一、稳定性的定义
量化平台的稳定性通常有两种方式,首先是平台的可用性,其次是线上问题和线上故障。
可用性一般等于(年度总时间 - 网站不可用时间) / 年度总时间
可用性的标准通常以几个九来衡量,比如四个九,即 99.99%的可用性,即平台全年的不可用时间不能超过0.01% * 365 * 24 * 60 = 52.56分钟。这是一个严峻的挑战。
线上故障通常指大规模地影响到了平台服务的质量甚至是可用性,通常分为P1/P2/P3/P4四个等级,一般称为P1/P2为重大故障。故障不一定会影响可用性,可用性有影响一定是有故障发生。
线上问题是指平台服务的小问题,小Bug,没有故障那么严重,但一定程度可以反映平台的稳定性。
稳定性的目标通常是 杜绝一切故障隐患,在上线前保证问题的发现与解决,若故障难以避免,要求有能快速发现并报警的方法,且有快速处理解决故障的能力。二、稳定性保障的思路
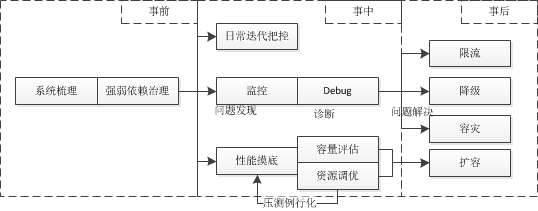
2.1 核心链路梳理
梳理出产品中真正核心业务模块,对整个调用链路进行分析,如,是否为强依赖,是否需要降级和限流侧率,资源是否满足极限要求等。
通常来说,当某个服务不可用时,业务链路不能继续进行且直接影响到业务功能,则为强依赖,否则为弱依赖。在进行强弱依赖治理时,要去除不合理的依赖,尽可能将非必须的强依赖降低为弱依赖。
对于强依赖要保障,合理分析制定降级、限流策略,缓存、资源调优。
对于弱依赖要隔离,故障时及时进行限流、超时拦截设置关停业务,以免对核心服务造成影响。 2.2 监控能力
监控反应的是能够尽可能快地发现线上故障从而快速解决,以此来降低损失。
监控通常包括以下方面:
系统监控:机器资源状态 (内存、CPU) 、应用性能指标状态(qps/latency)、Core异常监控、日志监控
业务监控:业务指标大盘、业务服务监控
对于业务监控,监控的频率通常和监控目标的重要程度有关,必要时也要按一定周期(日/周)进行汇总统计。2.3 性能摸底、资源调优
性能摸底是对现上服务服务的当前的极限能力就行探测,合理规划机器资源,对于资源过甚的业务要减少机器预算,对于触及资源红线的要进行扩容。
性能摸底压测流程可以例行化,一来可以及时发现业务迭代过程中可能带来性能问题,二来是时刻进行资源预警和分配。
限流摸底方案参考《一种性能资源摸底的方案》2.4. 限流降级
限流是根据某个应用或基础部件的某些核心指标,如QPS 或并发线程数,来决定是否将后续的请求进行拦截。限流可以牺牲少部分用户的体验从而保障大部分用户的产品体验。
降级是通过判断某个应用或组件的服务状态是否正常,来决定是否继续提供服务(服务降级)
降级从策略上又可以分为多级:功能降级(抵御短时峰值陡增)、Cache降级(抵御长时峰值增长)削峰限流(抵御长时超高峰值)、极端容灾(抵御极端服务宕机灾情)2.4.预案措施
预案是在有意识的为潜在或有可能出现的风险制定应对处置方案,涉及 事前预防、事中救援、事后处理三个风险阶段,又从容错、容量两个维度进行考量。容量分别是对服务上、下限保障的处理措施,如在超上限时进行限流,在遇到故障的恶劣情况下需要保证服务的最低质量,容错又分为无损、有损。无损不会对用户的体验造成损失。比如,事先准备预案链路、准备扩容机房。有损,会牺牲全部/部分用户的全部/部分体验,限流和降级都是有损的。2.6 故障处理
故障处理机制的目的是为了缩短故障时间,时间越短,用户影响就越小。
因此需要事先准备好各种故障下的处理流程:服务回滚流程、服务开关管理、cache管理、限流降级开关管理。三、保障体系
综合以上点 稳定性保障体系框图如下: