大数据技术基础
计算机操作系统
操作系统统筹协调计算机硬件系统的工作,具体使CPU可以进行逻辑与数值运算,主存储器能够加载应用数据与程序代码,硬盘可以顺利存入与读出信息,输入设备、输出设备可以根据需要实时写入、写出必要信息等。因此,操作系统实际是整个计算机硬件系统的“CEO”,担负着整个计算机硬件系统的管理、协调和运作的全部任务。
Linux操作系统
-
三个发展阶段
- 1.单一个人维护阶段
- 2.广大黑客志愿者加入阶段
- 3.Linux核心的细分工、快速发展阶段
-
核心版本编号示例
-
Linux Kernel与Linux Distribution
-
Linux的核心版本是Linux Kernel的版本
-
Linux Distribution是专门为使用者量身打造的Linux Kernel + Software + Tools的可安全安装程序的综合发布版本,可帮助日常使用者在Linux系统下完成工作和其他相关任务。
-
Linux Distribution主要版本
-
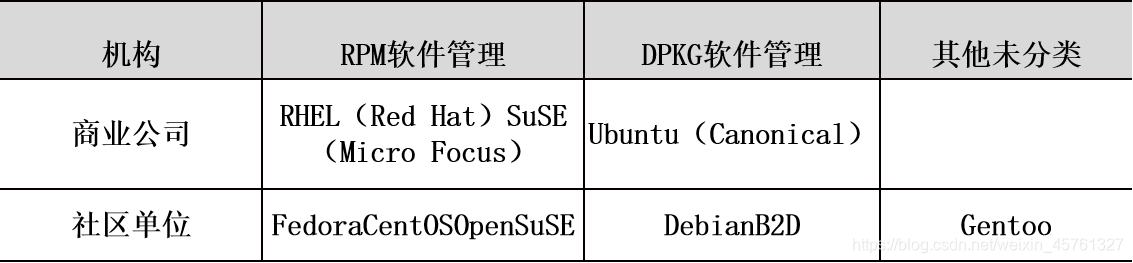
主要分为两大系统
- 1.使用RPM(Red-Hat Package Manager)方式安装软件的系统,主要有RHEL、SuSE、Fedora等
- 2.使用Debian的DPKG方式安装软件的系统,包括Ubuntu、Debian、B2D等
-
-
-
两者关系
-
-
Linux的主要应用场景
- (1)企业环境的应用,主要包括网络服务器(目前最热门的应用)、关键任务的应用(金融数据库、大型企业网管环境)、学术机构的高效能运算任务等。
- (2)个人环境的使用,主要包括桌面计算机系统(实现和Windows系统一样的桌面操作系统)、手持系统(PDA、手机端系统如Android)、嵌入式系统(包括路由器、防火墙、IP分享器、交换机等)。
- (3)云端的运用,主要包括云程序(云端虚拟机资源)、云端设备等。


编程语言
发展史
-
语言可以使人们以更加规范、方便和快捷的方式进行交流。
-
伴随着晶体管计算机的诞生(上世纪40年代),人们也编写了第一种真正意义上的编程语言,这就是机器语言。
-
机器语言太难理解和书写,且极易出错,汇编语言(Assembly Language)就应运而生。
- 使用助记符(Mnemonics)来代替机器指令的操作码(0和1的指令集)
- 用标号(Label)和地址符号(Symbol)分别来代替机器指令或者操作数值的存储地址
- 其大体的工作原理

- 机器语言和汇编语言统称为低级语言(1946—1953年)。
-
因汇编语言未能实现与自然语言的对接,编程语言进入高级语言时代(1954至今)
-
1954,John Backus在纽约发布人类第一个高级编程语言FORTRAN(FORmula TRANslator),主要用于做数值/科学计算
-
1957,第一个FORTRAN编译器在IBM 704计算机上实现,并首次成功运行了FORTRAN程序。
-
1960年出现了第一个结构化语言Algol(Algorithmic Language),它是算法语言的鼻祖,目的在于纯粹面向描述计算过程,其语法也是用严格的公式化的方法说明的。其标志着程序语言设计成为一名独立的学科
-
1964年,美国达特茅斯学院的J.Kemeny和T.Kurtz开发了BASIC(Beginners All Purpose Symbolic Introduction Code),该语言只有26个变量、17条语句,是初学编程人员的福音。
-
后来,编程语言发展到了使用编译器的阶段,出现了我们都熟知的C语言(Compiler language)。这种语言的核心在于编译器,而编译器的作用就是把某种语言写的代码转变为机器语言,从而让计算机识别并运行。
-
高级语言经过编译器时代的发展,过渡到面向对象时代(1995年开始),编程人员终于可以针对特殊的对象进行一对一的编程处理。业内称这种方法为面向对象程序设计(Object-Oriented Programming,OOP)。
-
随着面向对象程序设计语言的不断成熟,IDE(Integrated Develop Environment)作为提供程序开发环境的应用程序开始得到发展。
- IDE一般包括代码编辑器、编译器、调试器和图形用户界面工具,也就是集成了代码编写功能、分析功能、编译功能、调试功能等一体化的开发软件服务套件。这样的集成开发环境大大方便了编程人员的开发工作。随着Java语言的全球风靡,与之相关的IDE也不断地发展起来。
-
Python
-
Python语言诞生于1991年(比Java还早,最早发行于1994年)
-
优点
- 可读性强
- 代码量少
- 动态语言
- 编写简单
- 应用广泛
数据库
数据库技术是信息技术的核心技术。显然大数据时代仍然要依赖数据库技术提供可靠、安全、高效的数据存储和查询服务。
SQL数据库
- 1970年,IBM公司的研究员E.F.Codd博士提出的关系模型的概念奠定了整个关系模型的理论基础
- 1970年,关系模型建立后,IBM公司在San Jose实验室投入了大量的人力、物力研究出著名的System R数据库项目,初始目的在于论证关系型数据库的可行性。
- SQL最早在1986年由ANSI(American National Standards Institution)认定为关系型数据库语言的美国标准,同年即公布了标准的SQL文本。
- 基本可以说SQL数据库已经发展到了品类齐全、种类繁多的产品格局
NoSQL数据库
-
NoSQL采用了一些主要包括键-值、列族、文档等非关系模型不同于SQL的数据库管理系统设计方式
-
三大特点
-
1.优秀的可扩展性
- SQL数据库严格遵守ACID设计原则,所以一般很难实现硬件存储设备的“横向扩展”(多集群机器联动服务)。
-
2.方便多用的数据类型承载能力
- NoSQL数据库在设计之初就放弃了传统数据库的关系数据模型,旨在满足大数据的处理需求,采用诸如键-值、列族、文件集等多样的新型数据模型,并且对图形数据的兼容性也日渐提升
-
3.NoSQL数据服务与云计算可以紧密融合
- 云计算和云服务是当前时代的信息服务高地,其很多特点如水平扩展、多用户并行处理、远程登录操控等都可以与NoSQL数据库实现无缝对接
-
-
主要类型
-
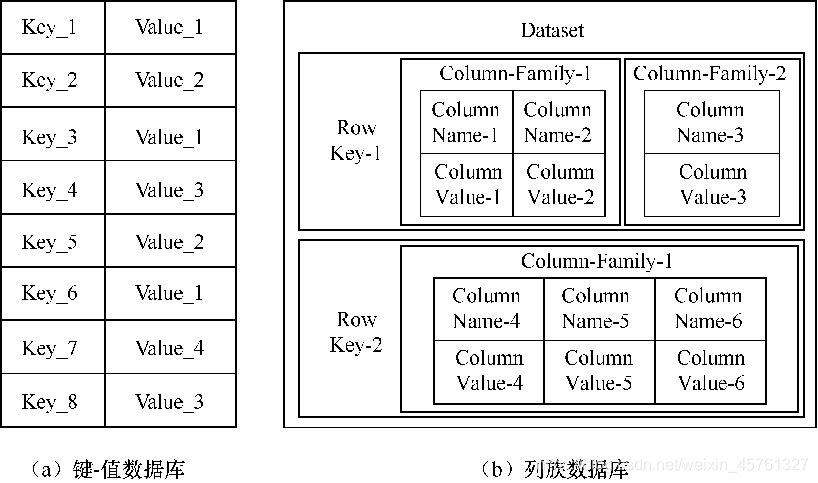
典型的NoSQL数据库通常包括键-值数据库、列族数据库、文档数据库和图形数据库4种类型
-
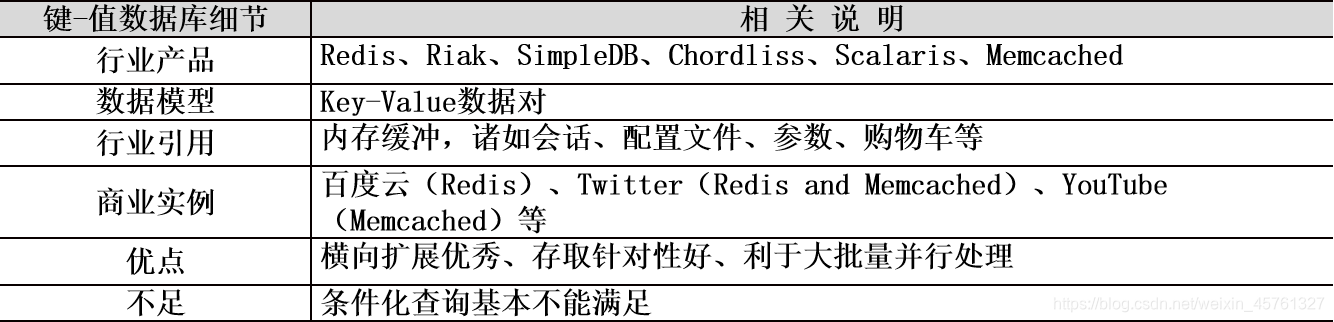
键值数据库
-
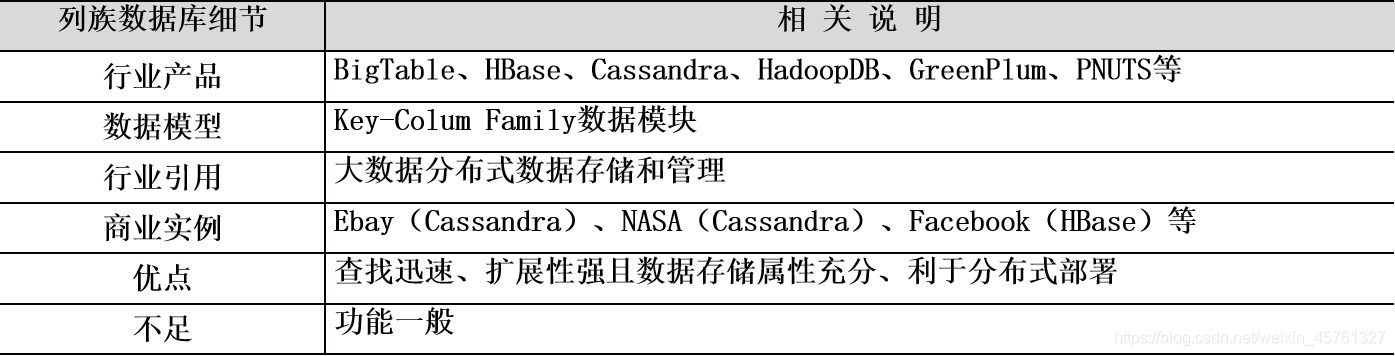
列族数据库
- 列族数据库(Column-Family DataBase)每个行键索引指向的是一个列族,列族数量管理者自己制定,这样相对键-值数据库每个行键只能针对一个数据属性的不足得到了大大的改善。
- 同时,列族数据库支持不同类型的数据访问模式,同一个列族可以被同时一起放入计算机内存之中,这样虽然消耗了内存存储,却带来了更好的数据响应性能。
-
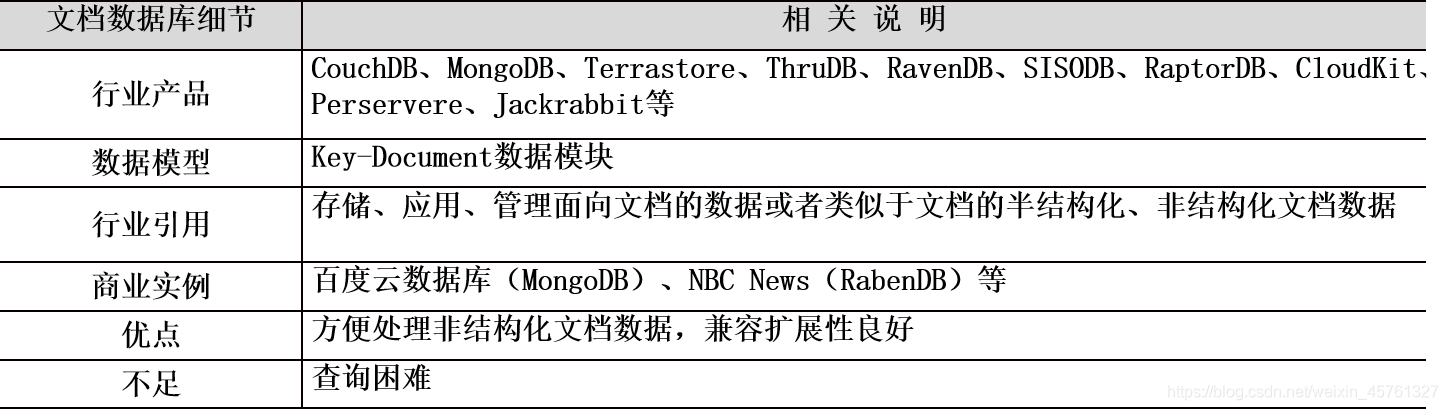
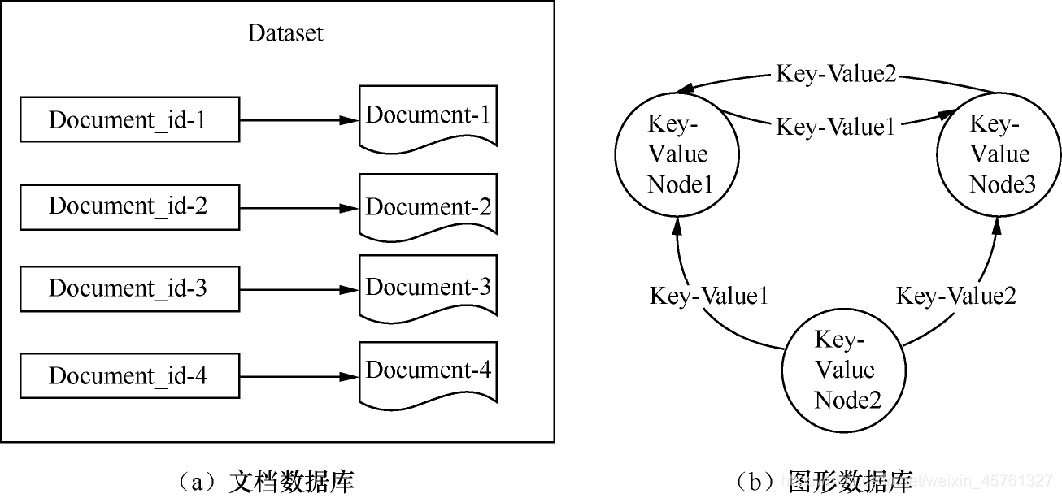
文档数据库
- 文档数据库(Document DataBase)的数据模式实际是一个键-值对应一个文件,而文档是数据库的最小单位。
-
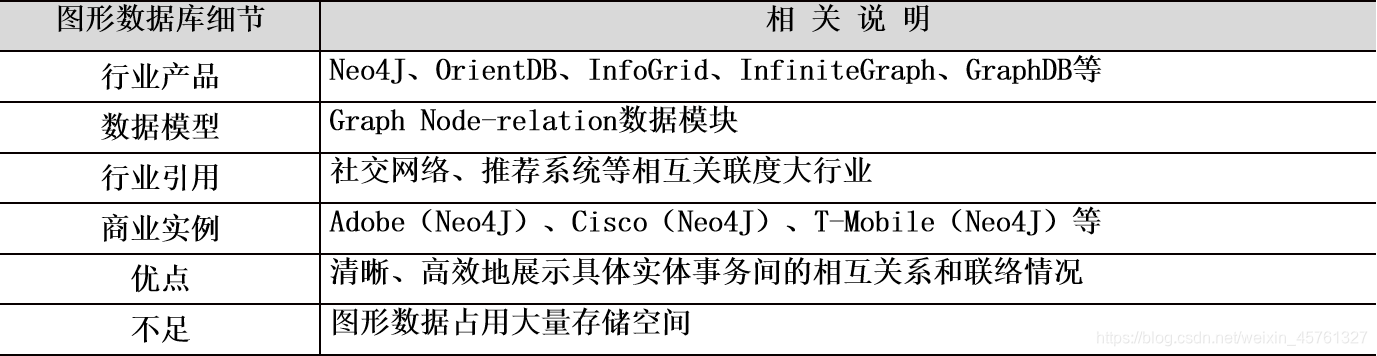
图形数据库
- 图形数据库(Graph DataBase)以图形为数据库基础,每一个图形代表一个数据库节点。
- 其组织模式以图论为基础,将一个图简化为一个数学概念,其表示了一个对象结合,而不同图形对象直接的关系则用关系键-值对来标明。
- 数据模型设计理念以图形为主题,可以高效地存储不同图形节点之间的关系,专门用于处理具有高度相互关联关系的数据,并使其以图形节点形式展现,十分适用于社交网络、模式识别、依赖分析、推荐系统及路径寻找等应用场景。
-
NewSQL数据库
- NewSQL数据库的诞生是为了解决NoSQL在难以满足海量数据查询和数据挖掘方面的需求等方面的问题
- 其综合了NewSQL综合了NoSQL和SQL数据库的技术优势,它既能像NoSQL数据库一样具有对海量数据足够优秀的扩展和并发处理能力,同时也具备SQL数据库对ACID和结构化快速高效查询的特点。
- 目前市场上具有代表性的NewSQL数据库主要包括Spanner、Clustrix、GenieDB、ScalArc、Schooner、VoltDB、RethinkDB、Akiban、CodeFutures、ScaleBase、Translattice、NimbusDB、Drizzle、Tokutek、JustOneDB等。但是,在严格意义上符合NewSQL数据库全部标准的理想NewSQL数据库或者标准的NewSQL数据库目前还没有出现。
算法
算法(Algorithm)是数学处理的灵魂和核心,也是实现现实事务数学化、公式化和逻辑化处理的桥梁,可以说算法是信息时代连通现实社会和虚拟世界的立交桥。
算法
- 算法是解决方案的准确而完整的描述,实质是一系列解决问题的高度符合逻辑性和可执行性的指令集合,其代表着用系统的方法描述解决问题的策略与机制。
- 其具体包括把符合算法要求的数据按照一定的数据结构方式进行准备、完整输入并存储,经过综合算法指令的步步实现后,在确认每个步骤合理完成后进行最后的结果输出和展现。
- 其评价标准为可行性、执行效率和对计算机的硬件要求
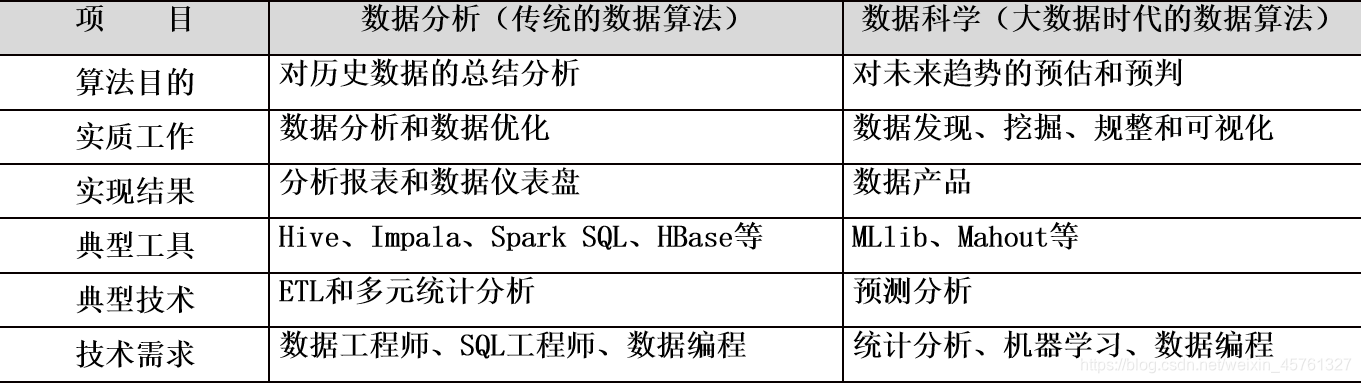
传统算法(数据分析)和大数据时代算法(数据科学)的区别

大数据时代的算法
-
机器学习
-
简介
- 最终目的在于专门研究如何用计算机模拟或者说实现人类的学习行为,以通过计算机的模拟学习获取新的知识和技能,并通过学习得来的“智慧”和理论来指导实现数据的分析和应用,尤其是对未来的预测和判断。
- 机器学习作为算法理论,是一门涉及多领域的交叉学科,包括概率论、数理统计、神经网络、线性代数、数值分析、计算机算法实现等多方面的知识,包含数学、计算机、哲学、人体学等的多种基础科学。
- 机器学习是在不设定任何前提规则的情况下由计算机完成学习,进而进行相应判断工作的科学。也就是让计算机模拟人类的思维学习方式去对海量的数据和逻辑关系进行学习研究,通过计算机的算法给出结论和判断。
- 目前最成熟、最流行的便是机器学习(Machine Learning)
-
技术优势
- (1)由于机器学习全部基于数据,排除了人类主观意识的干扰和经验主义,其学习或者说预测结果更加可信,并且随着数据量的增加带来更高的精确性。
- (2)机器学习可以由计算机实现自动的数据预测和一系列的数据推荐产品级应用。
- (3)机器学习算法理论上可以在毫秒级别实现并给出学习结果,这就允许我们进行事务的实时分析处理和运用,相比人类管理的层层审批制效率提高很多。
- (4)机器学习算法扩展性良好,理论上可以处理所有可用数据。
-
不足
- (1)机器学习的算法需要有些提前的预判(打标签),并且需要尽量完善、充实数据。
- (2)机器学习一般不能得到100%正确的预测结果,具有一定的风险。
-
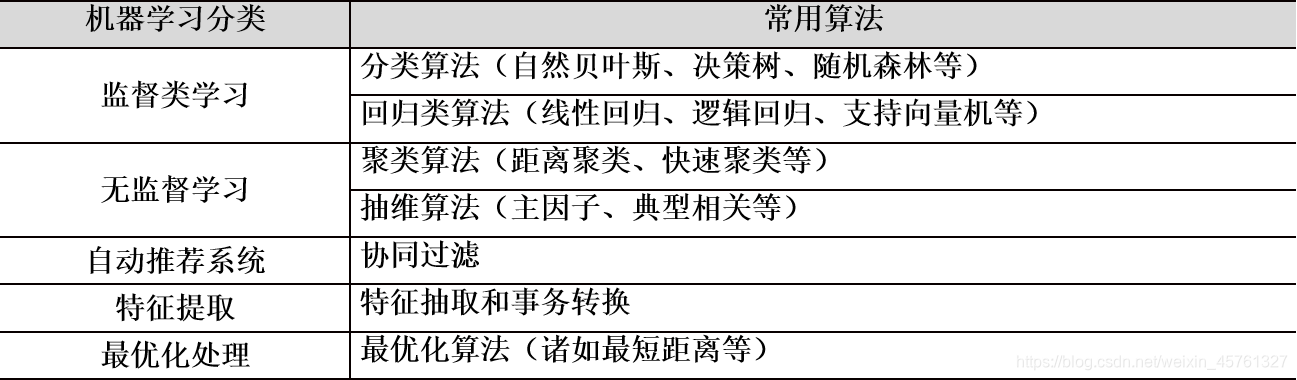
目前较流行的机器学习算法
-
大数据系统
Hadoop平台
-
简介
- Hadoop平台是Apache的开源的、理论上可无限扩展的分布式计算平台,其设计的初始目的是让大型计算机集群对海量的数据进行常规编程计算实现。
- Hadoop集群框架在设计之初即考虑到会出现安全隐患,在出现大规模的集群崩溃的情况下,开发应用人员需要做出人工处理。
-
主要模块
-
(1)Hadoop Common
- Hadoop Common是平台统一的集成,用来支持其他模块的共同工作,它就好比是计算机系统的主板,用来连通其他组件。
-
(2)HDFS
- HDFS全称为Hadoop Distributed File System,它是平台提供的分布式集群存储框架,支持平台对海量数据进行集群存储,并且保证数据的可靠、稳定和安全。
-
(3)YARN
- YARN即Yet Another Resource Negotiator,是Hadoop平台的集群资源管理和工作流程控制框架。
-
(4)MapReduce
- MapReduce是平台YARN框架管理下的分布式集群高效计算框架。
-
-
三大特征
-
1)Hadoop平台的三大组成
- ① 可靠、高效的分布式大数据存储框架—HDFS。
- ② 用于并行集群处理的计算框架—MapReduce、Crunch、Cascading、Hive、Tez、Impala、pig、Mahout等。
- ③ 平台集群资源管理器—YARN和Slider。
-
(2)Hadoop平台在经济、商业和技术领域的适应性和优势
- ① 经济性。
- ② 商业性。
- ③ 技术性。
-
(3)Hadoop平台的典型技术特点
- ① 商业实用性强。
- ② 纠错能力强。
- ③ 优秀的随时可扩展性。
- ④ 简单实用。
-
Spark平台
-
简介
- Hadoop平台下的MR(MapReduce)分布式计算框架存在致命的缺陷,MR只能进行一次性编程计算处理,然后再存入HDFS,所以MR就很难进行海量数据的迭代运算。为解决这一问题,Spark应运而生
- Spark最初是2009年由加州大学伯克利分校的RAD实验室开启的研究项目,此后RAD实验室更名为AMPLab,此项目组在利用开源平台Hadoop MapReduce分布式运算框架后意识到了其在迭代运算方面的不足,开始计划通过内存计算的方式改进MR的相关运算不足的缺陷,于是在2011年,AMPLab发展了更高运算部分的Shark和Spark Streaming,这些组件被称为Berkeley Data Analytics Stack(BDAS)。这些都是Spark正式版本的主要组成部分,Spark作为开源项目最开始版本,完成于2010年3月,此后于2013年6月转为Apache软件基金会旗下的顶级开源项目。
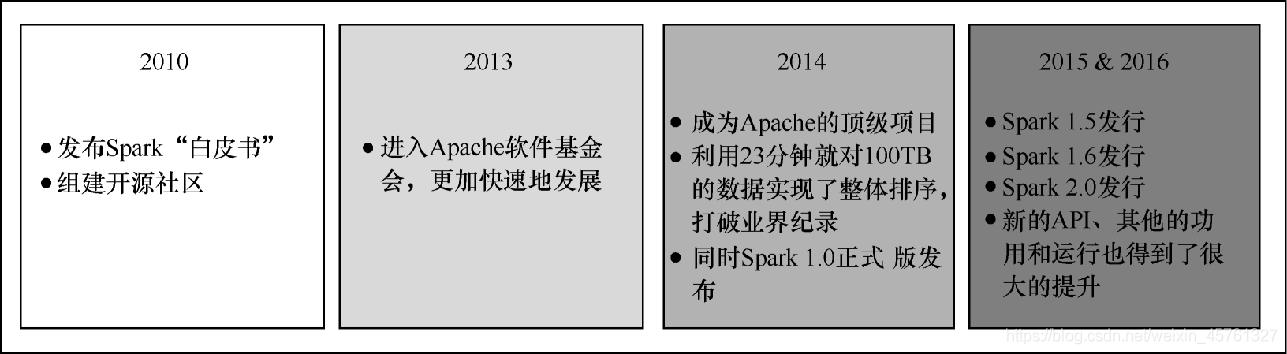
- 由于Hadoop也是Apache软件基金会旗下的顶级大数据平台项目,这样无疑加速了 Spark 的发展,其具体发行版本如图 2-10所示。
-
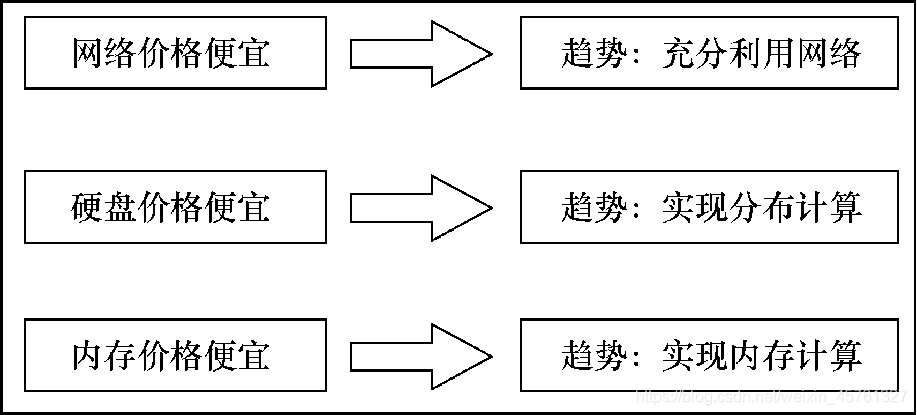
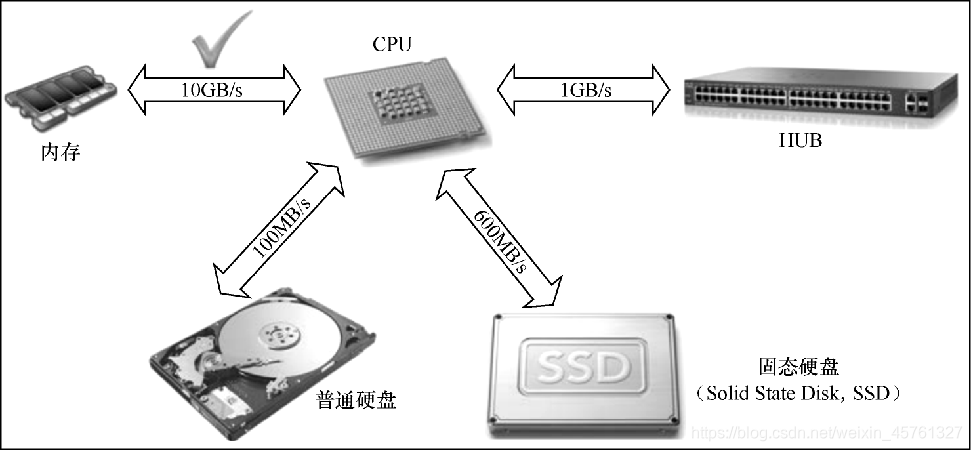
计算机的运算技术趋势
-
Spark的发行版本
-
Spark与MapReduce的区别

大数据的数据类型
结构化数据
- 传统关系型数据库数据,也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理。
- 结构化数据可以通过固有键值获取相应信息,并且数据的格式严格固定,如RDBMS data。最常见的结构化就是模式化,结构化数据也就是模式化数据。
- 大多数传统数据技术应用主要基于结构化数据,如银行业数据、保险业数据、政府企事业单位数据等主要依托结构化数据。结构化数据也是传统行业依托大数据技术提高综合竞争力和创新能力的主要数据类型。
半结构化数据
-
半结构化数据和普通纯文本相比具有一定的结构性,但和具有严格理论模型的关系型数据库的数据相比更灵活。
-
它是一种适用于数据库集成的数据模型,也就是说,适于描述包含在两个或多个数据库(这些数据库含有不同模式的相似数据)中的数据。
-
它是一种标记服务的基础模型,用于在Web上共享信息。
-
人们对半结构化数据模型感兴趣主要是它的灵活性。特别地,半结构化数据是“无模式”的。更准确地说,其数据是自描述的。它携带了关于其模式的信息,并且这样的模式可以随时间在单一数据库内任意改变。这种灵活性可能使查询处理更加困难,但它给用户提供了显著的优势。
-
特征
-
半结构化数据的结构模式具有下述特征。 - ① 数据结构自描述性。结构与数据相交融,在研究和应用中不需要区分“元数据”和“一般数据”(两者合二为一)。
- ② 数据结构描述的复杂性。结构难以纳入现有的各种描述框架,实际应用中不易进行清晰的理解与把握。
- ③ 数据结构描述的动态性。数据变化通常会导致结构模式变化,整体上具有动态的结构模式。
-
非结构化数据
-
非结构化数据一般指无法结构化的数据,如图片、文件、超媒体等典型信息,在互联网上的信息内容形式中占据了很大比例。
-
具体的非结构化数据处理技术包括:
- ①Web页面信息内容提取;
- ②结构化处理(含文本的词汇切分、词性分析、歧义处理等);
- ③语义处理(含实体提取、词汇相关度分析、句子相关度分析、篇章相关度分析、句法分析等);
- ④文本建模(含向量空间模型、主题模型等);
- ⑤隐私保护(含社交网络的连接型数据处理、位置轨迹型数据处理等)。
大数据应用开发流程
典型流程

- 1.提出商业需求并做出初步设想
- 2.根据需求确定必需的数据集
- 3.数据采集
- 4.数据预处理
- 5.数据分析和挖掘
- 6.大数据产品可视化
数据科学算法的应用流程
典型流程
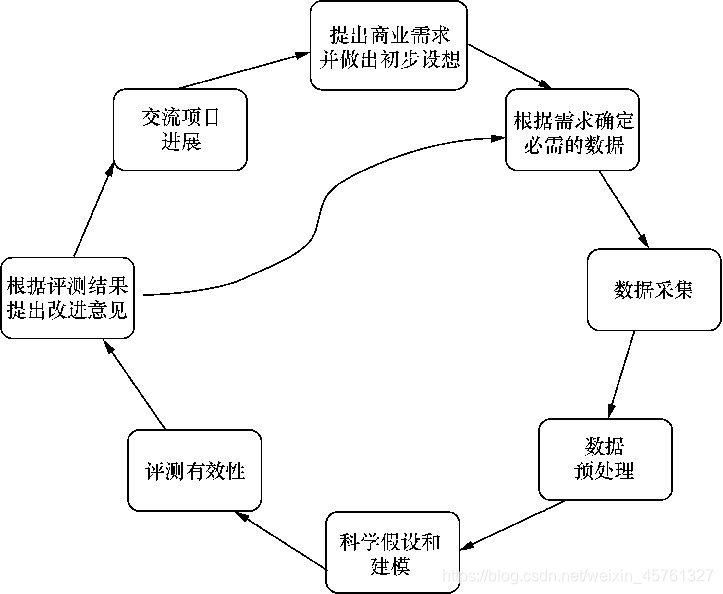
- 1.科学假设和建模
- 2.评测有效性
- 3.根据评测结果提出改进意见
- 4.交流项目进展
XMind: ZEN - Trial Version
