什么是全表扫描?
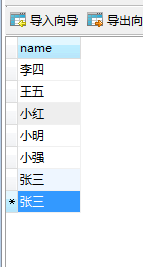
了解索引之前,我们先搞懂什么是全表扫描。假设在mysql数据库里有一个user表如下:

现在我们要从这个表中查找出所有名字是‘李四’的用户信息。我们使用下面的查询语句:
SELECT * FROM user WHERE name = '李四';
一旦我们运行这个查询,在查找名字为‘李四’的用户的过程中,究竟会发生什么?数据库不得不把user表中的每一行查一遍,并确定用户的名字(name)是否为 ‘李四’。由于我们想要得到每一个名字为‘李四’的用户信息,在查询到第一个符合条件的行后,不能停止查询,因为可能还有其他符合条件的行。所以,必须一行一行的查找直到最后一行,这就意味数据库不得不检查上千行数据才能找到名字为‘李四’的用户。这就是所谓的全表扫描。
什么是索引?
一个索引是存储着表中一个特定列的值的数据结构(最常见的是B-Tree)。索引在表的列上创建。所以,要记住的关键点是索引包含一个表中列的所有值,并且这些值存储在一个数据结构中。一定记住:索引是一种数据结构 。
索引是怎么提升性能的?
因为索引基本上是用来存储列值的数据结构,这使查找这些列值更加快速。如果索引使用最常用的数据结构-B-Tree-那么其中的数据是有序的。有序的列值可以极大的提升性能。下面解释原因。
在数据之外,数据库系统还维护着满足特定查找算法的数据结构。这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构就是索引
假设我们在 name这一列上创建一个B-Tree索引。这意味着当我们用之前的SQL查找姓名是‘李四’的用户时,不需要再扫描全表。而是用索引去查找名字为‘李四’的用户,因为索引已经按照按字母顺序排序。索引已经排序意味着查询一个名字会快很多,因为名字首字母为‘l’的用户都是排列在一起的。抽象出来的图如下:
另外重要的一点是,索引同时存储了表中相应行的指针以获取其他列的数据。
数据库索引里究竟存的是什么?
现在已经知道数据库索引是创建在表的某列上的,并且存储了这一列的所有值。但是,需要理解的重点是索引并不存储这个表中其他列(字段)的值。举例来说,如果我们在name列创建索引,那么列id,sex,address上的值并不会存储在这个索引当中。如果我们确实把其他所有字段也存储在个这个索引中,那就成了拷贝一整张表做为索引,这样会占用太大的空间而且会十分低效。
索引存储了指向表中某一行的指针
如果我们在索引里找到某一条记录作为索引的列的值,如何才能找到这一条记录的其它值呢?这是很简单 ,数据库索引同时存储了指向表中的相应行的指针。指针是指一块内存区域, 该内存区域记录的是对硬盘上记录的相应行的数据的引用。因此,索引中除了存储列的值,还存储着一个指向在行数据的索引。也就是说,索引中的name这列的某个值(或者节点)可以描述为 (“李四”, 0x82829), 0x82829 就是包含“李四”那行数据在硬盘上的地址。如果没有这个引用,你就只能访问到一个单独的值(“李四”),而这样没有意义,因为你不能获取这一行记录的user的其他值,例如(id),年龄(sex)和地址(address)。
数据库怎么知道什么时候使用索引?
当这个SQL (SELECT * FROM userWHERE name= ‘李四’ ;)运行时,数据库会检查在查询的列上是否有索引。假设name列上确实创建了索引,数据库会接着检查使用这个索引做查询是否合理,因为有些场景下,使用索引比起全表扫描会更加低效。