数据库复习题二
本复习题有一和二
此处为复习题二
觉得有用请点赞!
数据库系统与应用的知识点
一、 根据客户的问题进行需求分析(调查分析用户活动 、收集和分析需求数据,确定系统边界 画数据流图、数据字典)
二、 概念设计:画ER图 重点
三、 逻辑设计:关系模式(利用函数依赖、范式规范关系,闭包) 重点
四、 物理设计:确定存储方式、索引、数据结构
五、 实现:创建数据库、数据表、修改表、删除表、数据操纵(添加数据、修改数据、删除数据) 重点
六、 查询:单表查询,多表查询(连接查询、子查询) 重点
七、 程序设计:存储过程
详细内容:
一、概念设计:画ER图 重点

绘制E-R图的步骤
(1)首先确定实体类型。
(2)确定联系类型(1:1,1:N,M:N)。
(3)把实体类型和联系类型组合成E—R图。
(4)确定实体类型和联系类型的属性。
(5)确定实体类型的键,在E—R图中属于键的属性名下画一条横线。
二、逻辑设计:关系模式(利用函数依赖、范式规范关系) 重点
1、关系模式(Relational Schema):由一个关系名以及它所有的属性构成。
格式: 关系名(属性名1,属性名2,…,属性名n)
在SQL Server中对应的表结构为:
表名(字段名1、字段名2,… ,字段名n)
2、ER图转换为关系模式
转换原则
• 将E-R图转换为关系模型实际上就是将实体、属性和联系转换成关系模式。
• 在转换中要遵循以下原则:
(1)一个实体转换为一个关系模式,实体的属性就是关系的属性,实体的键就是关系的键。
(2)一个联系转换为一个关系模式,与该联系相连的各实体的键以及联系的属性均转换为该关系的属性。该关系的键有三种情况:
– 如果联系为1:1,则每个实体的键都是关系的候选键;
– 如果联系为1:n,则n端实体的键是关系的键;
– 如果联系为n:m,则各实体键的组合是关系的键。
3、数据库范式
基本概念
实体:现实世界中客观存在并可以被区别的事物。比如“一个学生”、“一本书”、“一门课”等等。值得强调的是这里所说的“事物”不仅仅是看得见摸得着的“东西”,它也可以是虚拟的,如“老师与学校的关系”。
属性:二维表中的每一列称为关系的一个属性。
元组:表中的一行就是一个元组。
域(Domain):属性所对应的取值变化范围叫属性的域。
分量:元组的某个属性值。在一个关系数据库中,它是一个操作原子,即关系数据库在做任何操作的时候,属性是“不可分的”。否则就不是关系数据库了。
主键(Primary Key):能唯一标识关系中不同元组的属性或属性组称为该关系的候选关键字。
外键(Foreign Key):如果关系R的某一(些)属性A不是R的关键字,而是另一关系S的关键了,则称A为R的外来关键字。
第一范式(1NF):属性不可分
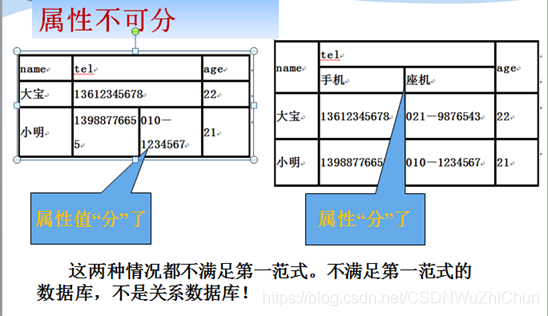
第二范式(2NF):符合1NF,并且,非主属性完全依赖于码。

第三范式(3NF)符合2NF,并且,消除传递依赖
上面的“学生上课表新”符合2NF,可以这样验证:两个主属性单独使用,不用确定其它四个非主属性的任何一个。但是它有传递依赖!
在哪呢?问题就出在“老师”和“老师职称”这里。一个老师一定能确定一个老师职称。
有什么问题吗?想想:
小结:
在数据库设计中,为了更好地应用三个范式,就必须通俗地理解三个范式(通俗地理解是够用的理解,并不是最科学最准确的理解):
第一范式:1NF是对属性的原子性约束,要求属性具有原子性,不可再分解;
第二范式:2NF是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性;
第三范式:3NF是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余。
没有冗余的数据库设计可以做到。但是,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。具体做法是:在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余。
练习1:设某商业集团的仓库管理系统
数据库有三个实体。
一是“公司”实体,属性有公司编号、公司名、地址等;
二是“仓库”实体,属性有仓库编号、仓库名、地址等;
三是“职工”实体,属性有职工编号、姓名、性别等。
公司与仓库间存在“隶属”联系,每个公司管辖若干仓库,每个仓库只能属于一个公司管辖;
仓库与职工间存在“聘用”联系,每个仓库可聘用多个职工,每个职工只能在一个仓库工作,仓库聘用职工有聘期和工资。
(1)试画出ER图,并在图上注明属性、联系的类型。
(2)将ER图转换成关系模式,并注明主键和外键。

公司(公司编号,公司名,地址)
仓库(仓库编号,仓库名,地址,公司编号)FK:公司编号
职工(职工编号,姓名,性别)
聘用(职工编号,仓库编号,聘期,月薪)
练习2:
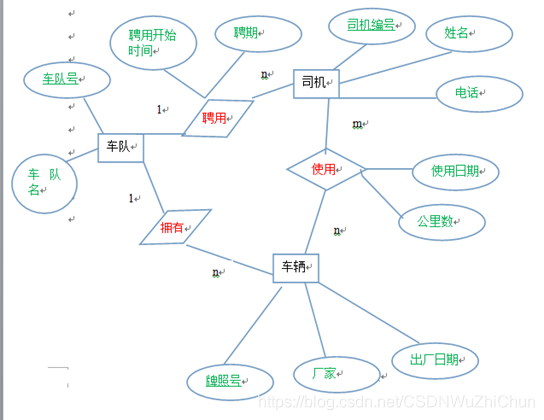
设某汽车运输公司数据库中有三个实体集。一是“车队”实体集,属性有车队号、车队名等;二是“车辆”实体集,属性有牌照号、厂家、出厂日期等;三是“司机”实体集,属性有司机编号、姓名、电话等。
车队与司机之间存在“聘用”联系,每可聘用若干司机,但每个司机只能应聘于一个车队,车队聘用司机有“聘用开始时间”和“聘期”两个属性;
车队与车辆之间存在“拥有”联系,每个车队可拥有若干车辆,但每辆车只能属于一个车队;
司机与车辆之间存在着“使用”联系,司机使用车辆有“使用日期”和“公里数”两个属性,每个司机可使用多辆汽车,每辆汽车可被多个司机使用。
(1)请根据以上描述,绘制相应的 E-R 图,并直接在 E-R 图上注明实体名、属性、联系类型。
(2)将 E-R 图转换成关系模式,并说明主键和外键。
(1)
(2)
车队(车队号,车队名)
司机(司机编号,姓名,电话,车队号,聘用开始时间,聘期)
车辆(牌照号,厂家,出厂日期,车队号)
使用(司机编号,牌照号,使用日期,公里数)
三、物理设计:确定存储方式、索引、数据结构
1、数据类型
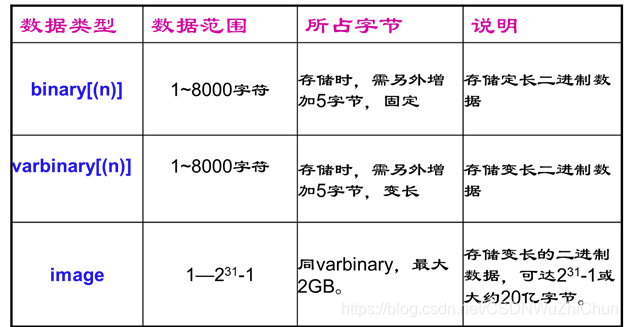
SQL Server系统提供的基本数据类型有二进制数据、字符型数据、Unicode数据、日期和时间数据、数字数据、货币数据和特殊数据等七种类型
(1)二进制数据类型
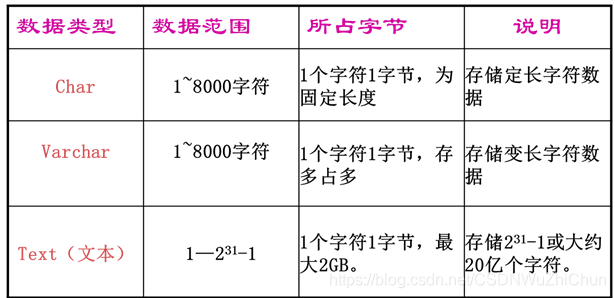
2、字符型数据类型
字符数据由字母、符号和数字等组成。在输入字符数据时,应将数据括在括号内。字符数据包括Char、Varchar和Text三种类型。
3、整数数据类型

4、日期和时间数据类型
日期和时间型数据由有效的日期和时间组成。这种数据类型分为datetime和smalldatetime两种,二者的主要差别在于它们的存储长度、所表示的时间范围和精度不同。在输入日期和时间型数据时应将数据引在单引号内。
Datetime:所存储的日期范围是从1753年1月1日开始,到9999年12月31日结束(每一个值都要求8个存储字节,表示时间的精度为1/300秒)。
Smalldatetime:所存储的日期范围是从1900年1月1日开始,到2079年6月6日结束(每一个值都要求4个存储字节,表示时间的精度为分钟)。
例:
车队(车队号,车队名)
司机(司机编号,姓名,电话,车队号,聘用开始时间,聘期)
车辆(牌照号,厂家,出厂日期,车队号)
使用(司机编号,牌照号,使用日期,公里数)
上述关系模式的数据结构如下
(1)车队信息表
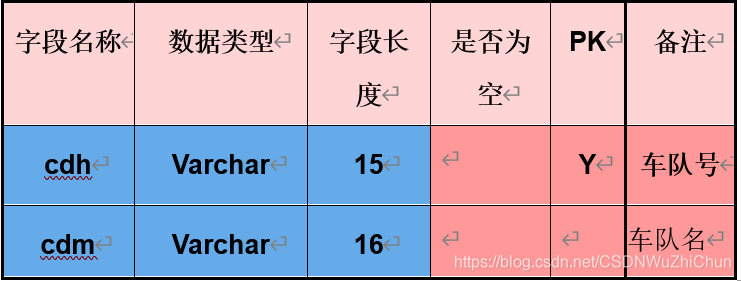
(2)司机信息表

(3) 车辆表

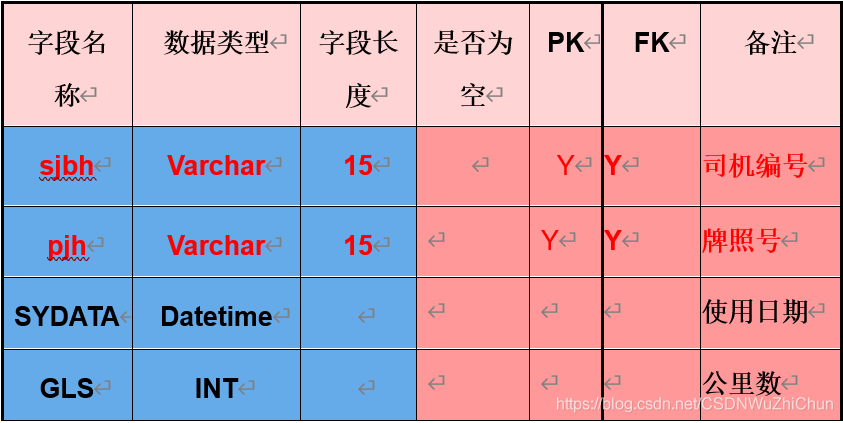
(4)使用情况表
五、 实现:创建数据库、数据表、修改表、删除表、数据操纵(添加数据、修改数据、删除数据) 重点
1、创建数据库的完整语法
CREATE DATABASE 数据库名
[ON [PRIMARY] [< filespec >[,…] ] [,[,…n] ] ]
[LOG ON {[,…n ] } ]

例: 创建一个学生成绩管理数据库(StudScore_DB2),该数据库的主文件逻辑名称为“StudScore_DB2_Data1”,物理文件名为“StudScore_DB2_Data1.mdf”,初始大小为10MB,最大尺寸为无限大,增长速度为10%;数据库的日志文件逻辑名称为“StudScore_DB2_log1”,物理文件名为“StudScore_DB2_log1.ldf”,初始大小为5MB,最大尺寸为25MB,增长速度为1MB。
CREATE DATABASE 学生成绩管理数据库
ON
(NAME=StudScore_DB2_Data1,
FILENAME =‘D:\StudScore_DB2_Data1.mdf’ ,
SIZE=10,
MAXSIZE=UNLIMITED,
FILEGROWTH=10% )
LOG ON
( NAME=‘StudScore_DB2_log1’ ,
FILENAME=‘D:\StudScore_DB2_log1.ldf’,
SIZE=5MB,
MAXSIZE=25MB,
FILEGROWTH=1MB)
练习:
创建上述的汽车运输公司数据库,要求存储在E盘根目录下,其它参数自定义。
CREATE DATABASE 汽车运输公司数据库
ON
(NAME=qcys_DB2_Data1,
FILENAME =‘E:\ qcys _DB2_Data1.mdf’ ,
SIZE=10,
MAXSIZE=UNLIMITED,
FILEGROWTH=10% )
LOG ON
( NAME=‘qcys _DB2_log1’ ,
FILENAME=‘E:\ qcys _DB2_log1.ldf’,
SIZE=5MB,
MAXSIZE=25MB,
FILEGROWTH=1MB)
2、创建表语法
CREATE TABLE 表名
( 字段名1 数据类型[约束],
字段名2 数据类型[约束],
…
字段名N 数据类型[约束],
);
2.1五个约束
定义数据表的约束
1、NULL /NOT NULL约束
语法格式: [CONSTRAINT <约束名> ][NULL | NOT NULL]
2、UNIQUE约束(唯一约束)
语法格式: [CONSTRAINT <约束名> ] UNIQUE
3、PRIMARY KEY约束(主键约束)
语法格式: [CONSTRAINT <约束名> ] PRIMARY KEY
4、FOREIGE KEY 约束(外键约束)
语法格式: [CONSTRAINT <约束名> ] FOREIGN KEY REFERENCES <主表名> (<列名>{}[,<列名>]})
5、CHECK约束
用来检查字段值所允许的范围,如一个字段只能输入整数,而且限定在0~100的整数,以此来保证完整性。
语法格式: [CONSTRAINT <约束名> ] CHECK(<条件>)
CONSTRAINT score check(score between 0 and 100)
Check(成绩〉=0 and 成绩<=100)
Check(性别 in(‘男’,’女’))
例:创建车队、司机、车辆、使用信息表。
车队信息表
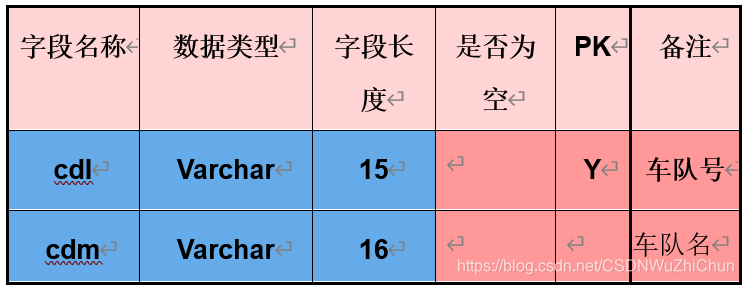
CREATE TABLE 车队信息表
( cdh Varchar (15) PRIMARY KEY,
Cdm Varchar (16)
);
司机信息表

CREATE TABLE 司机信息表
( sjbh Varchar (15) PRIMARY KEY,
sm Varchar (16) ,
dh char (11) ,
cdh Varchar (16),
pysj Datetime,
pj int );
(3) 车辆表

CREATE TABLE 车辆表
( pjh Varchar (15) PRIMARY KEY,
cj Varchar (30) ,
CCDATE Datetime ,
cdh Varchar (16) )
(4)使用情况表
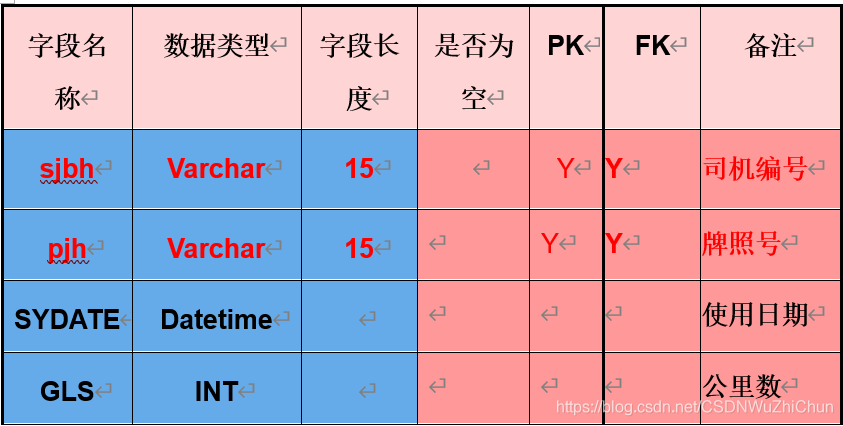
CREATE TABLE 使用情况表
( sjbh Varchar (15) CONSTRAINT PK_S_d Foreign key REFERENCES 司机信息表(sjbh),
pjh Varchar (15) CONSTRAINT PK_S_C Foreign key REFERENCES 车辆表(pjh) ,
SYDATE Datetime,
GLS int,
Constraint PK_S_P Primary Key (sjbh, pjh), --建立复合主键
);
3、PRIMARY KEY约束(主键约束)
语法格式: [CONSTRAINT <约束名> ] PRIMARY KEY
4、FOREIGE KEY 约束(外键约束)
语法格式: [CONSTRAINT <约束名> ] FOREIGN KEY REFERENCES <主表名> (<列名>{}[,<列名>]})

2、数据操纵
一、数据插入
格式: INSERT [INTO] 表名或视图
[(column {,column})] /插入的列名/
VALUES (coulmnvalue[{,columnvalue}]); /插入的列值/
二、数据更新
格式:
UPDATE 表名
SET columname=newvalue[,nextcolumn=newvalue2…]
WHERE columnname OPERATOR value[and| or column OPERATOR value];
三、数据删除
格式:
DELETE FROM 表名
WHERE columnname OPERATOP value [AND|OR column OPERATOP value];
练习:现有以下关系模式,请设计一些题目进行数据插入、更新、删除,并写出答案。
车队(车队号,车队名)
司机(司机编号,姓名,电话,车队号,聘用开始时间,聘期)
车辆(牌照号,厂家,出厂日期,车队号)
使用(司机编号,牌照号,使用日期,公里数)
六、查询:单表查询,多表查询(连接查询、子查询) 重点
SELECT 查询语句结构
1、SELECT 语句精简结构 语法:
SELECT select_list
[INTO new_table_name]
FROM table_list
[WHERE search_conditions]
[GROUP BY group_by_list]
[HAVING search_conditions]
[ORDER BY order_list [ASC | DESC ]]
SELECT语句的执行过程
1)读取FROM子句中基本表、视图的数据,执行笛卡尔积操作。
2)选取满足WHERE子句中给出的条件表达式的元组。
3)按GROUP子句中指定列的值分组,同时提取满足HAVING子句中组条件表达式的那些组。
4)按SELECT子句中给出的列名或列表达式求值输出。
5)ORDER子句对输出的目标表进行排序,按附加说明ASC升序排列,或按DESC降序排列。
语法:
SELECT [ALL | DICTINCT] [TOP] /指定输出行规则/
[<column_name>][AS<column_name>][,[<column_name>]
/指定要查询的列或行及其限定/
[AS<column_name>]…] /指定列别名/
FROM <database_name>]<table_name>[[AS]Local_Alias] /指定表或视图/
[[INNER | LEFT [OUTER] | RIGHT [OUTER] | FULL [OUTER] /指定连接类型/
JOIN [<database_name>]<table_name>[[AS]Locat_Alias][ON<连接条件>]]
[INTO | TO FILE <file_name>[ADDITIVE]
| TO PRINTER [PROMPT] | TO SCREEN ] /指定输出方式/
[PREFERENCE PreferenceName] [NOCONSOLE][PLAIN][NOWAIT]
[WHERE ][AND …] [AND | OR …]]
/指定查询的及其限定/
[GROUP BY ][,…]] /指定分组/
[HAVING ] /指定分组统计条件/
[UNION [ALL] < SELECT column_name>] /指定集合操作/
[ORDER BY <column_name>[ASC | DESC ][,<column_name>[ASC | DESC]…]]
/指定输出行规则/
1) 使用DISTINCT关键字去除重复的记录
2) TOP:在数据查询时,经常需要查询最好的、最差的、最前的、最后的几条记录,这时需要使用TOP关键字进行数据查询。
TOP n [PERCENT]:指定返回查询结果的前n行数据,如果PERCENT关键字指定的话,则返回查询结果的前百分之n行数据。
WITH TIES :此选项只能在使用了ORDER BY 子句后才能使用,当指定此项时除了返回由TOP n PERCENT指定的数据行外,还要返回与TOP n PERCENT返回的最后一行记录中由OEDER BY子句指定的列的列值相同的数据行。
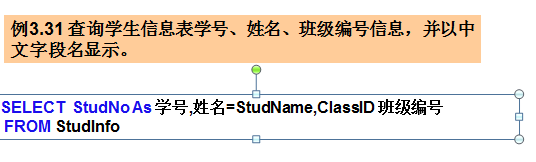
3) 别名运算
4) 使用INTO 子句
INTO new_table_name子句将查询的结果集创建一个新的数据表。

5)FROM子句
• FROM子句主要用来指定检索数据的来源,指定数据来源的数据表和视图的列表,该列表中的数据表名和视图名之间使用逗号分隔。
语法: [FROM { <table_source>} [,…n] ]

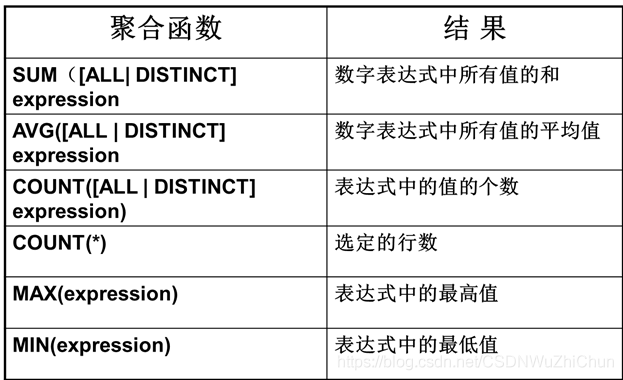
聚合函数
HAVING子句指定分组搜索条件,是对分组之后的结果再次筛选。
HAVING语法与WHERE语法类似。

创建视图
其语法格式如下:
CREATE VIEW [ 视图所有者 . ] /指定视图的所有者/
视图名 /指定视图名/
[ (列名 [ ,…n ] ) ] /指定视图中的列/
[ WITH <视图属性> [ ,…n ] ] /指定视图中的属性/
AS 查询语句 [ ; ] /指定创建视图的T-SQL语句/
[ WITH CHECK OPTION ] /指定修改条件/
存储过程概述
存储过程(Stored Procedure)是一组完成特定功能的SQL语句集,经编译后存储在数据库中。用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行存储过程。
利用SQL Server创建一个应用程序时,SQL是主要的编程语言。使用SQL进行编程,有两种方法。其一是,在本地存储SQL程序,并创建应用程序向SQL Server发送命令来对结果进行处理。其二是,可以把部分用SQL编写的程序作为存储过程存储在SQL Server中,然后创建应用程序来调用存储过程,对数据结果进行处理。
9.1.3 存储过程的设计规则
使用SQL语句CREATE PROCEDURE可以创建存储过程。其语法格式如下:
CREATE { PROC | PROCEDURE 存储过程名
[ ; number ]
[ { @参数 数据类型 }
[ VARYING ] [ = default ] [OUTPUT ]
] [ ,…n ]
[ WITH { RECOMPILE | ENCRYPTION | RECOMPILE ,ENCRYTION } ]
[ FOR REPLICATION ]
AS { <SQL语句> [;][ …n ] |
使用存储过程
存储过程可以使用EXECUTE语句在查询编辑器中执行。
语法:[[EXEC [ UTE]]
{ [ return_statrs= ]
{ 存储过程名 [;number ] |@preocdure+name_var
}
[[@parameter=]{value | @variable [OUTPUT]|[DEFAULT]]
[,…n]
[WITH RECOMPILE]
例9.4 编写一个存储过程,取得一个指定区间范围内的成绩。
CREATE PROCEDURE ProcGetScoreStep @Start numeric(4,1),@End numeric(4,1)
With Encryption
As
SELECT *
FROM 成绩表
WHERE 成绩>=@Start And 成绩<=@End
GO
–调用存储过程ProcGetScoreStep,并传递参数80和90,显示成绩在区间[80,90]的成绩信息。
Exec ProcGetScoreStep 80,90
关系运算
1.选取 (selection)
选取运算的含义
在关系R中选择满足给定条件的诸元组
σF® = {t|tR∧F(t)= ‘真’}
σ:为选取运算符;F:选择条件,是一个逻辑表达式,取值为“真”或“假”.它是由运算对象(属性名,常数,简单函数),算术比较运算符,逻辑运算符连接起来的逻辑表达式。
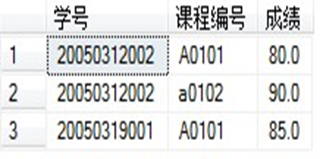
【例题 1】 查询年龄小于20岁的学生
结果见下表:

2.投影projection

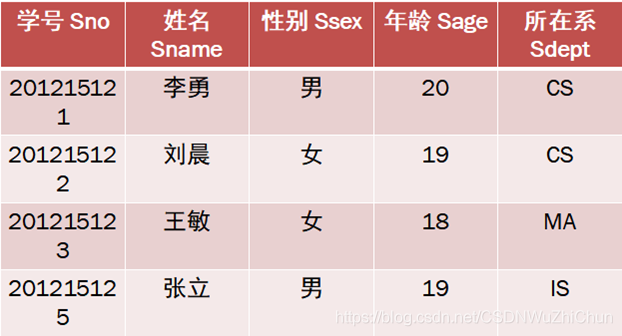
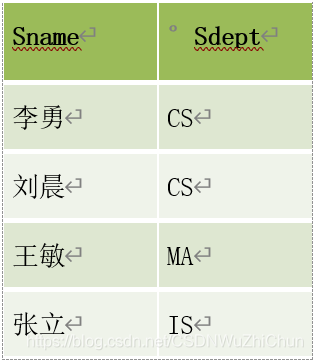
【例题 2】 查询学生的姓名和所在系
Student
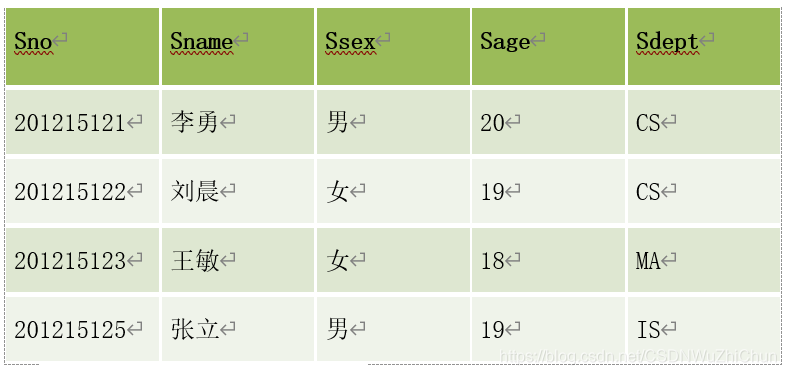
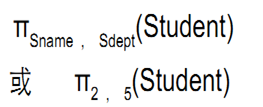
结果如下:
3、连接jion



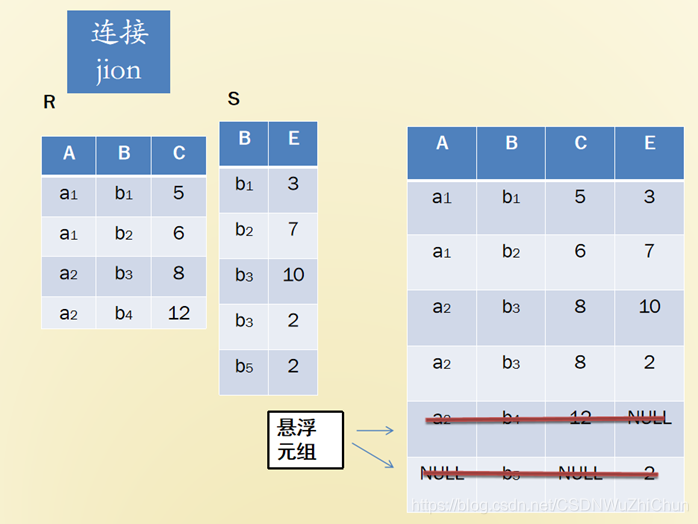
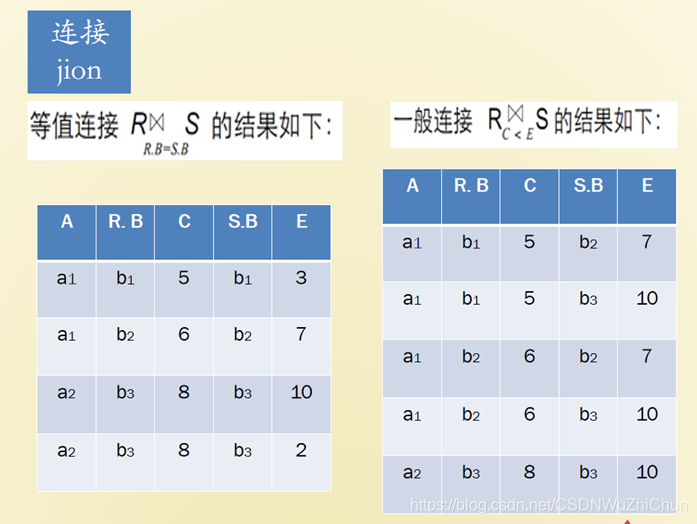

练习:
1、设有关系模式S(SNo,SN,Sex,Age),其中SNo,SN,Sex,Age分别表示学生的学号、姓名、性别、年龄。则“从中检索学生年龄大于18岁的学生学号”,关系代数表达式为( )。
A. σSNo(ΠAge>18(S)) B. σSNo(σAge>18(S))
D. ΠSNo(ΠAge>18(S)) D. ΠSNo(σAge>18(S))
2、有两个关系R(A,B)和S(B,C,D),则R×S结果的属性个数是( )。
A. 3 B. 4 C. 5 D. 6
