1、性能、并发、稳定性三者关系
高性能:高吞吐量、低延时
公式:吞吐量(并发)=单位时间/平均延时
N-th% Latency:TP99, TP999
稳定性:低延时的稳定性标准为TP99/TP999是隐含的必要条件;系统的稳定性标准:高+可用;用户标准
吞吐量:QPS, TPS,OPS等等,并发。并不是越高越好,需要考虑TP99。用户角度:系统是个黑盒,复杂系统中的任何一环到会导致稳定性问题。SLA:在某种吞吐量下能提供TP99为n毫秒的服务能力。降低延时,会提高吞吐量,但是延时的考核是TP99这样的稳定的延时。
2、如何改善延时
你应该知道如下表格
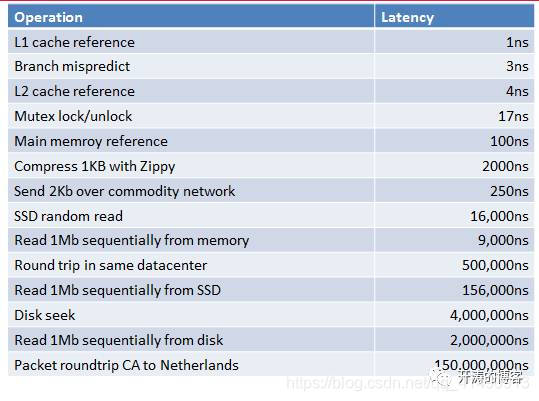
原文:
http://www.eecs.berkeley.edu/~rcs/research/interactive_latency.html
Jeff Dean(互联网战神)
Disk random read IOPS:
IOPS = 1000 / (4 + 60000/7200/2) = 122
IOPS = 1000 / (4 + 60000/10000/2) = 142
IOPS = 1000 / (4 + 60000/15000/2) = 166
SSD random read IOPS:
IOPS = 1000000/16=62500
数字的启示
高速缓存的威力;
线程切换代价cache miss
顺序写优于随机写
局域网络快于本地HDD
大块读优于小块读
SSD解决随机读写
跨地域IDC网络是最大的延时
策略
关键路径:“28原则”(20%的代码影响了80%的性能问题,抓重点)、“过早优化是万恶之源”。不同解读;
优化代码:空间换时间:各级缓存;时间换空间:比如传输压缩,解决网络传输的瓶颈;多核并行:减少锁竞争;lesscode;各类语言、框架、库的trick;算法+数据结构,保持代码的清晰、可读、可维护和扩展;
通过性能测试和监控找出瓶颈
metric
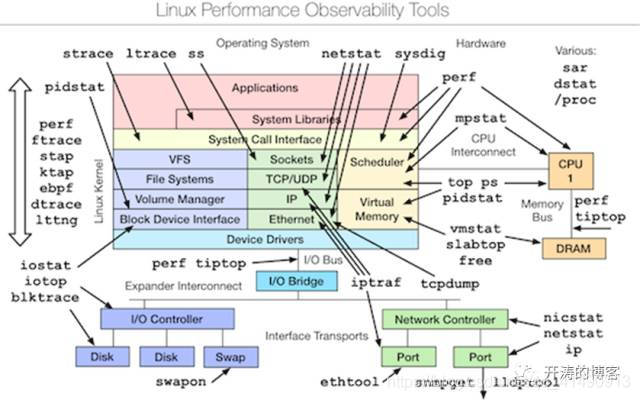 原文:http://www.vpsee.com/2014/09/linux-performance-tools/
原文:http://www.vpsee.com/2014/09/linux-performance-tools/
通过性能测试和监控:
单系统operf/jprofiler etc;
Java的一系列工具:jstat, jstack, jmap, jvisualvm,HeapAnalyzer, mat
分布式跟踪系统:Dapper,鹰眼等
benchmark
 原文:http://www.vpsee.com/2014/09/linux-performance-tools/
原文:http://www.vpsee.com/2014/09/linux-performance-tools/
微观
内存分配
吞吐量和利用率的权衡
显式分配器:jemalloc/tcmalloc代替默认的ptmalloc
隐式分配器:JVM GC的各种调优
是否使用hugepagen预分配和重用:Netty的Pooled ByteBuf
减少拷贝:new ArrayList(int), new StringBuilder(int)
内存分配器利用率:减少内部或外部碎片;Page Table(页表), TLB(页表寄存器缓冲),减少TLB miss,pin cache。增加COW的开销, 与内存分配器的实现冲突。JVM的GC调优是很多Java应用的关注重点。
减少系统调用
批处理: buffer io,pipeline
使用用户态的等价函数: gettimeofday ->clock_gettime
减少锁竞争
RWMutex
CAS
Thread local
最小化锁范围
最小化状态,不变类
批处理增加了内存拷贝的开销,但是减少了系统调用开销,减少了上下文切换的影响。bufferio的例子:日志、网络读写。pipeline的例子:redis。
减少上下文切换
触发:中断、系统调用、时间片耗尽、IO阻塞等
危害:L1/L2 Cache Missing,上下文保存/恢复
单线程:基于状态机redis和Master/Worker的nginx
CPU亲和性绑定
ThreadPool的配置,不同任务类型不同的ThreadPool
几个例子:1、docker中线程池大小的核数自动设定;2、CPU节能模式;3、CENTOS-7.1内核BUG。
网络
内核TCP Tuning参数和SocketOption:net.ipv4.tcp_*
TCP Socket连接池
网络I/O模型
传输压缩
编解码效率
超时、心跳和重试机制
网卡:多队列中断CPU绑定;增加带宽:万兆、Bonding;Offload特性:ethtool -k eth0;UIO Driver: DPDK
连接池:减少握手、减少服务端session创建消耗。网络I/O模型:BIO、Non-Blocking IO、AIO;select/poll、epoll/kqueue、aio;netty使用nativetransport。Offload特性:ethtool-k eth0。 将数据包分组、重组、chksum等从内核层放到硬件层做。
3、如何提高吞吐量
改善和降低单机的延时,一般就能提高我们的吞吐量。从集群化上讲,因素就比较多。
宏观
提升系统扩展能力
应用的无状态架构
缓存/存储的集群架构:冗余复制(负载均衡、异构解除系统依赖);分布式(数据sharding , 副本,路由,数据一致性);切换
微服务/SOA
扩容
异步化
缓存
复制
通过复制提高读吞吐量、容灾、异构
通过数据分片,提高写吞吐量
程序双写:一致性难以控制,逻辑复杂,幂等性要求。完全把控复制和切换时机。异构系统唯一选择。 同步双写(数据一致性高,影响性能,不适合多个复制集); 异步双写(数据一致性差,性能高,适合多个复制集);CDC[Change Data Capture](canal,databus等)
底层存储复制机制:一致性由底层控制,对应用端透明。程序和底层存储配合切换
扩容
每年大促前的核心工作:该扩容了吗?现状分析;扩容规划(关键系统峰值20倍吞吐量);扩容依据(架构梳理、线上压测);
扩容checklist:前(部署、DB授权…);后(配置更新、LB更新、接入日志、接入监控…)
应用扩容、数据扩容、写扩容、读扩容
垂直扩容:加内存、升级SSD、更换硬件。数据复制、切换
水平扩容:数据迁移或初始化
现状分析:去年双十一到目前,峰值时的性能数据;软硬件性能指标;数据存储容量。
扩容规划;流量规划:核心系统20倍吞吐量;数据增长量规划;扩容依据;架构梳理;线上压测。
读扩容比写扩容难;读写分离。
异步化
解耦利器
削峰填谷
页面异步化
系统异步化
JMQ
状态机(worker)+DB
本地队列
集中式缓存队列
本地内存队列:实时价格回源服务响应之后,通过BlockingQueue异步更新前端缓存。本地日志队列:库存预占。集中式缓存队列:商品变更任务下发系统。
异步化的一些例子:
1、操作系统内核的高速缓存队列,磁盘延迟刷盘;
2、mysql数据库复制、redis复制;
异步化需要注意的是:
1、任务要落地;
2、不可避免的重复执行,需要幂等;
3、是否需要保证顺序、如何保证顺序。
缓存
久经考验的局部性原理
多级缓存:浏览器browser cache、cdn、nginx本地redis缓存、本地JVM缓存、集中式缓存…
缓存前置:2/8原则、单品页、实时价格、库存状态
一致性、延迟权衡
缓存主节点负责写,和最重要的校验
通过CDC监听数据库binlog主动更新缓存
CPU不是瓶颈,网络才是
优化编码,减少尺寸
优化操作
优化拓扑
4、如何保障稳定性
宏观
提高可用性
分组和隔离
限流
降级
监控和故障切换
可用性
可用性衡量指标:几个9
可用性度量:A = MTBF / (MTBF + MTTR)
减少故障、加长可用时间
减少故障修复时间(发现、定位、解决)
冗余复制、灾备切换,高可用的不二法门
如何快速切换?
切换的影响
监控、ThoubleShooting、软件质量的影响
可行性指标:999,一周10分钟;9999,一周1分钟不可用。可用性:从客户角度。可用性度量:A = MTBF / (MTBF + MTTR) ,其中MTBF表示mean time betweenfailures,而MTTR表示maximum time to repair or resolve。
高可用行性的成本和收益,好钢用在刀刃上。
如何快速切换:有可以切换的?可以不重启应用么?操作快捷么?演练过么?
切换的影响:切换目标资源能否承受新增的压力;切换是否影响状态(数据的一致性、丢失问题)。
监控到位、即时,减少故障发现时间;监控全面,增加故障分析时可以参考的数据。
troubleshooting的能力,踩坑的精力, COE,问题本质、根源的追查。
软件质量:编码是否健壮、(异常处理、防御性、2/8原则)超时处理、日志是否全面合理、线程名称等等。
测试:case是否全面、自动回归。
上线:是否灰度:N+1, N+2;回滚方案、数据回滚。
分组和隔离
网络流量隔离:大数据单独部署,QOS;
业务系统隔离:秒杀系统独立出主交易;
流量分组:对使用者按照重要程度、请求量、SLA要求等因素分级
存储的分组:按照使用者重要程度、实时性要求等因素,将数据库的复制集分组
传统世界的例子:道路被划分为高速道路、自行道、人行道等,各行其道。
流量分组
举例:商品基础信息读服务。对使用者按照重要程度、请求量、SLA要求等因素分级,将服务实例和存储分组:交易、生产、网站、移动、promise、ERP…
读写分离
举例:商品主数据服务。按照使用者重要程度、实时性要求等因素,将数据库分组:ERP、POP、网站、大数据平台…
限流
限流原则:影响到用户体验,谨慎使用
区分正常流量和超预期流量:限流标准来自压力测试、折算
读少限,写多限
客户端配合限流
不同分组的限流阈值
各层限流手段
前置限流,快速失败:比如通过提供给调用方的JSF客户端,封装限流逻辑。
Nginx层限流:自主研发的模块;几个规则:账户,IP,系统调用流程。
应用限流:减少并发数线程数;读少限,写多限;DB限流;连接数。
降级
保证用户的核心需求
降级需要有预案和开关:确定系统和功能级别,是否可降,影响如何;降级需要有开关
非关键业务屏蔽:购物车的库存状态
业务功能模块降级:实时价格更新不及时;peking库,保订单管道、生产,暂停统计相关
数据降级:动态降级到静态;远程服务降级到本地缓存:采销岗服务
监控和切换
无所不在的监控:网络流量;操作系统指标;服务接口调用量、TP99、错误率…;日志;业务量变化;太多监控了,如何提高监控的质量
切换:切换开关;成熟的流程可自动化;数据的重要性、一致性,要求强一致的,可以人工介入;系统的指标没法判断、监控点不全的,需人工判断决定
review

Nginx层限流:自主研发的模块;几个规则:账户,IP,系统调用流程。
应用限流:减少并发数线程数;读少限,写多限;DB限流;连接数
5、如何验证性能和稳定性
线上压测:两类压力测试场景(读业务压测、写业务压测);压力测试方案(从集群中缩减服务器、复制流量、模拟流量、憋单)
全流程演练:降级、切换等
读业务压力测试:是将线上业务隔离后,压测至系统临界点,通过分析系统在临界点时软硬件指标定位系统短板并优化。
写逻辑压力测试,如果数据具有不可恢复性,一定要提前做好数据隔离保护,如订单号压测,为避免影响线上业务,压测前后都要做好“跳号”以隔离线上数据。
从集群中缩减服务器。加大单台服务器的压力。大概估算出正常的集群规模能够承载的流量。
复制流量。主要通过 Tcpcopy 复制端口流量,多层翻倍放大流。
模拟流量。模拟流量主要脚本攻击工具和压测工具结合,主要用ab,siege,webbench,loadruner通过多台机器压测。分机房,按分支进行压测。
憋单。主要针对后续的订单生产系统压测。通过在管道积压一批订单,然后快速释放,形成对后续生产系统持续快速的冲击,达到压测的目的。
