1. 练习 shell 中命令历史、别名、特殊字符用法(第 4 章 4.2 节~4.5 节)
(1)定义别名
定义别名是,往往用单引号将它所代表的内容括起来,以防止shell对其中的内容产生歧义,如对空格和特殊字符另作解释。

(2)特殊字符用法
1.一般通配符
*(星号):匹配任意字符的0次或多次(文件名中的圆点和路径名中的斜线必须显示匹配)
?(问号):匹配任意一个字符
[字符组]:匹配该字符组所限定的任何一个字符
!(惊叹号):如果它紧跟在一对方括号的左方括号[之后,表示不在此字符组的所列出的字符

2.模式表达式(各模式之间以 | 隔开)
*(模式表):匹配给定模式表中0次或多次出现的模式
+(模式表):匹配给定模式中1次或多次出现的模式
?(模式表):匹配模式表中任何一种0次或1次出现的模式
@(模式表):匹配模式表中给定一次出现的模式
!(模式表):出给定模式表中的一个模式外,它可以匹配其他任何东西
3.引号
双引号:由双引号括起来的字符除了$,倒引号(`)和反斜线(\)外都最为普通字符处理

单引号:括起来的字符都做为普通字符

倒引号:括起来的字符串被shell解释为命令行

注意:嵌套倒引号时内层需要使用反斜线\转义 形如 ` \` \` `
2. shell 命令应用练习
(1)通过帮助信息查看,简述以下文件的用途
1 /etc/passwd 密码文件

2 /etc/shadow 影子化的密码文件


3 /etc/group 定义系统中所有组包括名称,密码,组ID,用户列表
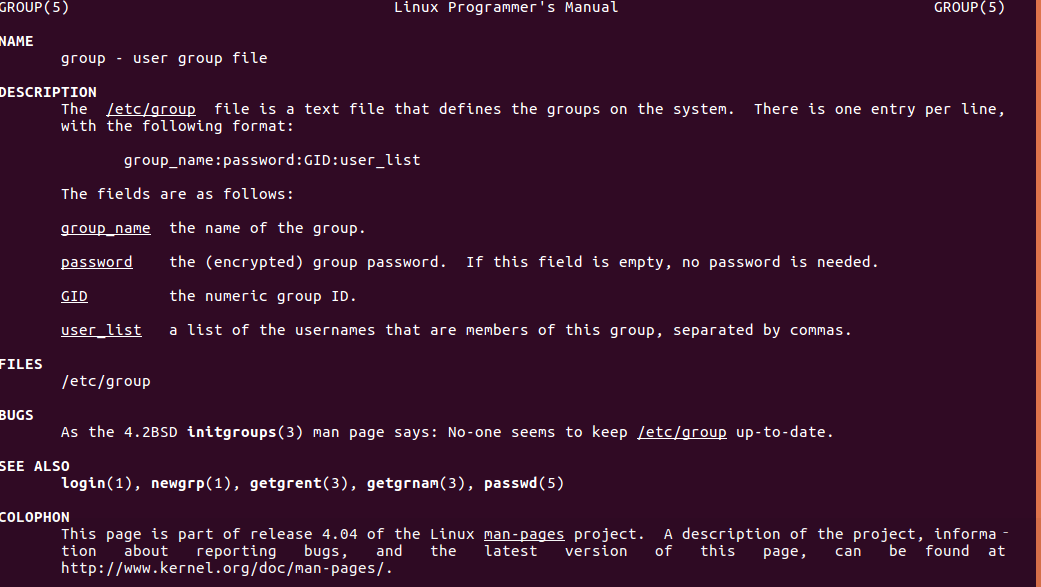
4 /etc/gshadow 影子化的组文件
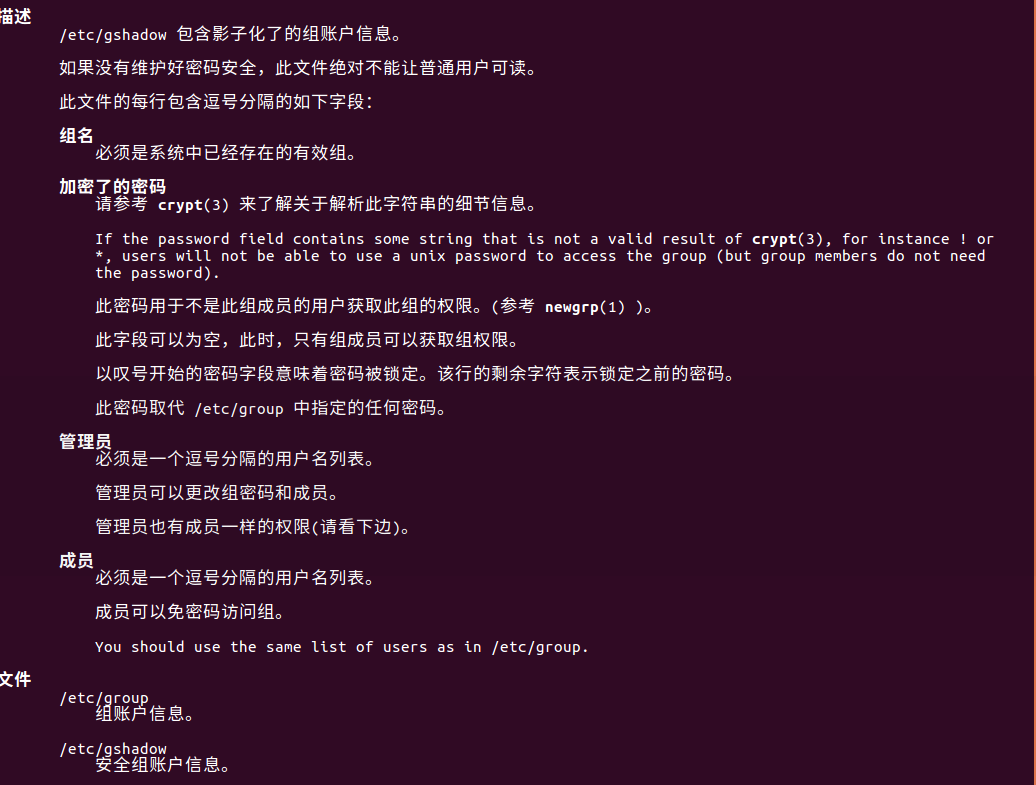
(2)依次输入如下命令,观察运行结果。结合 man id 查看到的帮助信息,指出每一条命令功能
1 id 用户组、UID以及该用户所属的所有组
2 id -u 有效的用户id
3 id -u root 有root权限的用户id
4 id -u beimingfeng 用户名为北冥风的用户id

(3)在 shell 命令终端依次输入以下命令,观察执行结果,理解每条命令实现的具体功能
1.
which python :which是通过 PATH环境变量到该路径内查找可执行文件,所以基本的功能是寻找可执行文件
whereis python:whereis命令用于程序名搜索,且只能搜索二进制文件、man说明文件、源代码文件。如果省略参数,则返回所有信息。
locate python:locate命令可以在搜索数据库时快速找到档案,速度较快,但是数据库可能没更新,搜索到已经删除的信息。
find /usr/bin -name python:根据条件筛选,通过硬盘查找方式在/usr/bin文件夹下搜索python,速度较慢
2.grep命令 是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来
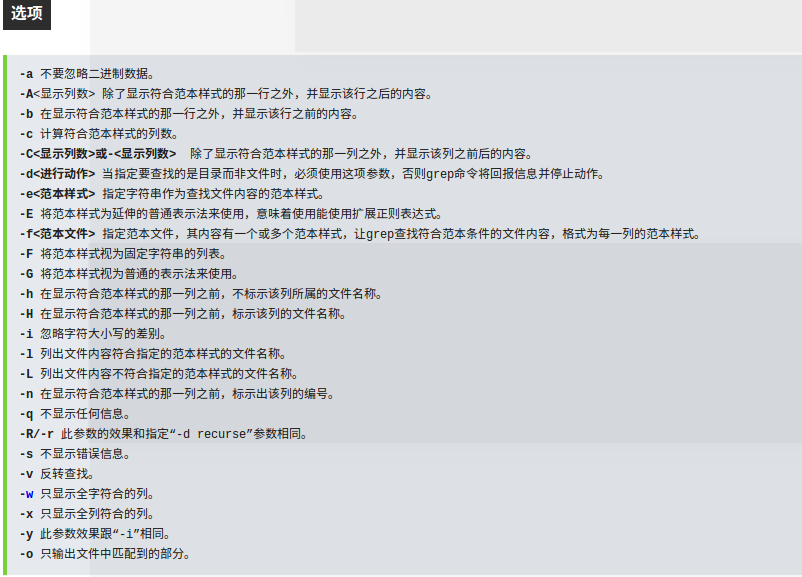
四条命令分别是:
在/ect/passwd下查询含有root,beimingfeng,^user后任意长度字符三种情况的匹配行
在/ect/passwd下查询含有任意长度数字的匹配行
在/ect/passwd下查询含有任意长度字母的匹配行
在/ect/passwd下查询含有0-9数字的长度大于4的字符串的匹配行
3
sudo apt install gimp:安装girp
which gimp:显示gimp所在目录 在usr/bin下
sudo apt remove gimp:卸载gimp
which gimp:显示gimp所在目录 此时已无
4
ls -dl /root --time-style=long-iso
ls -dl /root --time-style=long-iso | cut -d' ' -f1,8

cut用来截取信息,上面的信息可以看作共有8个域,题中取了1和8域
5
ls -l --time-style=long-iso
ls -l --time-style=long-iso -t 时间新的在前
ls -l --time-style=long-iso -t -r 先按时间新排序,然后反序排列
进行了排序 -t:用文件和目录的更改时间排序 -r:以文件名反序排列并输出目录内容列表;

6
ls /usr/share/man 查询/usr/share/man/目录下的文件和文件夹
ls /usr/share/man | grep man[1-8] 在/usr/share/man/目录下搜寻以man开头的后跟1-8中任意一个数字的文件或文件夹
ls /usr/share/man/man1 查看/usr/share/man/man1目录下的文件或文件夹
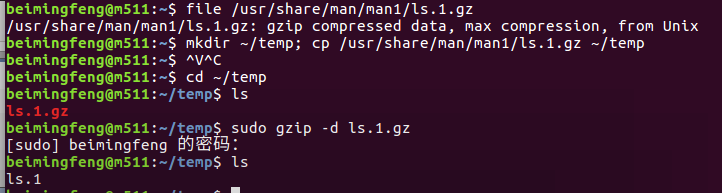
其中:file /usr/share/man/man1/ls.1.gz ls.1.gz文件的详细类型信息
mkdir ~/temp; cp /usr/share/man/man1/ls.1.gz ~/temp 从 /usr/share/man/man1目录下复制文件 ls.1.gz 到新创建的文件夹 temp 中
cd ~/temp; ls
sudo gzip -d ls.1.gz; ls 解压文件ls.1.gz
7
ls –l /home | grep "^d" | wc –l 查看/home目录,匹配出开头是d的文件,然后统计数目。

不知道为啥有这种情况
8
sudo adduser user7 添加一个用户名为user7的用户,自行设置密码和一些基础信息
ls /home | tee users | wc -l 在/home目录下查看然后统计用户的数目

(4)根据要求写出相应的 shell 命令
1 在目录/usr/include 下搜索文件 signal.h 是否存在 (提示: find 命令)
find /usr/include -name signal.h

2 在/usr/include 目录下的所有文件中查找包含 BUFSIZ 的行,并显示所在行号。
要求:屏幕上只显示查找到的结果,过滤错误信息。
grep -n -E "*BUFSIZ*" /usr/include/* 2> /dev/null
3 在用户名密码文件/etc/passwd 中查找登录 shell 为 bash 的用户信息记录,并显示行号(提示:使用 grep 和正则表达式中的$)

在不同位置加入$,结果并没有变化
4 从/etc/group 文件中截取第 1 列(组名)和第 3 列(组 id),并按照组 id 号的数值大小由小到大排序
cat /etc/passwd|cut -d':' -f1,3 | sort -n -k 2 -t ':'

5)体验 awk, sed 用法:依次执行命令,观察执行结果
1 cp /etc/apt/sources.list t1; less t1 将sources.list复制给t1,并分屏显示t1的内容


2 sed -e "s/#.*//g" t1

3 sed -e "s/#.*//g" t1 | awk '{if (length != 0) print $0}'

4 tail -5 /etc/passwd | awk -F: '{print $1}'

5 tail -5 /etc/group | tee t2

awk 'BEGIN{print "file t2"} {print "line" NR ":" $0} END {print "over"}' t2

1./etc/apt/sources.list 是包管理工具 apt 所用的记录软件包仓库位置的配置文件,同样的还有位于 /etc/apt/sources.list.d/*.list 的各文件。
档案类型 (Archive type)
条目的第一个词 deb 或是 deb-src 表明了所获取的软件包档案类型。
其中,
- deb
- 档案类型为二进制预编译软件包,一般我们所用的档案类型。
- deb-src
- 档案类型为用于编译二进制软件包的源代码。
仓库地址 (Repository URL)
条目的第二个词则是软件包所在仓库的地址。我们可以更换仓库地址为其他地理位置更靠近自己的镜像来提高下载速度。
常用镜像地址列表:
发行版 (Distribution)
跟在仓库地址后的是发行版。发行版有两种分类方法,一类是发行版的具体代号,如 xenial,trusty, precise 等;还有一类则是发行版的发行类型,如oldstable, stable, testing 和 unstable。
另外,在发行版后还可能有进一步的指定,如 xenial-updates, trusty-security, stable-backports 等。
软件包分类 (Component)
跟在发行版之后的就是软件包的具体分类了,可以有一个或多个。
2.sed是一种流编辑器,它是文本处理中非常中的工具,能够完美的配合正则表达式使用,功能不同凡响。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有 改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
3.awk是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。awk有很多内建的功能,比如数组、函数等,这是它和C语言的相同之处,灵活性是awk最大的优势。
sed练习:
1 打印t1文件的奇数行
2 将yellow加入到apple开头的行的下一行

awk练习:
1.打印这个字符串的倒数第二个字段
2.打印文件t1的每一行第二个和第三个字段

(6)查阅网络或帮助,体验命令 curl 和 wget 用法。
curl:curl命令是一个利用URL规则在命令行下工作的文件传输工具。它支持文件的上传和下载,所以是综合传输工具,但按传统,习惯称curl为下载工具。作为一款强力工具,curl支持包括HTTP、HTTPS、ftp等众多协议,还支持POST、cookies、认证、从指定偏移处下载部分文件、用户代理字符串、限速、文件大小、进度条等特征。做网页处理流程和数据检索自动化,curl可以祝一臂之力。
curl练习:
下载单个文件,默认将输出打印到标准输出中(STDOUT)中

wget:wget命令用来从指定的URL下载文件。wget非常稳定,它在带宽很窄的情况下和不稳定网络中有很强的适应性,如果是由于网络的原因下载失败,wget会不断的尝试,直到整个文件下载完毕。如果是服务器打断下载过程,它会再次联到服务器上从停止的地方继续下载。这对从那些限定了链接时间的服务器上下载大文件非常有用。
wget练习:
使用wget下载单个文件

3. 编写一个 shell 脚本,使用 4 种方式(参见第 4 章教材/课件)分别执行。
(1)练习 1
第 1 步,使用 vi/vim/gedit 或其它编辑器,编写 shell 脚本 ex1.sh,内容如下:

该脚本的功能是,备份当前目录下最近 1 天以内(即 24 小时内)被修改过的普通文件。
以 backup 系统当前日期时间为文件名,并压缩存档。备份过程中出错信息写入 error_info。
然后分别查看备份文档和报错信息。
5次尝试(网上和书上的方法类型略微有一点不同):


这个权限不足不知道啥问题 试过把脚本放在/home下 4种方法全是权限不足(chmod了也不可以)。
(2)练习 2
第 1 步,使用 vi/vim/gedit 或其它编辑器,编写 shell 脚本 ex2.sh,内容如下:
第 4 章介绍的四种方式,运行该脚本。

1 部分方法提示权限不足
2 程序死机,不继续运行
4.实验总结
这次实验相比前两次所耗费的时间大大增加,做的也稍微认真一点了,还是学到了一点东西。一个晚上做还是太急了,有的东西就稍微看看就过去了。