set接口
定义:
不包含重复元素的集合。 更正式地,集合不包含一对元素e1和e2 ,使得e1.equals(e2) ,并且最多一个空元素。 正如其名称所暗示的那样,这个接口模拟了数学集抽象。
- set接口的特点:无序、无下标、元素不能重复
set接口的方法全部继承自Collection,详细参考Collection接口
HashSet
定义:
此类实现Set接口,由哈希表(实际为HashMap实例)支持。 对set的迭代次序不作任何保证; 特别是,它不能保证顺序在一段时间内保持不变。 这个类允许null元素。
HashSet实现元素不重复的原理
1.什么是重复的数据?
public class SetCollection {
public static void main(String[] args){
HashSet<String> hashSet = new HashSet<>();
hashSet.add("A");
hashSet.add("B");
hashSet.add("C");
hashSet.add("D");
hashSet.add("E");
hashSet.add("A");
for(String s :hashSet){
System.out.println(s);
}
}
}
显而易见,上面程序打印结果为

那么对于程序编译器来说,A显然时具有重复对象的,因此程序运行结果输出为一个A,而非两个A,那么对于A来说,究竟是第二个重复的对象被删除了呢?还是把第一个对象给覆盖了呢?我们可以用add()方法返回值验证一下。
| 方法 | 描述 |
|---|---|
| boolean add(E e) | 将指定的元素添加到此集合(如果尚未存在)。 |
修改代码如下:
public class SetCollection {
public static void main(String[] args){
HashSet<String> hashSet = new HashSet<>();
System.out.println(hashSet.add("A"));
hashSet.add("B");
hashSet.add("C");
hashSet.add("D");
hashSet.add("E");
System.out.println(hashSet.add("A"));
for(String s :hashSet){
System.out.println(s);
}
}
}
打印结果如下:

- 结论:
第一次插入A元素是成功的,当第二此插入A时,程序编辑器报错了,因为它识别出这是一个重复的对象,因此拒绝插入集合。
2.HashSet怎么识别重复数据?
还是以代码为例:
public class TestHashSet {
public static void main(String[] args){
Student s1 =new Student("tom",20,"男",99D);
Student s2 =new Student("jack",21,"男",97D);
Student s3 =new Student("marry",20,"女",99D);
Student s4 =new Student("annie",21,"女",100D);
Student s5 =new Student("annie",21,"女",100D);
HashSet<Student> students = new HashSet<>();
students.add(s1);
students.add(s2);
students.add(s3);
students.add(s4);
System.out.println(students.add(s1));//插入重复对象(地址重复),不允许插入
System.out.println(students.add(s5));//插入重复对象(地址不同,内容相同),允许插入
for (Student student : students){
System.out.println(student);
}
}
}
class Student{
String name;
Integer age;
String gender;
Double score;
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", gender='" + gender + '\'' +
", score=" + score +
'}';
}
public Student(String name, Integer age, String gender, Double score) {
this.name = name;
this.age = age;
this.gender = gender;
this.score = score;
}
}
仔细阅读代码,你会发现,在往Students集合插入数据时,我们插入了两条特殊的数据,一条是地址重复的数据,一条时地址不同但是内容重复的数据,结果可能你已经猜到了,运行代码如下:

显然,对我们来说虽s5的地址与其他对象不同,但是内容上是和s4完全重复的,那么,怎么让程序编译器去识别呢?这就需要在Student类覆盖equals方法,来比较对象的各个属性值的异同,如果equals()返回true则是重复数据,反之则不是;
//Object.java中的eauals()方法
public boolean equals(Object obj) {
return (this == obj);
}
(IDE用户可以直接在Student类里直接生成equal()方法)
代码如下:
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return Objects.equals(name, student.name) &&
Objects.equals(age, student.age) &&
Objects.equals(gender, student.gender) &&
Objects.equals(score, student.score);
}
打印结果:

咦~~~ 和预想的不太一样的,我们的重写equals()方法并没有真正的覆盖封装的equals(),没有起到效果!为什么会这样呢?
其实是为了节省内存空间,节省资源,此时虽然用户写了覆盖eauals()方法,但是程序编译器认为没有必要使用。就是——“可以用,但没必要”。
原因很简单,如果每一次都调用equals(),插入5个对象将会调用多少次呢?
(设比较次数为n)
当插入一个对象时,不需要比较 (n=0)
当插入二个对象时,需要比较1次(n=1)
当插入三个对象时,需要比较2次(n=2)
当插入四个对象时,需要比较3次(n=3)
当插入五个对象时,需要比较4次(n=4)
仅仅插入5个对象却调用了10次equals(),显然没这个必要,大大降低了程序的执行效率,因此程序对equals()的使用是有条件的!这个条件就是HashCode(哈希码);
因为HashCode基于一个算法,多个对象可能会返回相同的HashCode(当然,如果各个对象生成的HashCode是不可能相同的话,也没有必要调用equals()方法了)
具体实现流程如下:

这也就证明了为什么我们单独使用equals();却没有达到去重的效果,因此,为了满足地址不同、内容相同的对象也可以被查重,我们需要去干预一下,干预的方法就是让地址不同、内容相同(属性相同)的对象拥有一致的HashCode;
因此,我们可以自定义HashCode()方法去覆盖的父类的HashCode()方法,怎么定义呢?当然,随意定义显然不合理,需要结合对象的各个属性的HashCode做结合,即为整个对象的HashCode;
方法如下(在Student类中重新HashCode()方法):
@Override
public int hashCode() {
return Objects.hash(name, age, gender, score);
}
再次打印结果:

小结:
HashSet基于HashCode来实现元素的不可重复- 当存入元素的
HashCode相同时,会调用equals()进行确认,结果为true,则拒绝存入;
LinkedHashSet
哈希表和链表实现的Set接口,具有可预测的迭代次序。 这种实现不同于HashSet,它维持于所有条目的运行双向链表。 该链表定义了迭代排序,它是将元素插入集合(插入顺序 ) 的顺序 。 请注意,如果一个元件被重新插入到组插入顺序不受影响 。 (元件e重新插入一组s如果当s.contains(e)将返回true之前立即调用s.add(e)被调用。)
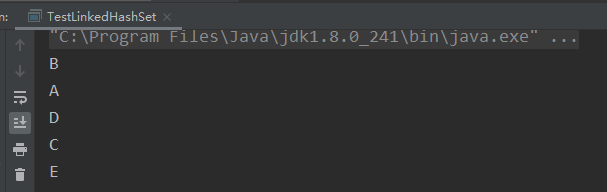
因为是链表结构,因此与HashSet不同,LinkedHashSet可以为我们保留插入顺序。
public class TestLinkedHashSet {
public static void main(String[] args){
LinkedHashSet set = new LinkedHashSet();
set.add("B");
set.add("D");
set.add("A");
set.add("E");
set.add("C");
for (Object o : set){
System.out.println(o);
}
}
}
打印结果(插入顺序是一定的):
Set进一步提供其元素的总排序 。 元素使用他们的自然顺序,或通常在创建有序Set时提供的Comparator进行排序。 改Set的迭代器将以递增的元素顺序遍历集合。 提供了几个额外的操作来利用订购。 (此接口是该组类似物SortedMap )。
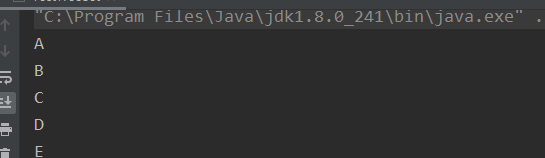
A NavigableSet实现基于TreeMap 。 的元件使用其有序(自然排序),或由Comparator集合创建时提供,这取决于所使用的构造方法。
public class TestTreeSet {
public static void main(String[] args){
TreeSet set = new TreeSet();
set.add("B");
set.add("A");
set.add("D");
set.add("E");
set.add("C");
for (Object o : set){
System.out.println(o);
}
}
}
打印结果:
使用TreeSet实现升降序
如果需要利用TreeSet进行排序,必须让比较对象实现Comparable接口,并重写compareTo()方法,在该方法定义排序条件(按什么排序)、排序方式(升序还是降序)。这里以升序为例:
public class TestTreeSet {
public static void main(String[] args){
TreeSet<Student> students = new TreeSet<Student>();
students.add(new Student("jack",99D));
students.add(new Student("tom",90D));
students.add(new Student("jerry",89D));
students.add(new Student("kitty",95D));
students.add(new Student("tony",95D));
students.add(new Student("simon",95D));
for (Object o : students){
System.out.println(o);
}
}
}
class Student implements Comparable<Student>{
String name;
Double score;
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", score=" + score +
'}';
}
public Student(String name, Double score) {
this.name = name;
this.score = score;
}
@Override
public int compareTo(Student o) {
//分数低的靠前
if(this.score>o.score){
return 1;
}else if(this.score<o.score){
return -1;
//名字按照字典排序
}else if (this.name.compareTo(o.name) < 0){
return -1;
} else if(this.name.compareTo(o.name) >0){
return 1;
}
return 0;
}
}
打印结果:

小结:
- 基于排列顺序实现元素不重复
- 实现了SortedSet接口,对集合元素自动排序
- 元素对象的类型必须实现
Comparable接口,覆盖CompareTo()方法,指定排序规则。
