
因为kmeans是一个无监督学习,在实验中,引入外部模型朴素贝叶斯模型作为对照实验,判断分类效果。训练集用于朴素贝叶斯模型训练,测试集用于kmeans聚类和朴素贝叶斯预测。
2.训练词向量
去停用词部分不再细说,数据进行基本的清洗后,转化为向量
# TODO:训练词向量
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
vec=CountVectorizer() # 使用前必须实例化!!!
tf = TfidfTransformer()
x = []
X = vec.fit_transform(list_all)
TFIDF = tf.fit_transform(X) # 文本语料转化为词向量矩阵
x为一个列表,列表中的每一行元素代表的是一个文档,每个文档由多个向量组成。
3.kmeans文本聚类
# TODO:k-MEANS进行聚类
from sklearn.cluster import KMeans
for i in range(3,20):
#n_clusters = i
kmean = KMeans(n_clusters=i,random_state=1)
kmean.fit(X_test)
print("K值:",i,"kmeans聚类结果:",kmean.labels_)

在这里尝试了不同的K值,但难以从聚类结果观察到其真实类别,也无法评估聚类情况。
引入手肘法进行判别,手肘法的核心思想是:随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么误差平方和SSE自然会逐渐变小。并且,当k小于真实聚类数时,由于k的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大,而当k到达真实聚类数时,再增加k所得到的聚合程度回报会迅速变小,所以SSE的下降幅度会骤减,然后随着k值的继续增大而趋于平缓,也就是说SSE和k的关系图是一个手肘的形状,而这个肘部对应的k值就是数据的真实聚类数。
from sklearn import metrics
print(metrics.adjusted_rand_score(y_test, kmean.labels_))
绘制簇内误差平方和曲线图如下:

观察可知,kmeans模型中,手肘的位置在3,符合真实聚类数。
当K=3时,聚类结果如下:
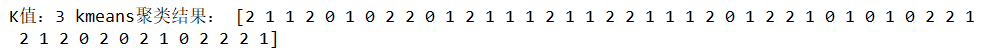
4.朴素贝叶斯模型分类
# todo:朴素贝叶斯分类器
from sklearn.naive_bayes import MultinomialNB
nbc = MultinomialNB()
nbc.fit(X_train,y_train)
print("朴素贝叶斯预测结果:",nbc.predict(X_test))
print("朴素贝叶斯测试准确率",nbc.score(X_test,y_test))
print("真实结果:",y_test)
朴素贝叶斯分类结果:
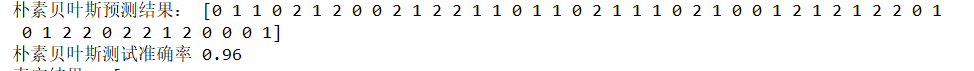
朴素贝叶斯的准确率为0.96。
5.模型评价
因为kmeans聚类只是把可能属于同一类的样本聚在一起,它的预测标签仅表示相同标签的样本属于一类,不能表示它的真实类别。

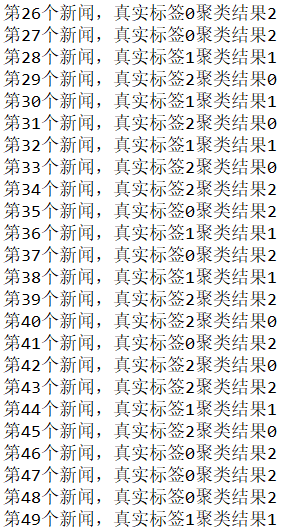
观察可知,聚类标签0对应真实标签2,聚类标签1对应真实标签1,聚类标签2对应真实标签0。错误聚类的样本为:



观察可知,有三个样本被分类错误,这三个样本都是标签为2的娱乐类新闻,有两条被误分到体育类,1条被误分到星座类。总体来看,kmeans取得了较好的聚类效果。
