为什么文本乱码呢,我来告诉你什么是编码,解码,乱码
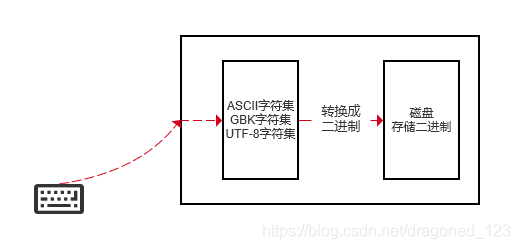
1.编码
二进制
了解编码之前需要了解一下二进制,二进制是计算机处理字符的基础,所有的字符通过相应的字符编码方式转化成二进制存放到电脑的硬盘上面。比如:
| 十进制 | 二进制 |
|---|---|
| 2 | 0000 0010 |
| 127 | 0111 1111 |
| 128 | 1000 0000 |
| 2,048 | 1000 0000 0000 |
| 32,768 | 1000 0000 0000 0000 |
每个二进制数字0或1就是一个位(bit)。位是数据存储的最小单位,其中8 bit 就称为一个字节(Byte)即 1Byte=8bit
十六进制
十六进制也比较简单,由16个数0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F组成,比如108的二进制是0110 1100,前四位可以转化0110是6,1100是12即是C,所以十六进制为 6C。
字符集
ASCII编码
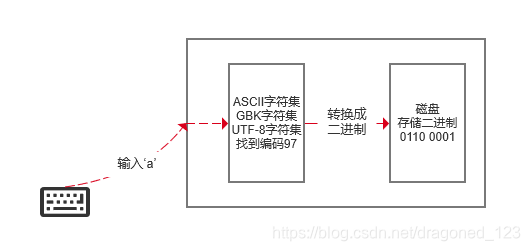
ASCII 字符集共有 128 个字符,其中有 96 个可打印字符,包括常用的字母、数字、标点符号等,另外还有 32 个控制字符。其实一个字节就可以表示所有的ASCII编码序号比如‘a’字符在ASCII的位置是 97 对应的二进制是 0110 0001
ISO-8859-1编码
ISO-8859-1收录的字符除ASCII收录的字符外,还包括西欧语言、希腊语、泰语、阿拉伯语、希伯来语对应的文字符号。欧元符号出现的比较晚,没有被收录在ISO-8859-1当中。
从 1 到 127 之间的代码是最初的 7bit ASCII编码。
从 160 到 255 之间的代码全都有实体名称,即是西欧的语言符号。
windows-1252编码
编码与ISO-8859-1的编码基本一致,区别在于128-159,使得ISO-8859-1没有编码的欧元符号等等能够展现,现在的ISO-8850-1基本都被windows-1252取代。
GB2312编码
中国第一个关于汉字的编码是GB2312,包括常见的7000多个汉字,不包括繁体字。使用两个字节表示,最高位是1,如果最高位是0表示的是ASCII编码。第一个字节的范围是1010 0001-1111 0111,第二个字节的范围是1010 0001-1111 1110。
GBK编码
GBK向下兼容GB2312,同时包含了繁体字,总计大约21000个汉字,第一个字节的范围是1000 0001-1111 1110,第二个字节的范围是0100 0000-0111 1110和1000 0000-1111 1110。
GB18030编码
GB18030向下兼容GBK,增加了少数民族的符号和中日韩统一字符,GB18030使用了变长编码,可能是两个字节也有可能是四个字节,两个字节是和GBK一样的编码,四个字节的范围是:第一个字节的范围是1000 0001-1111 1110,第二个字节的范围是0011 0000-0011 1001,第三个字节的范围是1000 0001-1111 1110,第四个字节的范围是0011 0000-0011 1001。
Big5编码
针对港澳地区,针对繁体中文的编码,一个字符使用两个字节表示,第一个字节的范围是1000 0001-1111 1110,第二个字节的范围是0100 0000-0111 1110和1010 0001-1111 1110。GB2312,GBK,GB18030都不兼容。
Unicode编码
世界所有的字符统一的进行字符编号,从0x000000-0x10FFFF编号。
UTF-32编码
由四个字节表示,如果第一个字节是二进制里面的最高位,第二个字节是二进制的最低位叫做大端(UTF-32BE),如果第一个字节是二进制里面的最低位,第二个字节是二进制的最高位叫做小端(UTF-32LE)
| Unicode编码 | UTF-32BE | UTF-32LE |
|---|---|---|
| 0x005CAF | 00 00 05 AF | 05 AF 00 00 |
| 0x03889B | 00 03 88 9B | 9B 88 03 00 |
UTF-16编码
其编码方式比较复杂,使用二或四个字节为每个字符编码,其中大部分汉字采用两个字节编码,少量不常用汉字采用四个字节编码。UTF-16 编码有大尾序和小尾序之别,即 UTF-16BE 和 UTF-16LE,在编码前会放置一个 U+FEFF 或 U+FFFE(UTF-16BE 以 FEFF 代表,UTF-16LE 以 FFFE 代表)UTF-16比起UTF-8,好处在于大部分字符都以固定长度的字节 (2字节) 储存,但UTF-16却无法兼容于ASCII编码。
UTF-8编码
使用一至四个字节为每个字符编码,其中大部分汉字采用三个字节编码,少量不常用汉字采用四个字节编码。因为 UTF-8 是可变长度的编码方式,相对于 Unicode 编码可以减少存储占用的空间,所以被广泛使用。
2.解码
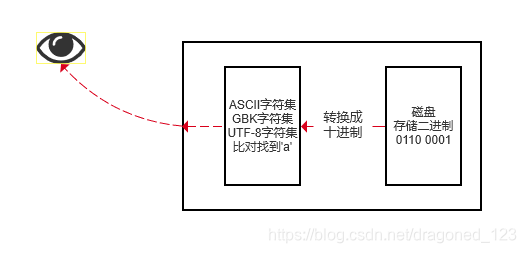 解码相当于从计算机的存储空间里面读取二进制文件然后根据保存的编码类型进行转换,找到相应的编码序号对用的字符显示到电脑屏幕上。
解码相当于从计算机的存储空间里面读取二进制文件然后根据保存的编码类型进行转换,找到相应的编码序号对用的字符显示到电脑屏幕上。
3.乱码
有时候当我们打开一个文本文件的时候,会出现乱码,英文能够正常打开,可是遇到中文就出现奇怪的文字比如这样:
 先写一段代码写入一个字符串到文件里面(当然你也可以用notepad或者vs code直接编辑)
先写一段代码写入一个字符串到文件里面(当然你也可以用notepad或者vs code直接编辑)
import java.io.File;
import java.io.FileOutputStream;
public class testencode {
public static void main(String[] args) throws Exception {
File f = new File("file.txt");
FileOutputStream fou = null;
fou = new FileOutputStream(f);
String str = "hello world ! 你好世界!";//将要转换编码的字符串
byte[] b = str.getBytes("GBK");//转换字符串的编码为GBK产生字节数组
fou.write(b);//写入文件
fou.close();
System.out.println("操作完成");
}
}
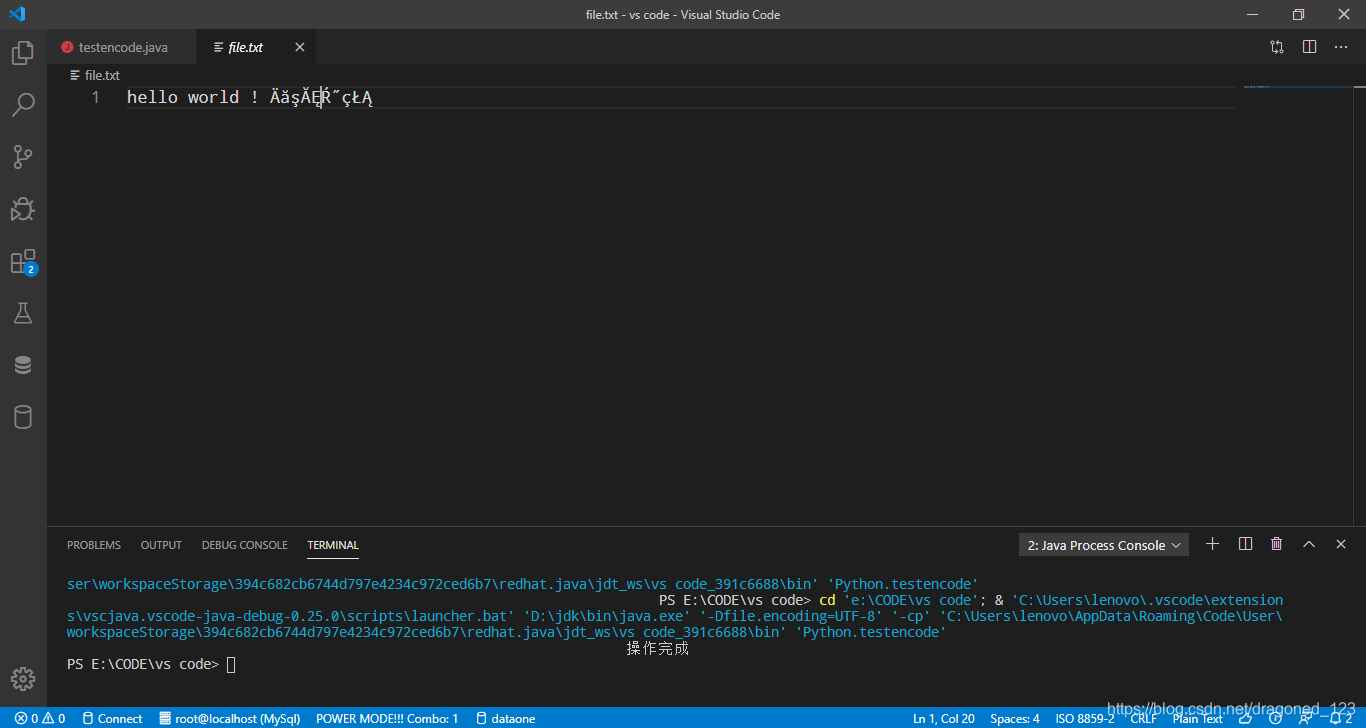
写入之后用vs code打开可以看到乱码,就是上面图片里面的乱码
怎么解决呢?这个代码我把字符串的编码转换成GBK,产生乱码是因为打开的解码方式不对,把文件打开方式转换一下就行了。
这是默认的打开方式是ISO 8859-2编码方式,点击一下编码
 点击Reopen,找到GBK就行了
点击Reopen,找到GBK就行了

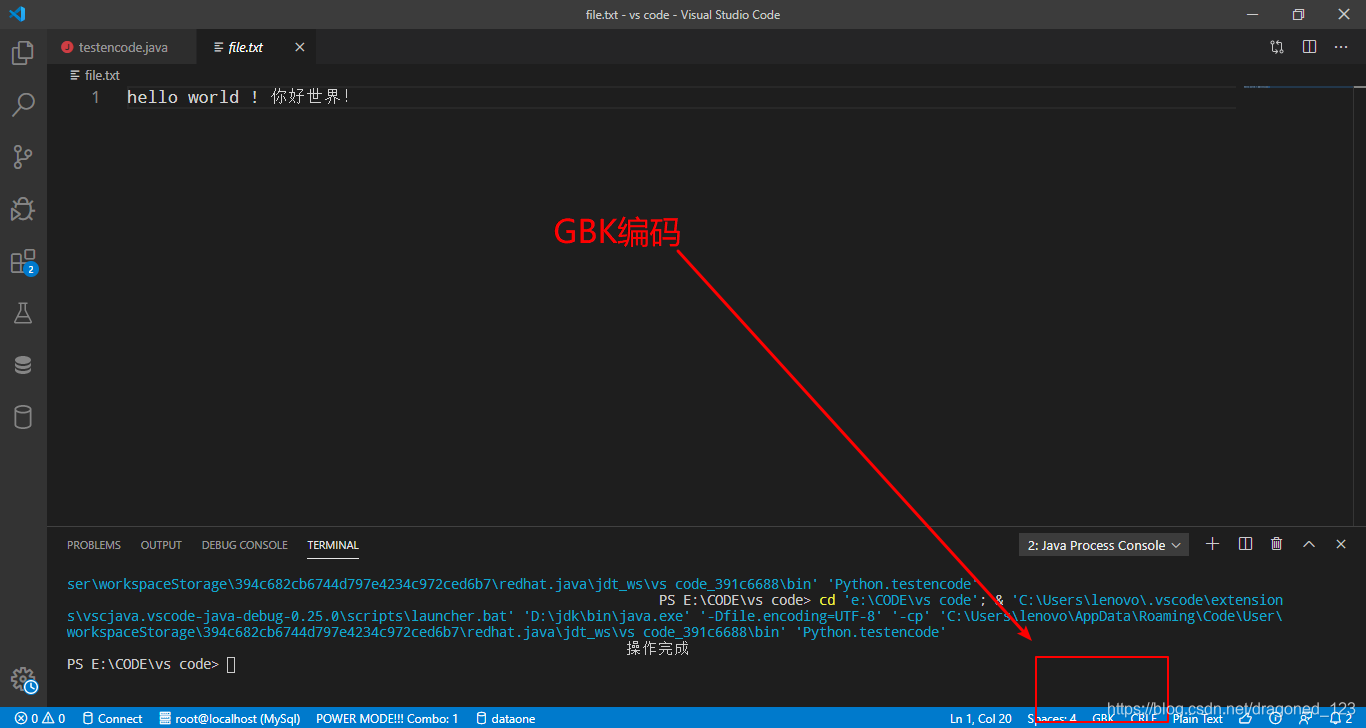
结果是:
总结一下:字符串出现乱码,要注意打开的解码方式是否和编码方式一致,一致的话显示是没有问题的,不一致的话中文很容易出现乱码,乱码归根结底还是编码和解码之间的不匹配问题,当然编码的转换不一定是可逆的,也就是说你以一种错误的解码方式解码得到的字符串,再把这个字符串转换回去,有可能会出现信息丢失的现象发生。后续我会写文章说一下可逆和不可逆的问题。
