文章目录
什么是对象池?
对象池从字面上来理解,就是一个能存储很多对象的池子。在Go里面,对象池是通过使用sync包里的Pool结构来实现的,对象池能提高内存复用,减少内存申请次数,甚至能降低CPU消耗,是高并发项目优化不可缺少的手法之一。
作者的解释如下:
// A Pool is a set of temporary objects that may be individually saved and
// retrieved.
//
// Any item stored in the Pool may be removed automatically at any time without
// notification. If the Pool holds the only reference when this happens, the
// item might be deallocated.
//
// A Pool is safe for use by multiple goroutines simultaneously.
//
// Pool’s purpose is to cache allocated but unused items for later reuse,
// relieving pressure on the garbage collector. That is, it makes it easy to
// build efficient, thread-safe free lists. However, it is not suitable for all
// free lists.
有哪些场景需要使用对象池?
在go源码里,作者对sync.Pool使用做了如下的建议:
// An appropriate use of a Pool is to manage a group of temporary items
// silently shared among and potentially reused by concurrent independent
// clients of a package. Pool provides a way to amortize allocation overhead
// across many clients.
//
// On the other hand, a free list maintained as part of a short-lived object is
// not a suitable use for a Pool, since the overhead does not amortize well in
// that scenario. It is more efficient to have such objects implement their own
// free list.
//
// A Pool must not be copied after first use.
fmt包的应用
fmt.Sprintf()
var ppFree = sync.Pool{
New: func() interface{} { return new(pp) },
}
// newPrinter allocates a new pp struct or grabs a cached one.
func newPrinter() *pp {
p := ppFree.Get().(*pp)
p.panicking = false
p.erroring = false
p.wrapErrs = false
p.fmt.init(&p.buf)
return p
}
// free saves used pp structs in ppFree; avoids an allocation per invocation.
func (p *pp) free() {
// Proper usage of a sync.Pool requires each entry to have approximately
// the same memory cost. To obtain this property when the stored type
// contains a variably-sized buffer, we add a hard limit on the maximum buffer
// to place back in the pool.
//
// See https://golang.org/issue/23199
if cap(p.buf) > 64<<10 {
return
}
p.buf = p.buf[:0]
p.arg = nil
p.value = reflect.Value{}
p.wrappedErr = nil
ppFree.Put(p)
}
// Sprintf formats according to a format specifier and returns the resulting string.
func Sprintf(format string, a ...interface{}) string {
p := newPrinter()
p.doPrintf(format, a)
s := string(p.buf)
p.free()
return s
}
字符串拼接应用
var bytePool = sync.Pool{
New: func() interface{} {
buf := make([]byte, 0, 4096)
return buf
},
}
var ch = make(ch []byte,1000)
func main(){
go func(){
for msg := range ch {
fmt.Println("recv msg")
msg = msg[:0]
bytePool.Put(msg)
}
}
...
for i:0;i<=100000;i++ {
lineBuf := bytePool.Get().([]byte)
lineBuf = append(lineBuf, topic)
lineBuf = append(lineBuf, position)
lineBuf = append(lineBuf, info)
lineBuf = append(lineBuf, data)
ch <- lineBuf
}
time.Sleep(5 * time.Minute)
}
对象池的实现(go1.12)
相关结构定义
Pool
type Pool struct {
noCopy noCopy
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
localSize uintptr // size of the local array
// New optionally specifies a function to generate
// a value when Get would otherwise return nil.
// It may not be changed concurrently with calls to Get.
New func() interface{}
}
- noCopy 防止copy
- local 本地对象池
- localSize 本地对象池的大小
- New 生成对象的接口方法
poolLocal
type poolLocal struct {
poolLocalInternal
// Prevents false sharing on widespread platforms with
// 128 mod (cache line size) = 0 .
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
- poolLocalInternal 本地对象池
- pad 占位
poolLocalInternal
// Local per-P Pool appendix.
type poolLocalInternal struct {
private interface{} // Can be used only by the respective P.
shared []interface{} // Can be used by any P.
Mutex // Protects shared.
}
- private 私有对象池
- shared 共享对象池
- Mutex 对象池锁,主要是锁共享对象池
设计思想
对象池与P的关系
请看如下代码释义:
func (p *Pool) pinSlow() *poolLocal {
// Retry under the mutex.
// Can not lock the mutex while pinned.
runtime_procUnpin()
allPoolsMu.Lock()
defer allPoolsMu.Unlock()
//寻找新的P
pid := runtime_procPin()
// poolCleanup won't be called while we are pinned.
s := p.localSize
l := p.local
//如果存在这个P的对象池则直接获取
if uintptr(pid) < s {
return indexLocal(l, pid)
}
//如果当前P的对象池不存在,加入到对象池集合中
if p.local == nil {
allPools = append(allPools, p)
}
// If GOMAXPROCS changes between GCs, we re-allocate the array and lose the old one.
// 如果P数量在GC的时候发生了变化,Go会重新生成匹配P数量的对象池,并且丢弃旧的。
//获取当前的P数量
size := runtime.GOMAXPROCS(0)
//创建P数量大小的对象池,并返回相应pid的对象池
local := make([]poolLocal, size)
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release
atomic.StoreUintptr(&p.localSize, uintptr(size)) // store-release
return &local[pid]
}
runtime_procPin方法实现
//go:nosplit
func procPin() int {
//获取当前goroutine
_g_ := getg()
//获取执行goroutine的M
mp := _g_.m
mp.locks++
//返回P
return int(mp.p.ptr().id)
}
//go:linkname sync_runtime_procPin sync.runtime_procPin
//go:nosplit
func sync_runtime_procPin() int {
return procPin()
}
从以上两段代码可以清楚的了解到sync.Pool的对象池是按照P进行分片,每个P都对应一个对象池,也就是poolLocal。如图:
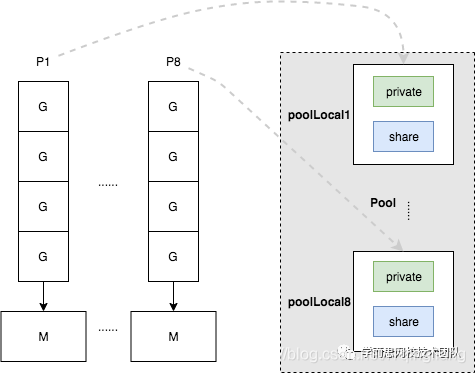
对象池中获取对象
Get函数源码释义
- Get函数的逻辑流程如下:
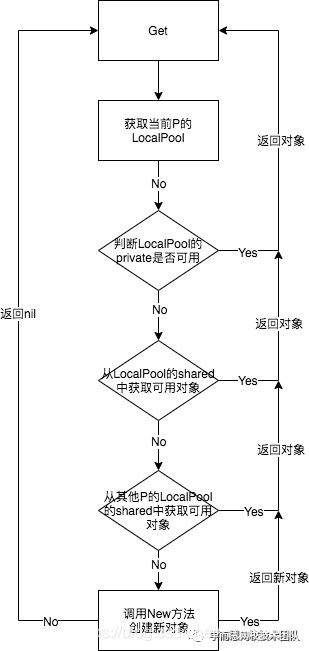
源码释义如下:
// Get selects an arbitrary item from the Pool, removes it from the
// Pool, and returns it to the caller.
// Get may choose to ignore the pool and treat it as empty.
// Callers should not assume any relation between values passed to Put and
// the values returned by Get.
//
// If Get would otherwise return nil and p.New is non-nil, Get returns
// the result of calling p.New.
func (p *Pool) Get() interface{} {
if race.Enabled {
race.Disable()
}
//获取当前P对应的LocalPool
l := p.pin()
//获取当前P的私有对象池
x := l.private
l.private = nil
runtime_procUnpin()
//如果私有对象池没有可用的对象
if x == nil {
l.Lock()
//从当前P的共享对象池尾部获取对象
last := len(l.shared) - 1
if last >= 0 {
x = l.shared[last]
l.shared = l.shared[:last]
}
l.Unlock()
//如果共享对象池尾部也没有可用的对象
if x == nil {
//此处去别的P的共享对象池去偷对象
x = p.getSlow()
}
}
if race.Enabled {
race.Enable()
if x != nil {
race.Acquire(poolRaceAddr(x))
}
}
//如果所有对象池里都无法拿到可用的对象,只能新创建对象
if x == nil && p.New != nil {
x = p.New()
}
return x
}
// pin pins the current goroutine to P, disables preemption and returns poolLocal pool for the P.
// Caller must call runtime_procUnpin() when done with the pool.
// pin方法主要是获取`PoolLocal`,当全局`sync.Pool`对象里没有对应P的`PoolLocal`时,触发`Pool.local`的重建,丢弃旧的。
func (p *Pool) pin() *poolLocal {
pid := runtime_procPin()
// In pinSlow we store to localSize and then to local, here we load in opposite order.
// Since we've disabled preemption, GC cannot happen in between.
// Thus here we must observe local at least as large localSize.
// We can observe a newer/larger local, it is fine (we must observe its zero-initialized-ness).
s := atomic.LoadUintptr(&p.localSize) // load-acquire
l := p.local // load-consume
if uintptr(pid) < s {
return indexLocal(l, pid)
}
return p.pinSlow()
}
//getSlow方法的职责是任意`P`上找到可用的对象
func (p *Pool) getSlow() (x interface{}) {
// See the comment in pin regarding ordering of the loads.
//计算当前LocalPool的大小
size := atomic.LoadUintptr(&p.localSize) // load-acquire
local := p.local // load-consume
// Try to steal one element from other procs.
//获取当前P的id
pid := runtime_procPin()
runtime_procUnpin()
//循环遍历所有P的LocalPool,从shared尾部获取可用对象
for i := 0; i < int(size); i++ {
l := indexLocal(local, (pid+i+1)%int(size))
l.Lock()
last := len(l.shared) - 1
if last >= 0 {
x = l.shared[last]
l.shared = l.shared[:last]
l.Unlock()
break
}
l.Unlock()
}
return x
}
向对象池归还对象
- Put函数的逻辑流程如下:
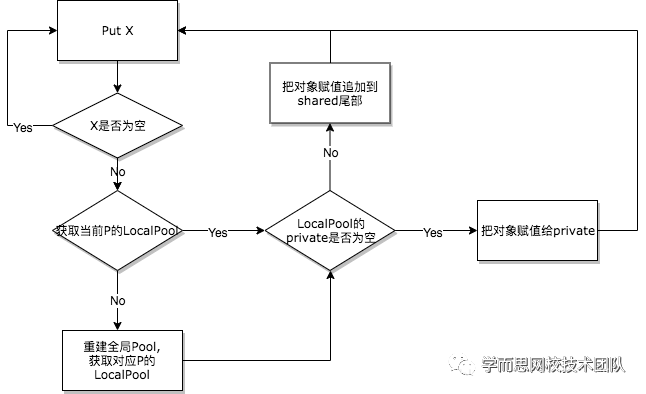
源码释义如下:
// Put adds x to the pool.
// Put方法比较简单,通过找到一个合适的`PoolLocal`,然后把释放的对象优先给到`local.private`,如果`private`不空,则追加到`shared`的尾部
func (p *Pool) Put(x interface{}) {
if x == nil {
return
}
if race.Enabled {
if fastrand()%4 == 0 {
// Randomly drop x on floor.
return
}
race.ReleaseMerge(poolRaceAddr(x))
race.Disable()
}
l := p.pin()
if l.private == nil {
l.private = x
x = nil
}
runtime_procUnpin()
if x != nil {
l.Lock()
l.shared = append(l.shared, x)
l.Unlock()
}
if race.Enabled {
race.Enable()
}
}
GC回收对象池
回收注册
对象池的回收是在GC的时候调用注册方法poolCleanup实现的,所以Go的sync.Pool所实现的对象池功能的生命周期是两次GC间隔时间。
func init() {
runtime_registerPoolCleanup(poolCleanup)
}
回收实现
func poolCleanup() {
// This function is called with the world stopped, at the beginning of a garbage collection.
// It must not allocate and probably should not call any runtime functions.
// Defensively zero out everything, 2 reasons:
// 1. To prevent false retention of whole Pools.
// 2. If GC happens while a goroutine works with l.shared in Put/Get,
// it will retain whole Pool. So next cycle memory consumption would be doubled.
//遍历全局allPools,allPools的的元素是通过pinSlow方法里重建Pool时添加的
for i, p := range allPools {
allPools[i] = nil
for i := 0; i < int(p.localSize); i++ {
l := indexLocal(p.local, i)
//清空private
l.private = nil
//清空shared
for j := range l.shared {
l.shared[j] = nil
}
l.shared = nil
}
//清空pool对象
p.local = nil
p.localSize = 0
}
//重置allPools全局对象
allPools = []*Pool{}
}
var (
allPoolsMu Mutex
allPools []*Pool
)
对象池的升级(go1.13)
结构的调整
Pool结构的改变
加入了两个新的属性,victim和victimeSize
type Pool struct {
noCopy noCopy
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
localSize uintptr // size of the local array
victim unsafe.Pointer // local from previous cycle
victimSize uintptr // size of victims array
// New optionally specifies a function to generate
// a value when Get would otherwise return nil.
// It may not be changed concurrently with calls to Get.
New func() interface{}
}
poolLocalInternal结构的改变
// Local per-P Pool appendix.
type poolLocalInternal struct {
private interface{} // Can be used only by the respective P.
shared poolChain // Local P can pushHead/popHead; any P can popTail.
}
// poolChain is a dynamically-sized version of poolDequeue.
//
// This is implemented as a doubly-linked list queue of poolDequeues
// where each dequeue is double the size of the previous one. Once a
// dequeue fills up, this allocates a new one and only ever pushes to
// the latest dequeue. Pops happen from the other end of the list and
// once a dequeue is exhausted, it gets removed from the list.
type poolChain struct {
// head is the poolDequeue to push to. This is only accessed
// by the producer, so doesn't need to be synchronized.
head *poolChainElt
// tail is the poolDequeue to popTail from. This is accessed
// by consumers, so reads and writes must be atomic.
tail *poolChainElt
}
type poolChainElt struct {
poolDequeue
// next and prev link to the adjacent poolChainElts in this
// poolChain.
//
// next is written atomically by the producer and read
// atomically by the consumer. It only transitions from nil to
// non-nil.
//
// prev is written atomically by the consumer and read
// atomically by the producer. It only transitions from
// non-nil to nil.
next, prev *poolChainElt
}
// poolDequeue is a lock-free fixed-size single-producer,
// multi-consumer queue. The single producer can both push and pop
// from the head, and consumers can pop from the tail.
//
// It has the added feature that it nils out unused slots to avoid
// unnecessary retention of objects. This is important for sync.Pool,
// but not typically a property considered in the literature.
type poolDequeue struct {
// headTail packs together a 32-bit head index and a 32-bit
// tail index. Both are indexes into vals modulo len(vals)-1.
//
// tail = index of oldest data in queue
// head = index of next slot to fill
//
// Slots in the range [tail, head) are owned by consumers.
// A consumer continues to own a slot outside this range until
// it nils the slot, at which point ownership passes to the
// producer.
//
// The head index is stored in the most-significant bits so
// that we can atomically add to it and the overflow is
// harmless.
headTail uint64
// vals is a ring buffer of interface{} values stored in this
// dequeue. The size of this must be a power of 2.
//
// vals[i].typ is nil if the slot is empty and non-nil
// otherwise. A slot is still in use until *both* the tail
// index has moved beyond it and typ has been set to nil. This
// is set to nil atomically by the consumer and read
// atomically by the producer.
vals []eface
}
type eface struct {
typ, val unsafe.Pointer
}
方法实现调整
Get的实现调整
Get方法中,从1.12版本中的从shared尾部获取对象x变成了从头部获取。
func (p *Pool) Get() interface{} {
if race.Enabled {
race.Disable()
}
l, pid := p.pin()
x := l.private
l.private = nil
if x == nil {
// Try to pop the head of the local shard. We prefer
// the head over the tail for temporal locality of
// reuse.
x, _ = l.shared.popHead()
if x == nil {
x = p.getSlow(pid)
}
}
runtime_procUnpin()
if race.Enabled {
race.Enable()
if x != nil {
race.Acquire(poolRaceAddr(x))
}
}
if x == nil && p.New != nil {
x = p.New()
}
return x
}
Put的实现调整
Put方法中,从1.12版本的把对象x放到shared尾部变成了放到了头部。
// Put adds x to the pool.
func (p *Pool) Put(x interface{}) {
if x == nil {
return
}
if race.Enabled {
if fastrand()%4 == 0 {
// Randomly drop x on floor.
return
}
race.ReleaseMerge(poolRaceAddr(x))
race.Disable()
}
l, _ := p.pin()
if l.private == nil {
l.private = x
x = nil
}
if x != nil {
l.shared.pushHead(x)
}
runtime_procUnpin()
if race.Enabled {
race.Enable()
}
}
getSlow的实现调整
getSlow方法中,变化如下:
- 1.12版本:遍历所有P对应的PoolLocal,并且从shared尾部获取对象
- 1.13版本:遍历所有P对应的PoolLocal,并且从shared头部获取对象,如果无法获取,则找对应P的victim的private获取对象,如果无法获取,则从所有P对应的victim里的shared尾部获取对象。
func (p *Pool) getSlow(pid int) interface{} {
// See the comment in pin regarding ordering of the loads.
size := atomic.LoadUintptr(&p.localSize) // load-acquire
locals := p.local // load-consume
// Try to steal one element from other procs.
//遍历所有localPool的shared获取可用对象
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i+1)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// Try the victim cache. We do this after attempting to steal
// from all primary caches because we want objects in the
// victim cache to age out if at all possible.
size = atomic.LoadUintptr(&p.victimSize)
if uintptr(pid) >= size {
return nil
}
//PoolLocal无法获取对象,从victim获取
locals = p.victim
l := indexLocal(locals, pid)
if x := l.private; x != nil {
l.private = nil
return x
}
//遍历所有victim的shared获取可用对象
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// Mark the victim cache as empty for future gets don't bother
// with it.
atomic.StoreUintptr(&p.victimSize, 0)
return nil
}
回收方法的调整
回收方法里对victim做了一些工作,将所有对象池分为新的和旧的,每一次GC的时候,先把旧的对象池集合的victim回收,将新的对象池集合的local赋值给victim,然后回收新的对象池集合的local,之后新的对象池集合赋值给旧对象池集合,旧对象池集合的victim将在下一次GC的时候被回收。
func poolCleanup() {
// This function is called with the world stopped, at the beginning of a garbage collection.
// It must not allocate and probably should not call any runtime functions.
// Because the world is stopped, no pool user can be in a
// pinned section (in effect, this has all Ps pinned).
// Drop victim caches from all pools.
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// Move primary cache to victim cache.
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
// The pools with non-empty primary caches now have non-empty
// victim caches and no pools have primary caches.
oldPools, allPools = allPools, nil
}
var (
allPoolsMu Mutex
// allPools is the set of pools that have non-empty primary
// caches. Protected by either 1) allPoolsMu and pinning or 2)
// STW.
allPools []*Pool
// oldPools is the set of pools that may have non-empty victim
// caches. Protected by STW.
oldPools []*Pool
)
性能的提升
优化数据结构提升性能
先从下图了解下内部数据读取流程的改变:
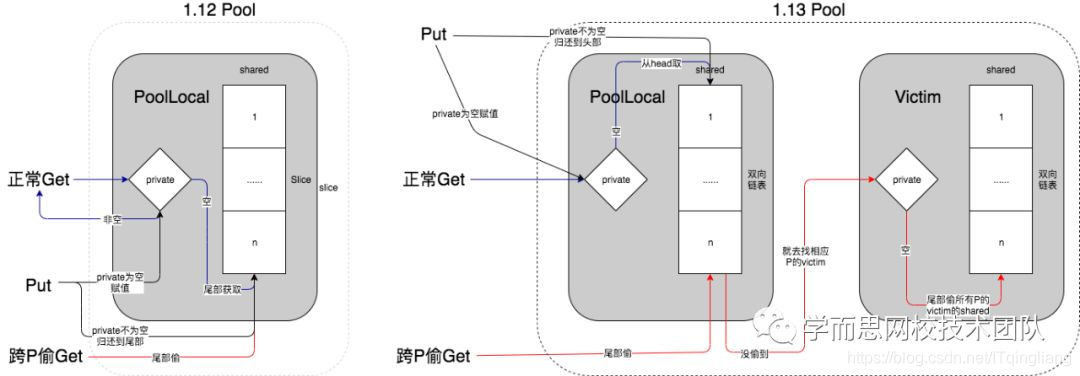
接下来我们分析一下上面的图,图中主要围绕了三种操作进行对比,这里我们做一个总结分析:
- 在1.12版本中,无论是Get还是Put还是跨P偷,就得操作shared的尾部,我们知道每个shared其实是对所有协程都可见的,每次都得切割slice,slice并不是协程安全的,所以这里需要去加锁,所以会有性能损耗。
- 在1.13版本中,将Get和Put与跨P偷做了隔离,shared使用了无锁双向链表实现,当协程去对应的PoolLocal去获取对象的时候,其实是先从shared双向链表的头部去获取,Put操作也是一样,所以性能得到了提升。
增加对象复用周期提升性能
- 在1.12版本中,GC回收所有的对象池集合的时候,会将所有的local全部重置回收,对象复用的周期只有一个GC间隔时间。
- 在1.13版本中,GC回收将所有对象池分为新的和旧的,每一次GC的时候,先把旧的对象池集合的victim回收,将新的对象池集合的local赋值给victim,然后回收新的对象池集合的local,之后新的对象池集合赋值给旧对象池集合,旧对象池集合的victim将在下一次GC的时候被回收,这里将次轮GC前积累的对象带到下轮GC再回收,再下轮GC之前,如果local没有可用对象的话,依然可以去victim里去获取,victim的设计将对象池的复用周期扩大了一个GC间隔时间。
参考资料
【1】 https://mp.weixin.qq.com/s/pMooZiba5VzbILr4OYlYzA
