今天使用python爬取了2页天堂图片网的图片并保存到事先准备好的文件夹。网址:https://www.ivsky.com/tupian
下面来讲述一下爬取流程:
①:首先,我们进入天堂图片网,查看每一页图片网址的相同与不同之处,以便我们爬取:
第一页网址如下:

第二页网址如下:

第三页网址如下:

好的,经过我们的细心发现,我们找到了猫腻,没错,除了第一页,每一页的网址都为https://www.ivsky.com/tupian/index_页码.html这种格式。
②:然后,我们又发现每一页中的封面图片之内还包含多张图片,我们右击图片进行检查:

链接①为多图片链接(进入可查看其它图片),链接②为封面图片的链接:

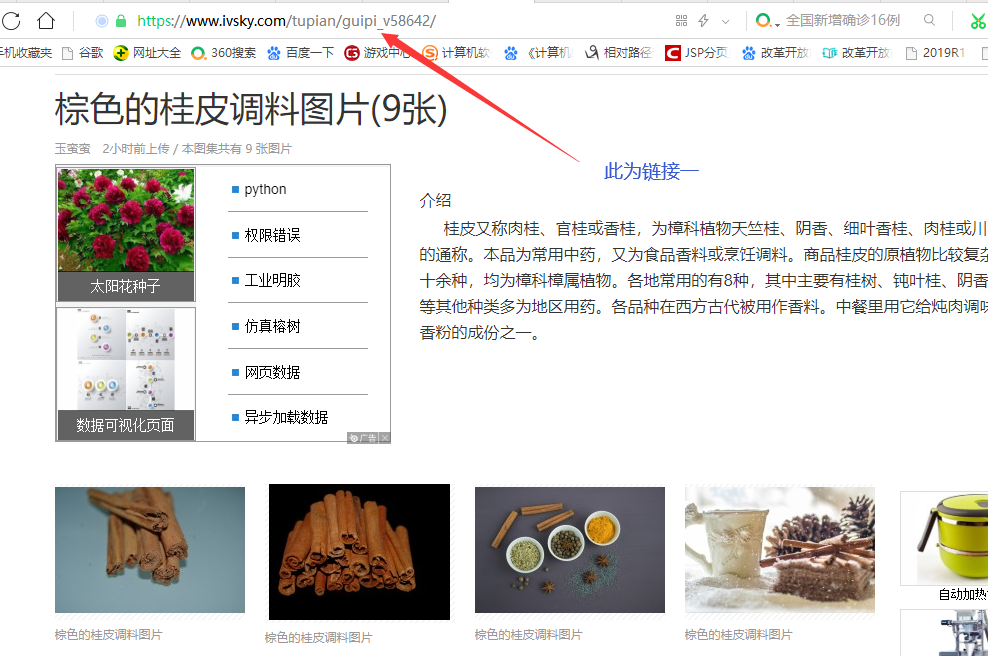
③:我们进入链接①并以同样的方式查看第一张图片的代码:

好的,至此我们知道,我们要爬取的图片的url就为上图所示的url,只要爬取到每个图片的url,那么我们就可以爬取每张图片存放到文件夹啦。
下面我们的思路就很清晰了:
①:爬取给定页码的代码中的封面图片url
②:根据封面图片url进入内部,并查找每张图片url
③:根据获取的所有图片url爬取图片存入准备好的文件夹
函数说明:
①:get_html(url):参数url为每页的url;
②:get_big_url(url):参数url为每一页的url,返回值为list列表,list列表存放该页所有大图片的url;
③:get_little_url(url):参数url为一个大图片的url,返回值为list列表,list列表存放该大图片内部所有小图片的url;
④:save(folder,little_url):参数folder为事先准备好的存放图片的文件夹,参数little_url为每页所有大图片包含的小图片的url,无返回值;
⑤:get_picture(url):参数url为每一页的url,该函数目的在于协调各个函数,体现了各个函数间的调用顺序;
⑤:if __name == '__main__':执行脚本
好的,接下来我们上代码:(下面的标注中的大图片url指代封面url,小图片url指代内部图片url)
get_html(url)函数,用来根据给定url爬取相应页面源码
get_big_url(url)函数:
def get_big_url(url): #获取网页代码 html = get_html(url).decode('utf8') #big_img_url存放大图片的网址 big_url = [] a = html.find("il_img") + 17 ##查询不到时a=-1,但是因为a = find +17,所以查询不到时为16 while a != 16: b = html.find('"', a) if b != -1: #new_url存放大图片的网址 new_url = "https://www.ivsky.com/" + html[a:b] # 将大图片地址放入列表big_url big_url.append(new_url) else: break #寻找下一个 a = html.find("il_img",b) + 17 return big_url
解释:
①为:将根据该页url爬取的代码放入html;
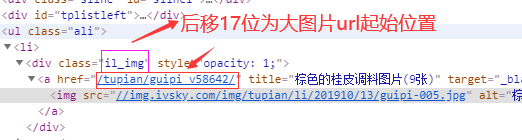
②为:在代码中查找“il_img”所在位置,后移17位为大图片url起始位置:
a = html.find("il_img") 返回的是"i"在整个源码中的位置。
③为:在源码中若找不到字符串"il_img",则返回a的值应为-1,但是因为在第二步我们将a的值加了17,所以找不到的情况下为16(这是基于源码中第16位不是我们要找的字符串的情况下,才可以这么写)。所以这句话表示,当我们找得到“il_img”时,执行下面语句。
④为:寻找a所在位置后的字符串引号
⑤为:若找得到引号,则执行下面语句
⑥为:html[a:b]为取源码中的a至b部分的字符串,并加上前缀“https://www.ivsky.com/”为大图片url
⑦为:将大图片url存放进数组big_url中
⑧为:若找到a找不到b则退出循环
⑨为:当找完一个大图片url后,我们要寻找下一个,那么我们就要从b所在位置起重新寻找字符串"il_img"所在位置,加17原因见②
最终返回值为存放所有大图片url的list列表
get_little_url(url)函数:该函数与获取大图片url的函数get_big_url(url)极为相似,故在此不做多余解释。
#参数url为大图片的url def get_little_url(url): # 获取网页代码 html = get_html(url).decode('utf8') # little_img_url存放小图片的网址 little_url = [] a = html.find('<img src="//') +10 while a != 9: b = html.find('.jpg', a, a+100) if b != -1: #new_url存放小图片的网址 new_url = "http:" + html[a:b+4] #将小图片地址放入数组little_url little_url.append(new_url) else: break a = html.find('<img src="//',b) + 10 return little_url # 返回小图片网址列表
save(folder,little_url)函数:
#将所有图片爬取并存入事先准备好的文件夹 def save(folder,little_url): for each_url in little_url: #下载的图片名称: filename = each_url.split("/")[-1] # print(each_url) path = folder + "\\" + filename with open(path,"wb") as f: #爬取图片 picture = get_html(each_url) f.write(picture) print("图片",filename,"爬取成功!")
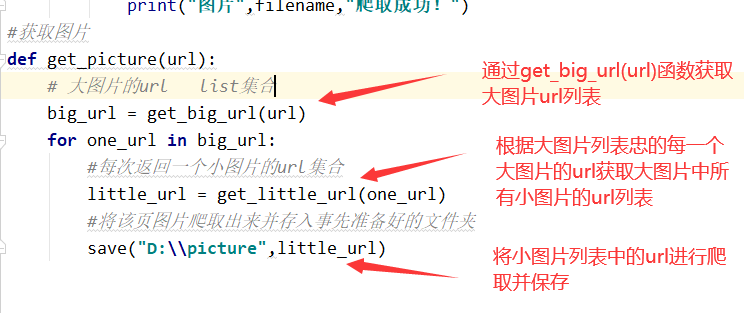
get_picture(url)函数
#获取图片 def get_picture(url): # 大图片的url list集合 big_url = get_big_url(url) for one_url in big_url: #每次返回一个小图片的url集合 little_url = get_little_url(one_url) #将该页图片爬取出来并存入事先准备好的文件夹 save("D:\\picture",little_url)
执行脚本:
1 if __name__ == '__main__': 2 # 循环page次,每次查找一页的图片集合 3 for page in range(1,3): 4 if page == 1: 5 url = "https://www.ivsky.com/tupian/" 6 else: 7 url = "https://www.ivsky.com/tupian/index_"+str(page)+".html" 8 print("总网址:",url) 9 get_picture("https://www.ivsky.com/tupian/") 10 print("爬取完成")
解析:

完整代码:


1 import urllib.request 2 import urllib.parse 3 import random 4 def get_html(url): 5 req = urllib.request.Request(url) 6 req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36 QIHU 360SE') 7 8 # IPList = ["122.224.65.201:3128","27.154.34.146:31527"] 9 # proxy = random.choice(IPList) 10 # proxy_supprot = urllib.request.ProxyHandler({"https:":proxy}) 11 # opener = urllib.request.build_opener(proxy_supprot) 12 # urllib.request.install_opener(opener) 13 14 response = urllib.request.urlopen(url) 15 html = response.read() 16 return html 17 18 #获取大图片的网址 19 def get_big_url(url): 20 #获取网页代码 21 html = get_html(url).decode('utf8') 22 #big_img_url存放大图片的网址 23 big_url = [] 24 a = html.find("il_img") + 17 25 ##查询不到时a=-1,但是因为a = find +17,所以查询不到时为16 26 while a != 16: 27 b = html.find('"', a) 28 if b != -1: 29 #new_url存放大图片的网址 30 new_url = "https://www.ivsky.com/" + html[a:b] 31 # 将大图片地址放入数组big_url 32 big_url.append(new_url) 33 else: 34 break 35 #寻找下一个 36 a = html.find("il_img",b) + 17 37 return big_url 38 39 #参数url为大图片的url 40 def get_little_url(url): 41 # 获取网页代码 42 html = get_html(url).decode('utf8') 43 # little_img_url存放小图片的网址 44 little_url = [] 45 a = html.find('<img src="//') +10 46 while a != 9: 47 b = html.find('.jpg', a, a+100) 48 if b != -1: 49 #new_url存放小图片的网址 50 new_url = "http:" + html[a:b+4] 51 #将小图片地址放入数组little_url 52 little_url.append(new_url) 53 else: 54 break 55 a = html.find('<img src="//',b) + 10 56 return little_url 57 # 返回小图片网址列表 58 59 #将所有图片爬取并存入事先准备好的文件夹 60 def save(folder,little_url): 61 for each_url in little_url: 62 #下载的图片名称: 63 filename = each_url.split("/")[-1] 64 # print(each_url) 65 path = folder + "\\" + filename 66 with open(path,"wb") as f: 67 #爬取图片 68 picture = get_html(each_url) 69 f.write(picture) 70 print("图片",filename,"爬取成功!") 71 #获取图片 72 def get_picture(url): 73 # 大图片的url list集合 74 big_url = get_big_url(url) 75 for one_url in big_url: 76 #每次返回一个小图片的url集合 77 little_url = get_little_url(one_url) 78 #将该页图片爬取出来并存入事先准备好的文件夹 79 save("D:\\picture",little_url) 80 81 82 83 84 85 if __name__ == '__main__': 86 # 循环page次,每次查找一页的图片集合 87 for page in range(1,3): 88 if page == 1: 89 url = "https://www.ivsky.com/tupian/" 90 else: 91 url = "https://www.ivsky.com/tupian/index_"+str(page)+".html" 92 print("总网址:",url) 93 get_picture(url) 94 print("爬取完成")
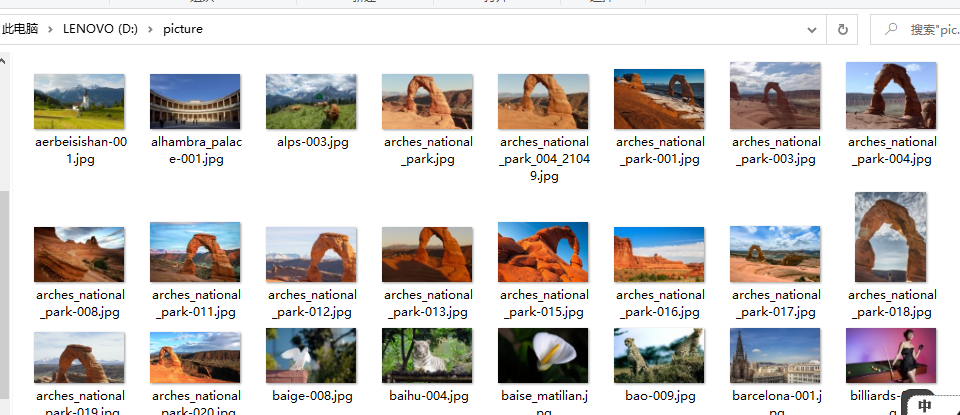
结果:
总结:
这次爬取天堂图片网用了半天时间,主要时间用于获取大图片小图片的url,在源码中查询字符串时,由于查询字符串之后对a与b进行了改变,所以跳出循环的条件不为a ==-1,而应是-1加上进行的偏移。