文章目录
一 简介
这个问题在之前有遇到,最近看了一个博客内容: 石杉的架构笔记 中看到了这个关于分布式锁的优化思路(这个仅仅作为一个思路,实现起来确实很复杂),特地记录一下
文章引至:石杉的架构笔记
文档路径:https://mp.weixin.qq.com/s/RLeujAj5rwZGNYMD0uLbrg
二 介绍
库存超卖现象:
假设下单时,用分布式锁来防止库存超卖,但是在每秒上千订单的高并发场景中,如何对分布式锁进行高并发的的优化呢?
1,库存超卖现象是怎么产生的?
先来看看如果不用分布式锁,所谓的电商库存超卖是啥意思?大家看看下面的图:
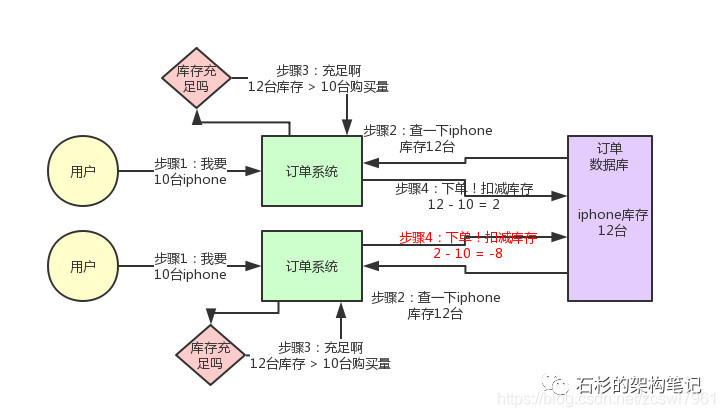
这个图,其实很清晰,假设订单系统部署两台机器上,不同的用户都要同时买10台iphone,分别发了一个请求给订单系统。
接着每个订单系统实例都去数据库里查了一下,当前iphone库存是12台。
于是乎,每个订单系统实例都发送SQL到数据库里下单,然后扣减了10个库存,其中一个将库存从12台扣减为2台,另外一个将库存从2台扣减为-8台。
现在完了,库存出现了负数!泪奔啊,没有20台iphone发给两个用户啊!这可如何是好。
2,用分布式锁如何解决库存超卖问题?
我们用分布式锁如何解决库存超卖问题呢?其实很简单
同一个锁key,同一时间只能有一个客户端拿到锁,其他客户端会陷入无限的等待来尝试获取那个锁,只有获取到锁的客户端才能执行下面的业务逻辑。

代码大概就是上面那个样子,现在我们来分析一下,为啥这样做可以避免库存超卖?
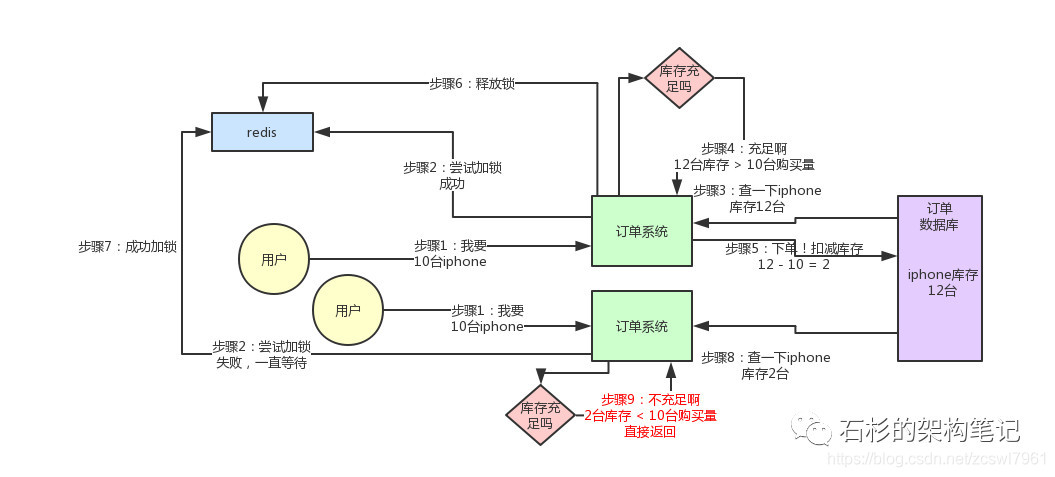
大家可以顺着上面的那个步骤序号看一遍,马上就明白了。
从上图可以看到,只有一个订单系统实例可以成功加分布式锁,然后只有他一个实例可以查库存、判断库存是否充足、下单扣减库存,接着释放锁。
释放锁之后,另外一个订单系统实例才能加锁,接着查库存,一下发现库存只有2台了,库存不足,无法购买,下单失败。不会将库存扣减为-8的。
3,有没有其他方案可以解决库存超卖问题?
比如悲观锁,分布式锁,乐观锁,队列串行化,异步队列分散,Redis原子操作,等等,很多方案,我们对库存超卖有自己的一整套优化机制。
三 分析
1,分布式锁在高并发场景下的问题
- 分布式一旦加入之后,对同一个商品的下单请求,会导致所有客户端都必须对同一个商品的库存锁key进行加锁操作
- 分布式锁加入进去之后,会导致同一个商品多个用户同时下单时,会变成基于分布式锁的串行化来处理这件事,导致没法同时处理同一个商品的大量下单的请求。
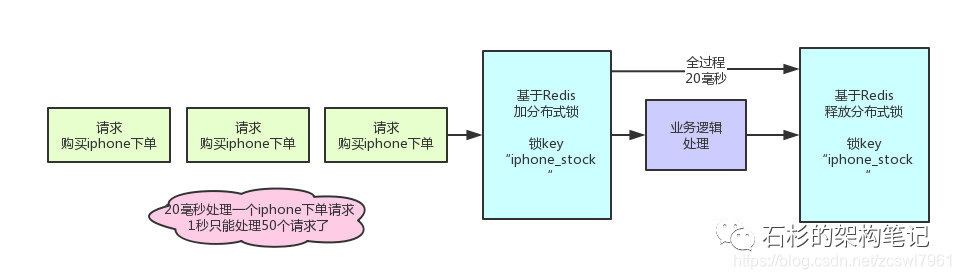
假设加锁之后,释放锁之前,查库存 -> 创建订单 -> 扣减库存,这个过程性能很高吧,算他全过程20毫秒。
那么1秒是1000毫秒,只能容纳50个对这个商品的请求依次串行完成处理。
比如一秒钟来50个请求,都是对iphone下单的,那么每个请求处理20毫秒,一个一个来,最后1000毫秒正好处理完50个请求。
2,如何对分布式锁进行高并发优化?
分段加锁的思想
把数据分成很多个段,每个段是一个单独的锁,所以多个线程过来并发修改数据的时候,可以并发的修改不同段的数据。不至于说,同一时间只能有一个线程独占修改ConcurrentHashMap中的数据。(根据Concurrent1.7的分段锁思路)
另外,Java 8中新增了一个LongAdder类,也是针对Java 7以前的AtomicLong进行的优化,解决的是CAS类操作在高并发场景下,使用乐观锁思路,会导致大量线程长时间重复循环。
LongAdder中也是采用了类似的分段CAS操作,失败则自动迁移到下一个分段进行CAS的思路。
分段锁在高并发售卖商品的示例
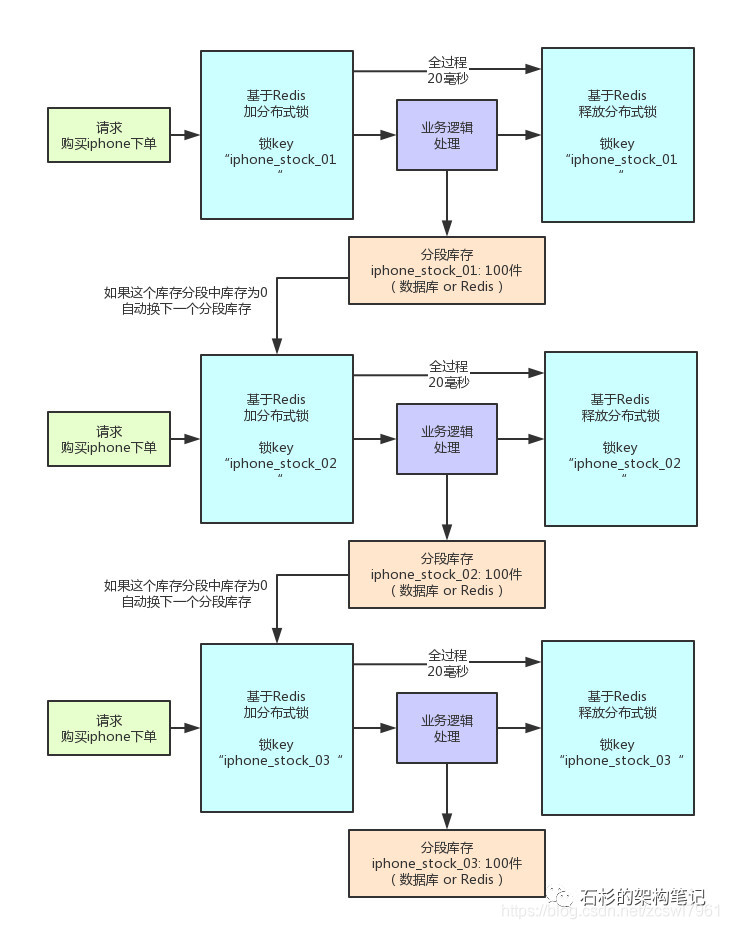
其实这就是分段加锁。你想,假如你现在iphone有1000个库存,那么你完全可以给拆成20个库存段,要是你愿意,可以在数据库的表里建20个库存字段,比如stock_01,stock_02,类似这样的,也可以在redis之类的地方放20个库存key。
总之,就是把你的1000件库存给他拆开,每个库存段是50件库存,比如stock_01对应50件库存,stock_02对应50件库存。
接着,每秒1000个请求过来了,好!此时其实可以是自己写一个简单的随机算法,每个请求都是随机在20个分段库存里,选择一个进行加锁。
分段加锁只是一个思路,但是也是存在大量的代码实现的复杂度:
- 某个下单请求,加锁,然后发现这个分段库存里的库存不足导致的问题,这个时候需要代码层面实现自动释放锁,然后立马换下一个分段库存,再次尝试加锁后尝试处理。这个过程一定要实现。
- 首先,你得对一个数据分段存储,一个库存字段本来好好的,现在要分为20个分段库存字段;
- 其次,你在每次处理库存的时候,还得自己写随机算法,随机挑选一个分段来处理;
- 最后,如果某个分段中的数据不足了,你还得自动切换到下一个分段数据去处理。
