双链表是单链表的拓展,单链表结点中只有一个指向其后继的指针,双链表有两个结点,一个指向其后继的指针,另一个指向前驱。
为什么要引入双链表呢?
这就要说单链表只有一个指针了,使得单链表只能从结点依次顺序地向后遍历,要访问某个p结点前面的结点,只能从头遍历,为了克服这个缺点,引入了双链表。
定义
typedef struct DNode {
ElemType data;
struct DNode* prior, * next;
}DNode,*DLinkList;
双链表结点中有两个指针prior和next,分别指向前驱和后继结点

相对于单链表,双链表只增加了prior指针。因此在双链表按照值查找和按照位查找的操作相同(没有用到prior指针),但在插入和删除操作上有不同。
基本操作
1、按照值查找和按照位查找
/*
按序号查找结点值:
*/
DNode* GetElem(DLinkList L, int i) {
int j = 1; //计数
DNode* p = L->next;
if (i <= 0)
return NULL;
while (p && j < i) {
p = p->next;
j++;
}
return p;
}
/*
按照值来查找
*/
DNode* LocateElem(DLinkList L, ElemType e) {
DNode* p = L->next;
while (p != NULL && p->data != e)
{
p = p->next;
}
return p;
}
2、双链表的插入操作
在双链表中p所指的结点之后插入结点s
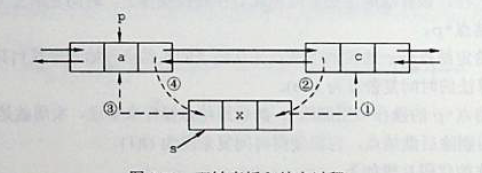
bool Insert(DLinkList &L, ElemType e, int i) {
DNode* p = GetElem(L, i - 1);
if (p != NULL)
{
DNode* s = (DNode*)malloc(sizeof(DNode));
s->data = e;
s->next = p->next; //s后继指向p的后继
p->next->prior = s; //p的后继的前驱是s
p->next = s; //p的后继修改为s
s->prior = p; //s的前驱是p
return true;
}
else
{
return false;
}
}
是在p后面插入,p的后继我们还不知道,所以要把p的后继指针修改好
3、删除操作
删除第i个结点
/*删除操作
*/
bool Delete(DLinkList& L, int i) {
DNode* p = GetElem(L, i);
if (p != NULL) {
p->next->prior = p->prior;
p->prior->next = p->next;
free(p);
return true;
}
else
{
return false;
}
}
删除第i个结点p,将p结点的后继的前驱改为p的前驱,p的前驱的后继改为p的后继,在free就可以了
总结
- 双链表有两个指针,一个指向后继,一个指向前驱
- 单链表访问后继结点的时间复杂度为0(1),访问前驱为0(n),而双链表都是0(1)
- 双链表是牺牲内存来减小时间
- 双链表和单链表的区别就在于双链表有一个前驱指针,其他都一样
