

import numpy as np
import pandas as pd
import xml.etree.cElementTree as et
def getvalueofnode(node):
"""return node text or None"""
return node.text
def main():
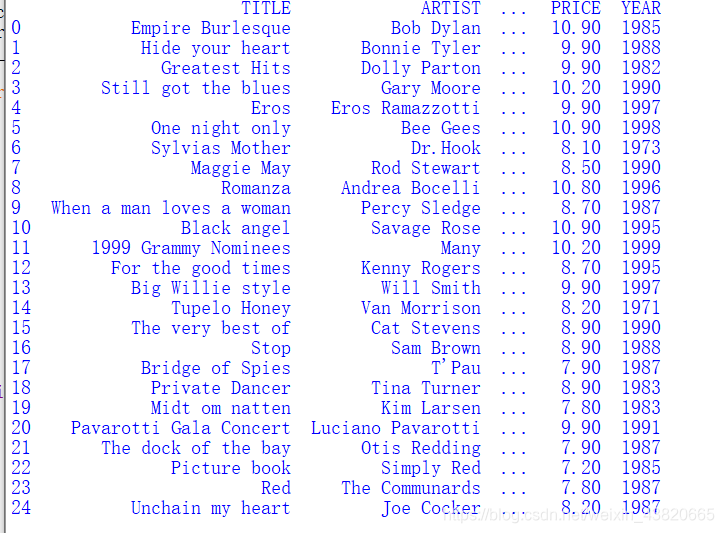
path = "cd_catalog.xml"
dfcols=['TITLE','ARTIST','COUNTRY','COMPANY','PRICE','YEAR']
parsed_xml=et.parse(path)
df_xml=pd.DataFrame(columns=dfcols)
for node in parsed_xml.getroot():
title=node.find('TITLE')
artist=node.find('ARTIST')
country=node.find('COUNTRY')
company=node.find('COMPANY')
price=node.find('PRICE')
year=node.find('YEAR')
df_xml=df_xml.append(pd.Series([getvalueofnode(title),
getvalueofnode(artist),
getvalueofnode(country),
getvalueofnode(company),
getvalueofnode(price),
getvalueofnode(year),
],index=dfcols),ignore_index=True)
print(df_xml)
main()

from urllib.parse import urlencode
import requests
from lxml import etree
import pandas as pd
import sys
import chardet
url="https://info.zufe.edu.cn/xygk/szdw.htm"
ua = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240"
with requests.request('GET',url,headers={'User-agent':ua}) as res:
res.encoding = res.apparent_encoding
content=res.text
html=etree.HTML(content)
dfcols=['NAME','POSITION','ADDRESS']
df_xml=pd.DataFrame(columns=dfcols)
name=html.xpath("//div[@id='vsb_content']//tr[position()<=14]/td//a//text()")
position=html.xpath("//div[@id='vsb_content']//tr[position()<=3]/td/strong/text()")
address=html.xpath("//div[@id='vsb_content']//tr[position()<16]/td/a/@href")
#print(name)
#print(position)
#print(address)
for i in range(12):
position.append('教授(13):')
for i in range(31):
position.append('副教授(31):')
for i in range(24):
position.append('讲师(24):')
ans = dict(zip(name,address))
for j,k in ans.items():
print(j,k)
ans = dict(zip(name,position))
for j,k in ans.items():
print(j,k)
