顺序表
按照顺序存储方式存储的线性表称为顺序表。
若顺序表中的元素按其值有序,则称其为有序顺序表。
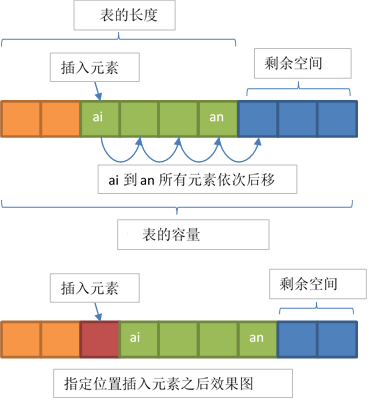
顺序表的插入
设顺序表 的长度为 ,将字段值为 的元素插入到第 个位置,插入步骤如下:
- 保证顺序表存储空间未满,并且插入位置合法
- 将第 个位置元素及其之后的所有元素后移一个位置
- 插入成功后,线性表长度变为
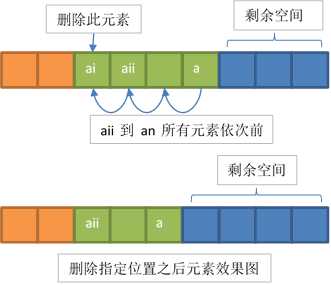
顺序表的删除
设顺序表 的长度为 ,删除第 个位置的元素,删除步骤如下:
-
保证删除位置合服性
-
将第 个位置之后的所有元素前移一个位置
-
删除成功后,线性表长度变为
顺序表总结
- 特点:存储地址连续,数据元素存储依次存放;数据元素类型相同,数据元素可随机存取
- 优点:存储空间的利用率高,存取速度快,适用于存取需求多的线性表
- 缺点:静态存储形式,数据元素的个数不能自由扩充 (受存储空间的限制);在插入、删除某个元素时,需要移动大量元素
单链表
结点只有一个指针域的链表成为单链表。
数据域 data 存放当前结点数据域的值,指针域 next 存放该结点的后继结点的地址信息。
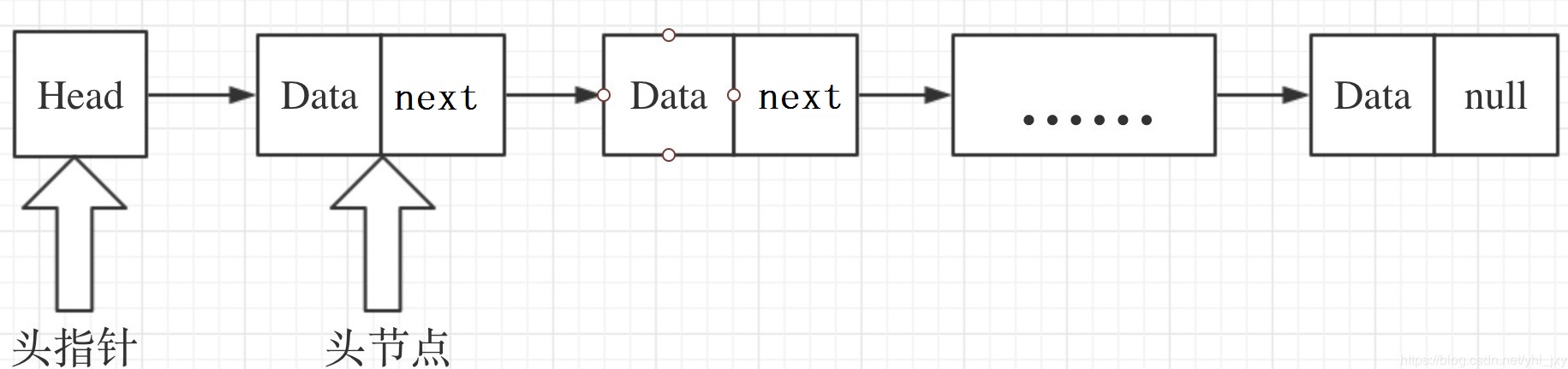
若表中只有头结点,则链表长度为 0,此时称其为空链表。
单链表的指针之间关系:
若
为指向单链表第
个结点的指针,则可以知道:
- 指向第 个结点
- 为 个结点的数据域
- 为 个结点的数据域
通过头指针进入单链表,根据每个结点的指针域可以循环遍历整个链表。
单链表中获取元素
获取单链表第 个数据步骤如下:
- 声明一个结点 指向单链表的第一个结点,初始化 从 1 开始;
- 当 时遍历链表,让 的指针向后移动,不断指向下一个结点, 累加 1;
- 若到单链表末尾 为空,则说明第 元素不存在;
- 否则查找成功,返回结点 的数据。
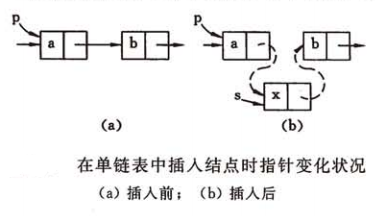
单链表的插入
将结点 插入到单链表中的指定位置,若指针 指向 插入位置的前一个结点,插入步骤如下:
- 将 结点的指针域指向 的后继结点:
- 将 指针域指向 结点:
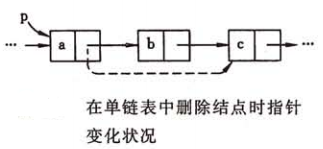
单链表的删除
删除单链表中的 结点,若指针 指向 结点的前一个结点,删除步骤如下:
- 将 的指针域指向 的后继结点:
- 释放结点
单链表的时间复杂度
- 单链表查询元素的最好时间复杂度为 ,最坏时间复杂度为 ,平均复杂度为 。
- 单链表的插入删除是先遍历链表,找到对应位置后进行插入和删除操作,整体的时间复杂度为 。
单链表和顺序表的比较
存储分配方式:
- 顺序表采用顺序存储方式,用一段连续的存储单元一次存储线性表中的数据元素
- 单链表采用链式存储方式,用一组任意的存储单元存放单链表中的元素
时间复杂度:
- 查找:顺序表的时间复杂度为 ;单链表的时间复杂度为 。
- 插入和删除:顺序表平均移动表长一半的元素,时间复杂度为 ;单链表在查找到某位置的指针后,插入和删除的时间复杂度为 。
空间性能:
- 线性表需要预先分配存储空间,若初始化时存储空间过大,容易造成浪费;若空间过小,容易引起数据的上溢。
- 单链表不需要预先分配存储空间,只要有空间就可以进行操作,单链表中的元素个数不受限制。
结论:
- 若线性表需要频繁查找,且插入删除操作较少,宜采用顺序表存储;
- 若线性表需要频繁进行插入和删除时,宜采用单链表存储。
- 当线性表中的元素个数变化较大或根本无法预知其变化时,宜采用单链表存储;
- 若能预知线性表的大致长度,宜采用顺序表存储。
应用实例
- 求单链表中有效结点个数
- 查找单链表中的倒数第 k 个结点
- 查找单链表中的倒数第 k 个结点,要求只能遍历一次链表
- 查找单链表的中间结点,要求只能遍历一次链表
- 单链表的逆序打印
- 逆置/反转单链表
- 单链表排序(冒泡排序&快速排序)
- 两个有序单链表进行合并,合并后依然有序
- 单链表实现约瑟夫环
循环链表
当单链表最后一个结点的指针域指向头结点时形成环状的链表称为循环链表。

当循环链表只包含一个头指针指向的头结点,其指针域存放指向自身的指针,称为空循环链表
循环链表与单链表的异同:
- 循环链表可以从任意位置访问任意结点;单链表只能访问任一结点之后的结点。
- 链表遍历的终止条件:结点的指针是否指向头指针;单链表遍历的终止条件:结点的指针是否为空。
- 循环链表可以获取前驱结点(遍历整个链表);单链表无法获取前驱结点。
- 循环链表的插入和删除与单链表类似。
应用实例
- 约瑟夫问题
- 设编号为 1,2,3,4…n 的 n 个人围坐一圈,约定编号为 k 的人从 1 开始报数,数到 m 的人出列,他的下一位又从 1 开始报数,数到 m 的人又出列,以此类推,直到所有人都出列,输出一个出列编号序列。
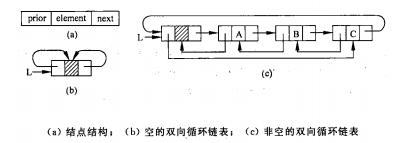
双向链表
结点由数据域(
)、左指针域(
)、右指针域(
)组成的链表称为双向链表。
左指针域和右指针域分别存放结点左右相邻结点的地址信息。

链表中的头结点的左指针和尾结点的右指针均为 。
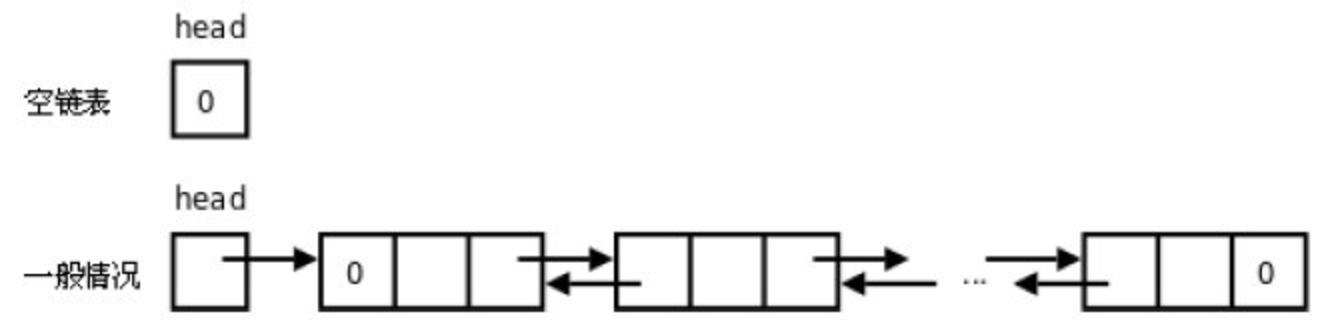
在双向链表的基础上,头结点的左指针指向链表的位结点,尾结点的右指针指向头结点,这样的链表称为双向循环链表。
双向链表的指针之间关系:
若
为指向第
个结点的指针,则可以知道:
- 指向第 个结点
- 指向第 个结点
通过头指针进入双向循环链表,每个结点可以便利的访问其前驱结点和后继结点。
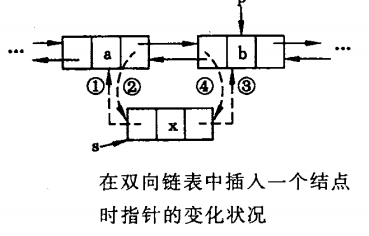
双向链表的插入
将结点 插入到双向循环链表的指定位置,若指针 指向 插入位置的后一个结点,插入步骤如下:
- 结点的左指针指向 的前驱结点:
- 结点的右指针指向 所在结点:
- 的前驱结点的右指针指向 结点:
- 的左指针指向 结点:
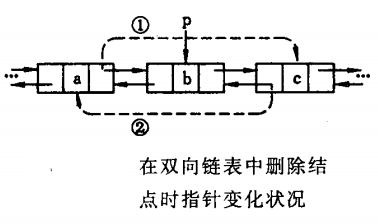
双向链表的删除
删除双向循环链表的结点 ,若指针 指向 结点,删除步骤如下:
- 的后继结点的左指针指向 的前驱结点:
- 的前驱结点的右指针指向 的后继结点:
- 释放 结点
链表的优缺点
链表的优点如下:
- 链表能灵活地分配内存空间;
- 能在 时间内删除或者添加元素,前提是该元素的前一个元素已知,当然也取决于是单链表还是双链表。在双链表中,如果已知该元素的后一个元素,同样可以在 时间内删除或者添加该元素。
链表的缺点是:
- 不像顺序表能通过下标迅速读取元素,每次都要从链表头开始一个一个读取;
- 查询第 个元素需要 时间。
算法例题
1.链表的翻转
例题:给你一个链表,每 k 个结点一组进行翻转,请你返回翻转后的链表。k 是一个正整数,它的值小于或等于链表的长度。如果结点总数不是 k 的整数倍,那么请将最后剩余的结点保持原有顺序。
说明:
- 算法只能使用常数的额外空间。
- 不能只是单纯的改变结点内部的值,而是需要实际的进行结点交换。
示例:
给定这个链表:1->2->3->4->5
当 k=2 时,应当返回:2->1->4->3->5
当 k=3 时,应当返回:3->2->1->4->5
解题思路:
这道题考察了两个知识点:对链表翻转算法是否熟悉、对递归算法的理解是否清晰
在翻转链表的时候,可以借助三个指针:prev、curr、next,分别代表前一个结点、当前结点和下一个结点,实现过程如下所示。
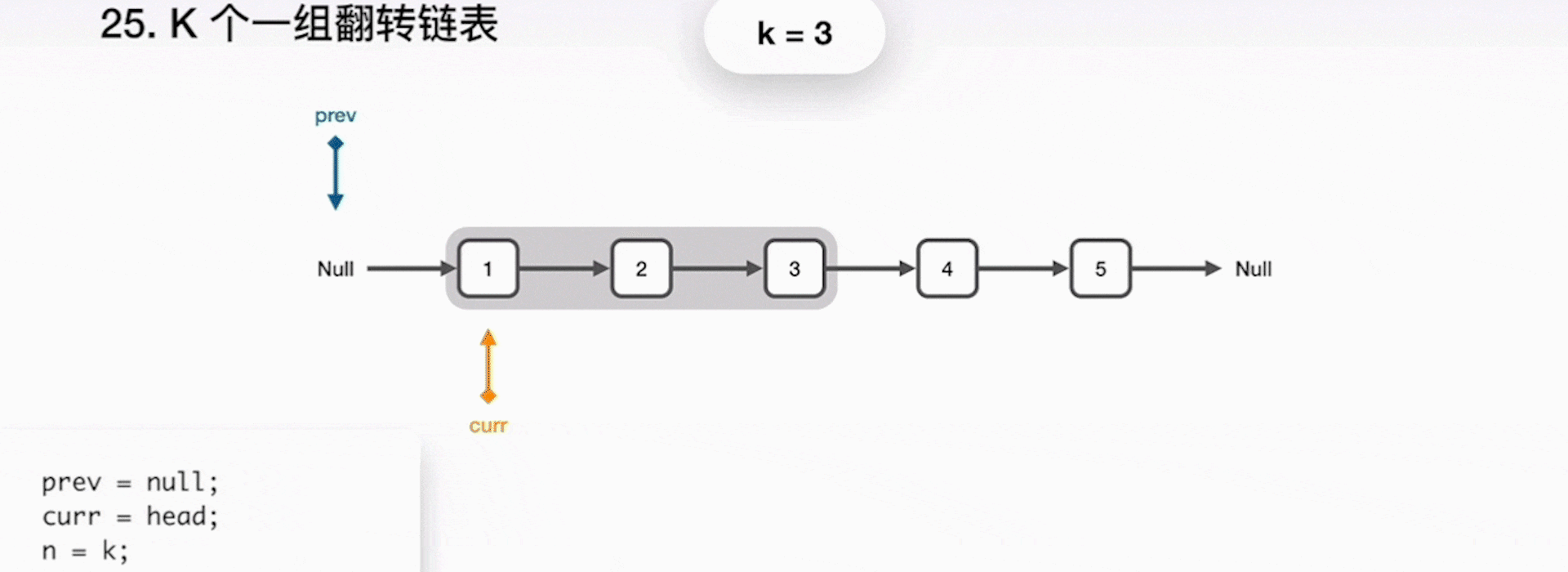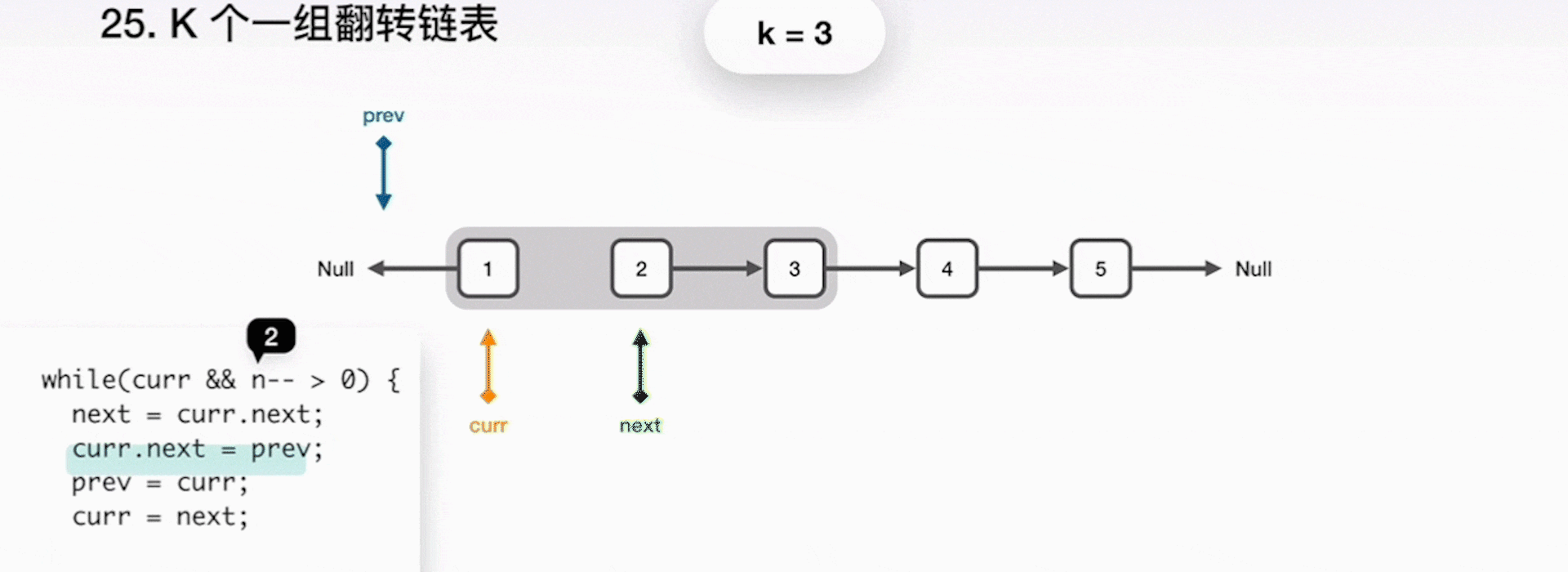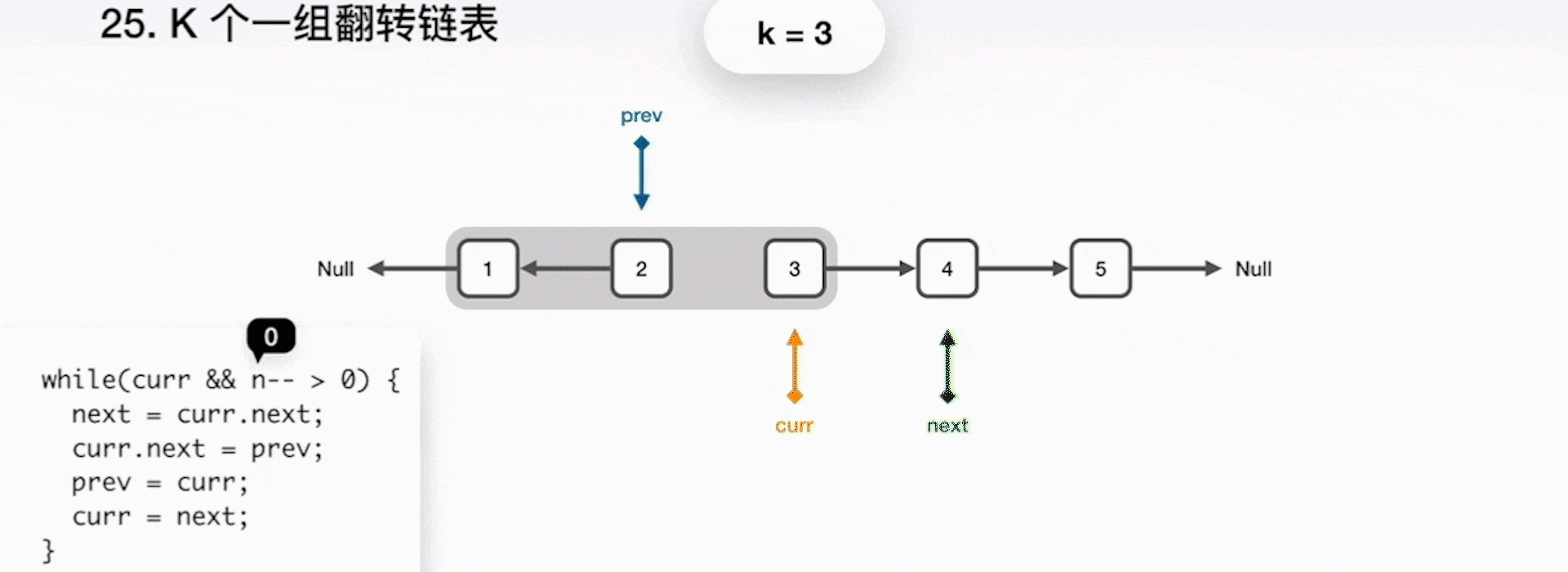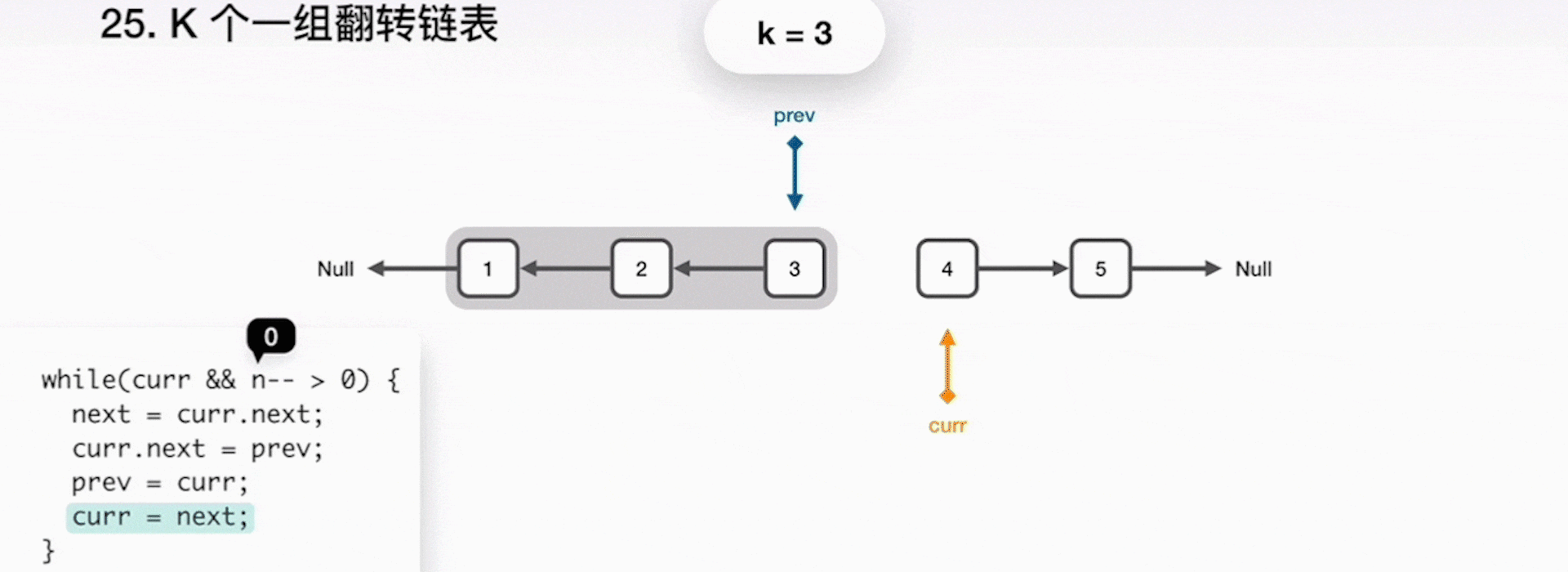
- 将 curr 指向的下一结点保存到 next 指针;
- curr 指向 prev,一起前进一步;
- 重复之前步骤,直到 k 个元素翻转完毕;
- 当完成了局部的翻转后,prev 就是最终的新的链表头,curr 指向了下一个要被处理的局部,而原来的头指针 head 成为了链表的尾巴。
参考
- 《数据结构(C语言版)》 严魏敏、吴伟民著
- 《数据结构(第3版)》 刘大有等著
- 《大话数据结构》 程杰著
- 《搞定数据结构与算法》 苏勇
