mask-rcnn应用的任务是实例分割,和目标检测,语义分割有些许差别。目标检测的任务是在检测到的物体周围用框框起来,语义分割和实例分割都是描绘出检测物体的轮廓(边缘),但是实例分割比语义分割更进一步是为不同的物体标注不同的颜色和分类,而语义分割只描绘出轮廓,不进行物体的区分。
一、改进之处
mask-rcnn使用的主体框架与faster-rcnn相同,但是有几点改进:
1.使用ROIAlign替代了ROI Pooling
2.除了bbox和classification分支,多了一个mask分支
3.在特征提取网络中使用了FPN网络
下面针对以上三点分别进行详细介绍:
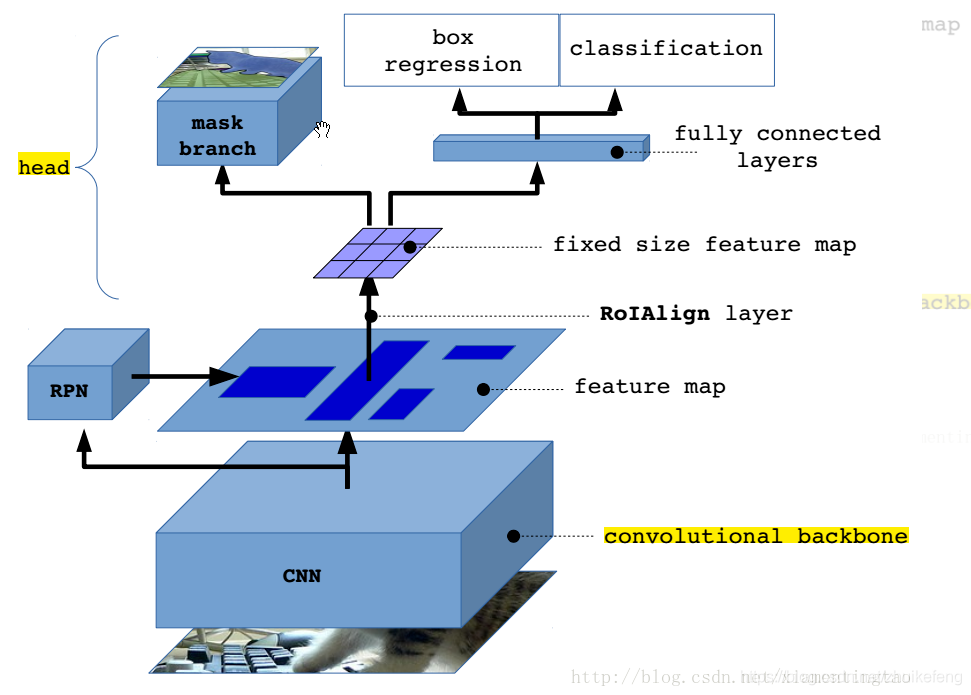
二、ROIAlign

ROI Pooling在映射proposals和feature map的位置,和feature map划分为7×7个bin的过程中,分别使用了两次量化(四舍五入)操作。进行这个操作是为了划分出来的顶点,强制与像素点的位置对应起来,这样后续进行maxpool的时候,可以参考顶点的像素值大小。但是这样操作带来的坏处就是,计算得到的框和实际框的位置不能完全一致,会稍有交错。这种交错对画框的影响不大,但是对描轮廓的影响很大。

ROIAlign的提出就是为了解决上述问题,它舍弃了ROI Pooling的两次量化操作,而是保留了实际计算得到的顶点坐标的值。在后续计算maxpool的过程中,使用双线性插值解决了这个问题。具体过程如下:

假设在特征图中需要划分出2×2个bin,最后需要得到2*2个maxpool之后的值。之前的做法是在每一个框中选择像素值最大的就好,但是因为ROIAlign的非量化操作,使得框中存在未完全包含的像素块。这时候可以使用双线性插值。

在一个方框中选取四个虚拟点,这四个点的位置是将该方框再划分成四个方框,各个方框的中心点。中心点值的大小是根据双线性插值法计算得到的值。然后取这四个点中的最大值,即得到最后的2×2个值。
三、mask分支
mask分支本质上是一个FCN(Fully Convolutional Network)网络。通常cnn网络在卷积之后会接上若干个全连接层,FCN采用反卷积层对最后一个卷积层得到的特征图(feature map)进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每一个像素都产生一个预测,同时保留了原始输入图像中的空间信息。所有的层都是卷积层,故称为全卷积网络。

所以mask分支的任务就是接收卷积得到的特征图,进行反卷积操作,最后得到proposal中的实例的轮廓,这个轮廓相当于是盖在原始proposal上的mask,在这个mask之内的值为1,不在这个mask之内的值为0。
四、FPN(Feature Pyramid Network)
特征金字塔网络是为了解决多尺度特征提取的问题。传统的特征提取网络如VGG,ResNet,往往只会使用最后的卷积层提取到的特征。但是因为卷积后的特征的长×宽是不断减小,深度是不断增大的。这就意味说,最后得到的网格中的一个网络,对应到初始图像中可能是很大一块,这种情况会使提取到的小尺度图像的特征信息在不断卷积和池化的过程中损失了。而FPN的提出就是要解决这个问题。它会将最深卷积层提取到的特征进行上采样至其上一层卷积层提取到特征的相同大小,然后加到上层卷积层提取到的特征图中,如此继续上采样,最终扩大到第一层卷积层提取特征的大小。如此利用了所有尺度提取到的特征信息,会使得网络在识别小物体的准确率有较大提高。

