1.练习shell中的命令历史、别名、特殊字符用法
命令历史:
使用history命令显示命令历史表中的命令。
(1)history后不带任何参数,会显示历史命令清单(包含刚刚输入的history命令)
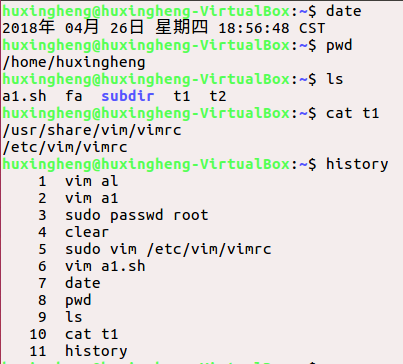
(2)如果history后面给出一个正整数,例如:history 3,只显示最后的3行。

(3)如果history后给出一个文件,例如:history t1,则把a1作为历史文件名
命令使用失败.....
历史命令调用:
!!:重复上一条命令
!n:重新执行第n条历史命令
!-n:重新执行倒数第n条历史命令。如!-1就等于!!
!string:重新执行以字符串string开头的最近的历史命令行。例如,!ca表示访问前面最近的cat命令
!?string?:重新执行最近的、其中包含字符串string的那条历史命令。例如,!?hist?表示重复前面的含有hist的命令
!#:到现在为止所输入的整个命令行
例如:!7 先显示序号为7的命令,然后执行此命令。

别名:
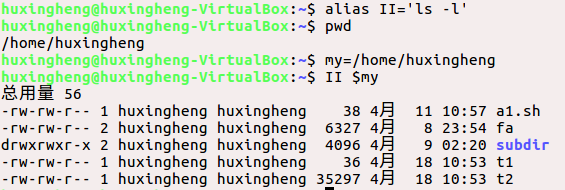
定义别名:alias [name[=value]]
取消别名:unalias name
例如:

特殊字符用法:
一般通配符:* ?[ ] ! ^
示例如下:

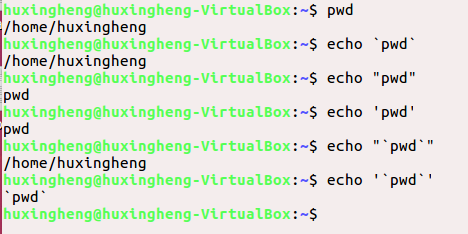
引号:
倒引号:调用倒引号内的命令
单引号:显示单引号内的内容
双引号:显示双引号内的内容
单引号内包含倒引号:原封不动的显示
双引号内包含倒引号:调用倒引号内的命令
2.shell命令应用练习
(1)通过帮助信息查看,简述以下文件的用途:
/etc/passwd 是用户账户信息文件,包含使用冒号(:)分隔的七个字段

/etc/shadow 是可选的加密后的密码文件,包含系统账户的密码信息和可选的年龄信息,此文件包含9个字段,用半角冒号分隔,如果没有为好好密码安全,此文件绝对不能让普通用户可读

/etc/group 文件保存了系统中所有组的名称,以及每个组中的成员列表。文件中每一行表示一个组,由三个冒号分隔开的字段组成。

/etc/gshadow 文件包含影子化了的组账户信息

(2)依次输入如下命令,观察运行结果。结合man id查看到的帮助信息,指出每一条命令功能。
id :打印用户组、UID以及该用户所属的所有组
id -u :打印有效的用户id
id -u root :打印拥有root权限的用户id
id -u huxingheng :打印用户名为huxingheng的用户id

(3)在shell命令终端依次输入以下命令,观察执行结果,理解每条命令实现的具体功能。
<1>
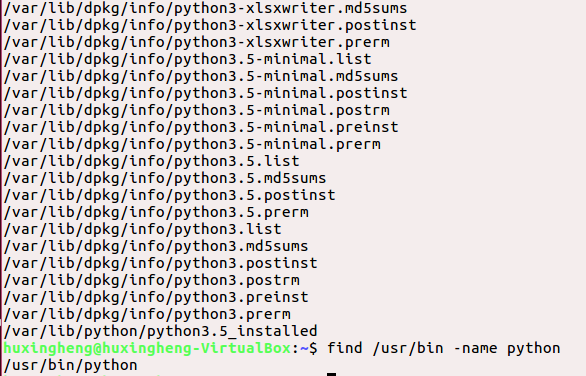
which python :在path变量指定的路径中搜索python命令的位置,并返回第一个搜索结果。
whereis python:whereis命令用于程序名搜索,且只能搜索二进制文件、man说明文件、源代码文件。如果省略参数,则返回所有信息。
locate python:locate命令可以在搜索数据库时快速找到档案,它的功能和find类似,但find是通过硬盘查找,速度慢且浪费资源,而locate则是通过数据库查找索引,速度较快。
find /usr/bin -name python:通过硬盘查找方式在/usr/bin文件夹下搜索python

<2>
sudo apt install gimp:
首先,解释下什么是gimp。gimp是GNU图像处理程序(GNU Image Manipulation Program)的缩写,号称是linux下的Photoshop。
此命令是用来安装gimp程序的
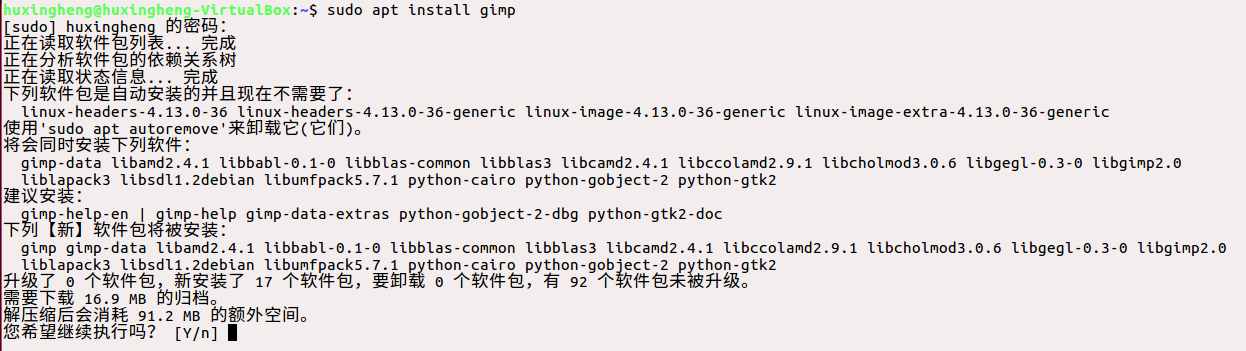
which gimp:显示gimp所在目录

sudo apt remove gimp:卸载gimp程序

which gimp:显示gimp所在目录(已删除,所以显示为空)

<4>
对比总结:通过下面的截图对比可以看出,真的不一样了!好吧,我没看明白,但确实不一样了,好像是后面的内容被剪掉了,数了下,貌似是以空格为界定,然后8个。。。猜测猜测,纯属猜测。
补:明白了,自定义分隔符为空格 (d与f联用)指定显示第1个和第8个区域。
ls -dl /root --time-style=long-iso (说实话,我没搞懂它的用处)

ls -dl /root --time-style=long-iso|cut -d' ' -f1,8

<5>
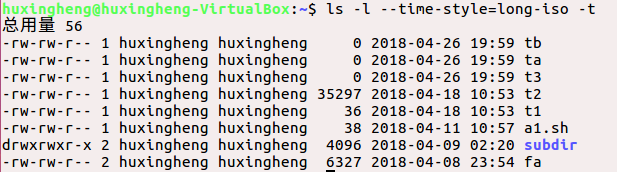
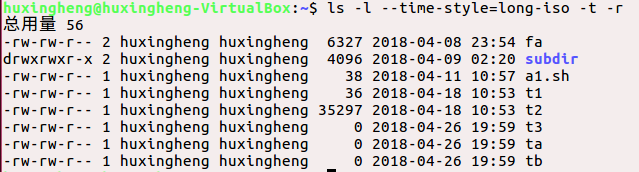
对比总结:很明显,第二条命令在查看时对文件按时间排了序(时间从后往前),第三条命令在查看时同样对文件按时间排了序,只是它的顺序是从前往后。
ls -l --time-style=long-iso

ls -l --time-style=long-iso -t
ls -l --time-style=long-iso -t -r
<6>
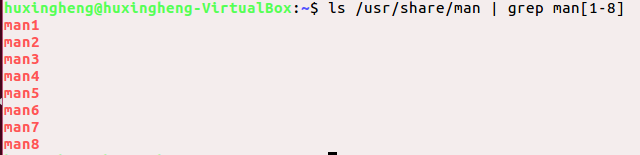
ls /usr/share/man
查看/usr/share/man目录下的文件和文件夹

ls /usr/share/man | grep man[1-8]
功能:在/usr/share/man 目录下查找与字串“man1”、“man2”......“man8”匹配的文件或文件夹
ls /usr/share/man/man1
功能:查看/usr/share/man/man1目录下的文件或文件夹
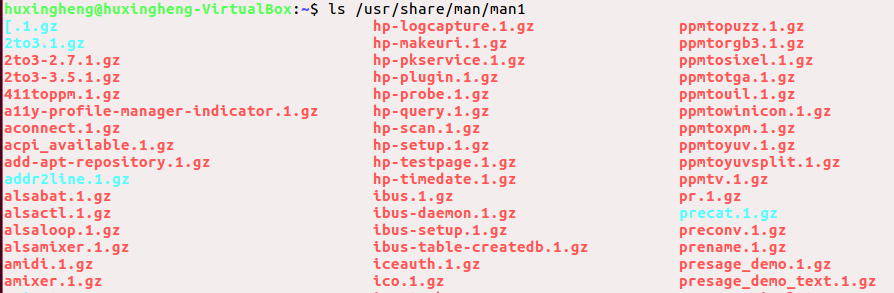
file /usr/share/man/man1/ls.1.gz
功能:ls.1.gz展现文件的详细类型信息

mkdir ~/temp; cp /usr/share/man/man1/ls.1.gz ~/temp
功能:从 /usr/share/man/man1目录下复制文件 ls.1.gz 到新创建的文件夹 temp 中


sudo gzip -d ls.1.gz; ls
功能:安装 ls.1.gz

<7>
ls -l /home | grep "^d" | wc -l
功能:查看/home目录,匹配出开头是d的....然后统计数目并显示在屏幕上。
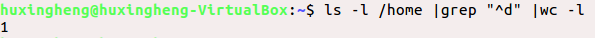
<8>
sudo adduser user7
功能:添加新用户

ls /home | tee users | wc -l
功能:在/home目录下查看并统计用户的数目,并将用户数显示到屏幕上。

(4)根据要求写出相应的shell命令。
在目录 /usr/include 目录下搜索文件signal.h是否存在


在/usr/include目录下的所有文件中查找包含BUFSIZ的行,并显示所在行号。(要求过滤掉错误信息)

在用户名密码文件/etc/passwd中查找登录shell为bash的用户信息记录,并显示行号。

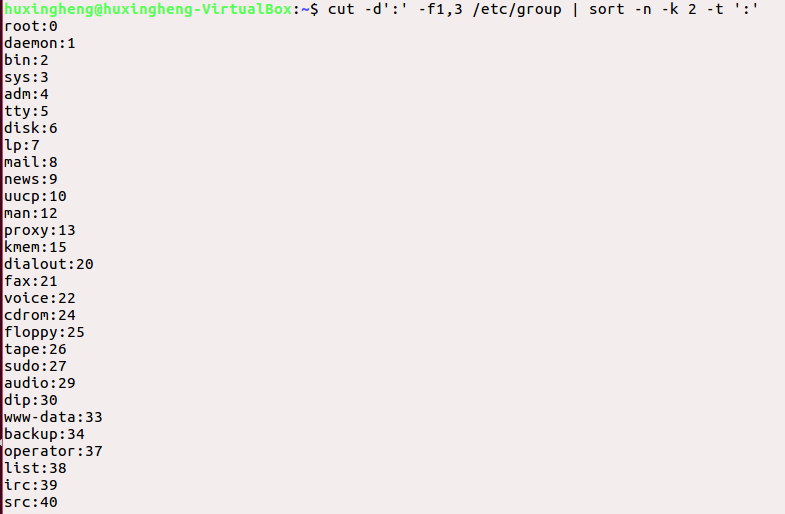
从/etc/group文件中截取第一列和第三列,并按照组id的数值大小从小到大排列
由于/etc/group文件是以冒号为分隔符,so......看图!
体验awk,sed的用法:依次执行命令,观察执行结果。
cp /etc/apt/sources.list t1; less t1


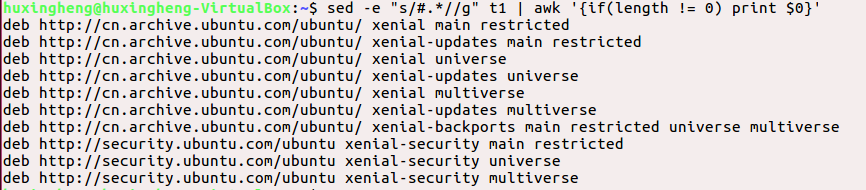
sed -e "s/#.*//g" t1

sed -e "s/#.*//g" t1 | awk '{if(length != 0) print $0}'
tail -5 /etc/passwd | awk -F: '{print $1}'

tail -5 /etc/group | tee t2

awk 'BEGIN {print "file t2"} {print "line" NR ":" $0} END {print "over"}' t2

总结:
sources.list:linux中的源配置文件,存放的是ubuntu软件更新的源服务器地址,该文件可编辑。
sed:号称在线编辑器,一次只处理一行的内容,处理时,将当前处理的行存储在临时缓冲区,接着用sed命令处理缓冲区的内容,处理完成后,把缓冲区的内容送往屏幕,接着处理下一行,不断重复,直至处理到文末。文件内容并未改变,除非用了重定向。
awk:awk是一种强大的文本分析工具,它在对数据分析并生成报告时显得尤为强大,简单说,awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
查阅网络和帮助,体验命令curl和wget方法。
curl:听说是很强大的http命令行工具。
wget:传说是下载文件的工具,都linux用户必不可少。
(注:emmm,好吧,其实这里我不太会,连sed、awk、curl、wget是什么都不清楚,印象中好像老师有提到过,但很模糊,所以它们的用法.....后期再完善吧,太困了,睡觉了。)
编写一个shell脚本,使用四种方式分别执行。
练习(1)
使用vim编辑器编写一个脚本ex1.sh,步骤请看截图:

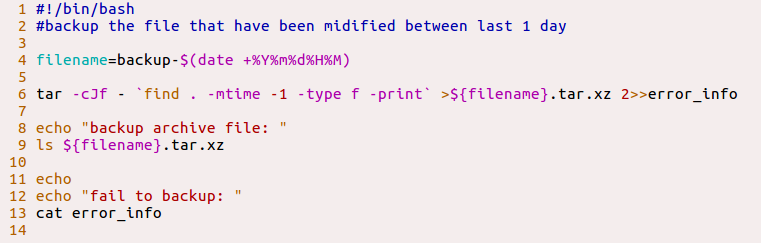
执行该脚本:

该脚本实现的功能是:备份当前目录下最近1天以内被修改过的普通文件以backup系统当前日期时间为文件名,并压缩存档。备份过程中错误信息写入error_info,然后分别查看备份文档和报错信息。尝试着执行了一下,第一种和第四种方式成功执行,第二种方式没有看明白什么意思,第三种方式执行失败了。
练习(2)
用vim编辑器编写脚本ex2.sh,步骤请看截图:


执行该脚本:

这次实验做的好烂噢!一脸蒙圈.....
line 3 中 read 命令选项-n11 功能:
使用-n选项可以设置read命令记录指定个数的输入字符,当输入字符达到指定数目时,自动退出,并将输入的数据赋值给变量。
在此题中,-n11的功能是指读入的数据指定为11个字符,超过11个字符将自动退出。
line 14 的功能:
在文件名与变量filename中存放内容相同的文件中查找与变量code中存放的字串匹配的行,并存到t1中,然后从t1中读取信息,放到变量major中。
总结:这次实验的内容好“丰富”噢,做了好长好长时间啊,主要是有好多东西都不会,全程在百度命令的用法,去查书或查ppt的话感觉效率有点低,要翻老半天才能找到那条命令在哪,估计是我书翻的少了,对内容太不熟悉了。然后上次实验提了一下关于上课的反馈,居然被老师翻牌了,受宠若惊!随后老师就改变了上课方式,新的方式感觉很好,先听懂了再自己去敲命令要比跟着老师一起敲要好的多,起码不会显得手忙脚乱,对命令理解的也要好的多。emmm,暂时就这样吧,先睡觉了。
——END——