关于Elasticsearch的基本了解
Elasticsearch是实时的分布式索引分析引擎,内部使用Lucene做索引与搜索。
实时:指的是新增的数据会很快被检索到;
分布式:可以动态调整集群规模,弹性扩容。
Lucene:是Java语言编写的全文搜索框架,用于处理纯文本的数据,但它只是一个库,提供建立索引、执行搜索等接口,但是不提供分布式服务。
ES中的基本概念
- cluster:代表一个集群,集群中有多个节点,其中有一个为主节点,这个节点是通过选举产生的,起到了去中心化。
- shards:代表索引分片,es可以把一个完整的索引分成多个分片,可以把一个索引拆分成多个,实现分布式搜索。
- replicas:代表索引副本,es可以设置多个索引的副本,既能提高系统的容错性,也能对搜索请求进行负载均衡。
- recovery:代表数据恢复或者叫数据重新分布,es在有节点加入或者退出时会根据机器的负载对索引进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
- river:代表es的一个数据源,也是其他存储方式(如数据库)同步数据到es的一个方法。(river
包括couchDB、RabbiMQ等) - gataway:代表es索引快照的存储方式,es默认是先把索引放在内存中,当内存满了之后再持久化到本地硬盘。当es关闭重启时,es会从硬盘中读取索引备份数据。es支持多种
gateway方式:本地文件系统(默认),分布式文件系统,Hadoop的HDFS和云存储等; - discovery.zen:代表es的自动发现节点机制,es会通过广播寻找存在的节点,再通过多播协议来进行节点之间的通讯。
- Transport:代表es内部jiedian或者集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时支持json、thrift等。
es的部分特性
扩展能力:通过分片的方式将数据分成若干小块分配到各个机器中,从而实现了系统的水平扩展能力。
读写并行:分片是底层的基本的读写单元,分片的目的是分割巨大的索引,让读写可以并行操作,由多台机器共同完成。
容错性:通过副本的形式,把数据复制成多个副本,放置到不同的机器中。
并发更新:ES将数据副本分为主从两个部分,即主分片和副分片。主数据作为权威数据,写过程先写主分区,成功后再写副分区,恢复阶段以主分区为主。
实时性:为尽可能让新的索引可以被索引,ES在系统将数据写入系统缓存后(还没有写入磁盘之前),该数据就对外可读。
ES的索引结构
ES是面向文档的。各种文本内容以文档的形式存储的ES中,文档可以是一封邮件、一条日志、或者一个网页的内容。
通常说ES只支持JSON格式,指的是ES使用JSON作为文档的序列化格式。
在存储结构上,由_index、_ type 、和_id三个参数来唯一标识一个文档:
- _index:指向一个或多个物理分片的逻辑命名空间
- _type:一个数据的整体模式是相似或相同的集合
- _id:文档标记符由系统自动生成或使用者提供
一个ES索引包含很多分片,一个分片是一个Lucene的索引,它本身就是一个完整的搜索引擎,可以独立执行建立索引和搜索任务。
Lucene索引有由很多分段组成,每个分段都是一个倒排索引。
使用倒排索引一旦被写入文件后就具有不变性:对文件的访问不需要加锁,读取索引时可以被文件系统缓存等。
为了保持索引的一致性,我们在修改文档时,会把原先的索引标记成删除(但并没有做物理删除),使用新的索引。
在ES中,每秒清空一次写缓存,将这些数据写入文件,这个过程称为refresh,每次refresh会创建一个新的Lucene段。
但是过多的Lucene段会影响其性能,所以ES采用将较小的段合并为大的段的策略:在和并过程中,标记为删除的数据不会写入新分段,当合并过程结束,旧的分段数据被删除,标记删除的数据才从磁盘删除。
如何理解倒排索引?
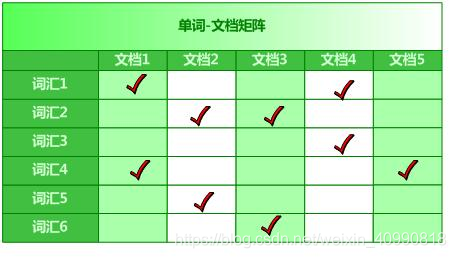
正排索引:可以理解为将一个文档进行wordcount统计后的结果 :hello 2次 world 1次
倒排索引: 倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。
ES集群
ES集群采用的是一种主从模式
- 这种模式可以简化系统设计,Master作为权威节点,部分操作仅由Master执行,并负责维护集群元数据。
- Master节点存在单节点故障需要灾备问题,并且集群规模会受限于Master节点的管理能力。
ES集群中节点角色
主节点
- 负责集群侧面的相关操作,管理集群变更。
- 集群状态由主节点进行维护,如果主节点从数据节点接收更新,则将这些更新广播到集群的其他节点,让每个节点的集群状态保持最新。
node.master: true
node.data: false
数据节点
- 负责保存数据、执行数据相关操作:CURD、搜索、聚合等。
- 数据节点对CPU、内存、I/O要求比较高
- 一般情况下,数据读写流程只和数据节点交互。不会和主节点打交道。
node.master: false
node.data: true
node.ingest: false
预处理节点
- 预处理操作允许在索引文档之前,即写入数据之前,通过事先定义好的一系列的processors(处理器)和pipeline(管道),对数据进行某种转换、富化。
- 默认情况下,在所有的节点上启动了ingest。
node.master: false
node.data: false
node.ingest: master
协调节点
- 协调节点将请求转发给保存数据的数据节点
- 每个数据节点在本地执行请求,并将结果返回协调节点。协调节点收集数据后,将每个数据节点的结果合并为单个全局结果。
- 因为对结果收集和排序需要很多的CPU和内存资源,所以协调节点的存在,可以缓解其他节点的压力。
node.master: false
node.data: false
node.ingest: false
部落节点
- 部落节点可以在多个集群之间充当联合客户端
- 本质上是一个 智能负载均衡器,提供路由请求的功能
- 目前已经被协调节点所取代
node.master: false
node.data: false
集群健康状态
丛数据完整性的角度,集群健康状态分为三种:(针对单个索引也适用)
- Green:所有的主分片和副分片都正常运行。
- Yellow:所有的主分片都正常运行,但不是所有的副分片都正常运行。这意味着存在单节点故障风险。
- Red:有主分片没能正常运行。
集群扩容
当扩容集群、添加节点时,分片会均衡地分配到集群的各个节点,从而对索引和搜索过程进行负载均衡,这些都是系统自动完成的。
当ES集群发生故障时,ES会自动处理节点异常:
- 当主节点异常时,集群会重新选举主节点
- 当某个主分片异常时,会将副分片提升为主分片
集群进行扩展的过程:
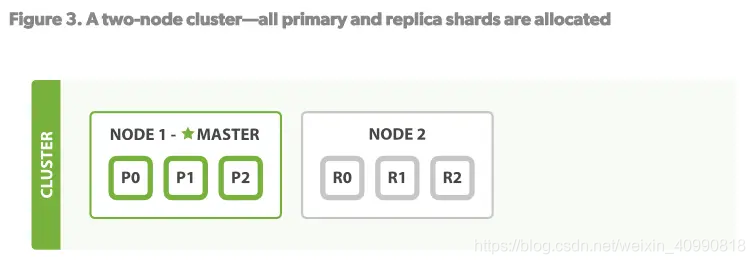
1.当只有一个节点时:Node1上有三个主分片,没有副分片

2.添加第二个节点后,副分片被分配到Node2
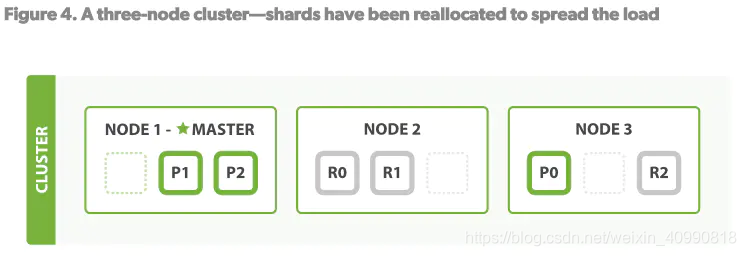
3.添加第三个节点后,索引的六个分片(三主三副)被平均分配到集群的三个节点
这个过程会保证主分片和副分片不会分配到同一个节点,避免单个节点故障引起数据丢失。