原文地址在此:
https://www.cnblogs.com/aspwebchh/p/6652855.html
强力建议大家去看原文,原文说的通俗易懂。本着传播知识的目的,本文精简以及稍微添加了一些东西,若有冒犯之处,联系即删!!
问题:
-
为什么要给表加上主键?
-
为什么加索引后会使查询变快?
-
为什么加索引后会使写入、修改、删除变慢?
-
什么情况下要同时在两个字段上建索引?
聚集索引:
数据库索引大部分使用的是【平衡树】(B树或B+树)作为索引的结构。在平常是建表,我们都会为其加上主键。没有主键的表有些DBMS可能都不会让你创建。没有主键的表在磁盘上是以内容无序、存储连续的存储结构保存着,像真正的表一样,一行一行的。加上了主键的表,其结构变成了【平衡树】的结构,整个表就是一个索引,这就是【聚集索引】。这就是为什么主键只有一个的原因。 因为主键的作用就是把【表】的数据格式转换成【索引(平衡树)】的格式放置。
`
 其中所有结点(除去底部结点),都是由表的主键字段中的数据构成,即主键id。底部的结点是由每张表的数据记录组成,根据主键id,进行搜索。
其中所有结点(除去底部结点),都是由表的主键字段中的数据构成,即主键id。底部的结点是由每张表的数据记录组成,根据主键id,进行搜索。
假如执行如下SQL语句: select * from table where id = 12346;
运行流程如下:
首先根据所给table的主键id定位到该叶结点,然后在叶节点中根据id取到等于12346的数据行。
(大概是这么做的。以SQL Server 为例,SQL Server 以【页】作为IO操作的最小单位,页的大小为8k,也就是说,存取的时候会直接对一块或多块大小为8k区域进行操作。而页中存着表A的所有或部分数据行。每页的开头是一个96 B 的页头,用于存储有关页的系统信息,包括页码、页类型、页的可用空间,以及拥有该页的对象的分配单元ID。那么根据主键id找到属于表A的所有的页和区后,进行IO操作,进行扫描,有时候并行读取表,与id进行对比,至于是怎么比对,是顺序比对还是使用别的什么算法,我不太清楚,请明白的大佬告诉我下。然后找到所想要的数据行。更详细的SQL Server有关页的情况 请点击这里)
从上图中可以看出,该树有三层,只需进行三次查找就能找到叶节点。如下图:

假如现有一张存有一亿条记录的数据表,想要查找到自己希望的那条数据,
- 若没有索引,按照常规的顺序查找,在最坏的情况下,那就需要一亿次IO操作,用大O标记法就是O(n)最坏时间复杂度。这个效率是极其低下的,你可能要等上几个月的时间。用大O标记法就是O(n)最坏时间复杂度
- 加上索引,其存储的结构变为平衡树,假设这棵树有10层,那么只需要10次IO开销就能查找到所需要的数据, 速度以指数级别提升,用大O标记法就是O(log n),n是记录总树,底数是树的分叉数,结果就是树的层次数。换言之,查找次数是以树的分叉数为底,记录总数的对数,用公式来表示就是
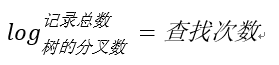
用程序来表示就是Math.Log(100000000,10),100000000是记录数,10是树的分叉数(真实环境下分叉数远不止10), 结果就是查找次数,这里的结果从亿降到了个位数。因此,利用索引会使数据库查询有惊人的性能提升,这就是为什么使用索引会加快检索速度的原因。
加上了索引,从顺序结构变为了树状结构,让其查询的速度变快,但让其写入的速度变慢。因为平衡树的结构必须实时维护,在每次数据改变时, DBMS必须去重新梳理树(索引)的结构以确保它的正确,这会带来不小的性能开销,也就是为什么索引会给查询以外的操作带来副作用的原因。
【点击这里查看平衡树结构的平衡原理】
非聚集索引
这也就是平常我们使用常规索引。它和聚集索引的结构一样,采用平衡树做为索引的结构。索引中的各结点的值来自表中的索引字段。假如给user表的name字段加上索引 , 那么索引就是由name字段中的值构成,如果给表中多个字段加上索引 , 那么就会出现多个独立的索引结构,每个索引(非聚集索引)互相之间不存在关联。
| … | name | age | gender | … |
|---|---|---|---|---|
| … | Ali | 10 | male | … |
| … | Taob | 10 | female | … |
| … | Tianm | 10 | male | … |
假如有一表如上所示,则在name字段上加的索引,其索引结构就如同下图中索引一的结构。索引一中的叶结点的值是该name字段所在表的主键id。

更加详细的结构图如下:(请务必仔细看看这张图,和下面的图结合起来就可以理解非聚集索引查找的流程)

图片来源点击此处查看
每次给字段建一个新索引, 字段中的数据就会被复制一份出来, 用于生成索引。 因此, 给表添加索引,会增加表的体积, 占用磁盘存储空间。非聚集索引和聚集索引的区别在于, 通过聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据,如下图:

不管是用那种方式进行查找,最后都是通过主键利用聚集索引进行定位数据行。聚集索引(主键)是通往真实数据所在的唯一路径。

覆盖索引
这是一种不需要聚集索引就可查询数据的方式。这种非主流的方法 称之为「覆盖索引」查询, 也就是平时所说的复合索引或者多字段索引查询。 文章上面的内容已经指出, 当为字段建立索引以后, 字段中的内容会被同步到索引之中, 如果为一个索引指定两个字段, 那么这个两个字段的内容都会被同步至索引之中。
先看下面这个SQL语句
//建立索引
create index index_birthday on user_info(birthday);
//查询生日在1991年11月1日出生用户的用户名
select user_name from user_info where birthday = ‘1991-11-1’;
其运行流程如下:
首先通过非聚集索引 【index_birthday】 查找 birthday = ‘1991-11-1’ 的所有记录的主键id值,然后根据得到的主键id值进行聚集索引查找,找到主键id对应的真实数据。再取出user_name字段的值即可。
把birthday字段上的索引改成双字段的覆盖索引
create index index_birthday_and_user_name on user_info(birthday, user_name);
这句SQL语句的执行过程就会变为:
通过非聚集索引index_birthday_and_user_name查找birthday等于1991-11-1的叶节点的内容,然而, 叶节点中除了有user_name表主键ID的值以外, user_name字段的值也在里面, 因此不需要通过主键ID值的查找数据行的真实所在, 直接取得叶节点中user_name的值返回即可。 通过这种覆盖索引直接查找的方式, 可以省略不使用覆盖索引查找的后面两个步骤, 大大的提高了查询性能,如下图:

数据库索引的内容就暂时到此为止了。
若读者有别的感兴趣的或者想知道的内容,请告诉我,我整理出来。
我只是小白,所以我愿意整理。
