快速排序的三种实现
快速排序是对冒泡排序的一种改进,使用了分治的思想。
基本思想:
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归 进行,以此达到整个数据变成有序序列。
算法描述:
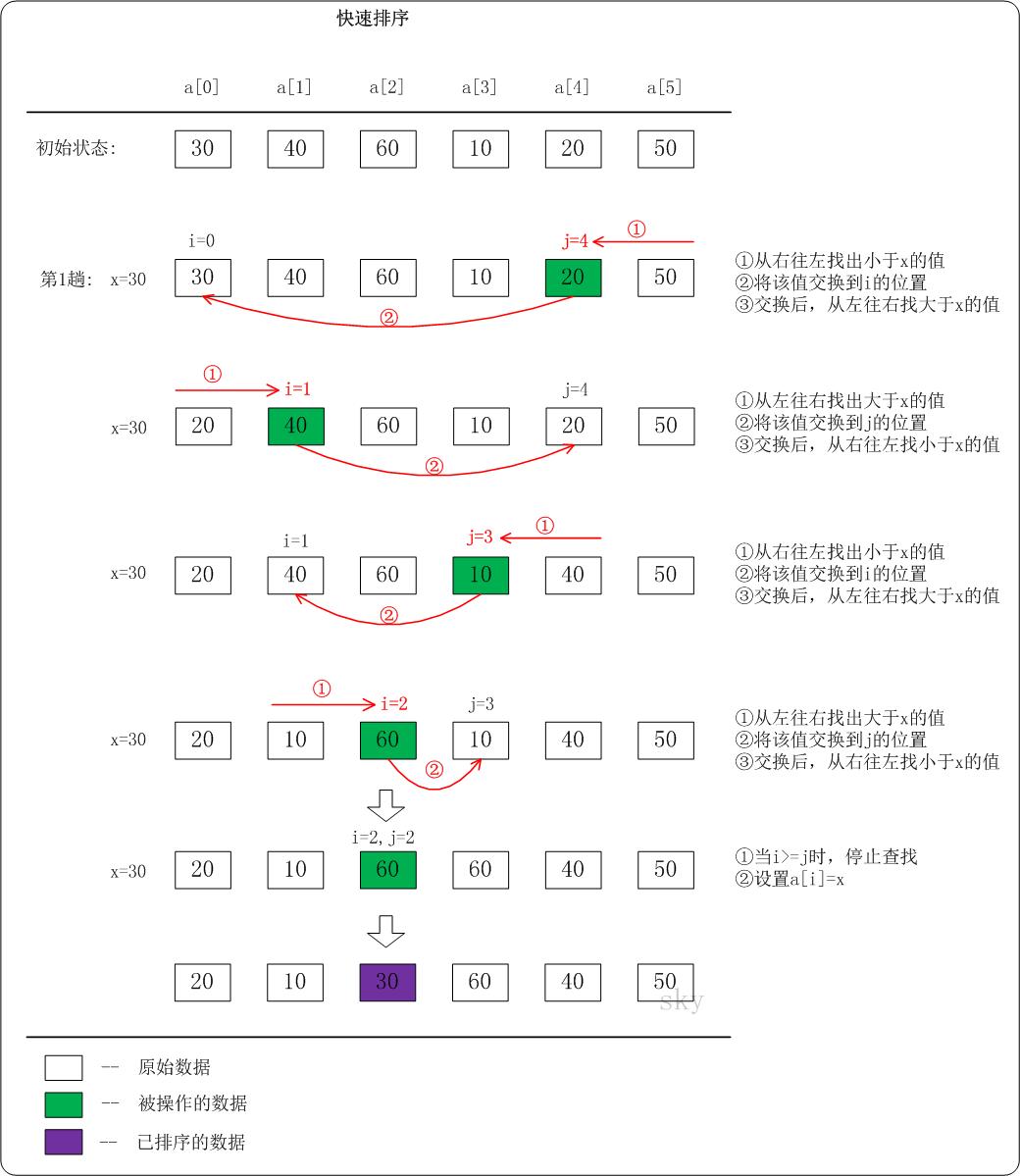
- 从数列中挑出一个元素,称为"基准"(pivot)。
- 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 递归地(recursively)把小于基准值元素的子数列和大于基准值元素的子数列排序。
选择基准的方式:
- 固定位置(一般取待排序列第一个元素或者最后一个元素)
- 随机选取基准(随机抽取待排序列中任意一个元素为基准)
- 三数取中(取待排序列首、中、尾三个元素的中位数为基准)
选取基准有以上三种方式,每种方式代表一种快速排序的实现
第一种实现:选取待排序列首元素为基准
代码实现:
//找基准,返回第一趟排序后的基准(low)的位置
public static int partion(int[] array,int low,int high){
int tmp=array[low];
//hign向前走找比tmp小的值
while(low<high){
while(low<high&&array[high]>=tmp){
high--;
}
if(low>=high){
array[low] = tmp;
break;
}else{
array[low] = array[high];
}
//low向后走找比tmp大的值
while(low<high&&array[low]<=tmp){
low++;
}
if(low>=high){ //low与high相遇,即没有比tmp大的值了,此时需把基准放在相遇的位置
array[low] = tmp;
break;
}else{
array[high] = array[low];
}
}
return low;//此时low和high相遇,返回第一趟排序后的基准(low)的位置
}
public static void quick(int[] array,int start,int end) {
int par = partion(array,start,end); //找基准
//递归左边
if(par>start+1){ //至少保证有两个数据
quick(array,start,par-1);
}
//递归右边
if(par<end-1){
quick(array,par+1,end);
}
}
public static void quickSort1( int[] array){
quick(array,0, array.length-1);
}第二种实现:随机选取待排序列中任意元素为基准
首先,分析选取固定位置为基准的方式,当待排序列为有序时,使用递归实现,数据量特别大时,会出现栈溢出的情况
因为当待排序列有序时(假设待排序列为1,2,3,4,5,6,7),每次的基准就是1,2,3…,当基准为1时,high从后向前找比基准小的元素,需要遍历完整个序列,没有找到(如果找到了,把找到的数放在low的位置),然后low从前向后找比基准大的元素,找到2,把2放在high的位置,以此类推,此时快速排序就相当于是冒泡排序。
再来分析一下随机选取的基准的方式,此种方式在待排序列元素全部相等的情况下,算法时间复杂度仍为O(N^2),因此,这种选取基准的方式也不是最好的。
第三种实现:取待排序列首、中、尾三个元素的中位数为基准
采用三数取中选取基准实现快速排序时,只需要把在每次递归调用基准之前,调用三数取中方法(medianOfThree),交换三个数的位置,把中位数放在待排序列第一个位置,即low得位置即可。
public static void swap(int[] array,int low,int high){
int tmp = array[low];
array[low] = array[high];
array[high] = tmp;
}
public static void medianOfThree(int[] array,int low,int high){
int mid=(low+high)/2;
//low mid high 3个数取中位数,
//交换三数位置,确保low位置存放的数是中位数
if(array[mid]>array[low]){
swap(array,mid,low);
} //确定array[mid]<array[low]
if(array[low]>array[high]){
swap(array,low,high);
} //确定array[low]<array[high]
}
public static void quick(int[] array,int start,int end) {
//找基准之前三数取中,把中位数放在low的位置
medianOfThree(array,start,end);
int par = partion(array,start,end); //找基准
//递归左边
if(par>start+1){ //至少保证有两个数据
quick(array,start,par-1);
}
//递归右边
if(par<end-1){
quick(array,par+1,end);
}
}
public static void quickSort1( int[] array){
quick(array,0, array.length-1);
}快速排序的非递归实现
一般情况下,将递归实现转化为非递归实现,需要借助栈
这里使用的思想就是:每趟快速排序之后,如果子序列包含两个元素以上,就把low和par-1以及par+1和high压入栈,一趟快速排序之后,就取出子序列区间,继续进行下一趟快速排序,直到栈为空,说明快速排序完成,待排序列有序。
public static void quickSort(int[] array) {
Stack<Integer> stack = new Stack<>();
int low = 0;
int high = array.length-1;
int par = partion(array,low,high);//一趟快速排序
if(par > low+1){ //左边有两个以上的数据
stack.push(low);
stack.push(par-1);
}
if(par < high-1) {//右边有两个以上的数据
stack.push(par+1);
stack.push(high);
}
while(!stack.empty()){
high = stack.pop();
low = stack.pop();
//取出子序列区间,继续进行快速排序
par = partion(array,low,high);
if(par > low+1){
stack.push(low);
stack.push(par-1);
}
if(par < high-1) {
stack.push(par+1);
stack.push(high);
}
}
}快速排序的两种优化
第一种优化方式:当待排序列分割到一定长度后,使用直接插入排序
当子序列长度小到一定范围时,假设end和start之间有16个元素(待排序列总长度为1000000),此时的子序列已经基本有序,可以使用直接插入排序,该排序算法的特点就是越有序越快
那么,如何修改代码呢?
方法很简单,只需要在每次递归找基准之前,判断子序列长度是小于16即可,如果小于,就使用直接插入排序算法
public static void quick(int[] array,int start,int end) {
//找基准之前三数取中,把中位数放在low的位置
if(end-start+1<=16){
insertSort2(array,start,end);
}
medianOfThree(array,start,end);
int par = partion(array,start,end); //找基准
//递归左边
if(par>start+1){ //至少保证有两个数据
quick(array,start,par-1);
}
//递归右边
if(par<end-1){
quick(array,par+1,end);
}
}第二种优化方式:在一次分割结束后,可以把与Key相等的元素聚在一起,继续下次分割时,不用再对与key相等元素分割
举例:
待排序序列 1 4 6 7 6 6 7 6 8 6
三数取中选取枢轴:下标为4的数6
转换后,待分割序列:6 4 6 7 1 6 7 6 8 6 枢轴key:6
本次划分后,未对与key元素相等处理的结果:1 4 6 6 7 6 7 6 8 6
下次的两个子序列为:1 4 6 和 7 6 7 6 8 6
本次划分后,对与key元素相等处理的结果:1 4 6 6 6 6 6 7 8 7
下次的两个子序列为:1 4 和 7 8 7
经过对比,我们可以看出,在一次划分后,把与key相等的元素聚在一起,能减少迭代次数,效率会提高不少
算法效率
| 平均时间复杂度 | 最好时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 稳定性 |
| O(nlogn) | O(nlogn) | O(N^2) | O(logn)~ O(n) | 不稳定 |
最好时间复杂度:当每次划分时,算法若都能分成两个等长的子序列时,分治算法效率达到最大
最坏时间复杂度:待排序列有序时,相当于冒泡排序,递归实现会出现栈溢出的现象,时间复杂度为O(N^2)
最好空间复杂度:每次都把待排序列分为相等的两部分,2^x=n (分割x次,保存x个par) ,x = logn
最坏空间复杂度:1 2 3 4 5 6 7 N个数据就保存N个par
